Talk given at ClojureD conference, Berlin
Apache Spark is an engine for efficiently processing large amounts of data. We show how to apply the elegance of Clojure to Spark - fully exploiting the REPL and dynamic typing. There will be live coding using our gorillalabs/sparkling API.
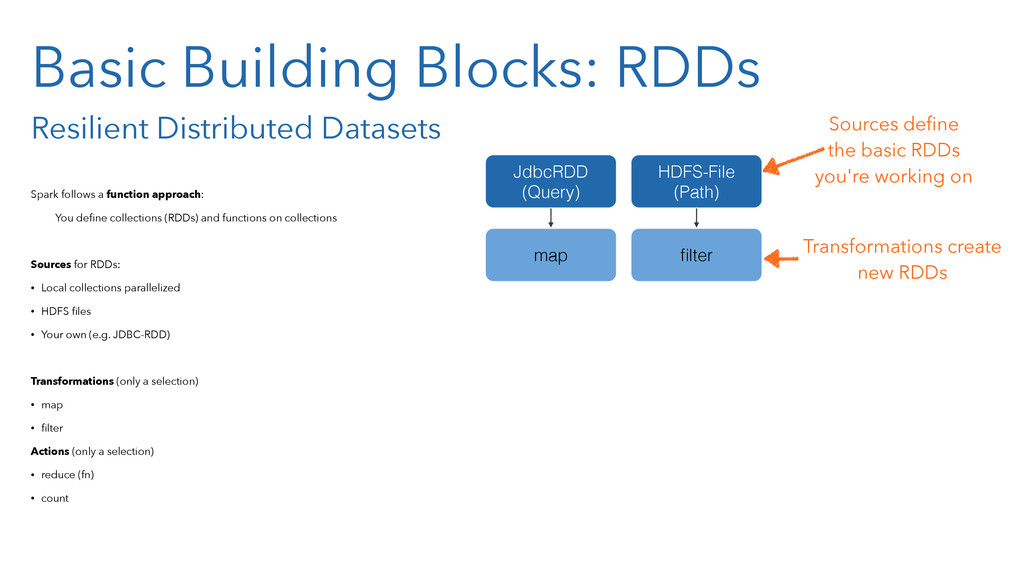
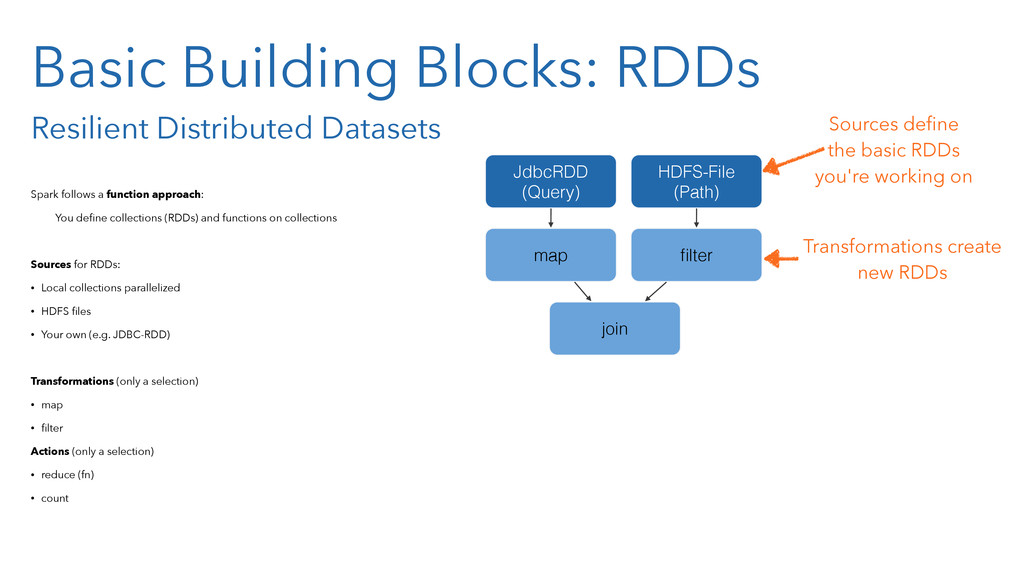
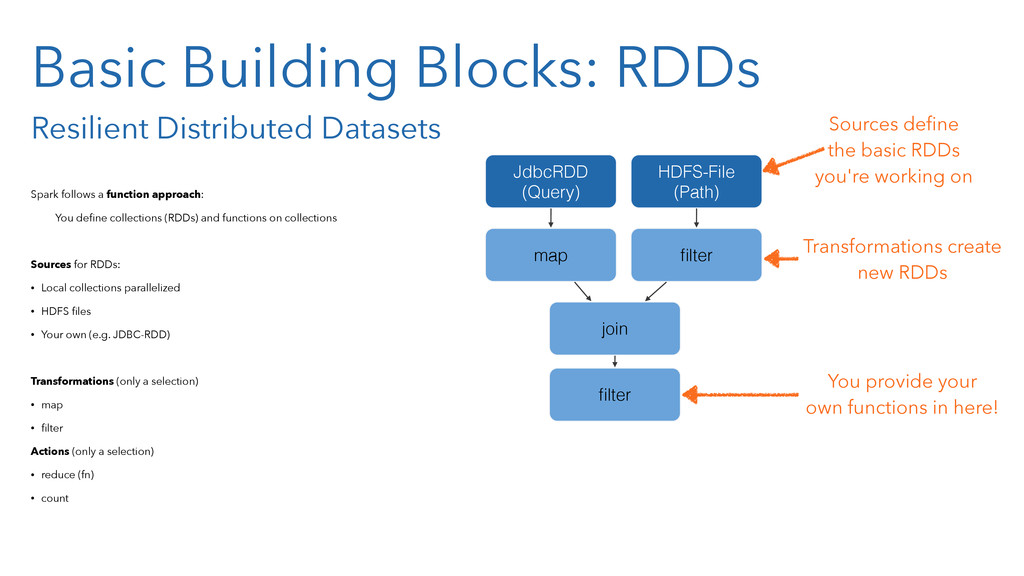
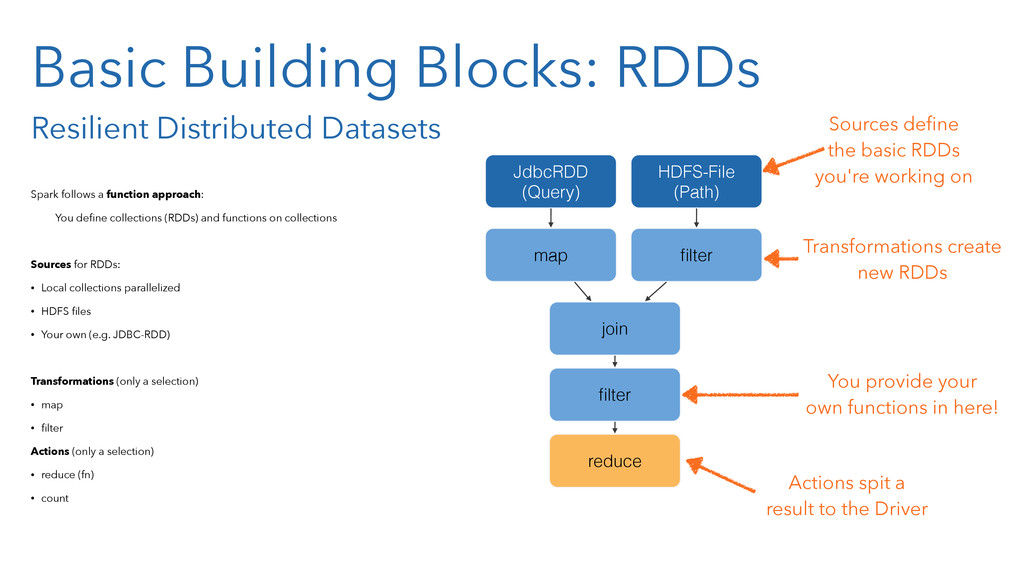
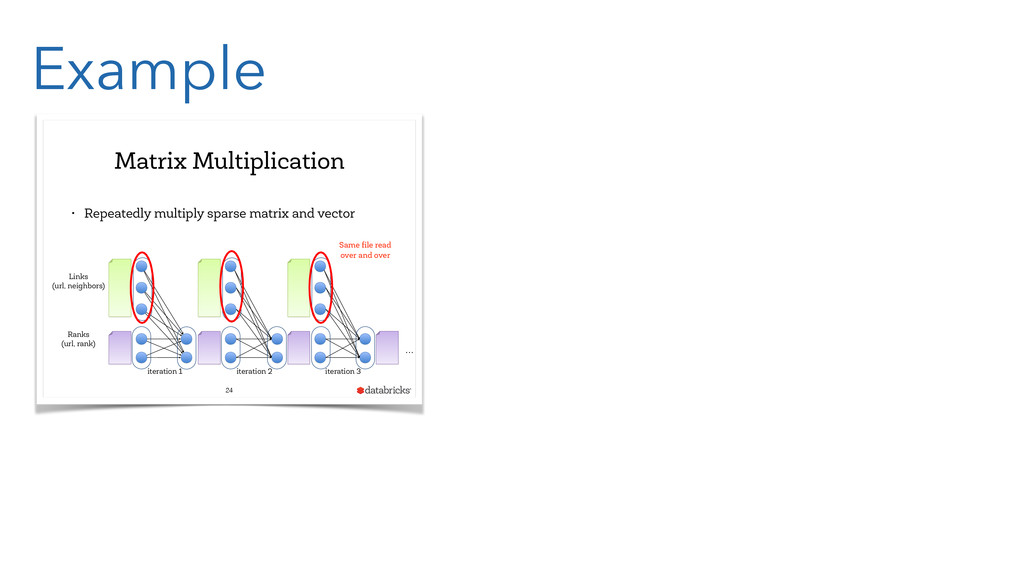
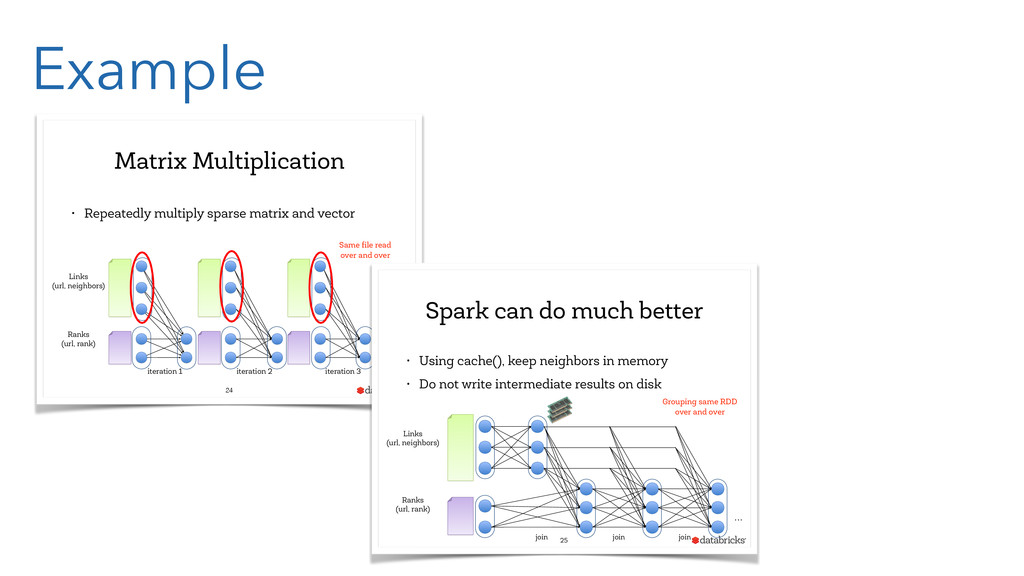
In the presentation, we will of course introduce the core concepts of Spark, like resilient distributed data sets (RDD). And you will learn how the Spark concepts resembles those well-known from Clojure, like persistent data structures and functional programming.
Finally, we will provide some Do’s and Don’ts for you to kick off your Spark program based upon our experience.
About Paulus Esterhazy and Christian Betz
Being a LISP hacker for several years, and a Java-guy for some more, Chris turned to Clojure for production code in 2011. He’s been Project Lead, Software Architect, and VP Tech in the meantime, interested in AI and data-visualization.
Now, working on the heart of data driven marketing for Performance Media in Hamburg, he turned to Apache Spark for some Big Data jobs. Chris released the API-wrapper ‘chrisbetz/sparkling’ to fully exploit the power of his compute cluster.
Paulus Esterhazy
Paulus is a philosophy PhD turned software engineer with an interest in functional programming and a penchant for hammock-driven development.
He currently works as Senior Web Developer at Red Pineapple Media in Berlin.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In Practice 1: line count (defn line-count [lines] (->> lines](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_28.jpg){kind=link}
![In Practice 2: line count cont'd (defn line-count* [lines] (->>](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In Practice 3: status codes (defn parse-line [line] (some->> line](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_38.jpg){kind=link}
![In Practice 4: status codes cont'd (defn parse-line [line] (some->>](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
![In Practice 7: top errors (defn top-errors [lines] (->> lines](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_42.jpg){kind=link}
![In Practice 8: top errors cont'd (defn top-errors* [lines] (->](https://files.speakerdeck.com/presentations/6410055085e60132de3b7a1c3ec56d64/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}