Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Webスクレイピング
Search
株式会社Curious Vehicle
February 07, 2025
28
0
Share
Webスクレイピング
株式会社Curious Vehicle
February 07, 2025
More Decks by 株式会社Curious Vehicle
See All by 株式会社Curious Vehicle
PQCが変える暗号の世界
curicle
0
15
最近流行ってるClaudeについて
curicle
0
6
ElasticsearchのHA構成について
curicle
0
11
機械学習で絶対音感になりたかった
curicle
0
13
BQにおけるSQLアンチパターンとslot消費削減策
curicle
0
16
VibeKanbanについて
curicle
0
10
"バーチャル宮本さん"を作ってみた
curicle
0
8
"バーチャル宮本さん” 本番デプロイ編
curicle
0
14
最近課金しているAIサービスについて
curicle
0
15
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.1k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
370
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
1
170
Into the Great Unknown - MozCon
thekraken
40
2.3k
Thoughts on Productivity
jonyablonski
76
5.1k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
170
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
95
The Curious Case for Waylosing
cassininazir
0
290
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
170
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.3k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
68
38k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.1k
Transcript
第46回勉強会 Webスクレイピング 2019/06/25 安齋 佑司 1 — Curious Vehicle Confidential
—
もくじ • Webスクレイピングとは • 環境構成 • 処理概要 • 実行結果 •
まとめ 2 — Curious Vehicle Confidential —
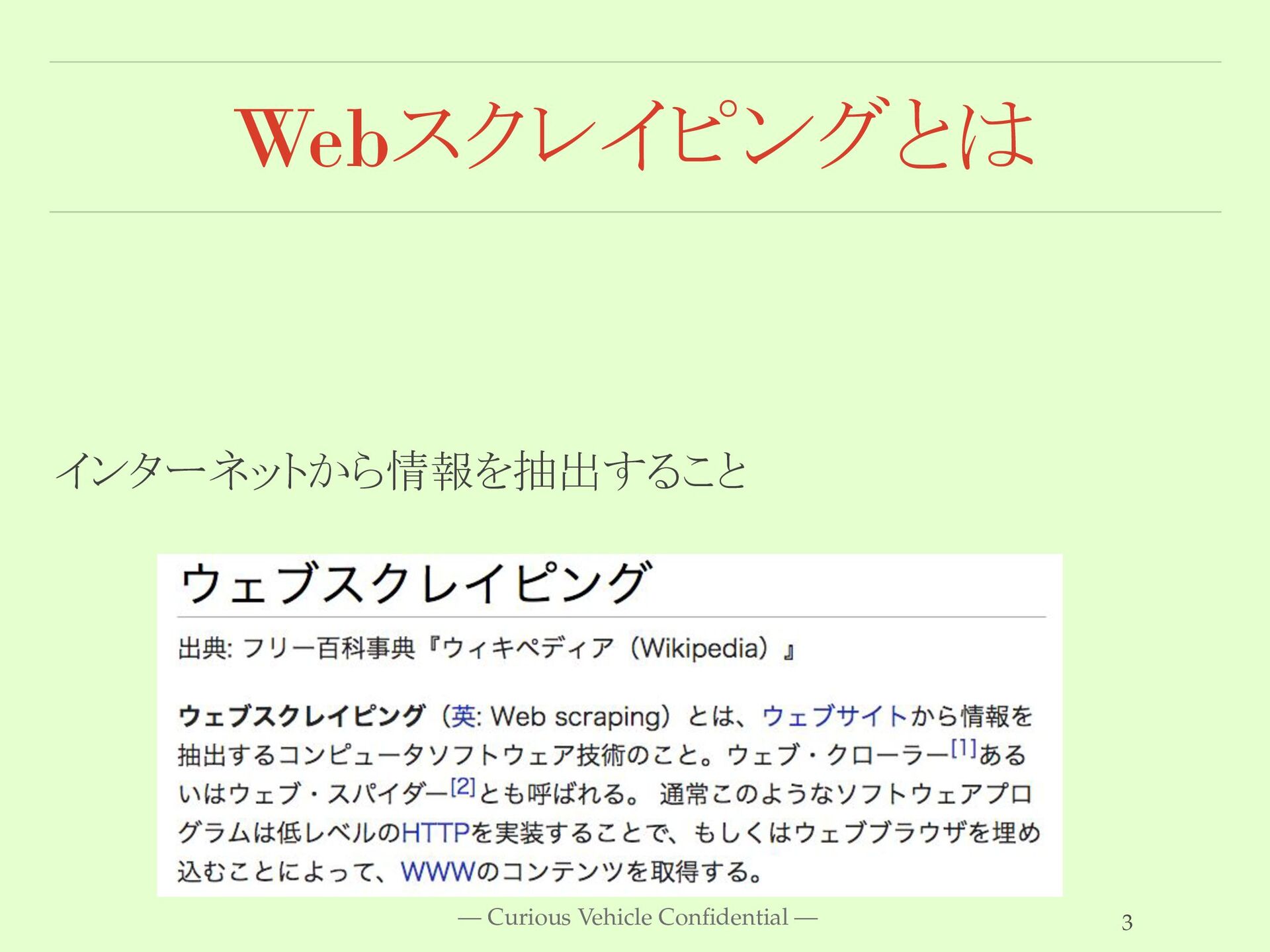
Webスクレイピングとは インターネットから情報を抽出すること — Curious Vehicle Confidential — 3
Webスクレイピングとは • 用途 1. 競合分析 2. データ補充 3. データマイニング —
Curious Vehicle Confidential — 4
Webスクレイピングとは • スクレイピングの流れ 1. Webクローリング 2. 抽出対象箇所の情報抽出 (ノイズを削除) 3. 整形
— Curious Vehicle Confidential — 5 今回は、ある目的でとあるWebサイトから情報を抽出したので その方法と結果を紹介します。
環境構成 1. インターネットに接続した端末 (クラウド推奨) 2. crawler4j (Java) 3. 整形用のスクリプト (Python)
4. 分析用ライブラリ (Python, gensim) — Curious Vehicle Confidential — 6 クローリングされたサイトからアクセスが遮断されても 影響が出ないようにクラウドからクローリングをかけている。 ※ サイト側からはDoSと見分けがつかないため。
処理概要 1. クローリング 2. 情報抽出 3. クレンジング 4. 分析 —
Curious Vehicle Confidential — 7
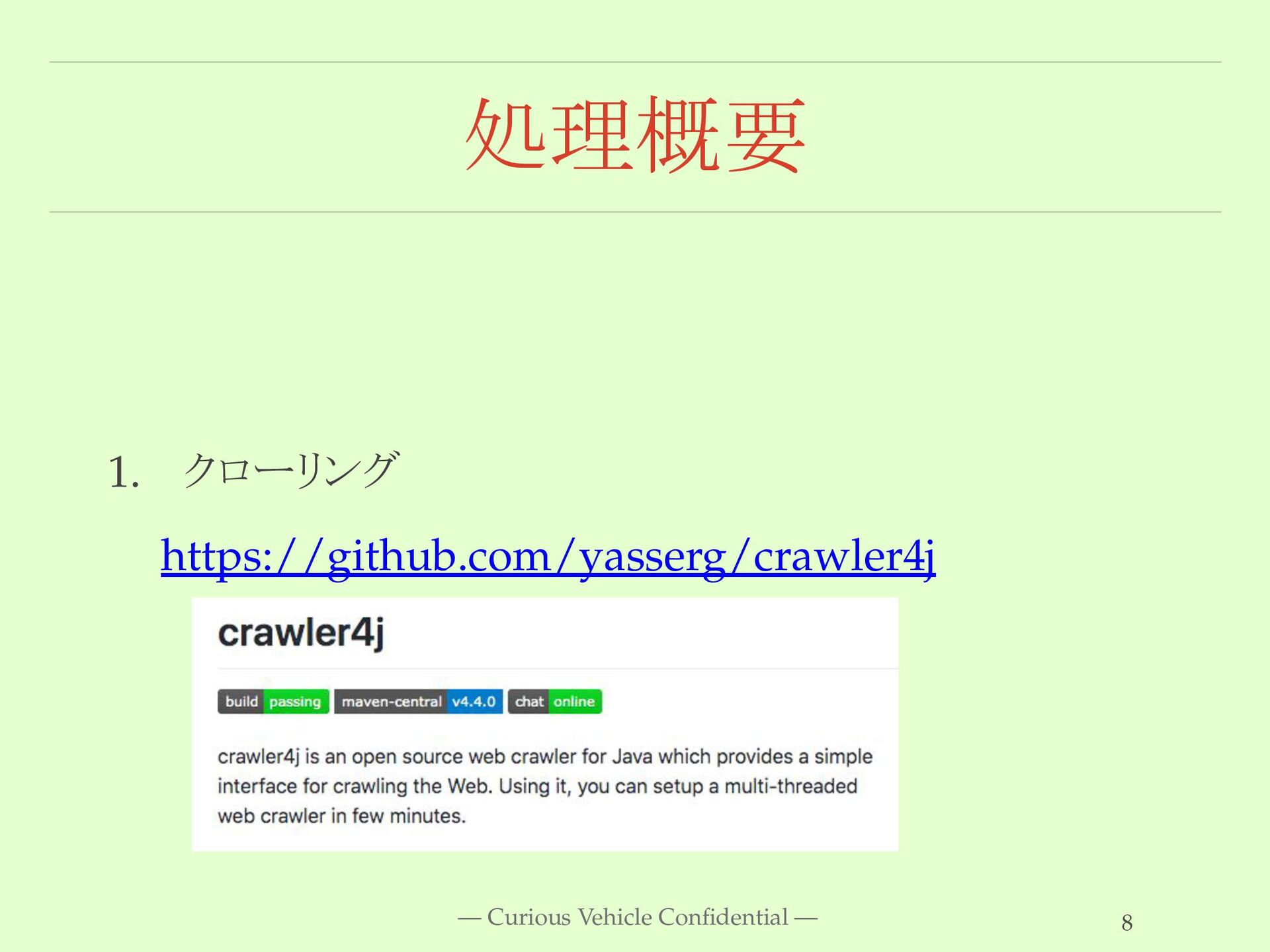
処理概要 1. クローリング https://github.com/yasserg/crawler4j — Curious Vehicle Confidential — 8
処理概要 — Curious Vehicle Confidential — 9 テキスト情報を取得するため More Examples
の Basic crawler を利用した
処理概要 — Curious Vehicle Confidential — 10 テキスト情報を取得するため More Examples
の Basic crawler を利用した
処理概要 — Curious Vehicle Confidential — 11 並列数、インターバル、階層の深さ、最大取得ページ数、URLを設定
処理概要 — Curious Vehicle Confidential — 12 フィルタ情報を設定し、ファイルに出力する処理を追記
処理概要 — Curious Vehicle Confidential — 13 Installation に従って pom.xml
を記述して Maven でビルド (面倒)
処理概要 — Curious Vehicle Confidential — 14 プログラムを実行して目的のページ数が取得されるまで待つ 1秒インターバル、4並列 *1ページ表示にかかる時間
→ 2万ページを取得するまで放置した。
処理概要 2. 情報抽出 — Curious Vehicle Confidential — 15 使わずにタグの文字列で当てに行った
処理概要 2. 情報抽出 — Curious Vehicle Confidential — 16
処理概要 3. クレンジング — Curious Vehicle Confidential — 17 英語以外の言語のページを除外
(2万 → 13270に減少) コンテンツに混ざっているHTMLタグを除外
処理概要 3. クレンジング — Curious Vehicle Confidential — 18 文章から特徴を抽出するために、以下の情報を削除
• Stop words • 前置詞、接続詞、代名詞、数詞 など 単語の正規化 • 複数形を単数形に寄せる • 原形に寄せる ※ この辺は vi マクロでコードを書いたが NLP系のライブラリを使えばよかった
処理概要 4. 分析 — Curious Vehicle Confidential — 19 各ページのトピックを
LDAで出力
処理概要 4. 分析 — Curious Vehicle Confidential — 20 全ページから
Word Count を出力
実行結果 — Curious Vehicle Confidential — 21 LDA 1コンテンツ1行でトピックを出力
実行結果 — Curious Vehicle Confidential — 22 Word Count 頻度順に出力
まとめ • WebスクレイピングはWeb上の資源を抽出できる • クローリングはサイトに迷惑をかけないように • 他の方法もあるので今回の方法が最善ではない • やってみると発見があるから面白い —
Curious Vehicle Confidential — 23
おしまい ご清聴ありがとうございました。 — Curious Vehicle Confidential — 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}