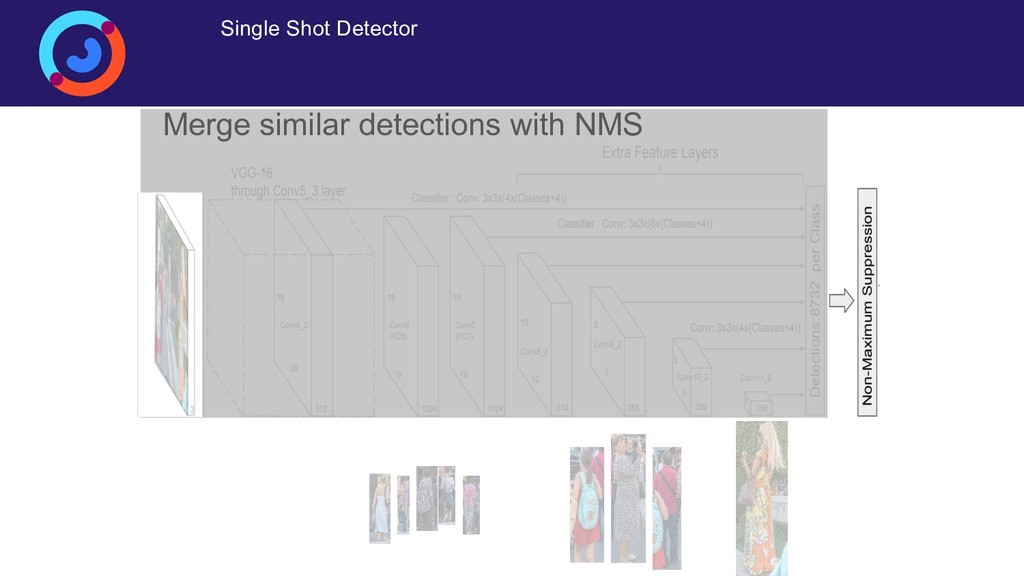
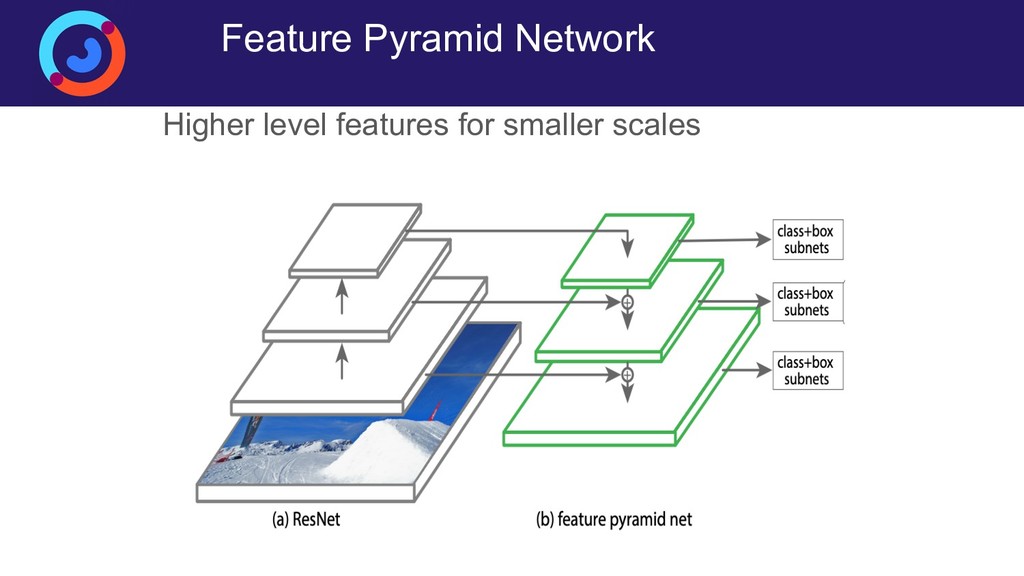
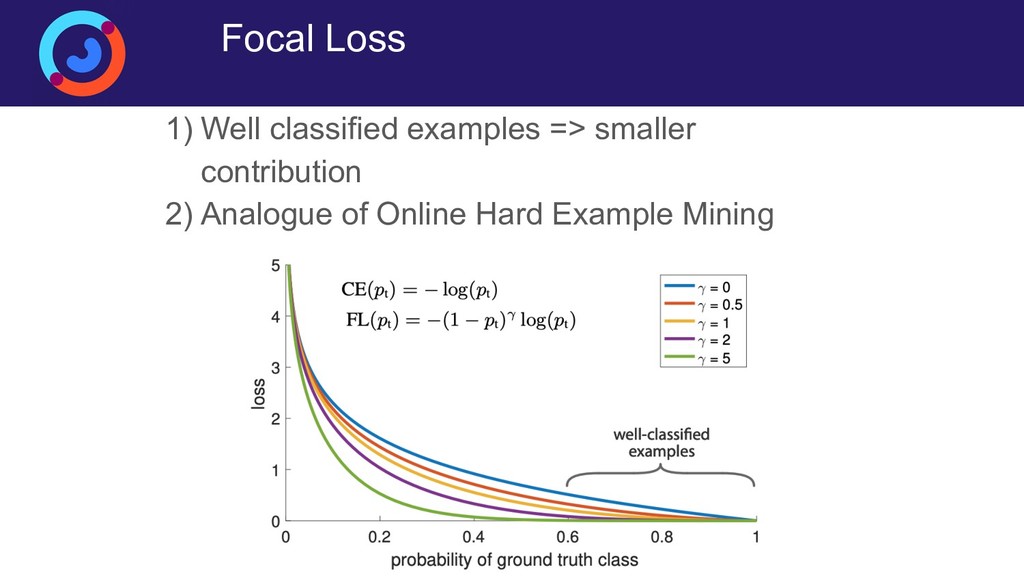
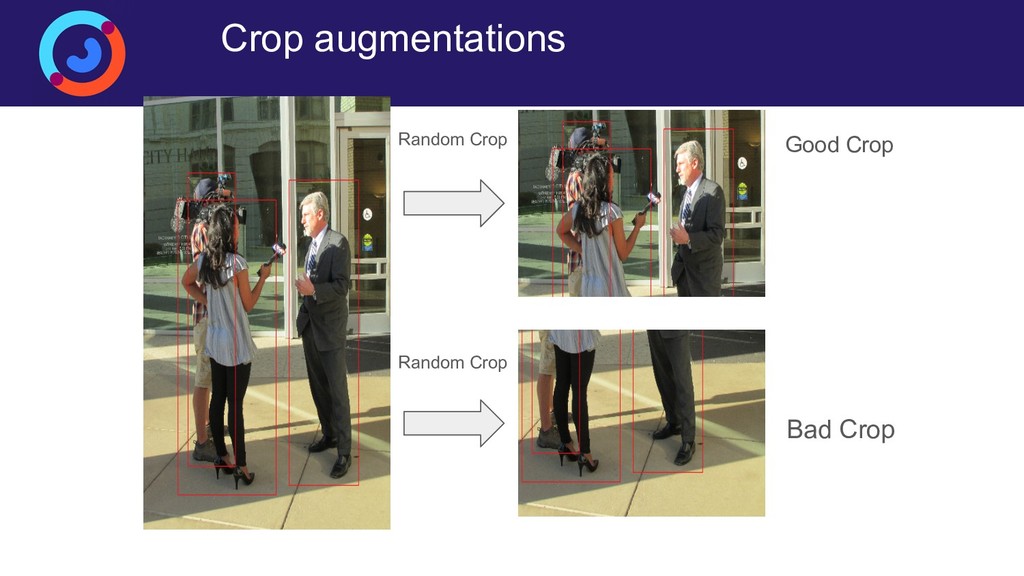
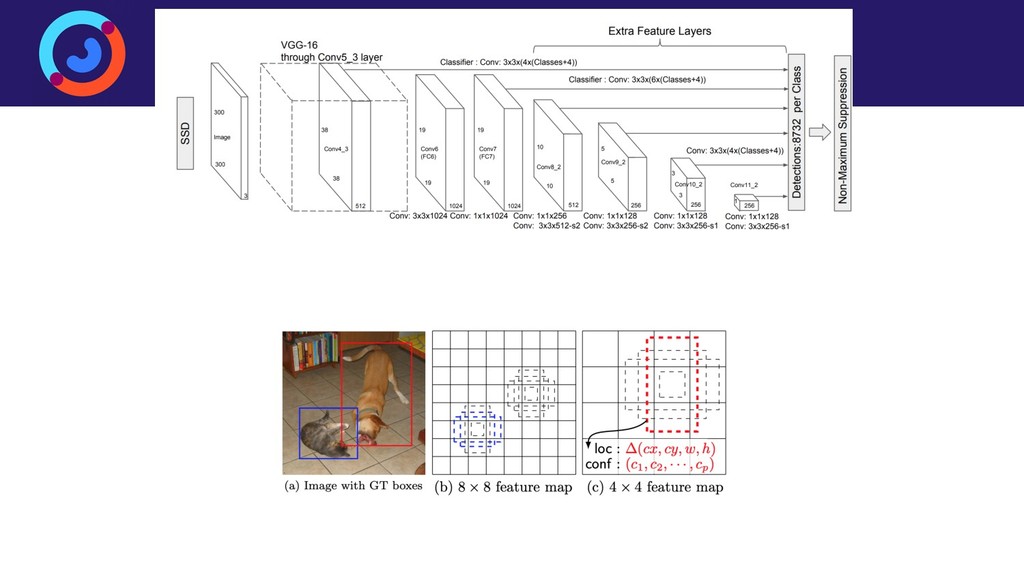
Задача детектирования людей на изображении или видеопотоке — это сложная задача компьютерного зрения, основными сложностями в которой являются разнообразие возможных сценариев детектирования, большая внутриклассовая вариативность самих людей (одежда, поза), а также частое перекрытие людей (ообенно сложный случай — толпы). Для её решения исторически было придумано множество способов, но на данный момент наилучшее качество демонстрируют свёрточные нейронные сети. Доклад посвящен построению собственной production-ready системы детектирования людей, работающей на свёрточных нейронных сетях в реальном времении. Рассматриваются специфические приемы (архитектуры, функции потерь, особенности обучения), позволяющие существенно поднять качество детектирования.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
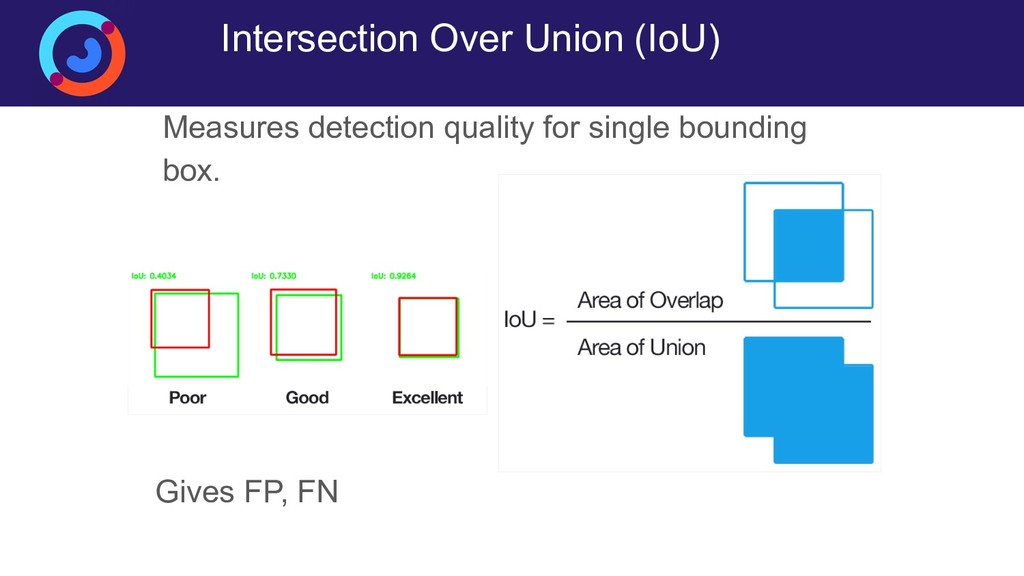{kind=link}
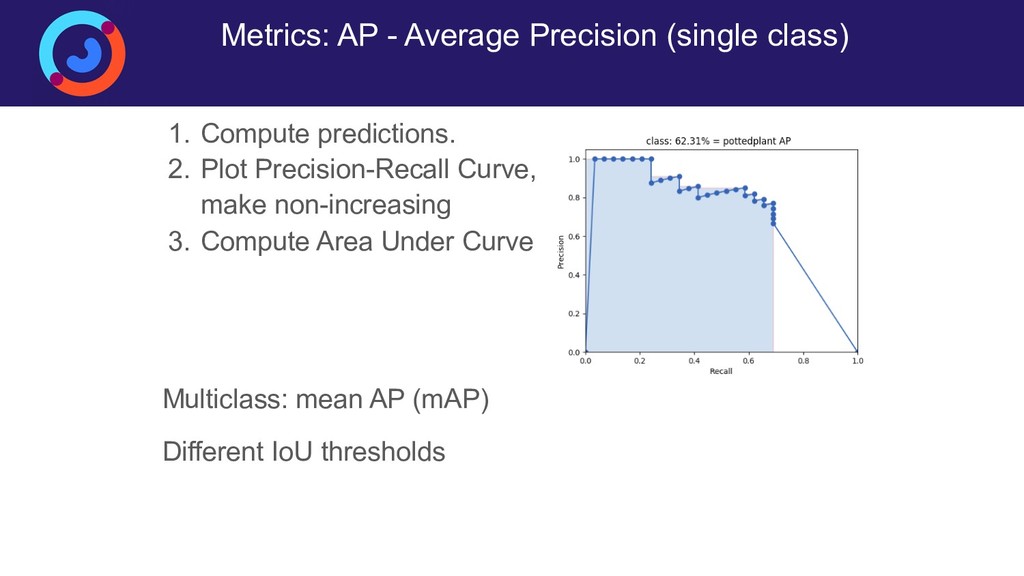{kind=link}
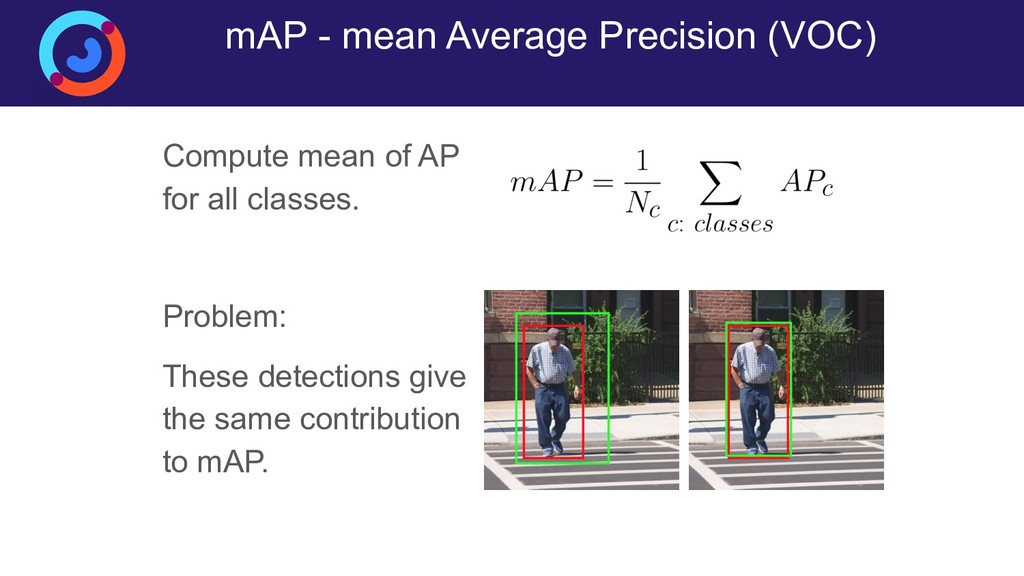{kind=link}
![Metrics: mAP@[.5:.95] (COCO) 1) For each IoU threshold in [.5:.95]](https://files.speakerdeck.com/presentations/e1936519373844218313b9a0fcd1b5d3/slide_14.jpg){kind=link}
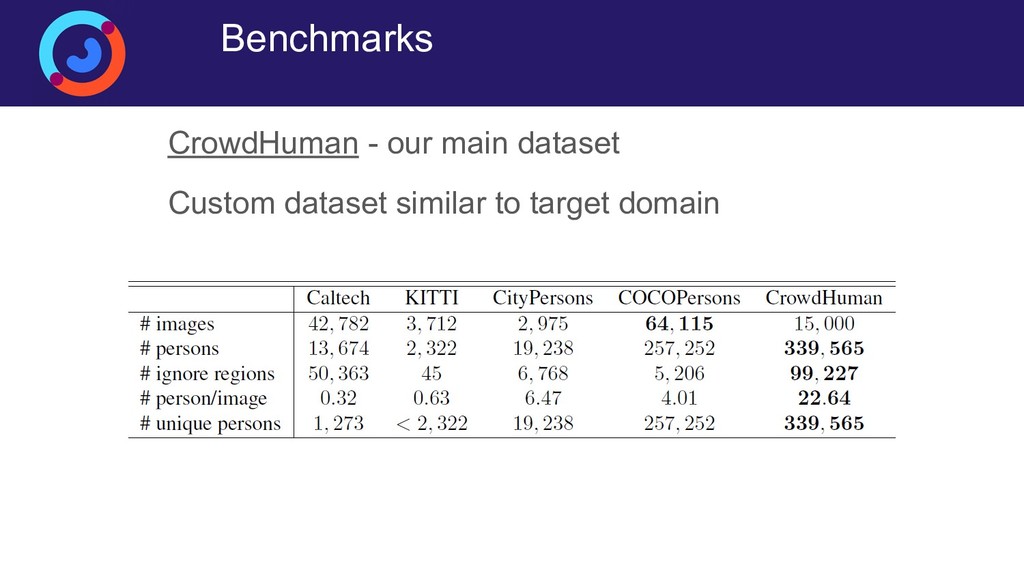{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
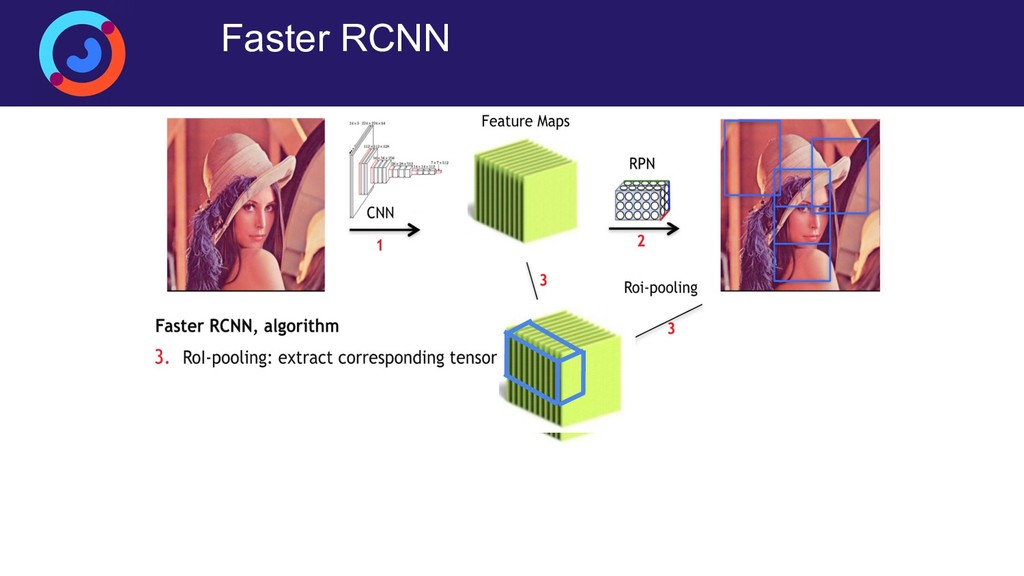{kind=link}
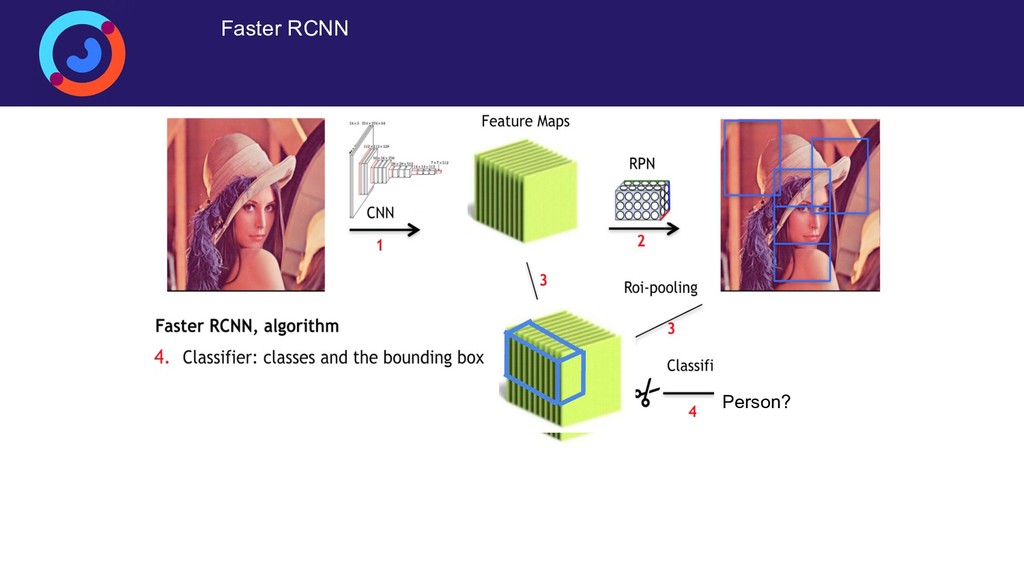{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
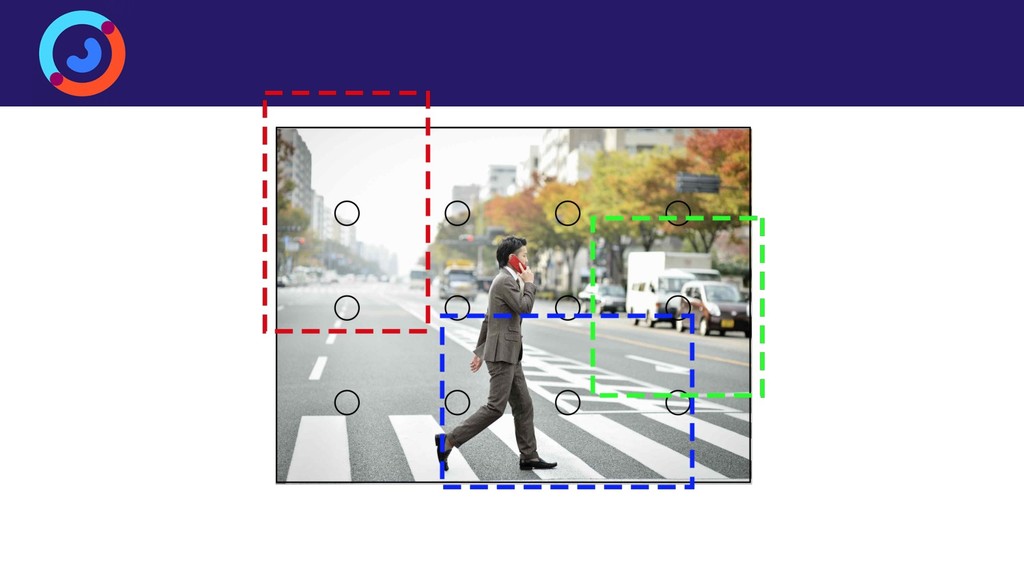{kind=link}
{kind=link}
{kind=link}
{kind=link}
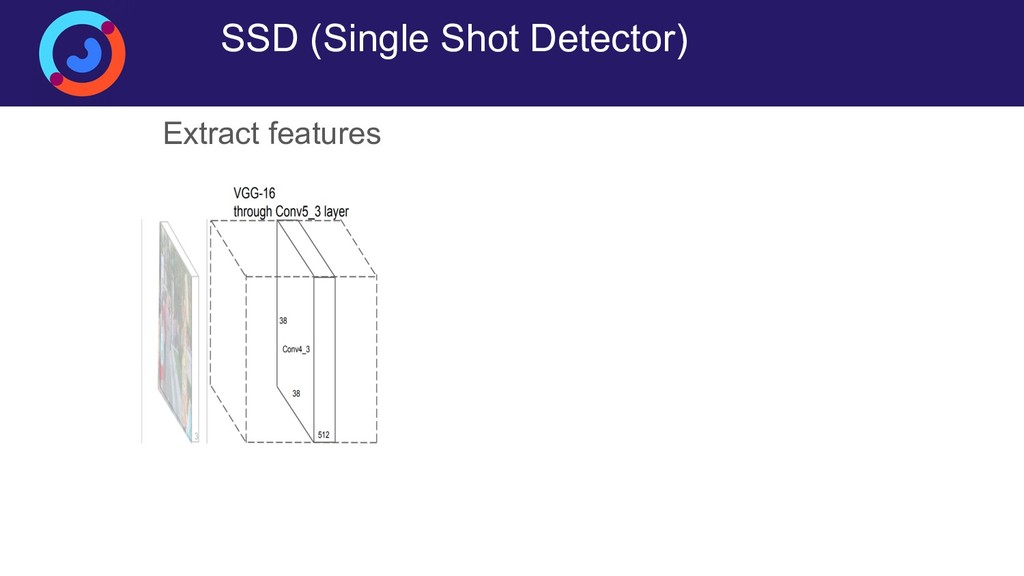{kind=link}
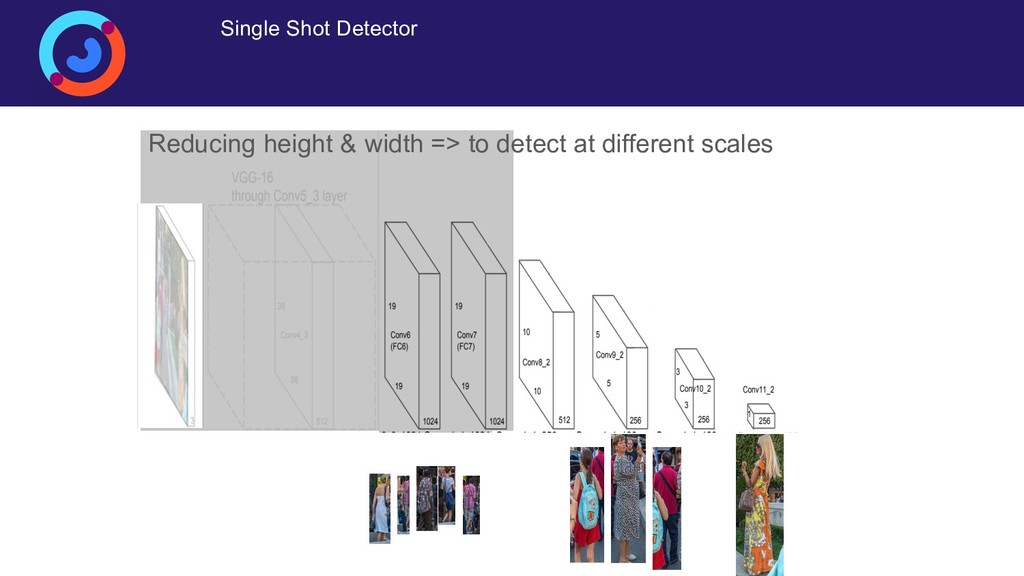{kind=link}
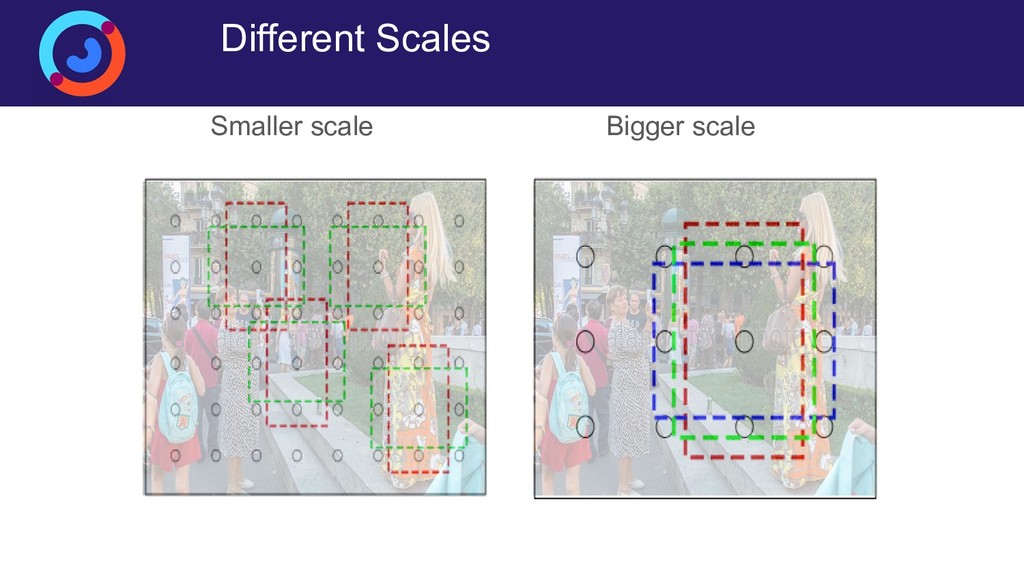{kind=link}
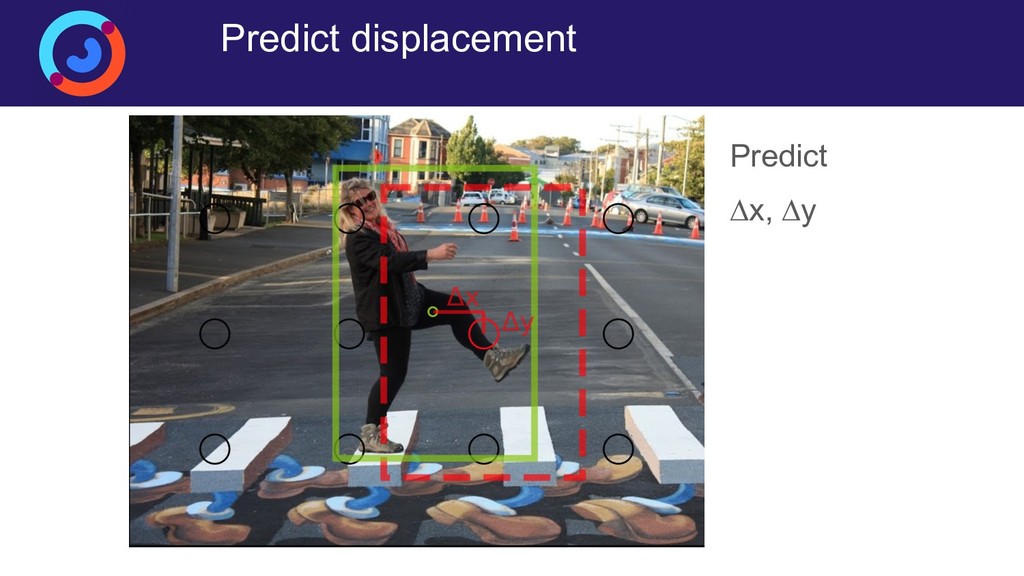{kind=link}
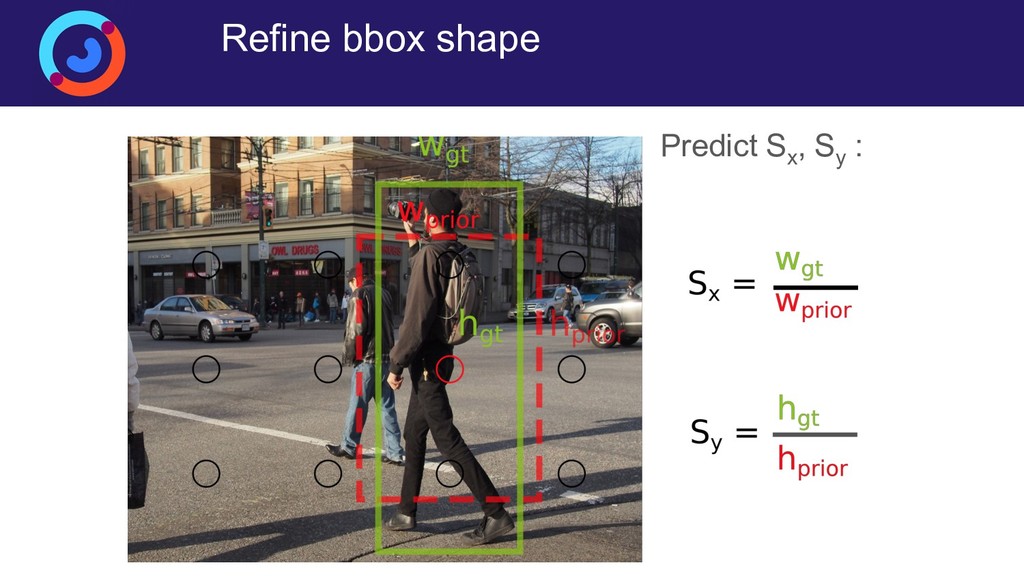{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
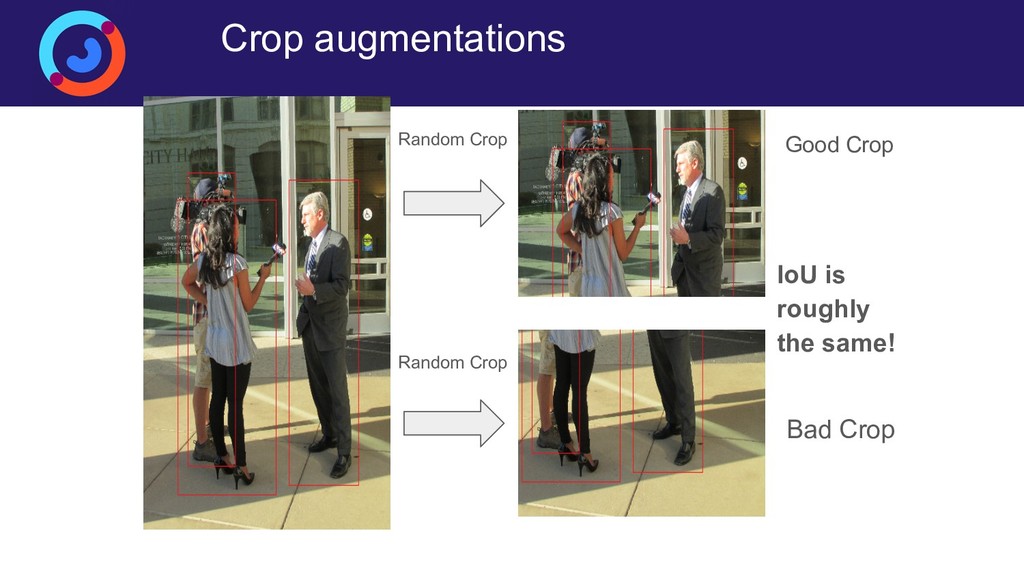{kind=link}
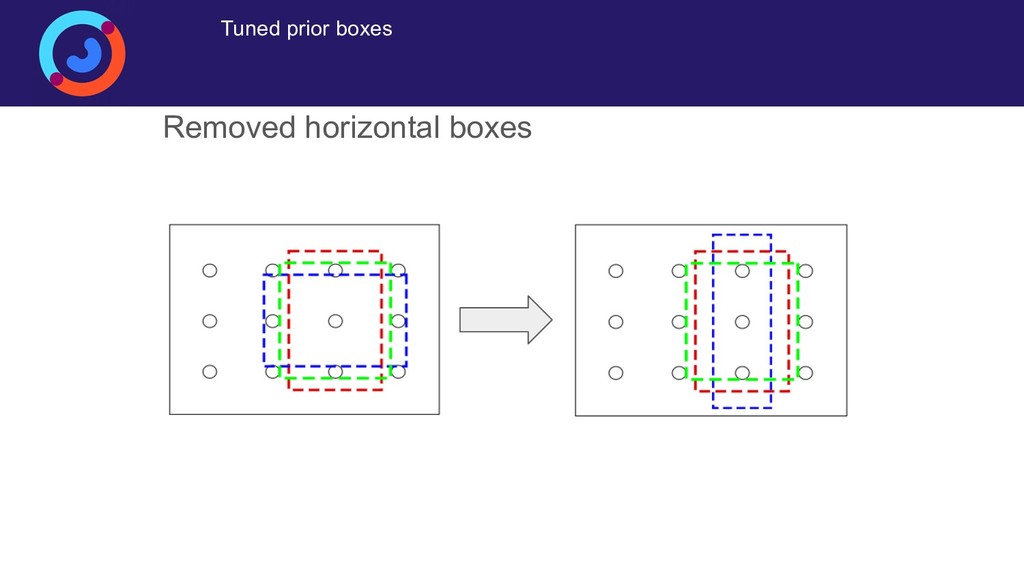{kind=link}
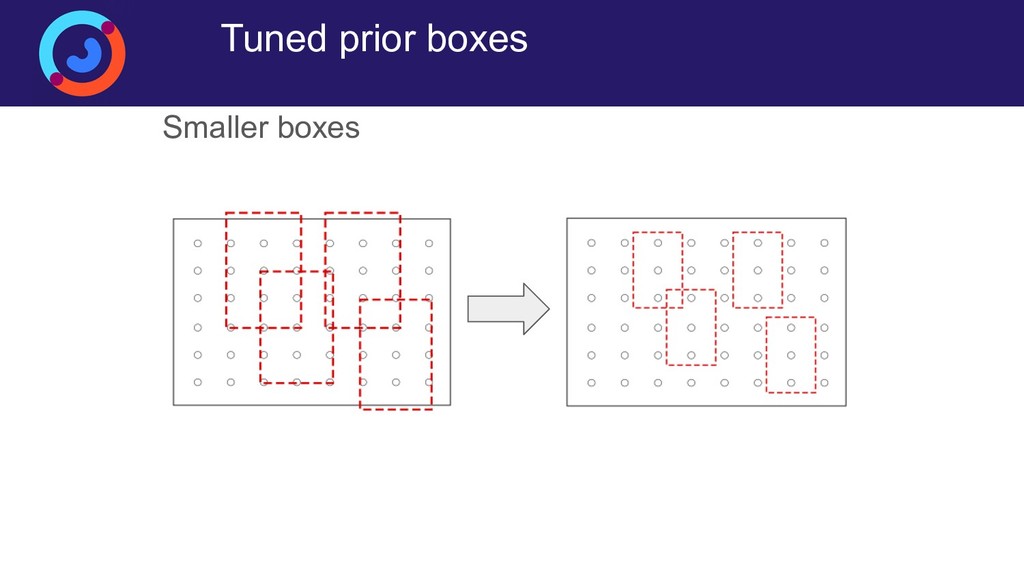{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
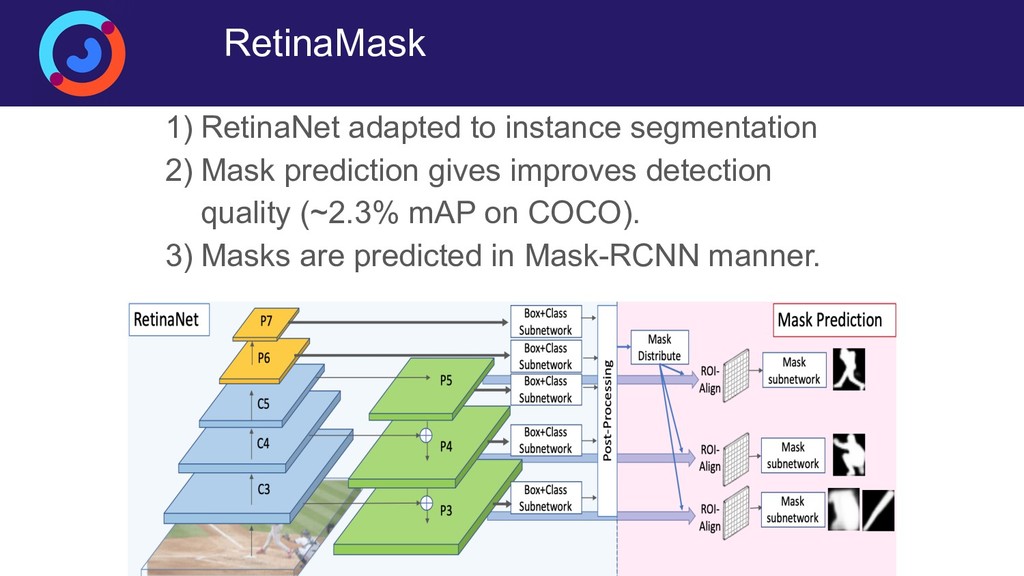{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}