Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ログ監視システムにおける時間ベース遅延の可視化 / Apache Kafka Meetup J...
Search
CyberAgent
PRO
April 09, 2019
Technology
2.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ログ監視システムにおける時間ベース遅延の可視化 / Apache Kafka Meetup Japan
4月9日開催
Apache Kafka Meetup Japan
ログ監視システムにおける時間ベース遅延の可視化
秋葉原ラボ:大平哲也
CyberAgent
PRO
April 09, 2019
More Decks by CyberAgent
See All by CyberAgent
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
Databricks 導入から Genie 活用まで、全部やった話
cyberagentdevelopers
PRO
0
840
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める「データの民主化」-
cyberagentdevelopers
PRO
0
500
「エンジニア進化論」2028年の開発完全自動化、エンジニアはどう進化するか
cyberagentdevelopers
PRO
9
8.9k
NAB Show 2026 動画技術関連レポート / NAB Show 2026 Report
cyberagentdevelopers
PRO
0
320
Local LLM Meetup #1 Opening
cyberagentdevelopers
PRO
0
440
LocalLLMで機密データを匿名化したい
cyberagentdevelopers
PRO
1
460
Vibe Fine-Tuning Version 2 — RunPod SSH で安く学習してみた
cyberagentdevelopers
PRO
0
430
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
cyberagentdevelopers
PRO
10
12k
Other Decks in Technology
See All in Technology
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
4
1.1k
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
270
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
440
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
140
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
220
Featured
See All Featured
Unsuck your backbone
ammeep
672
58k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Google's AI Overviews - The New Search
badams
0
1.1k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Done Done
chrislema
186
16k
New Earth Scene 8
popppiees
3
2.4k
The SEO Collaboration Effect
kristinabergwall1
1
510
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Navigating Team Friction
lara
192
16k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
ログ監視システムに おける時間ベース遅延の可視化 大平哲也
1. 自己紹介 2. 秋葉原ラボの紹介 3. オフセットを用いた遅延計測の問題点 4. 時間ベース遅延の可視化 5. オフセットの地点のデータ取得の高速化
6. 遅延の可視化 7. まとめ 発表の流れ
大平 哲也 (おおだいら てつや) 内定者期間中に秋葉原ラボでログ遅延監視ツールの開発 今年度入社。只今研修中 最近興味のある分野:ストリーム処理、Dataflow、進化計算 趣味:コーヒー、自転車、電子工作 自己紹介 だいら
@tdaira_
「データを活用」してサービスと会社の発展に寄与する 秋葉原ラボについて
サイバーエージェントで扱うサービス
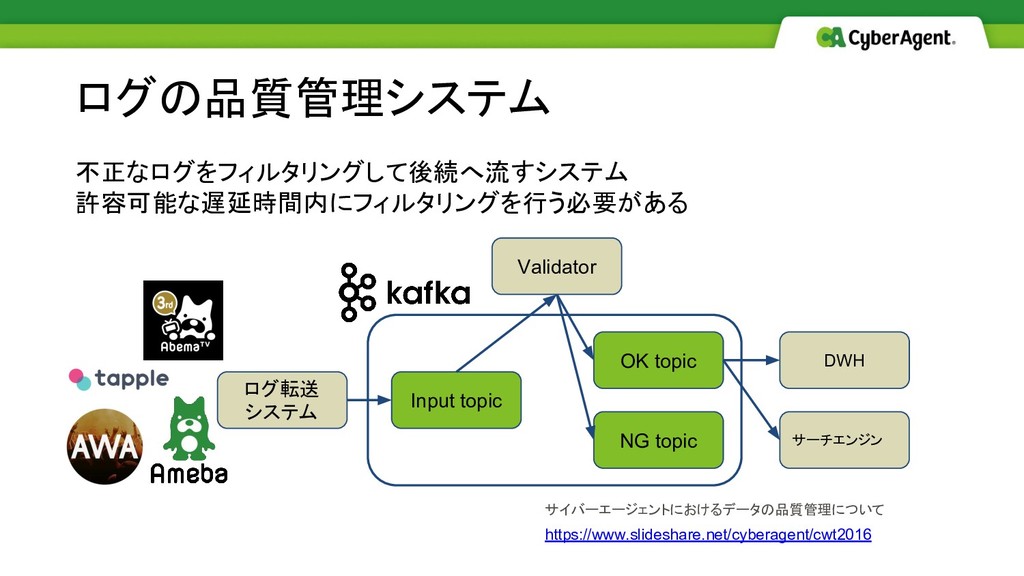
不正なログをフィルタリングして後続へ流すシステム 許容可能な遅延時間内にフィルタリングを行う必要がある ログの品質管理システム Input topic NG topic OK topic Validator
ログ転送 システム DWH サーチエンジン サイバーエージェントにおけるデータの品質管理について https://www.slideshare.net/cyberagent/cwt2016
KafkaのOffsetの管理 パーティション Offsetによりどこまで各 Consumerが値を読み 取ったかが管理されて いる Offsetの遅延 [Lag] = [最新レコードのOffset]
- [ConsumerのOffset] Consumer Aのラグ [Lag] = 12 - 9 = 3 Consumer Bのラグ [Lag] = 12 - 11 = 1
オフセットはKafkaのコマンドラインツールやkafka-manager等の 監視ツールで確認することができる オフセットの確認作業 Consumerの Offset 最新レコードの Offset Offsetの遅延
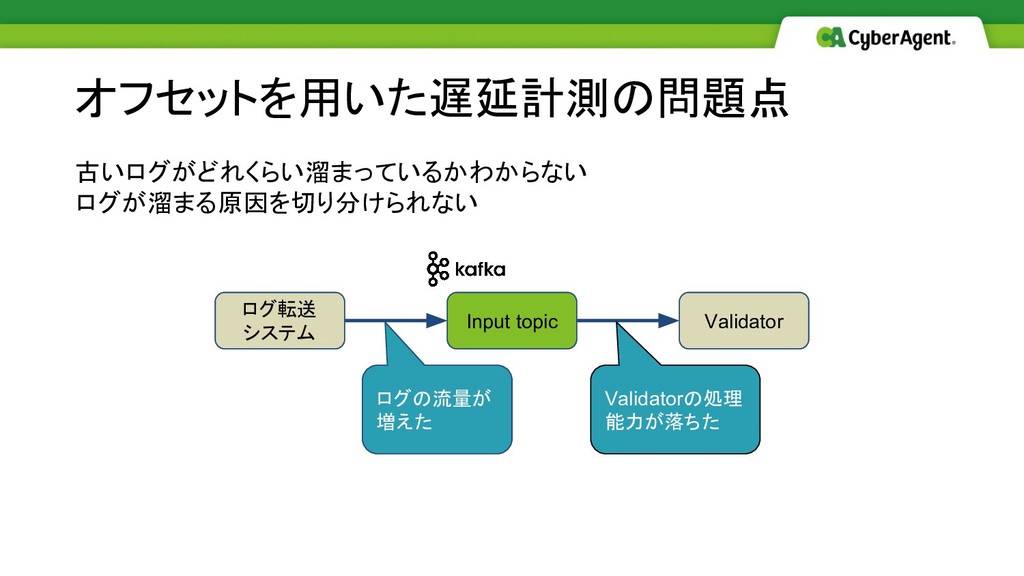
古いログがどれくらい溜まっているかわからない ログが溜まる原因を切り分けられない オフセットを用いた遅延計測の問題点 Input topic Validator ログ転送 システム ログの流量が 増えた
Validatorの処理 能力が落ちた
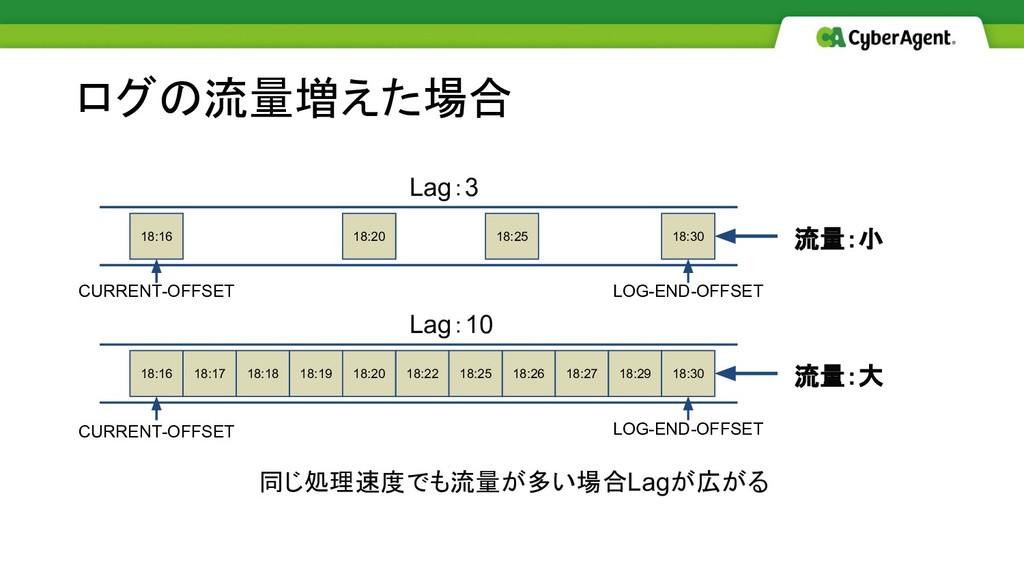
ログの流量増えた場合 18:16 18:20 18:25 18:30 18:16 18:17 18:18 18:19 18:26
18:27 18:29 18:30 18:20 18:22 18:25 流量:大 流量:小 同じ処理速度でも流量が多い場合Lagが広がる CURRENT-OFFSET Lag:3 Lag:10 CURRENT-OFFSET LOG-END-OFFSET LOG-END-OFFSET
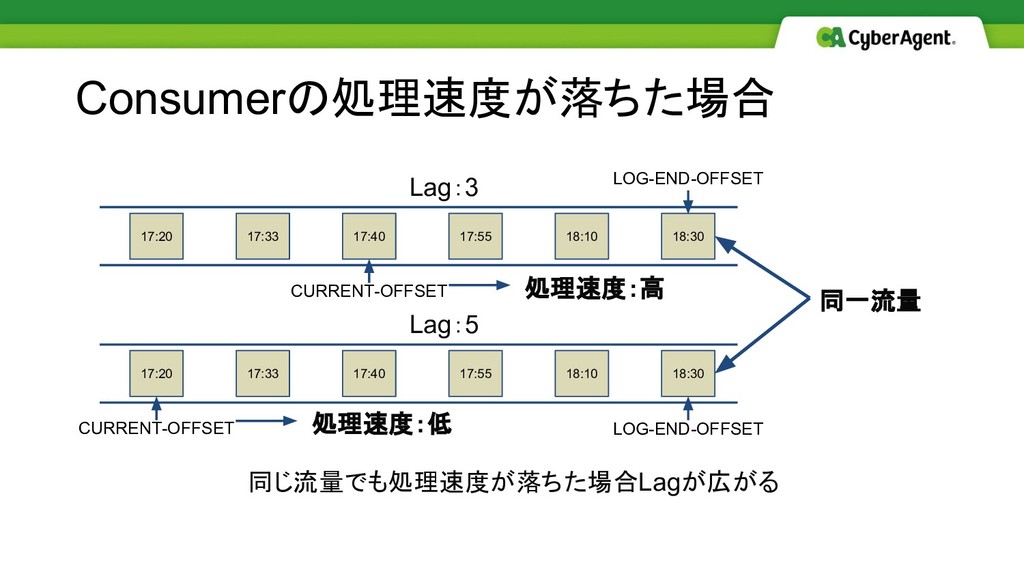
Consumerの処理速度が落ちた場合 17:20 17:33 18:10 18:30 17:40 17:55 同一流量 同じ流量でも処理速度が落ちた場合Lagが広がる 17:20
17:33 18:10 18:30 17:40 17:55 処理速度:低 処理速度:高 Lag:3 Lag:5 CURRENT-OFFSET CURRENT-OFFSET LOG-END-OFFSET LOG-END-OFFSET
• 経験則でオフセットの遅延から遅延時刻を推定 • メッセージを手動で取得し、タイムスタンプを一つずつ確認 遅延への対応 時間ベースでログの遅延を監視したい
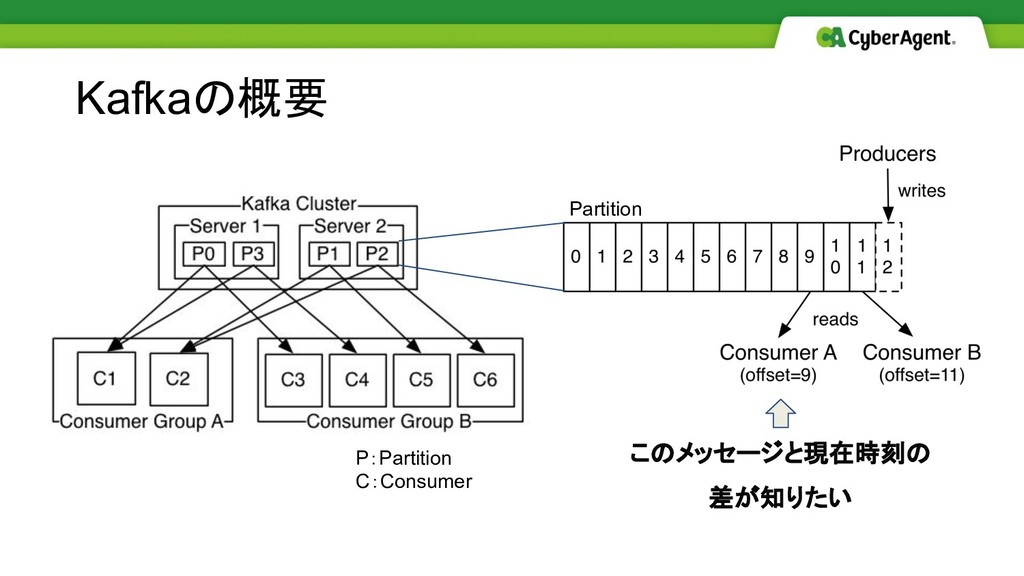
Kafkaの概要 このメッセージと現在時刻の 差が知りたい P:Partition C:Consumer Partition
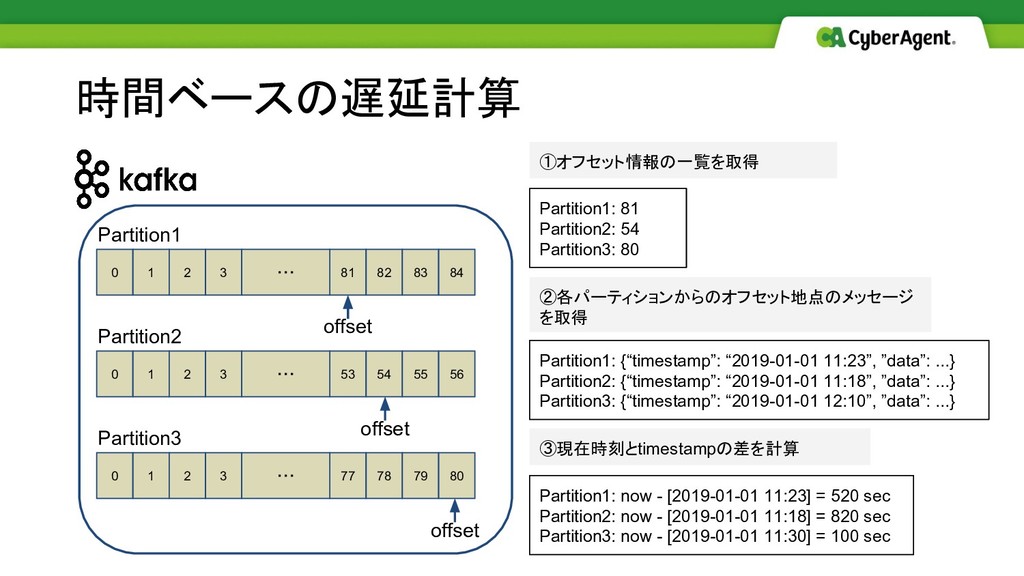
時間ベースの遅延計算 ①オフセット情報の一覧を取得 ②各パーティションからのオフセット地点のメッセージ を取得 ③現在時刻とtimestampの差を計算 0 1 2 3 81
82 ・・・ 83 84 0 1 2 3 53 54 ・・・ 55 56 0 1 2 3 77 78 ・・・ 79 80 offset offset offset Partition1 Partition2 Partition3 Partition1: 81 Partition2: 54 Partition3: 80 Partition1: {“timestamp”: “2019-01-01 11:23”, ”data”: ...} Partition2: {“timestamp”: “2019-01-01 11:18”, ”data”: ...} Partition3: {“timestamp”: “2019-01-01 12:10”, ”data”: ...} Partition1: now - [2019-01-01 11:23] = 520 sec Partition2: now - [2019-01-01 11:18] = 820 sec Partition3: now - [2019-01-01 11:30] = 100 sec
Consumerグループ一覧の問い合わせ ↓ Consumerグループが読んでいるパーティションの取り出し ↓ パーティションのOffsetを問い合わせ ↓ パーティションにメッセージを問い合わせ ↓ メッセージからタイムスタンプを取りだして遅延を計算 ↓
一覧にして出力 プログラム上の処理の流れ
実行結果はConsumerGroupのパーティションごとに出力 実行結果 > sbt “runMain command.LagReaderCommand -b [boot-strap-server] -c consumer_group"
ConsumerGroup TopicPartition Lag consumer_group 0 10sec consumer_group 1 45sec consumer_group 2 15sec 最終的にこれを全パーティション分取得して監視したい
一つ一つのパーティションを順番に読んでいくと データの取り出しに時間がかかる (パーティション数が100程度のstg環境で17分) 実行時間の問題点 複数パーティションから同時購読を行い高速化
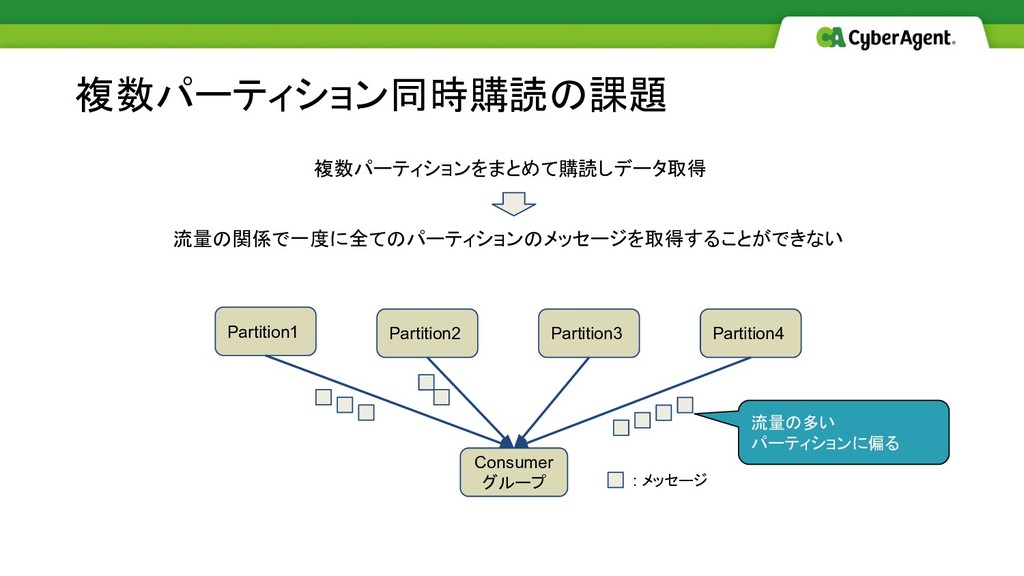
複数パーティションをまとめて購読しデータ取得 流量の関係で一度に全てのパーティションのメッセージを取得することができない 複数パーティション同時購読の課題 Partition1 Partition2 Partition3 Partition4 Consumer グループ :
メッセージ 流量の多い パーティションに偏る
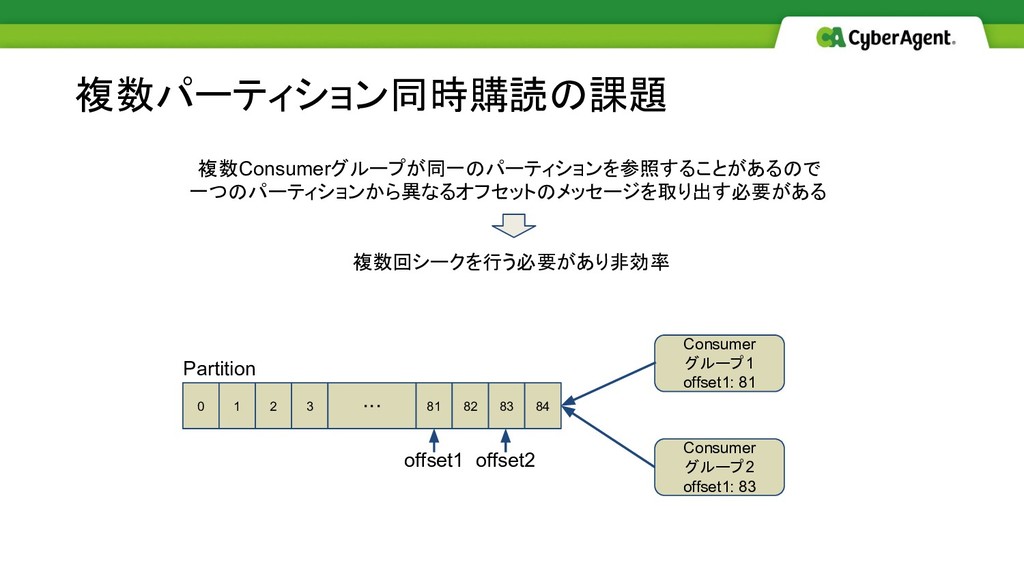
複数Consumerグループが同一のパーティションを参照することがあるので 一つのパーティションから異なるオフセットのメッセージを取り出す必要がある 複数回シークを行う必要があり非効率 複数パーティション同時購読の課題 0 1 2 3 81 82
・・・ 83 84 offset1 Partition offset2 Consumer グループ1 offset1: 81 Consumer グループ2 offset1: 83
Consumerグループ一覧の問い合わせ ↓ Consumerが読んでいるパーティションの取り出し ↓ パーティションのOffsetを問い合わせ ↓ パーティションにメッセージを問い合わせ ↓ メッセージからタイムスタンプを取りだして遅延を計算 ↓
一覧にして出力 プログラム上の処理の流れ(修正前)
Consumerグループ一覧の問い合わせ ↓ Consumerが読んでいるパーティションの取り出し ↓ パーティションのOffsetを問い合わせ ↓ Offsetの重複排除 ↓ パーティションに並列に問い合わせ ↓
メッセージを取得できなかったパーティションがないか確認 ↓ メッセージからタイムスタンプを取りだして遅延を計算 ↓ 一覧にして出力 プログラム上の処理の流れ(修正後)
Consumerグループ2 - Topic1 Partition1: 100 - Topic2 Partition1: 150 -
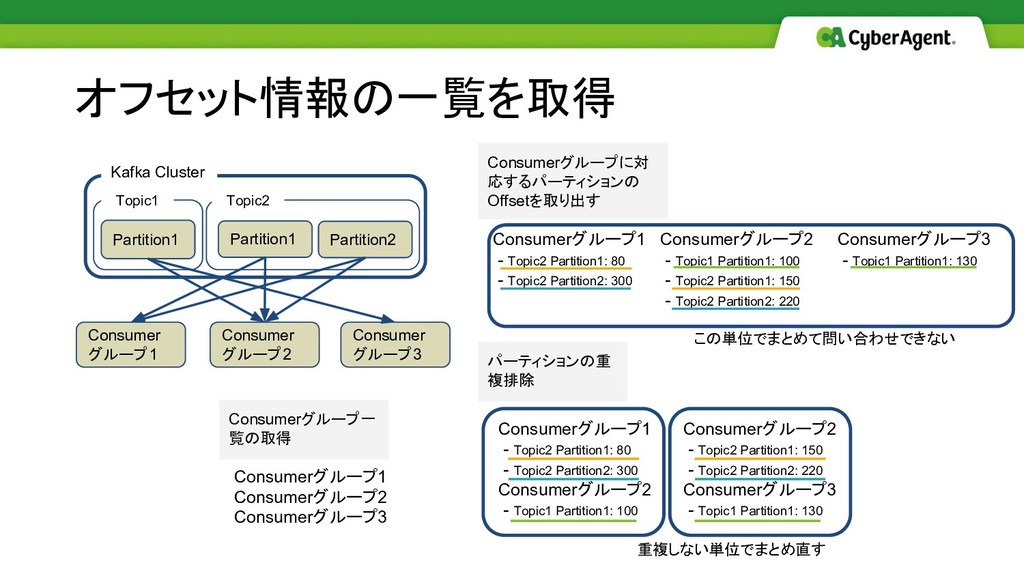
Topic2 Partition2: 220 Consumerグループ1 - Topic2 Partition1: 80 - Topic2 Partition2: 300 Consumerグループ3 - Topic1 Partition1: 130 オフセット情報の一覧を取得 この単位でまとめて問い合わせできない Partition1 Partition1 Partition2 Consumer グループ2 Consumer グループ1 Kafka Cluster Consumerグループ一 覧の取得 Consumerグループに対 応するパーティションの Offsetを取り出す パーティションの重 複排除 Consumerグループ1 Consumerグループ2 Consumerグループ3 Consumerグループ2 - Topic2 Partition1: 150 - Topic2 Partition2: 220 Consumerグループ3 - Topic1 Partition1: 130 Consumerグループ1 - Topic2 Partition1: 80 - Topic2 Partition2: 300 Consumerグループ2 - Topic1 Partition1: 100 重複しない単位でまとめ直す Consumer グループ3 Topic2 Topic1
Consumerグループ一覧の問い合わせ ↓ Consumerが読んでいるパーティションの取り出し ↓ パーティションのOffsetを問い合わせ ↓ Offsetの重複排除 ↓ パーティションに並列に問い合わせ ↓
メッセージを取得できなかったパーティションがないか確認 ↓ メッセージからタイムスタンプを取りだして遅延を計算 ↓ 一覧にして出力 プログラム上の処理の流れ(修正後)
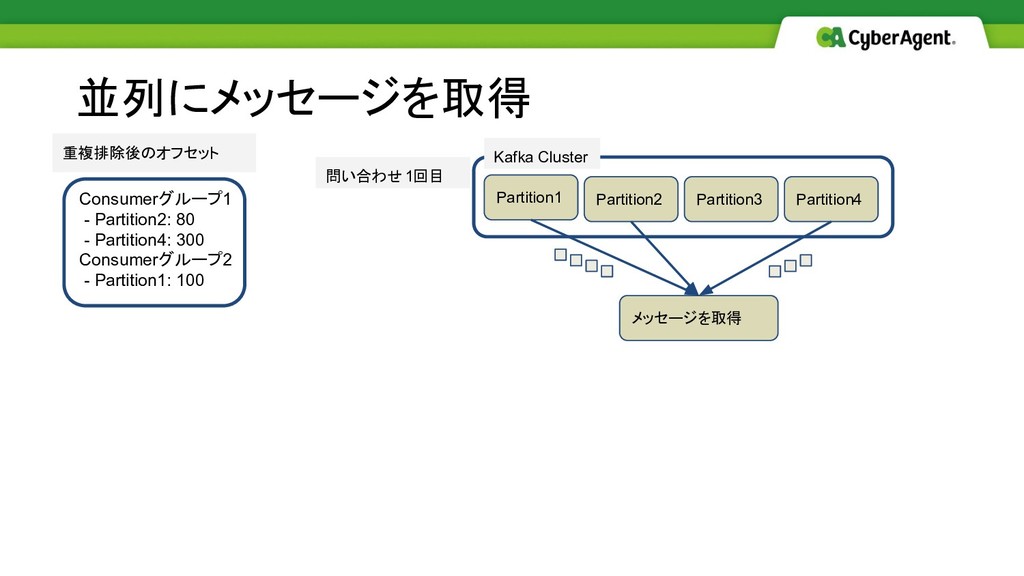
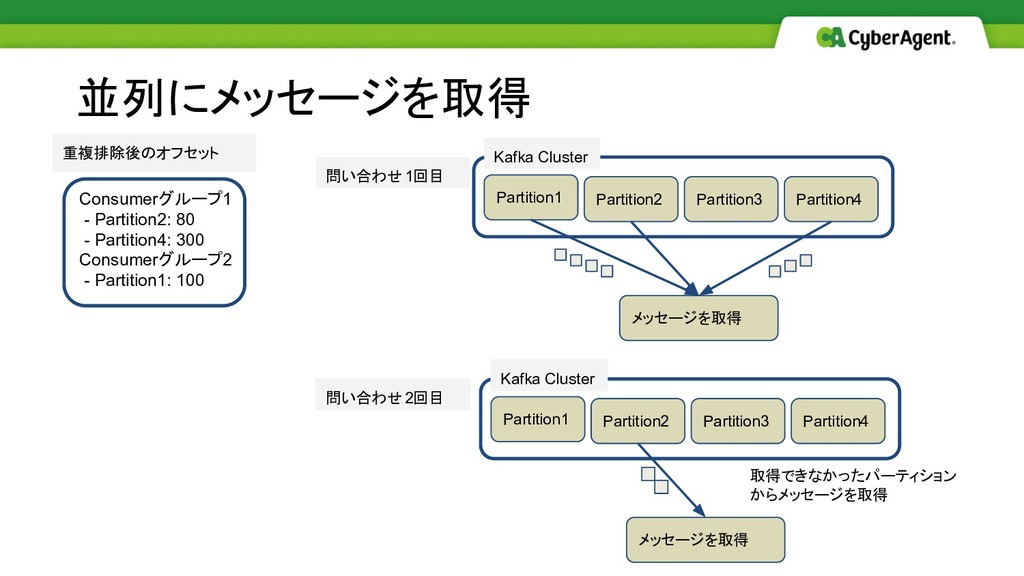
並列にメッセージを取得 重複排除後のオフセット Consumerグループ1 - Partition2: 80 - Partition4: 300 Consumerグループ2
- Partition1: 100 Partition1 Partition2 Partition3 Partition4 メッセージを取得 Kafka Cluster 問い合わせ1回目 Partition1 Partition2 Partition3 Partition4 メッセージを取得 Kafka Cluster 問い合わせ2回目 取得できなかったパーティション からメッセージを取得
並列にメッセージを取得 重複排除後のオフセット Consumerグループ1 - Partition2: 80 - Partition4: 300 Consumerグループ2
- Partition1: 100 Partition1 Partition2 Partition3 Partition4 メッセージを取得 Kafka Cluster 問い合わせ1回目 Partition1 Partition2 Partition3 Partition4 メッセージを取得 Kafka Cluster 問い合わせ2回目 取得できなかったパーティション からメッセージを取得
7分半→1分半へ高速化 比率にすると1/5程度の時間に短縮 1分半ほどの実行時間であれば常時回しておけば遅延監視には十分な速度 高速化結果
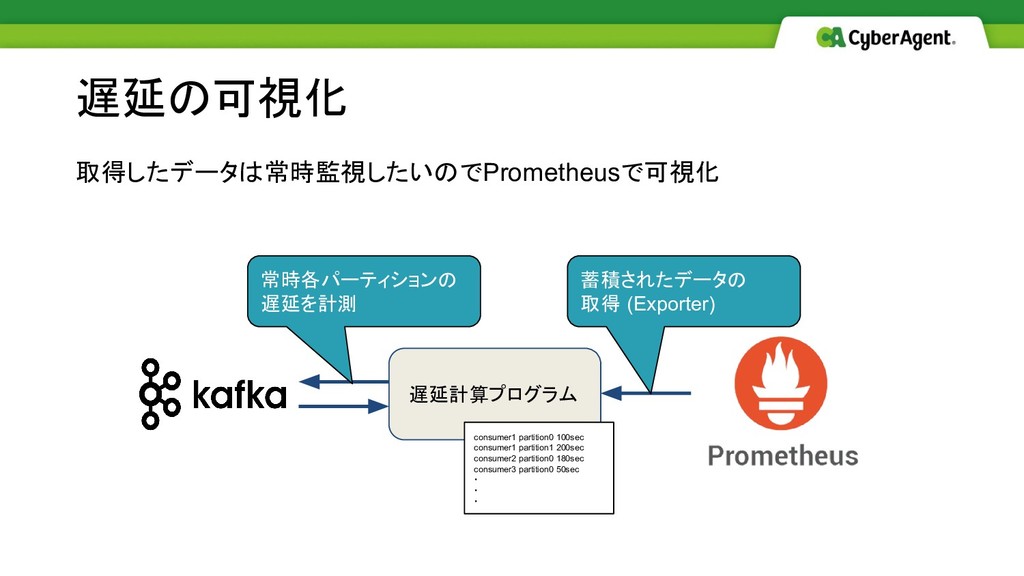
取得したデータは常時監視したいのでPrometheusで可視化 遅延の可視化 遅延計算プログラム 常時各パーティションの 遅延を計測 蓄積されたデータの 取得 (Exporter) consumer1 partition0
100sec consumer1 partition1 200sec consumer2 partition0 180sec consumer3 partition0 50sec ・ ・ ・
Prometheusの画面 オフセットベース 時間ベース 時刻 ログのオフセット ログの遅延時間 最大の遅延は 23時35分の70万 最大の遅延は 0時0分の25分
時刻 オフセットベースで遅延が広がったタイミングよりもあとで、時間ベースでの遅延が広がっている
• 時間ベースの遅延を可視化 • 複数パーティションの同時購読より遅延取得を高速化 • Prometheusで常時遅延の監視を実現 まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![KafkaのOffsetの管理 パーティション Offsetによりどこまで各 Consumerが値を読み 取ったかが管理されて いる Offsetの遅延 [Lag] = [最新レコードのOffset]](https://files.speakerdeck.com/presentations/9cab5c32364347dd93bd496a60b0bc69/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実行結果はConsumerGroupのパーティションごとに出力 実行結果 > sbt “runMain command.LagReaderCommand -b [boot-strap-server] -c consumer_group"](https://files.speakerdeck.com/presentations/9cab5c32364347dd93bd496a60b0bc69/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}