Presentation courtesy of Steve Lantz.
The recently introduced Intel Xeon Phi “Knights Landing” (KNL) is one of the most anticipated processors to enter the HPC market. With a design that puts a heavy emphasis on floating-point throughput, it is clearly targeted at the scientific computing community (and relatives). KNL has two big advantages: it is a full-fledged x86_64 processor, and it can be programmed in standard compiled languages such as C/C++ and Fortran. However, it takes some doing to realize the advertised performance.
For this meeting we will start with an overview of KNL’s unique features and their implications for programs. The presentation will be followed by a hands-on session with “Stampede Upgrade”, a cluster of 504 KNL nodes at the Texas Advanced Computing Center (TACC). The short exercises will illustrate the importance of vectorization in codes that will run well on current and future processor architectures.
Presented at SSW: https://cornell-ssw.github.io/meetings/2016-12-05
{kind=link}
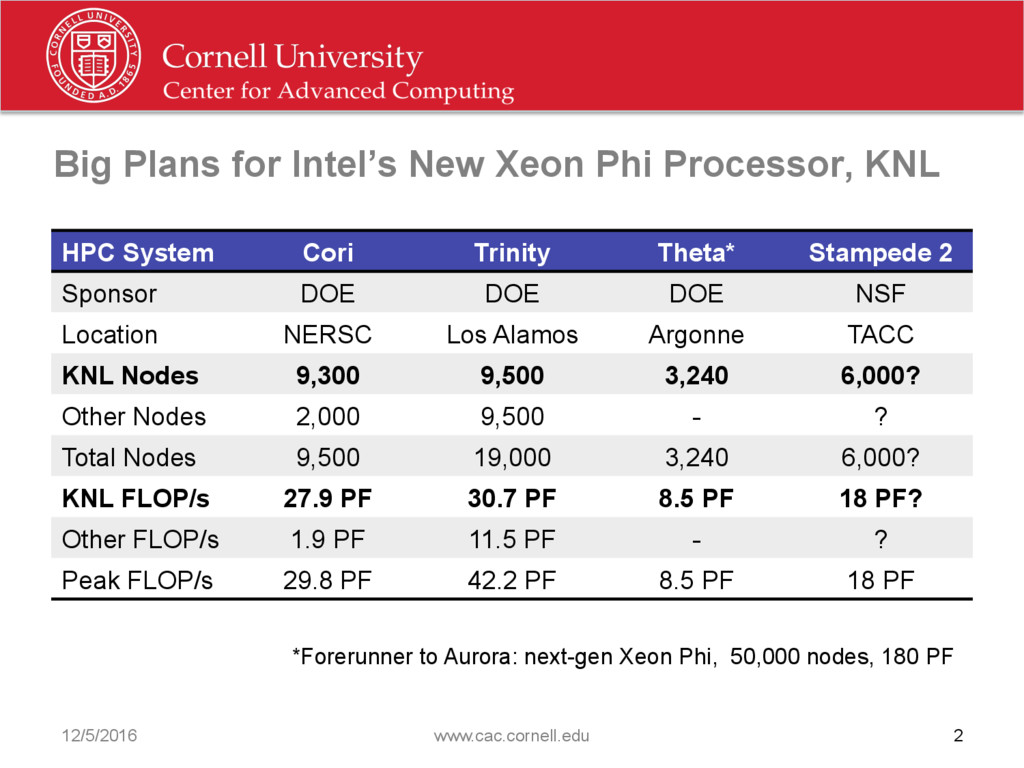{kind=link}
{kind=link}
{kind=link}
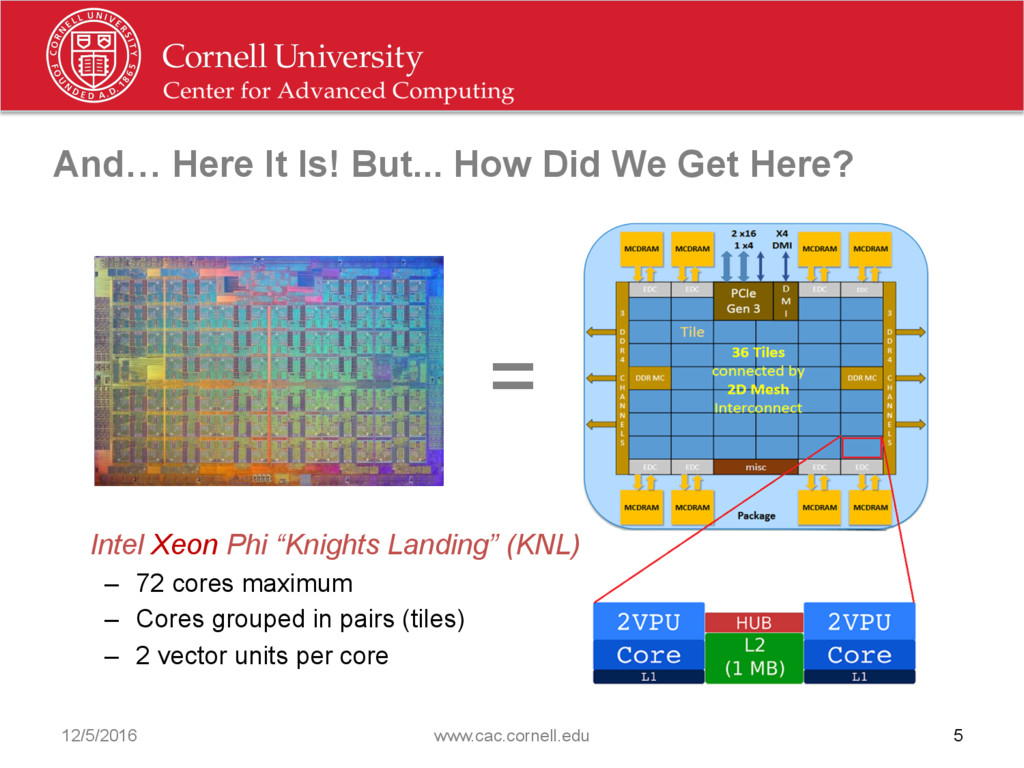{kind=link}
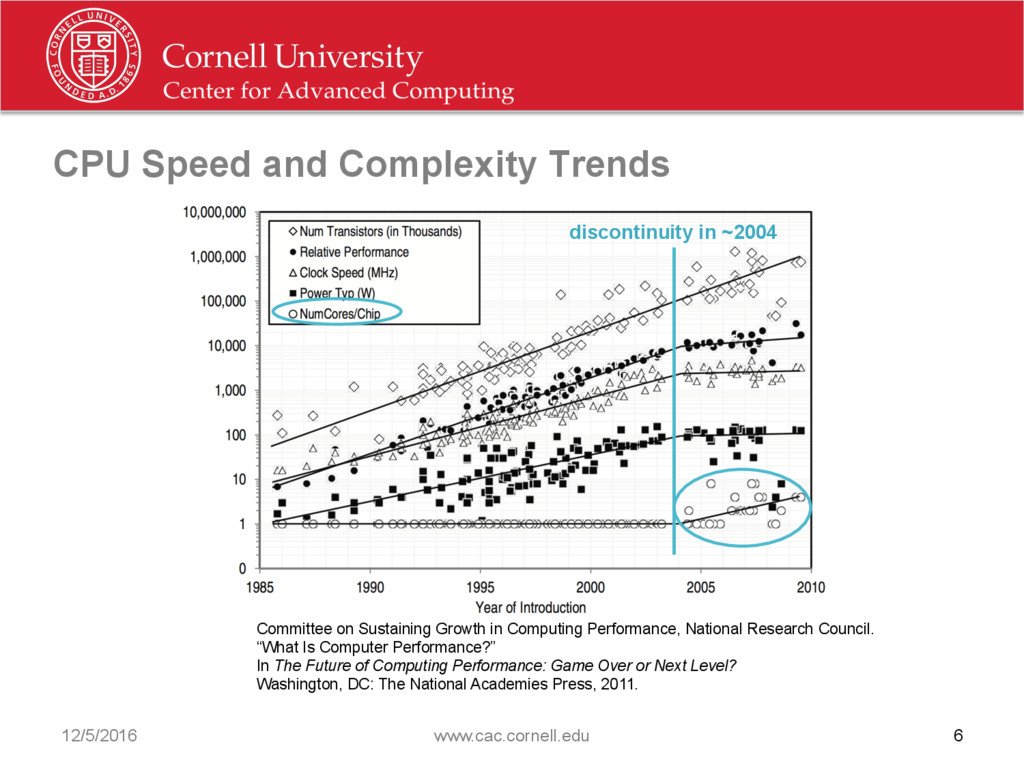{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
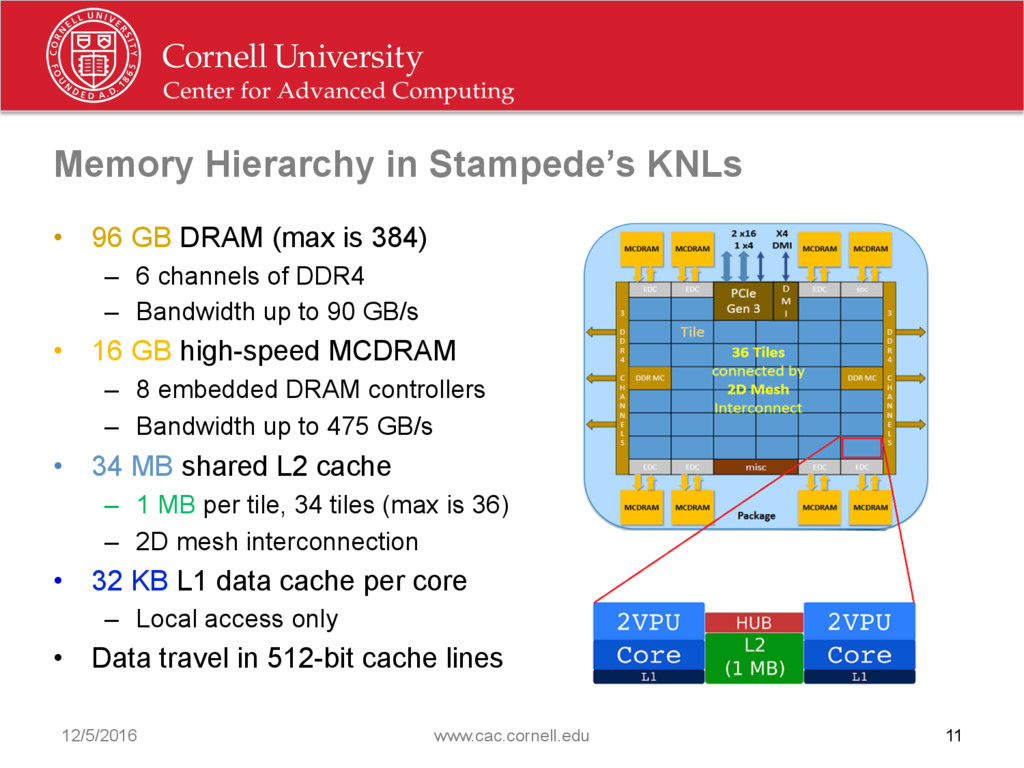{kind=link}
{kind=link}
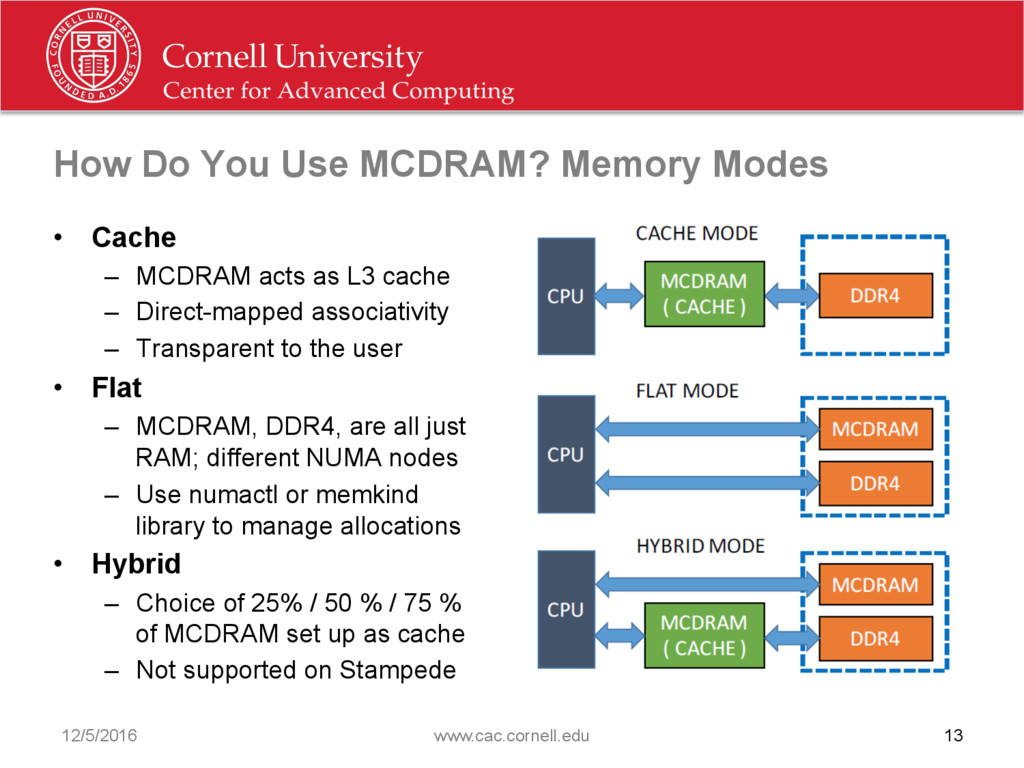{kind=link}
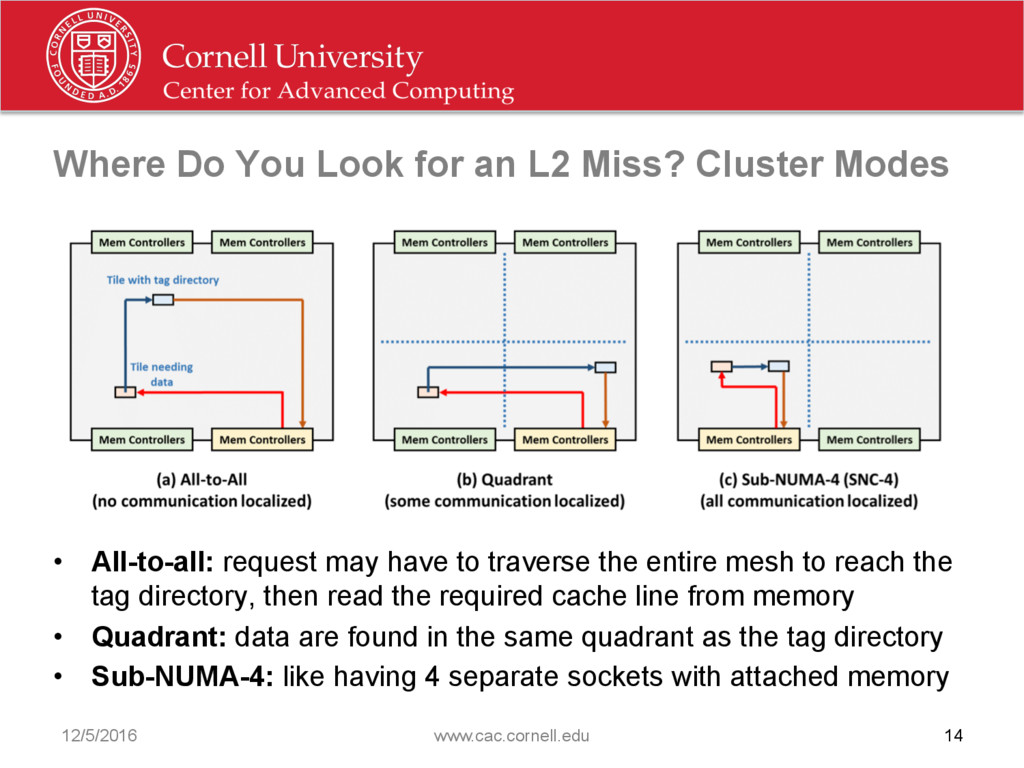{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}