Big Data Processing with the elegance of Clojure? As Apache Spark and Clojure share a similar mindset (functional, immutability), they fit together nicely.
Dr. Christian Betz gives an intro into Apache Spark. He shows some examples (live coding), explaining benefits from that technology stack, e.g. test-driven development of Big Data solutions, or REPL-driven development.
In the past months, Chris designed and implemented a Spark system for productive use. He released „sparkling“ (https://gorillalabs.github.io/sparkling), a Clojure-API to Apache Spark. Tips and tricks from practical experience can help you with your first steps into Clojure/Spark.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
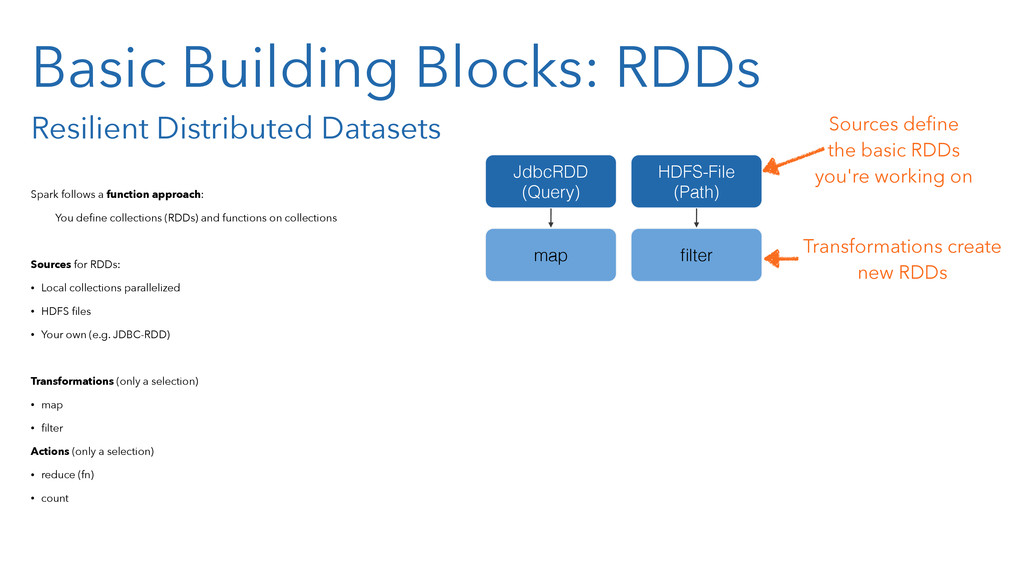{kind=link}
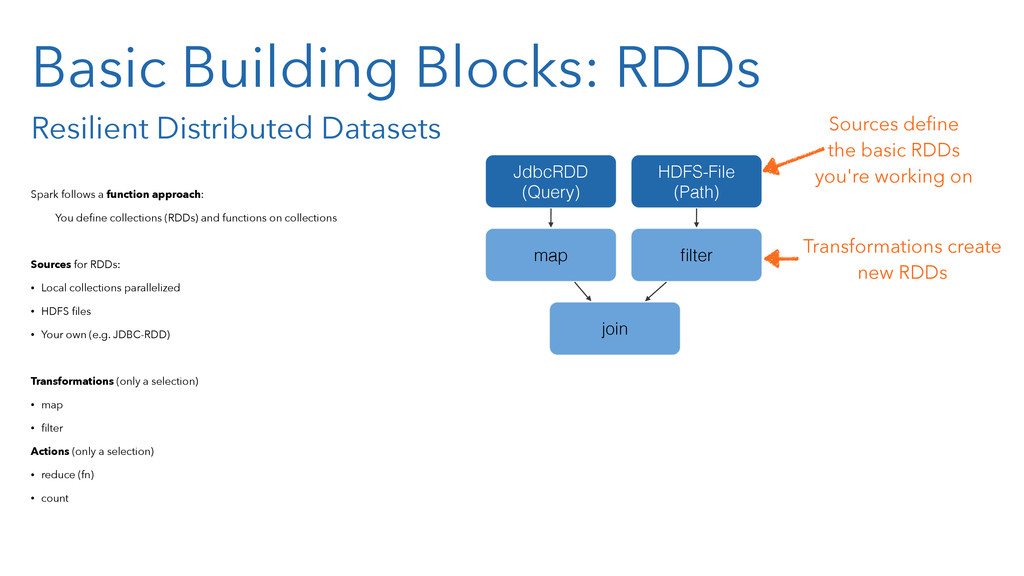{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In Practice 1: line count (defn line-count [lines] (->> lines](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_22.jpg){kind=link}
![In Practice 2: line count cont'd (defn line-count* [lines] (->>](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In Practice 3: status codes (defn parse-line [line] (some->> line](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_32.jpg){kind=link}
![In Practice 4: status codes cont'd (defn parse-line [line] (some->>](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
![In Practice 7: top errors (defn top-errors [lines] (->> lines](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_36.jpg){kind=link}
![In Practice 8: top errors cont'd (defn top-errors* [lines] (->>](https://files.speakerdeck.com/presentations/beb5d75623804ae3a87c5bf0ee0e1cbf/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
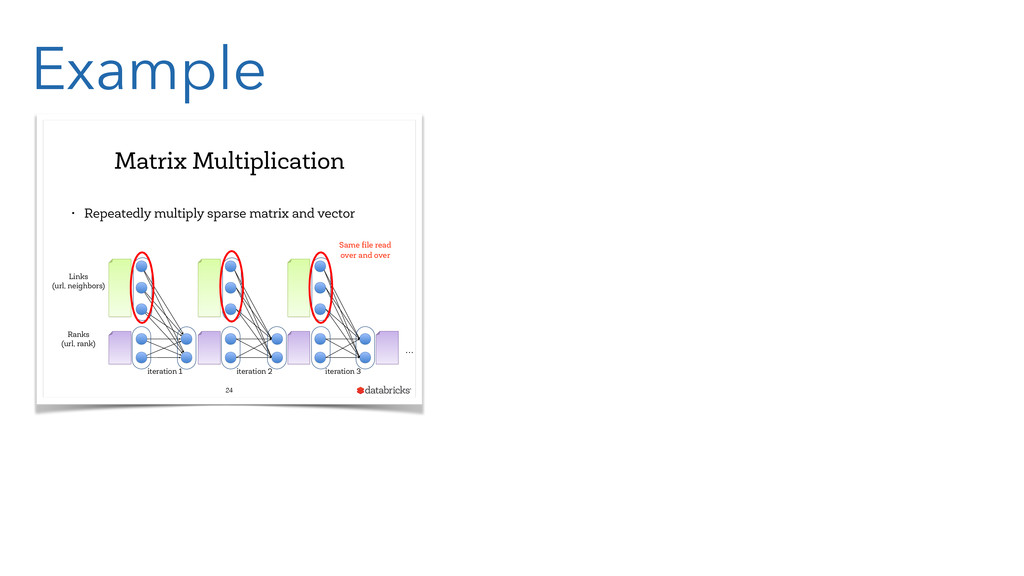{kind=link}
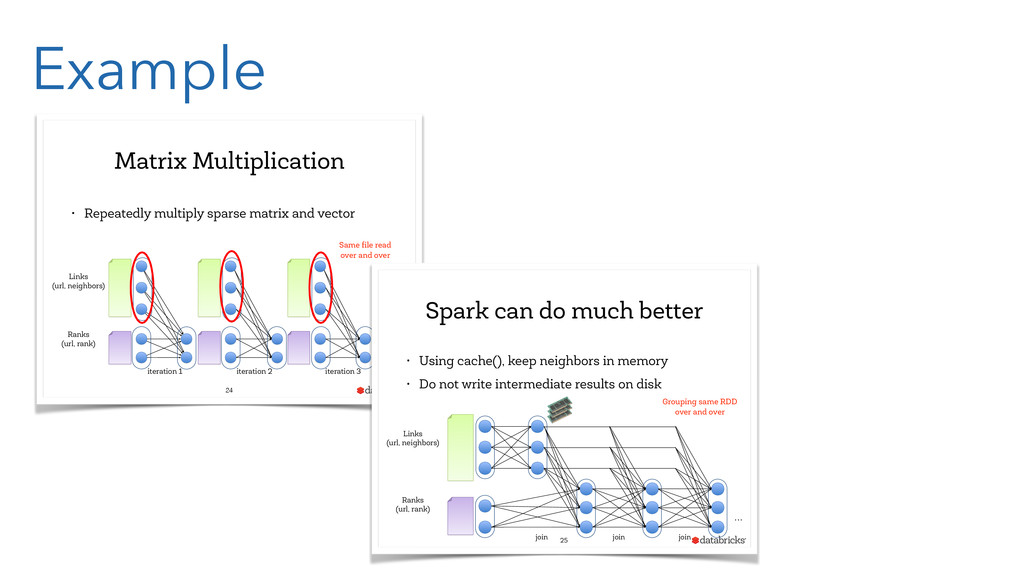{kind=link}
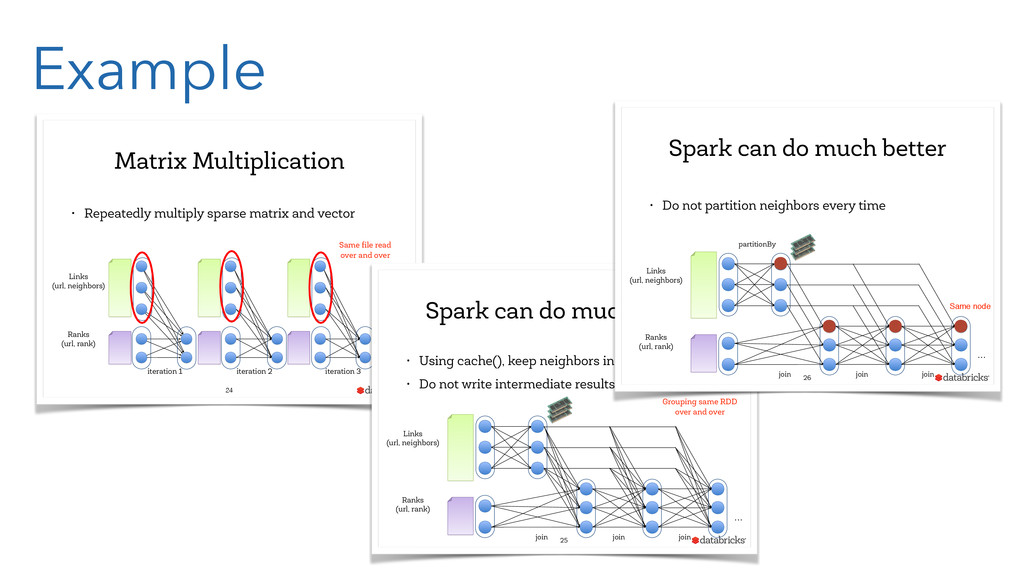{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}