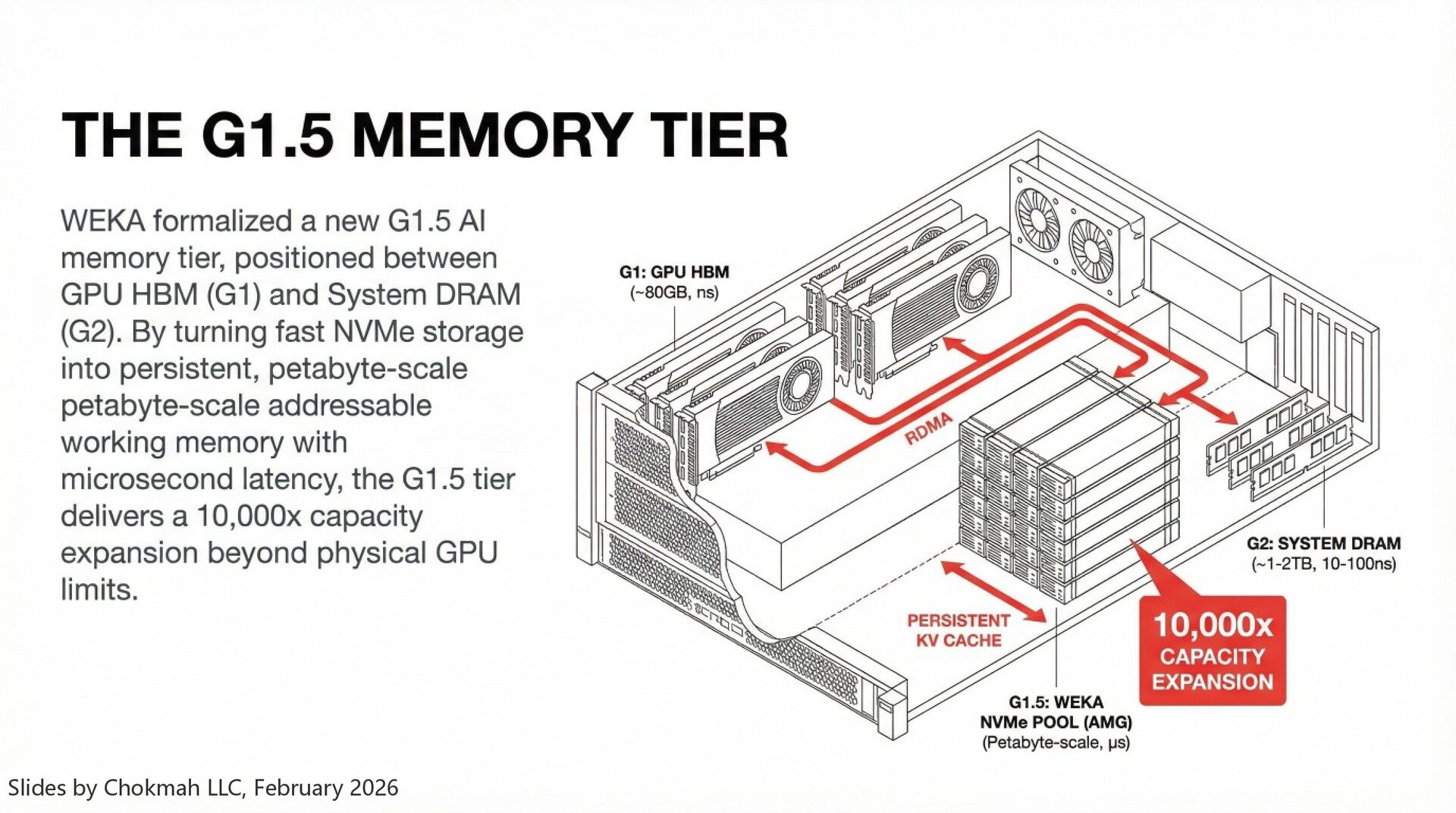
AI infrastructure's primary bottleneck has shifted from compute (FLOPs) to memory (HBM capacity). Modern LLMs generate massive KV caches (state) that quickly overflow the ~80GB HBM on GPUs, forcing systems to either crash (OOM), evict context (causing expensive recompute), or refuse long contexts. WEKA solves this by creating a new architectural tier—"G1.5"—between GPU HBM (G1) and CPU DRAM (G2), effectively turning fast NVMe storage into an extension of GPU memory
Traditional inference "pins" user sessions to specific GPUs because moving the KV cache is too expensive. WEKA's Augmented Memory Grid (AMG) externalizes state into a persistent, shared pool accessible via RDMA/GPUDirect, allowing any GPU to serve any request. This transforms GPUs from "stateful pets" into "stateless cattle"
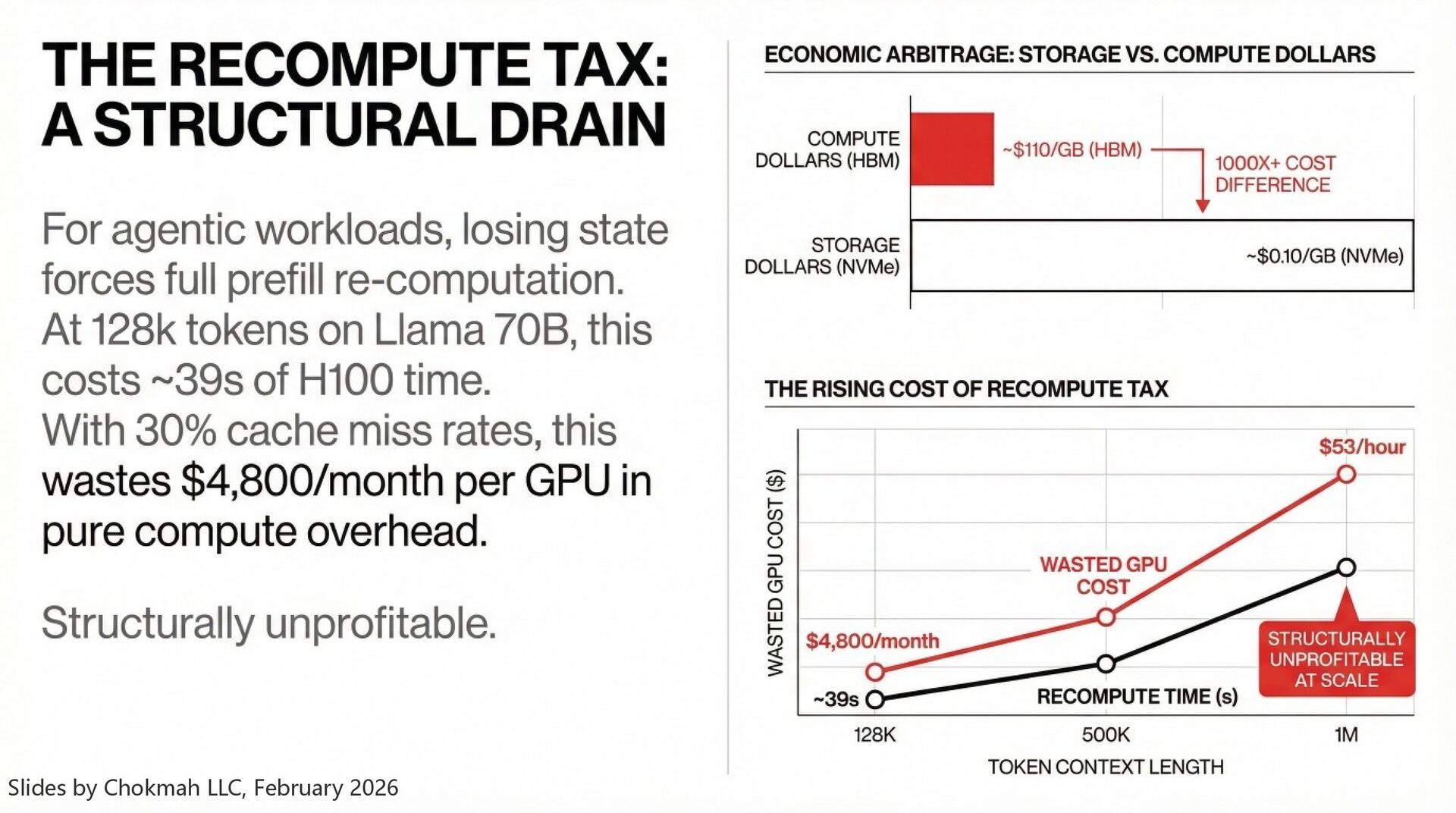
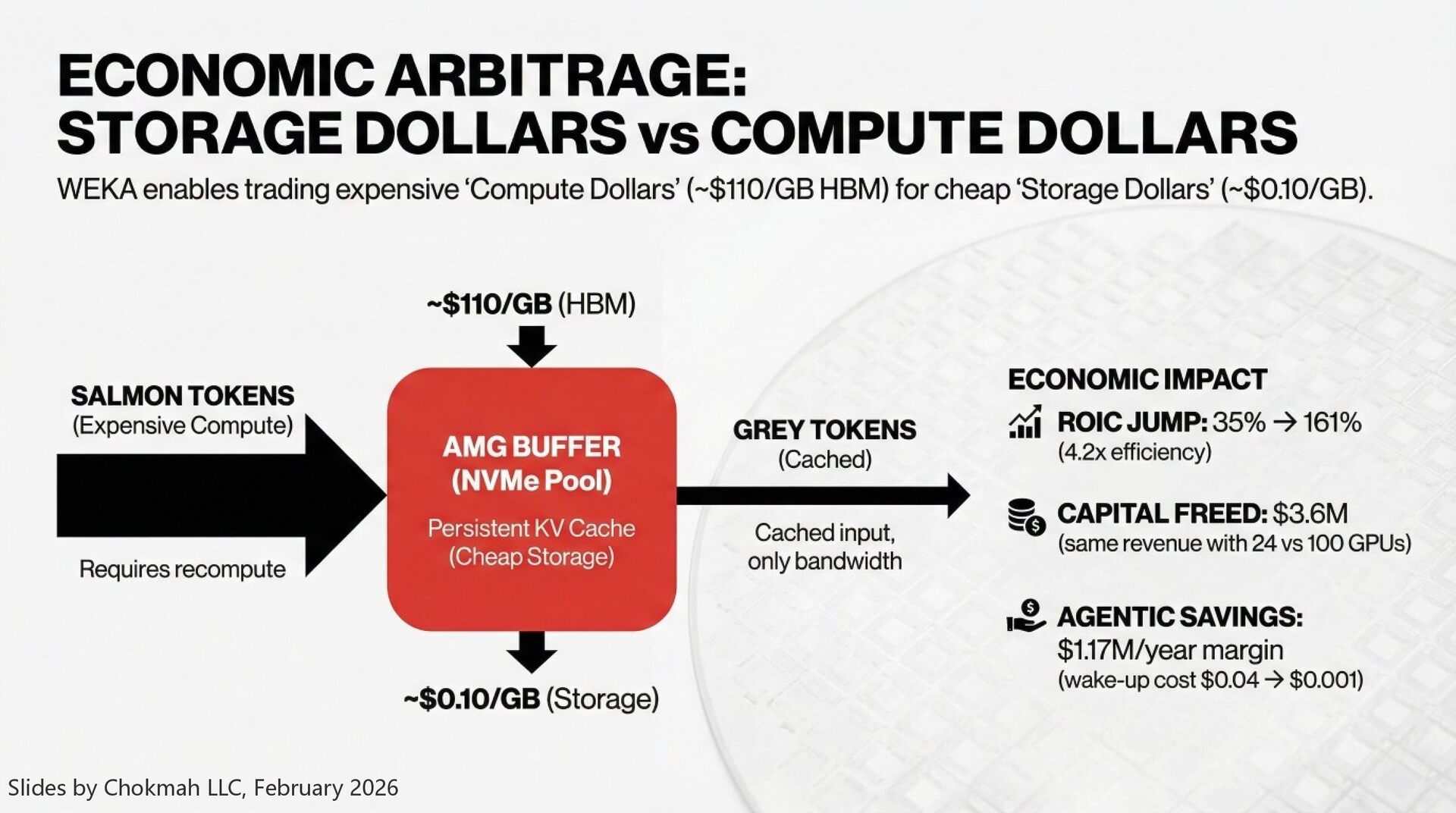
WEKA enables a trade of "Storage Dollars" (cheap, ~$0.10/GB) for "Compute Dollars" (expensive, ~$110/GB for HBM). By avoiding the "recompute tax"—regenerating KV caches from scratch—the system recovers GPU cycles that would otherwise burn electricity producing heat rather than tokens
WEKA reframes their solution not as "faster storage" but as a "Token Warehouse"—a memory-class buffer for "Work in Progress" (active KV caches) rather than "Finished Goods" (datasets/checkpoints). This shifts the paradigm from "storage as archive" to "storage as working memory"
Traditional inference economics punish long context (it consumes scarce HBM and triggers recompute). AMG inverts this: long context becomes a recoverable asset stored in cheap NVMe, while the cost of holding it approaches zero. This converts expensive "Salmon Tokens" (new input requiring compute) into cheap "Grey Tokens" (cached input requiring only bandwidth)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}