information all the time Mine more == Collect more (and vice-‐versa) Challenges Application Complexities Data growth Infrastructure Economics Need of the day
information all the time Mine more == Collect more (and vice-‐versa) Challenges Application Complexities Data growth Infrastructure Economics
information all the time Mine more == Collect more (and vice-‐versa) Challenges Application Complexities Data growth Infrastructure Economics
information all the time Mine more == Collect more (and vice-‐versa) Challenges Application Complexities Data growth Infrastructure Economics
but complex problem to solve Data Growth Growth is exponential Infrastructure Availability Unscalable hardware Economics Managing high data volume comes at a price Failures are very costly
Inspired by Google’s white papers on Map/Reduce (MR), Google File System (GFS) Originally developed to support Apache Nutch Search Engine Software Framework -‐ Java Designed For sophisticated analysis To deal with structured and unstructured complex data
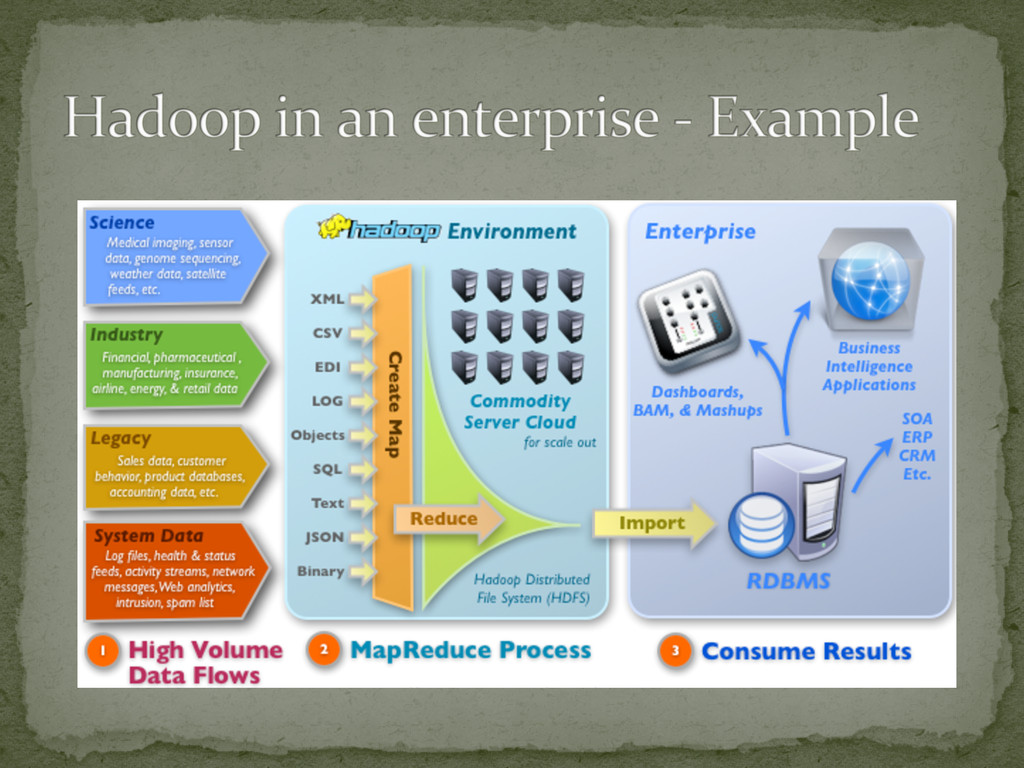
Scale hardware when ever you want System compensates for hardware scaling and issues (if any) Run large-‐scale, high volume data processes Scales well with complex analysis jobs Handles failures Ideal to consolidate data from both new and legacy data sources Value to the business
Map/Reduce Software framework for Clustered, Distributed data processing ZooKeeper Scheduler Avro Data Serialization Chukwa Data Collection System to monitor Distributed Systems HBase Data storage for distributed large tables Hive Data warehousing infrastructure Pig High-‐Level Query Language
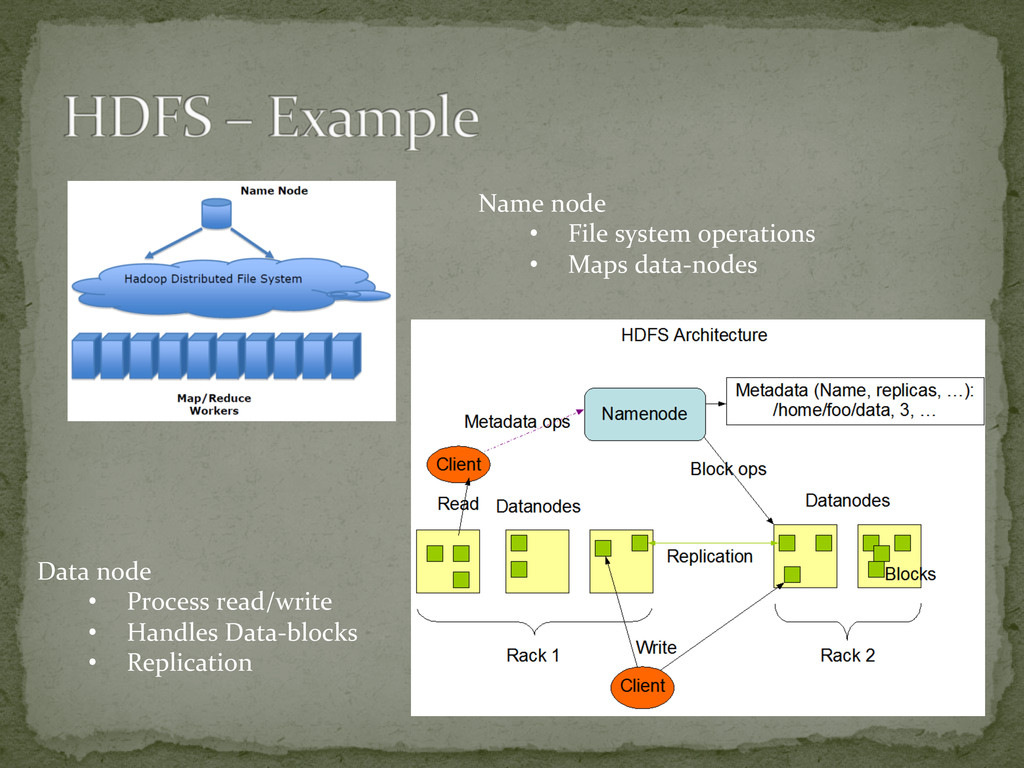
Fault Tolerant Handle large volumes of data Provides High Throughput Streaming data-‐access Simple file coherency model Portable to heterogeneous hardware and software Robust Handles disk failures, replication (& re-‐replication) Performs cluster rebalancing, data integrity checks
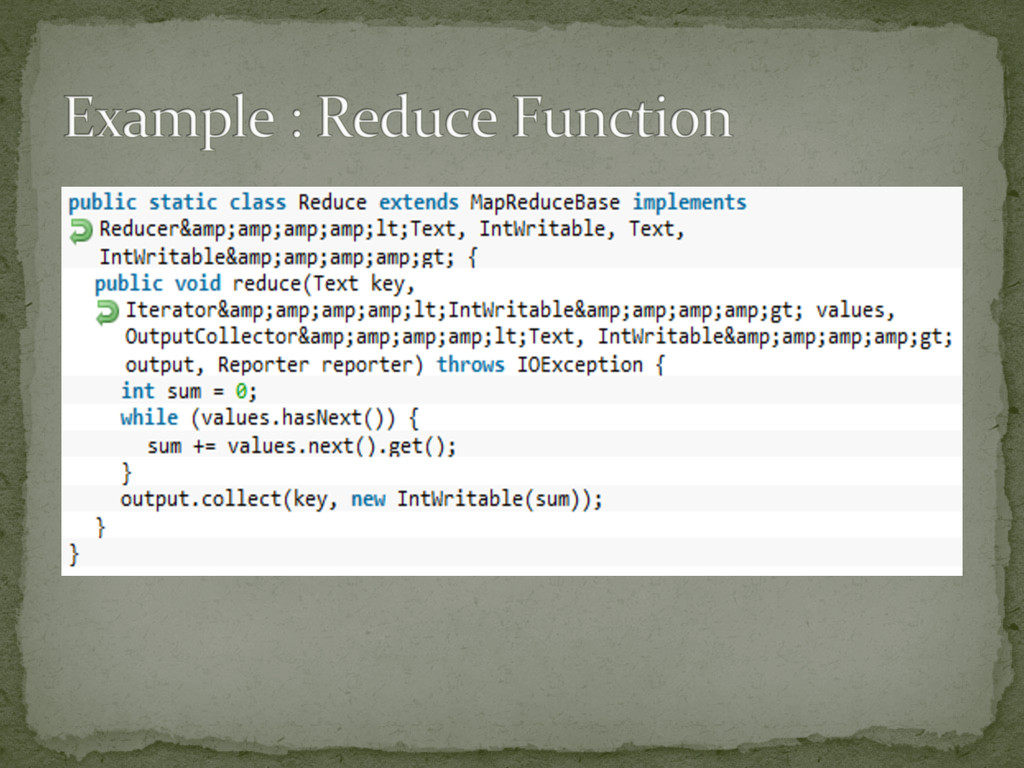
into separate chunk’s Processed by map tasks, in parallel Sorts the output of the maps Processed by reduce tasks, in parallel Typically stored and processed in a file system Framework takes care of Scheduling tasks Monitoring Re-‐executing failed tasks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}