partitioning for heterogeneous causal e ects. Proceedings of the National Academy of Sciences, ( ), – . Breiman, L. ( ). Bagging predictors. Machine Learning, ( ), – . Chernozhukov, V., Chetverikov, D., Demirer, M., Du o, E., Hansen, C., & Newey, W. ( ). Double / debiased / Neyman machine learning of treatment e ects. American Economic Review, ( ), – . Chipman, H. A., George, E. I., & McCulloch, R. E. ( ). BART: Bayesian additive regression trees. e Annals of Applied Statistics, ( ), – . Cutler, A., Cutler, D. R., & Stevens, J. R. ( ). Random Forests. In C. Zhang & Y. Ma (Eds.), Ensemble Machine Learning (pp. – ). Springer. Doyle, M. W., & Sambanis, N. ( ). International peacebuilding: A theoretical and quantitative analysis. American Political Science Review, ( ), – . Hastie, T., Tibshirani, R., & Friedman, J. ( ). e elements of statistical learning: Data mining, inference, and prediction. Springer Verlag. Hofmann, T., Sch¨ olkopf, B., & Smola, A. J. ( ). Kernel methods in machine learning. e Annals of Statistics, ( ), – .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
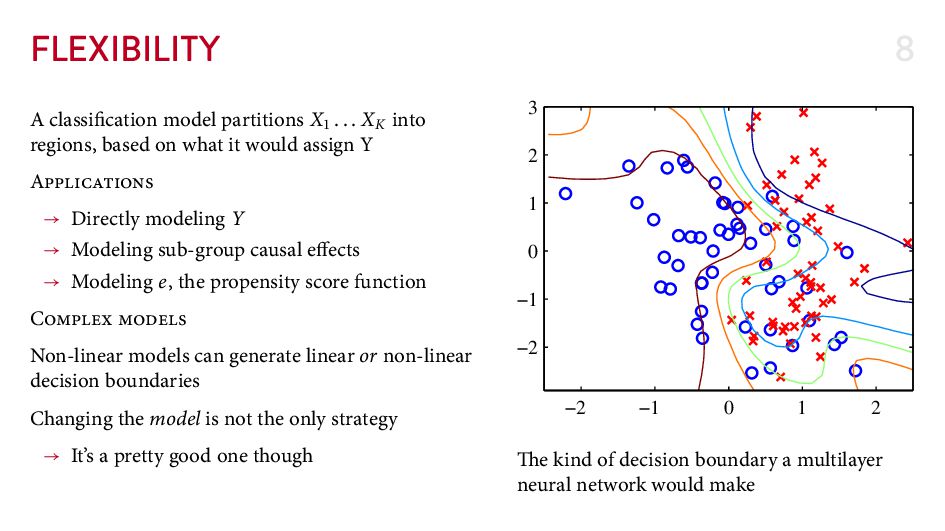{kind=link}
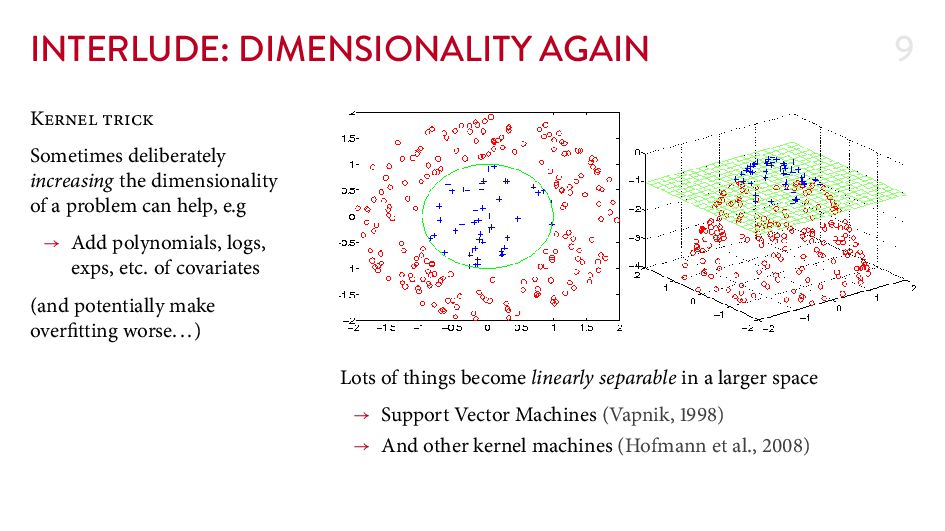{kind=link}
{kind=link}
{kind=link}
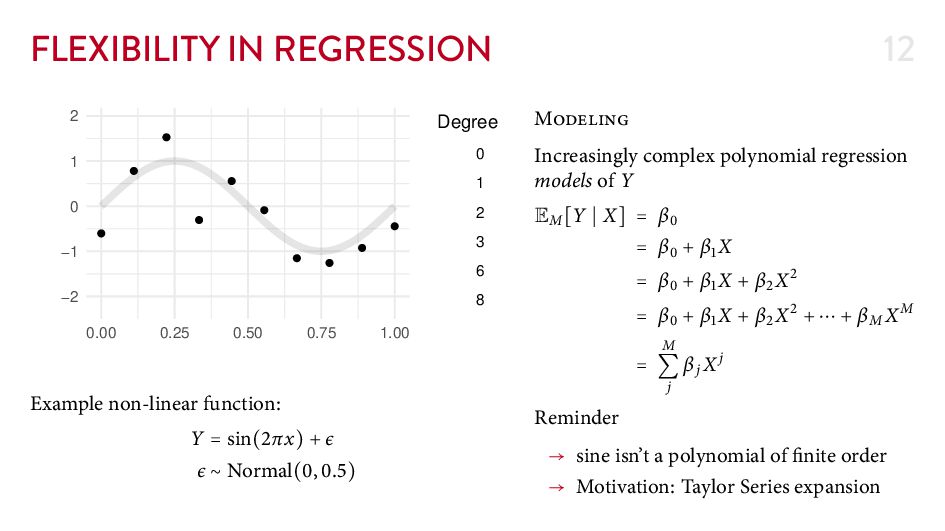{kind=link}
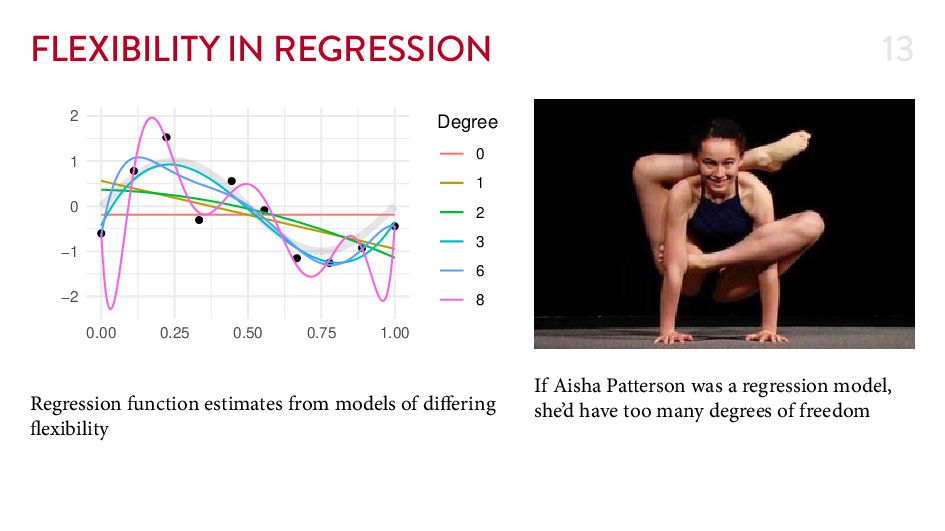{kind=link}
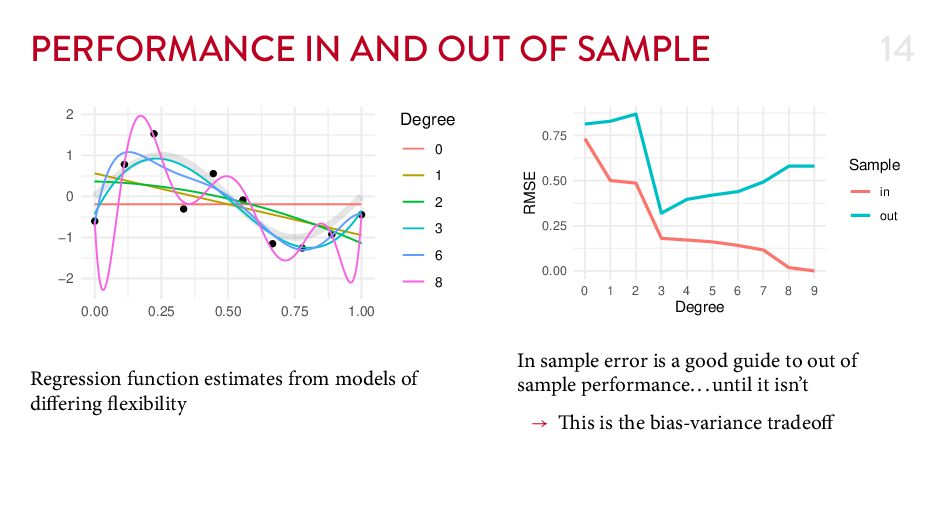{kind=link}
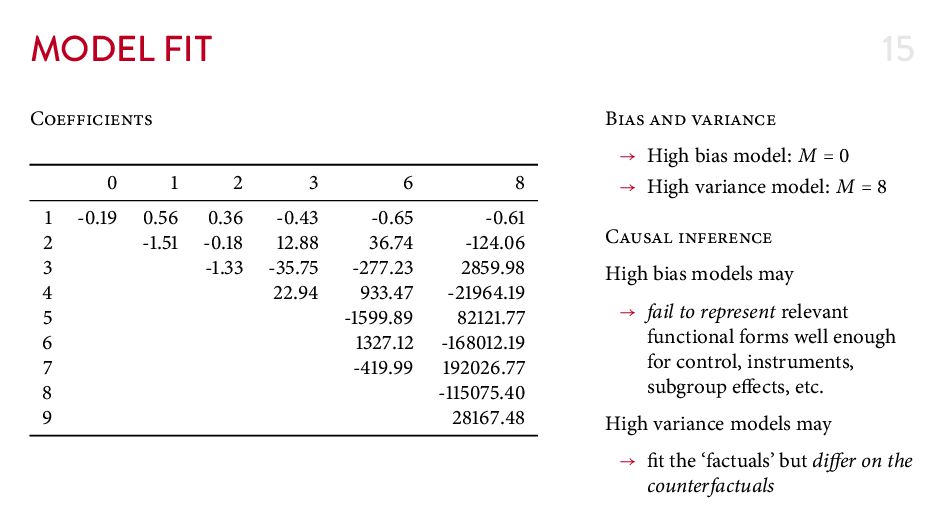{kind=link}
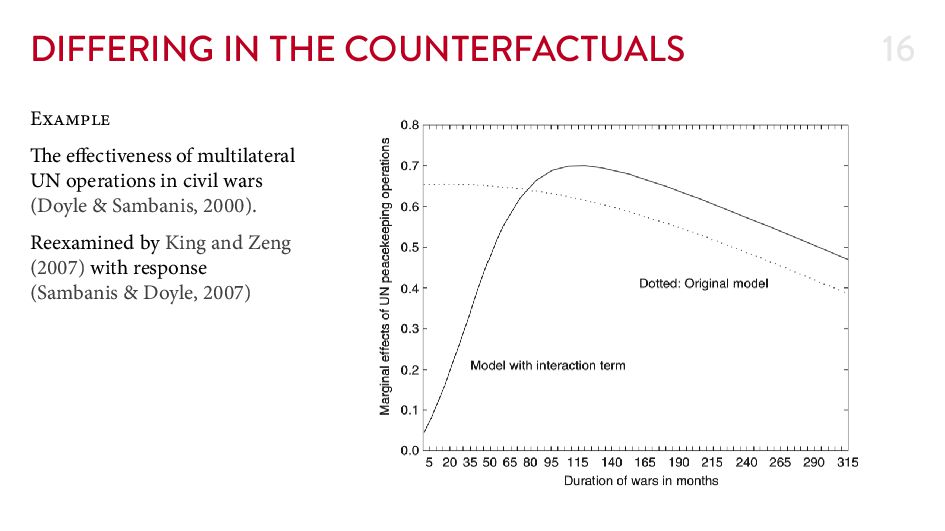{kind=link}
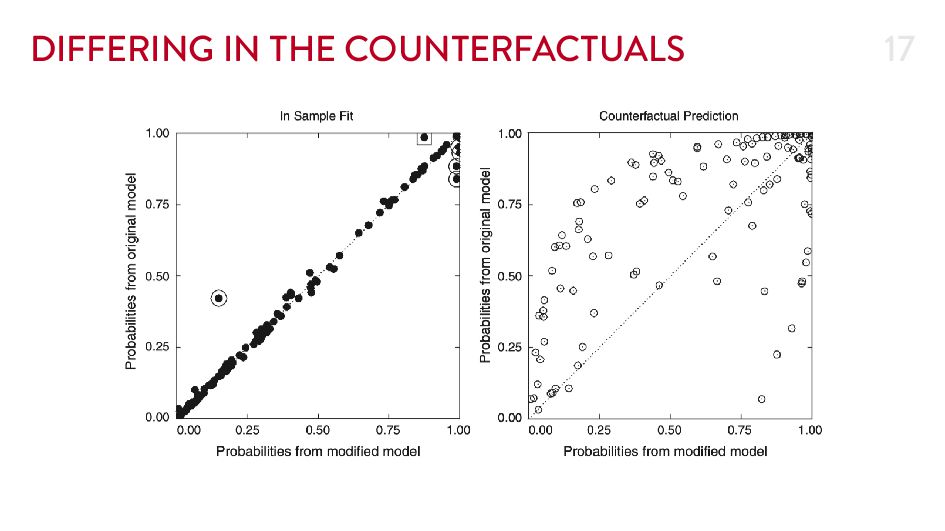{kind=link}
{kind=link}
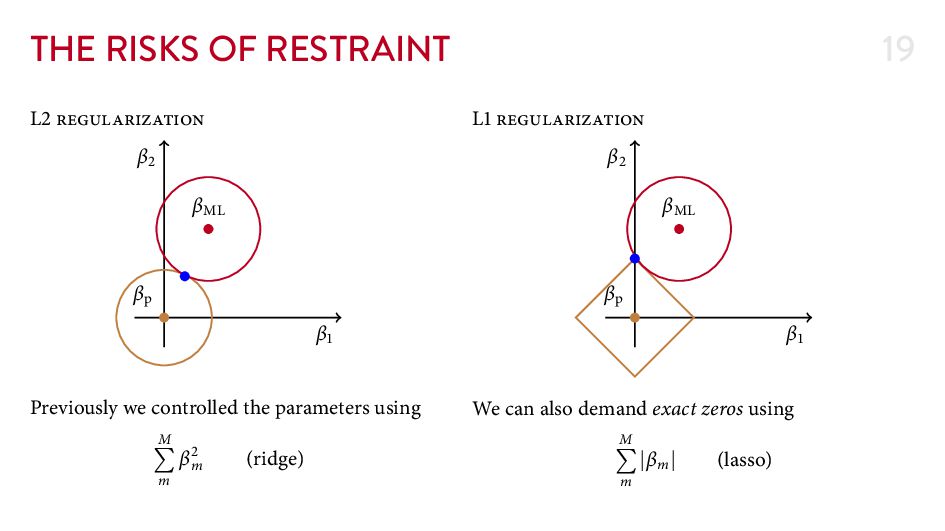{kind=link}
{kind=link}
{kind=link}
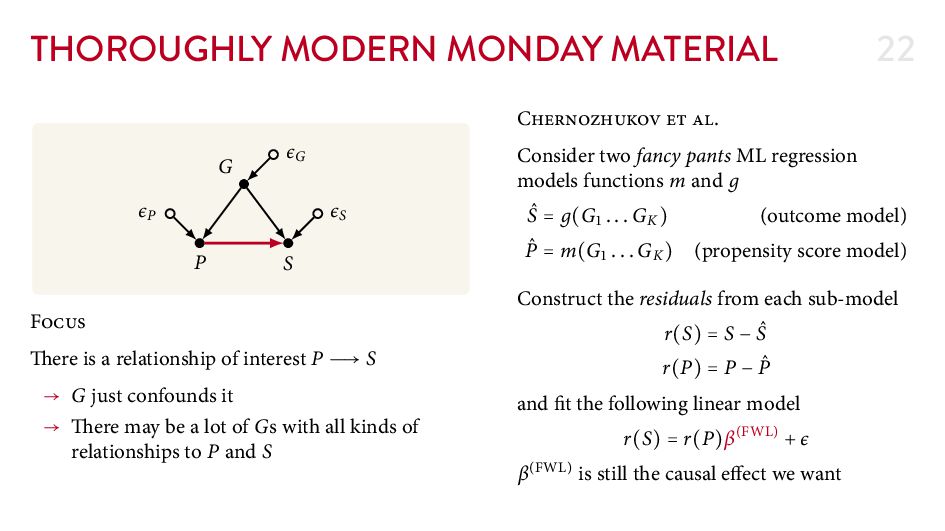{kind=link}
{kind=link}
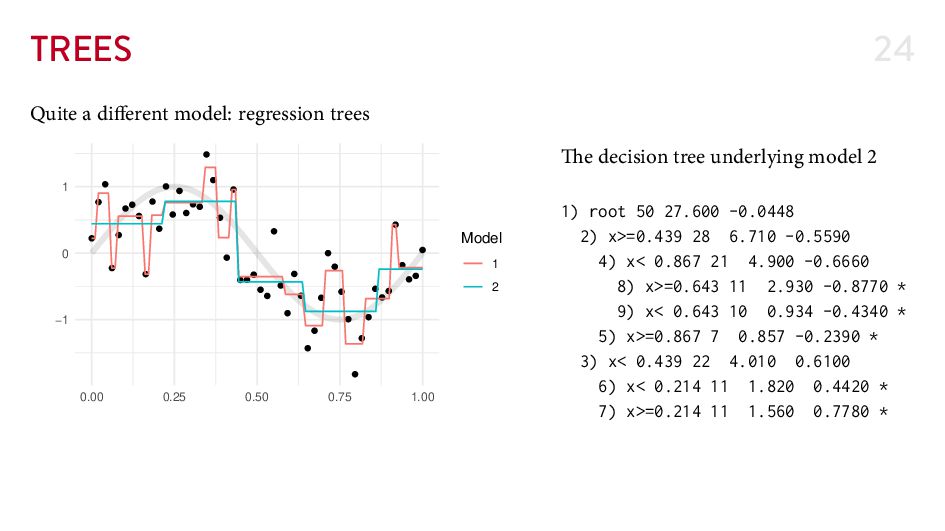{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}