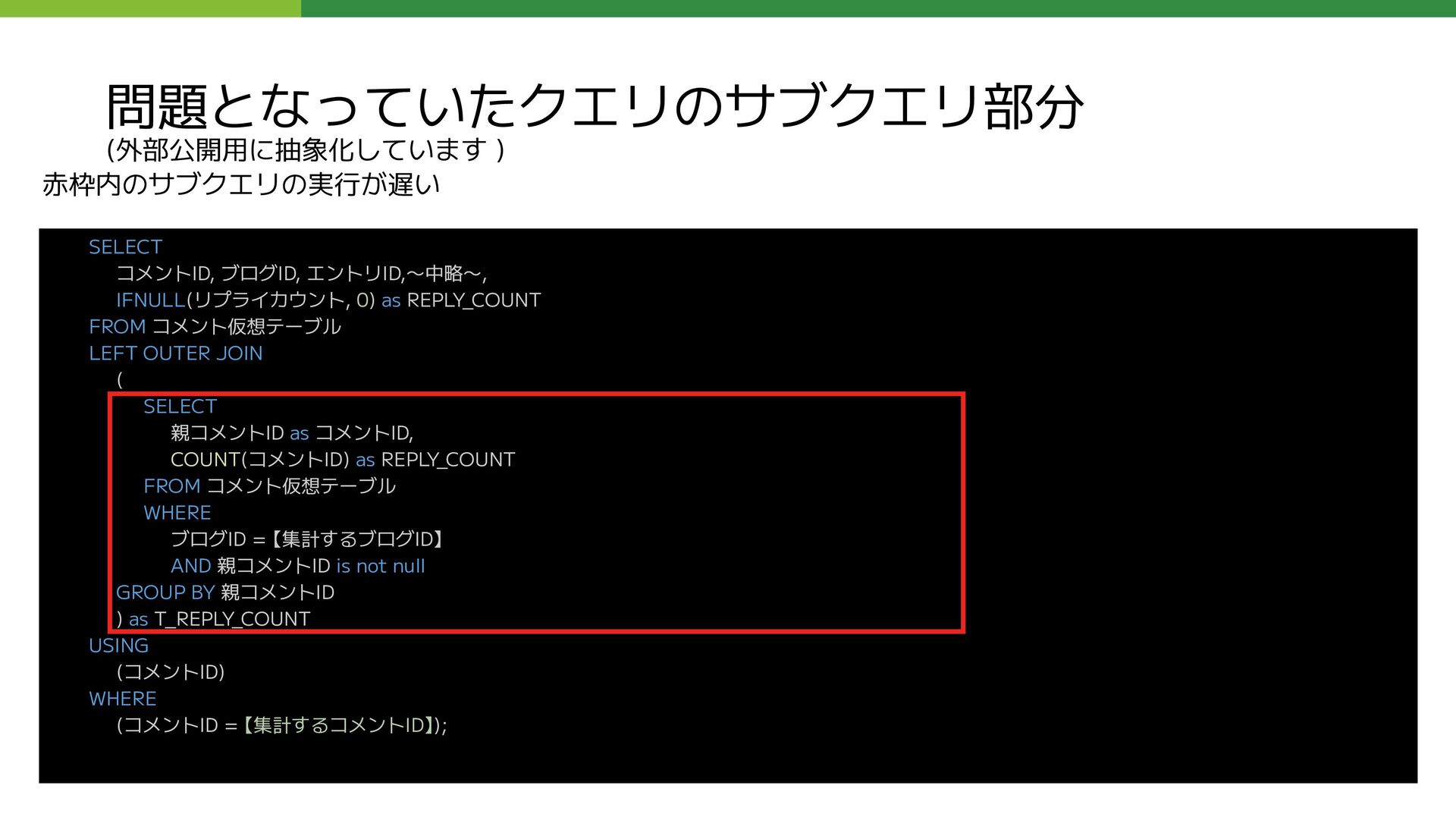
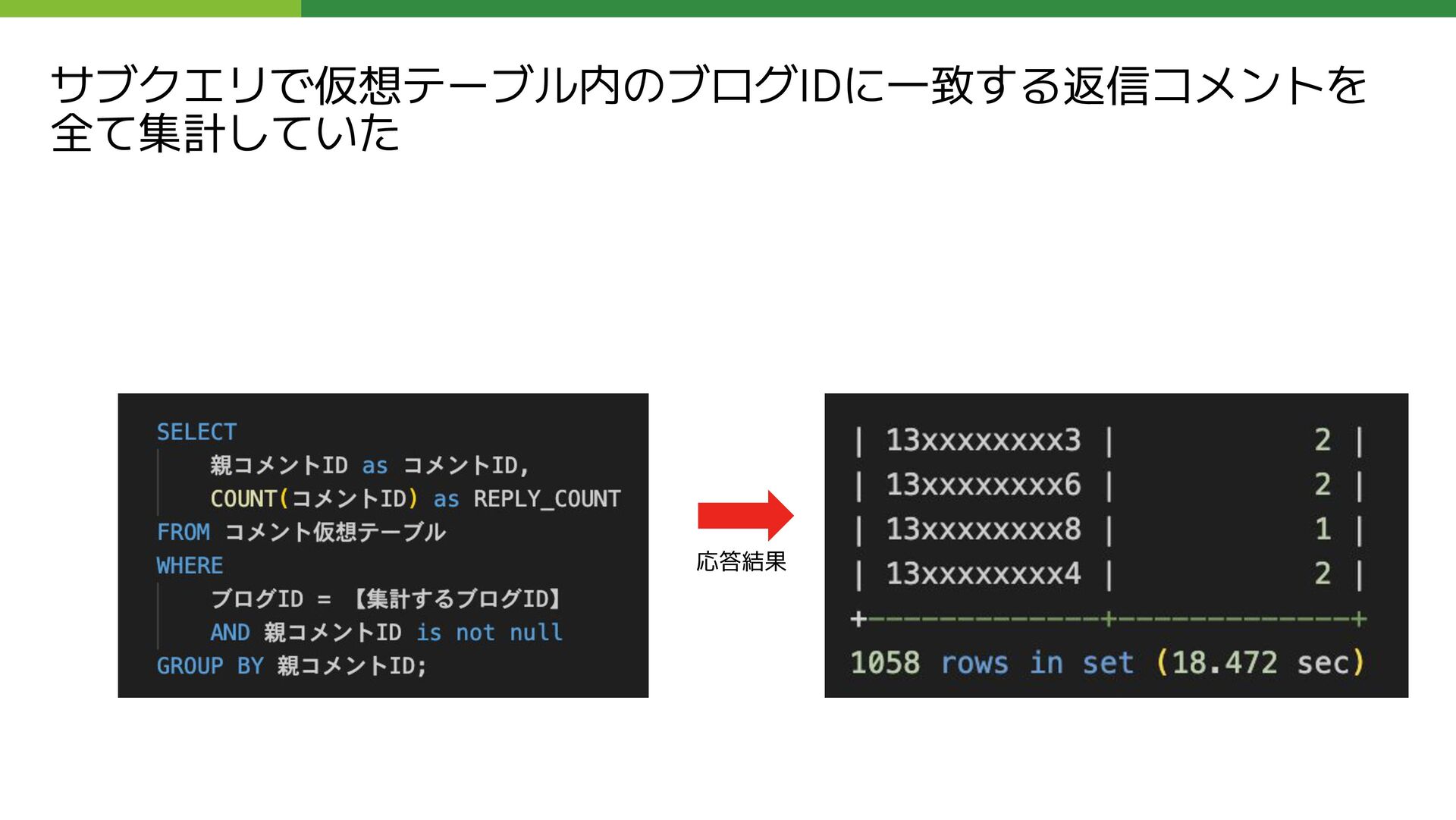
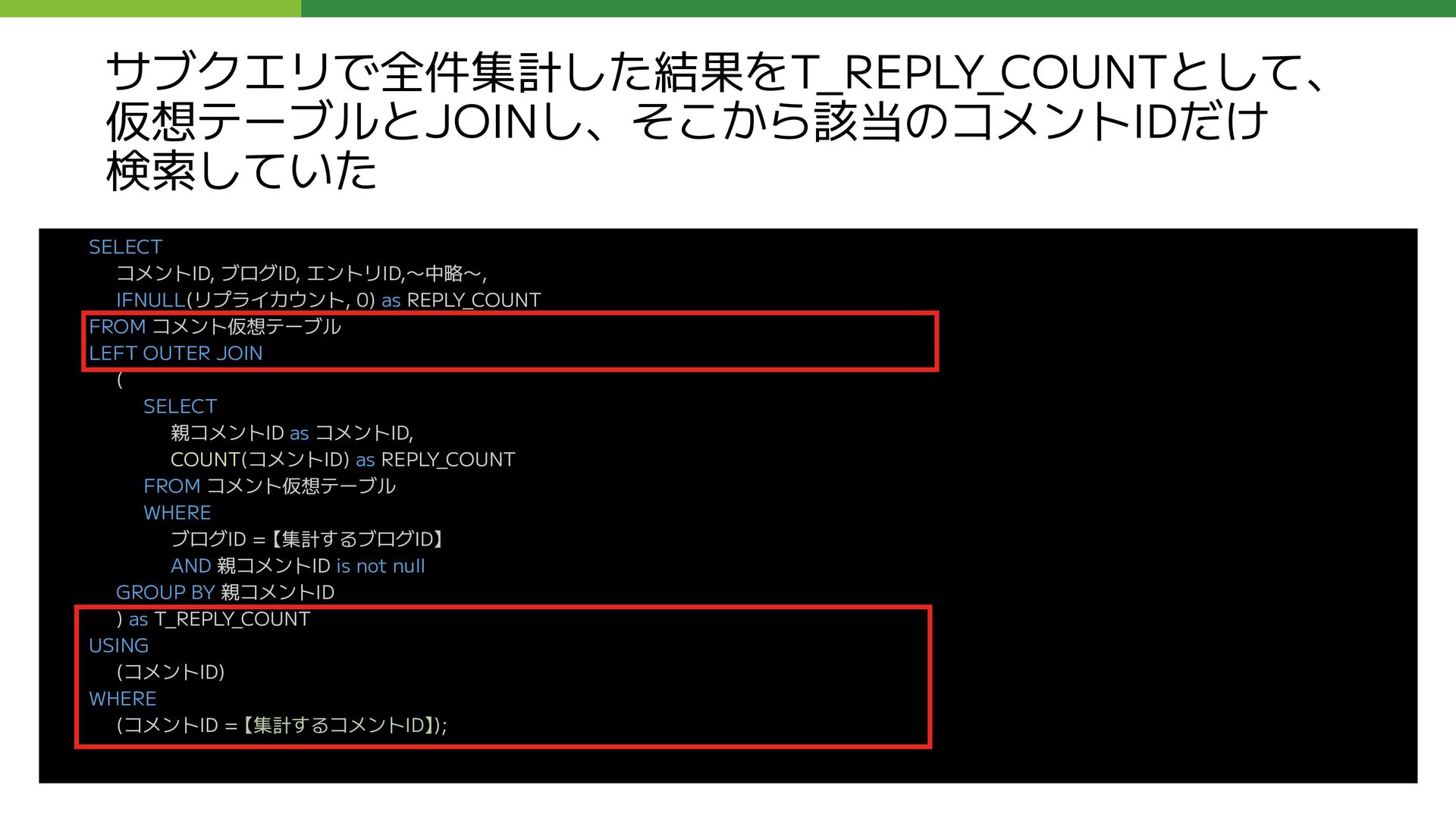
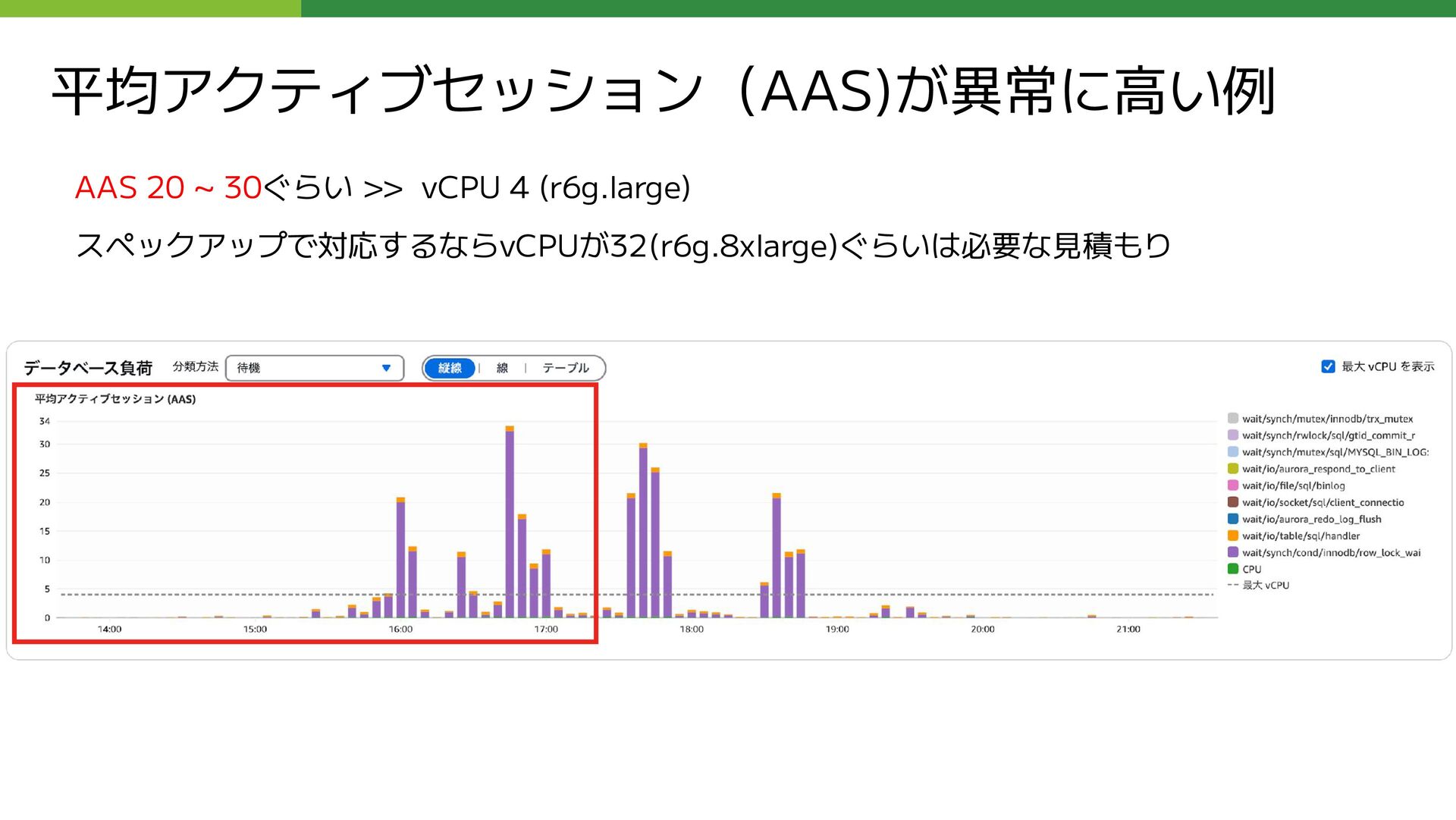
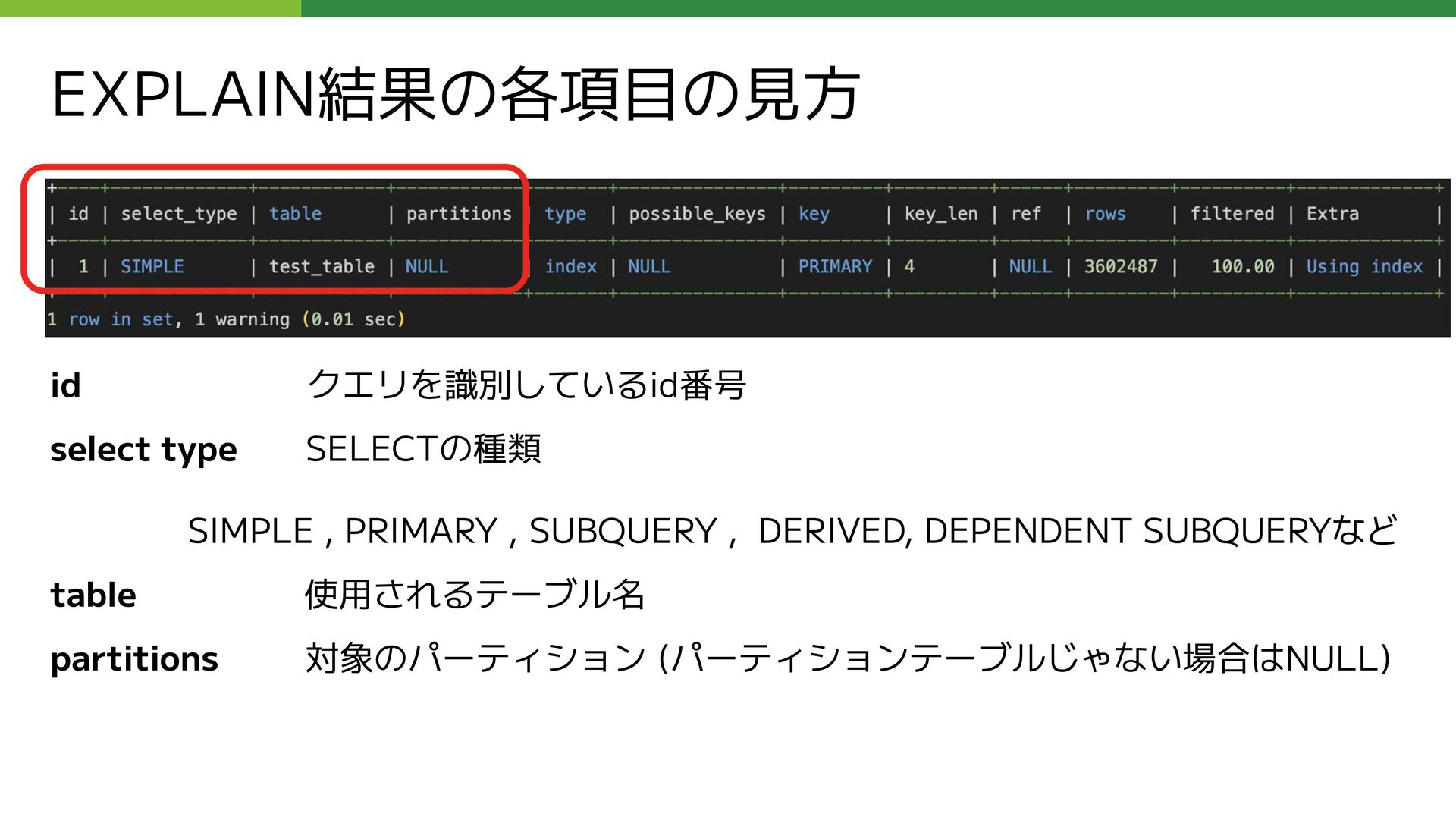
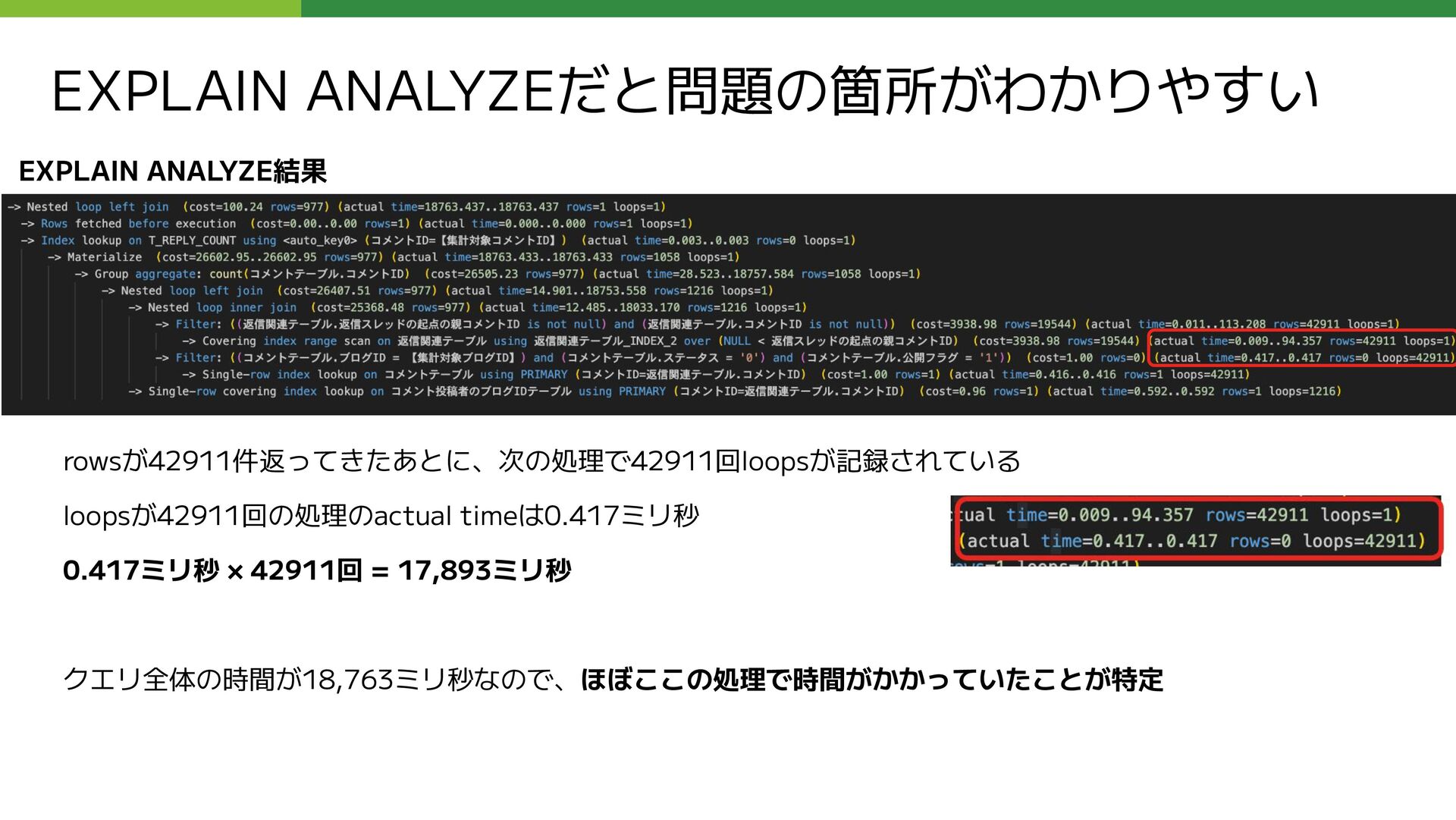
REPLY_COUNT FROM コメント仮想テーブル LEFT OUTER JOIN ( SELECT 親コメントID as コメントID, COUNT(コメントID) as REPLY_COUNT FROM コメント仮想テーブル WHERE ブログID = 【集計するブログID】 AND 親コメントID is not null GROUP BY 親コメントID ) as T_REPLY_COUNT USING (コメントID) WHERE (コメントID = 【集計するコメントID】); このクエリの応答に数十秒かかる状態になっていた
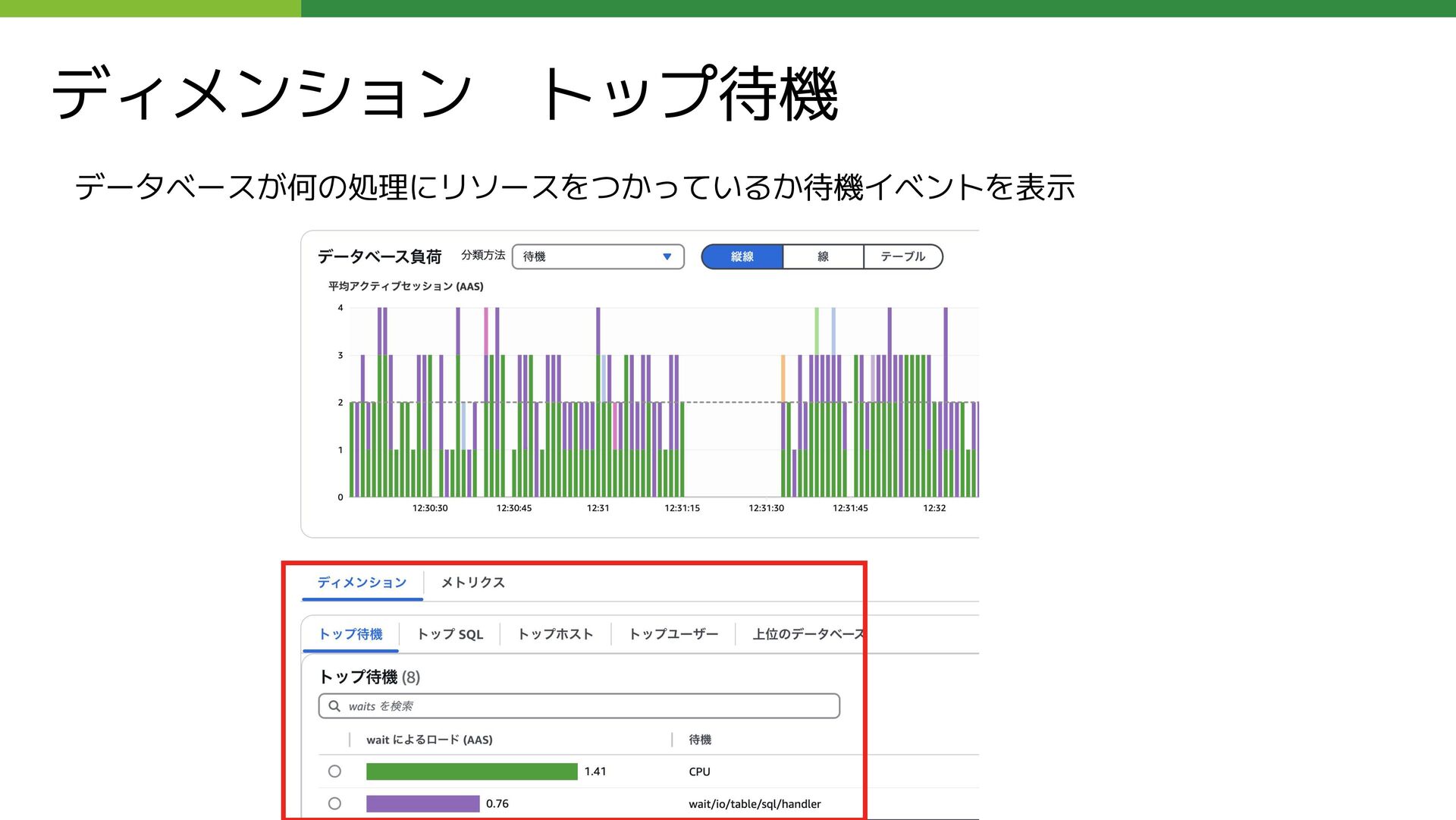
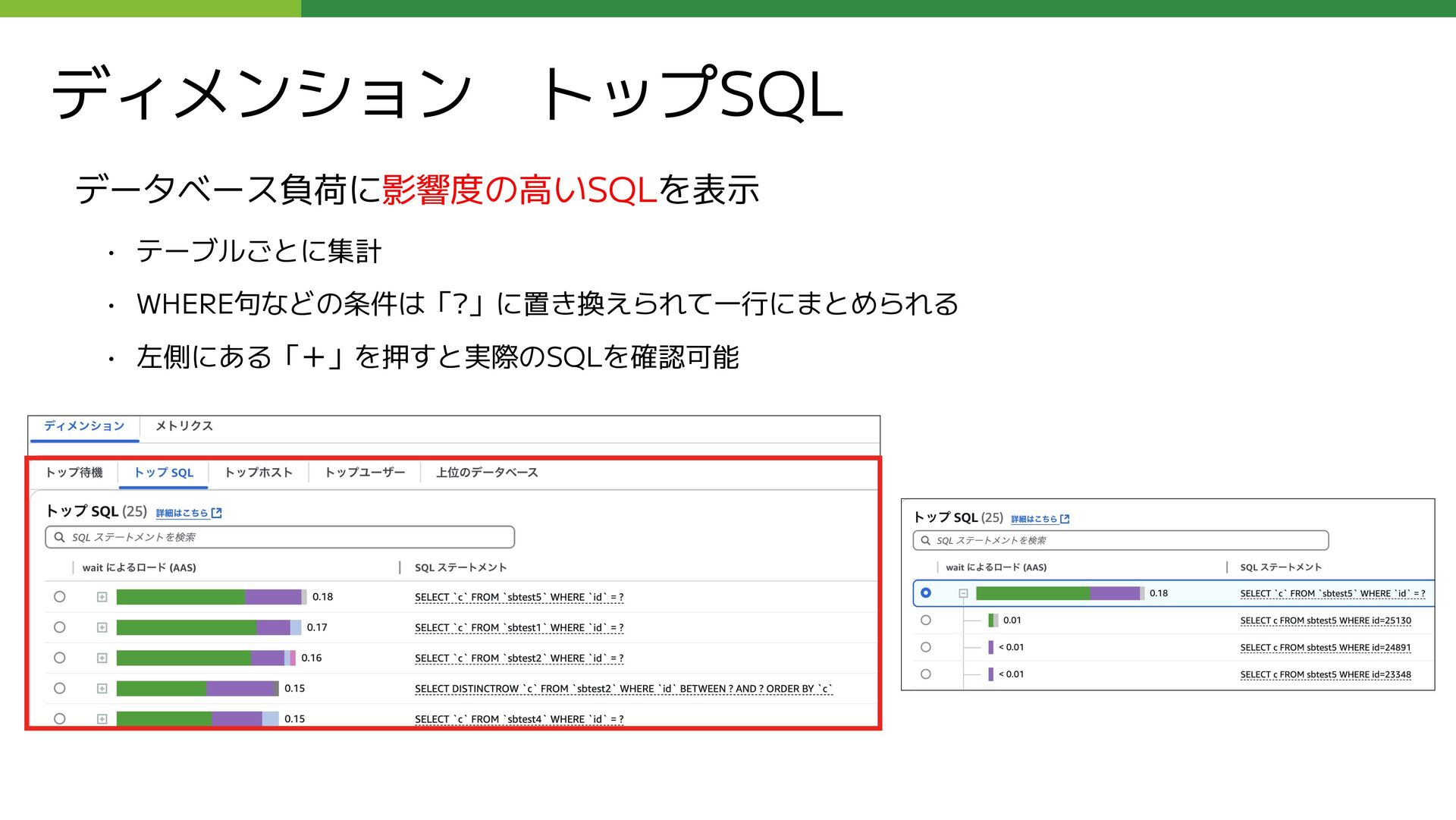
`コメントID`, `コメントテーブル`.`ブログID` AS `ブログID`, `コメントテーブル`.`エントリーID` AS `エントリーID`, 〜中略〜 `コメントテーブル`.`コメント本文` AS `コメント本文`, 〜中略〜 `コメント投稿者のブログIDテーブル`.`コメント投稿者ブログID` AS `コメント投稿者ブログID`, `返信関連テーブル`.`返信先コメントID` AS `返信先コメントID`, `返信関連テーブル`.`返信スレッドの起点の親コメントID` AS `親コメントID` FROM `コメントテーブル` LEFT JOIN `コメント投稿者のブログIDテーブル` ON `コメントテーブル`.`コメントID` = `コメント投稿者のブログIDテーブル`.`コメントID` LEFT JOIN `返信関連テーブル` ON `コメントテーブル`.`コメントID` = `返信関連テーブル`.`コメントID`; テーブルの主な用途:コメント本文のテーブルとその他テーブルを組み合わせて完全なコメント情報を持っている
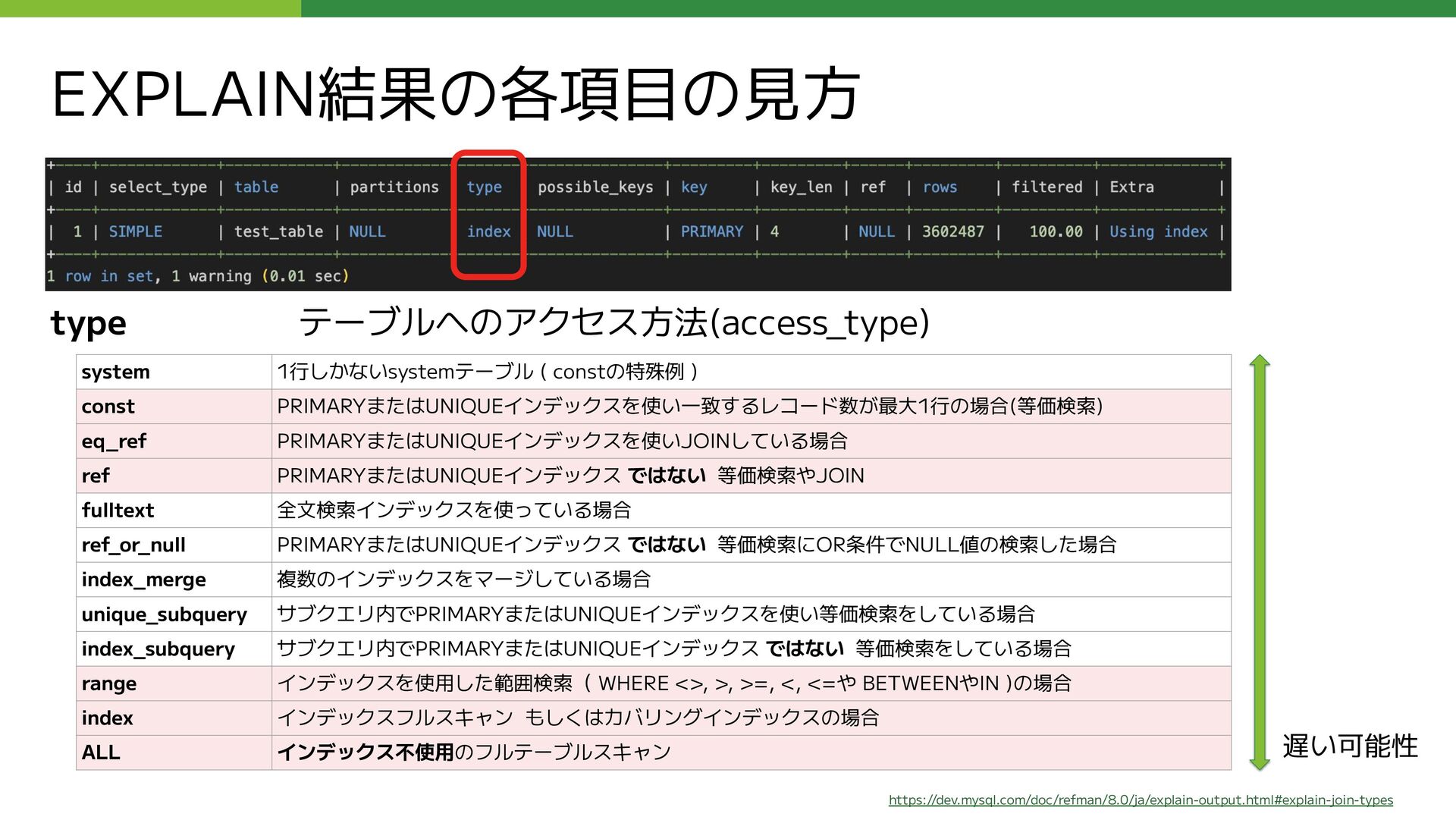
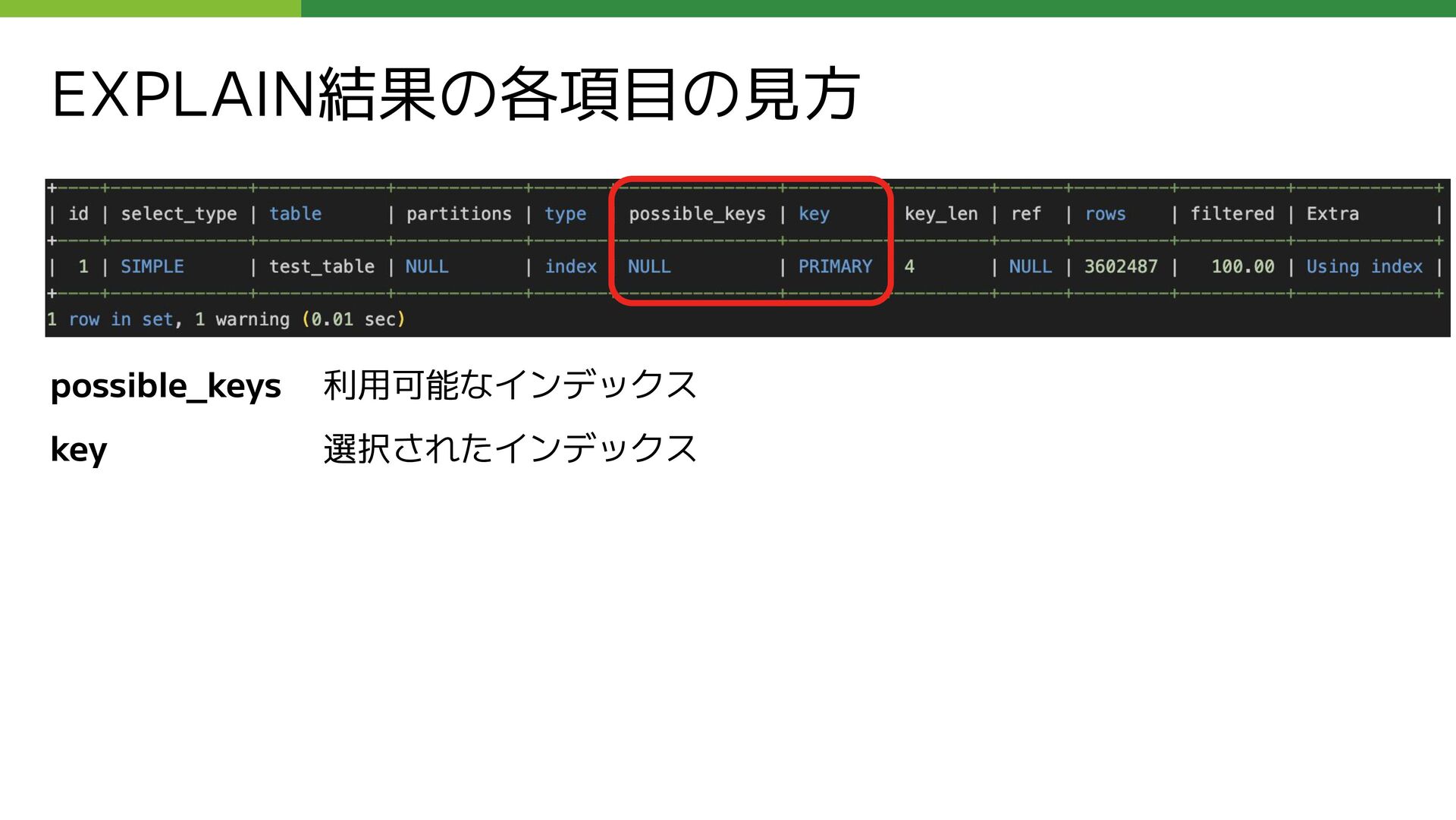
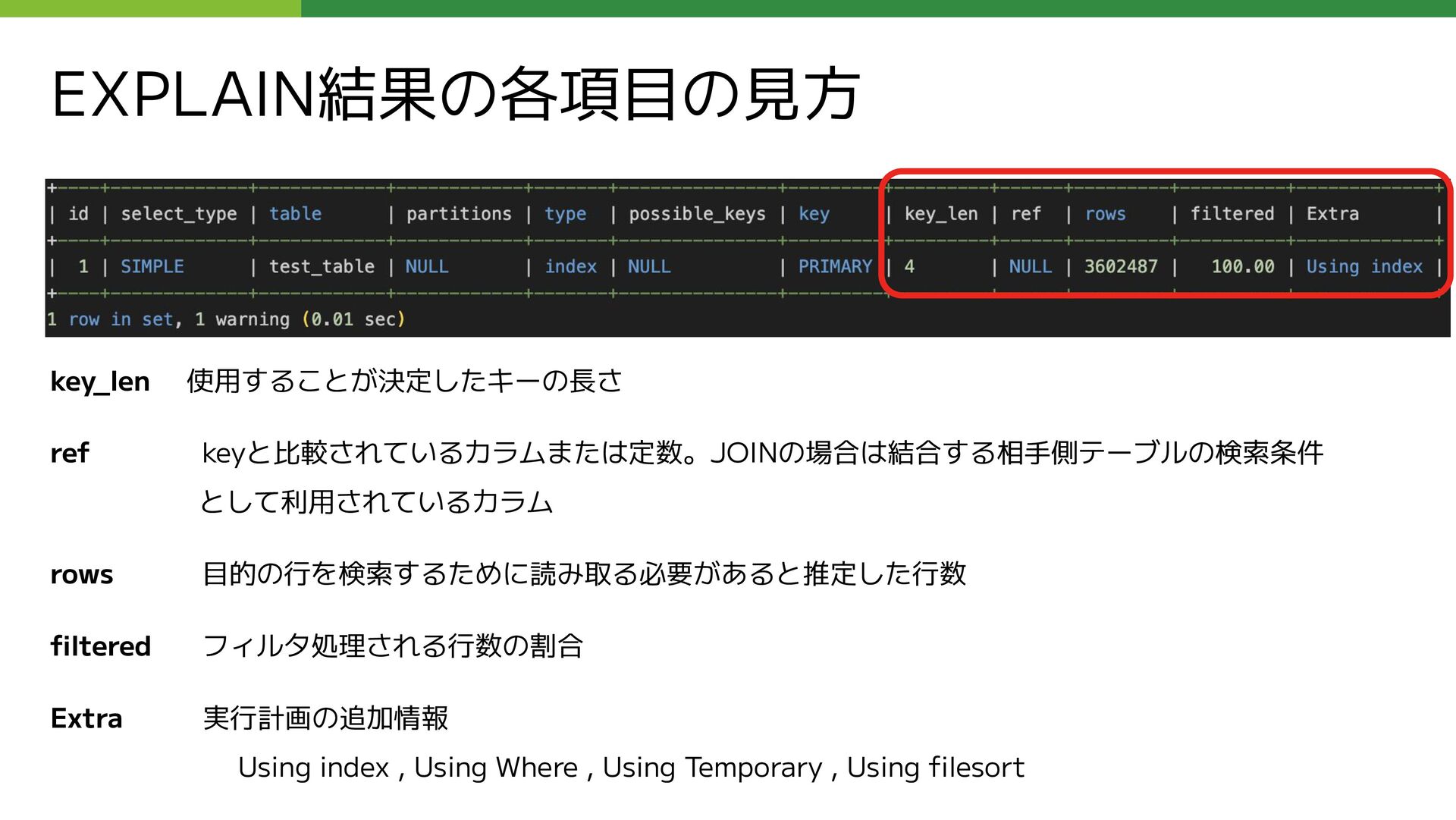
LEFT OUTER JOIN ( SELECT 親コメントID as コメントID, COUNT(コメントID) as REPLY_COUNT FROM コメント仮想テーブル WHERE ブログID = 【集計するブログID】 AND 親コメントID is not null GROUP BY 親コメントID ) as T_REPLY_COUNT USING (コメントID) WHERE (コメントID = 【集計するコメントID】); 問題となっていたクエリのサブクエリ部分 (外部公開用に抽象化しています ) 赤枠内のサブクエリの実行が遅い
REPLY_COUNT FROM コメント仮想テーブル LEFT OUTER JOIN ( SELECT 親コメントID as コメントID, COUNT(コメントID) as REPLY_COUNT FROM コメント仮想テーブル WHERE ブログID = 【集計するブログID】 AND 親コメントID is not null GROUP BY 親コメントID ) as T_REPLY_COUNT USING (コメントID) WHERE (コメントID = 【集計するコメントID】);
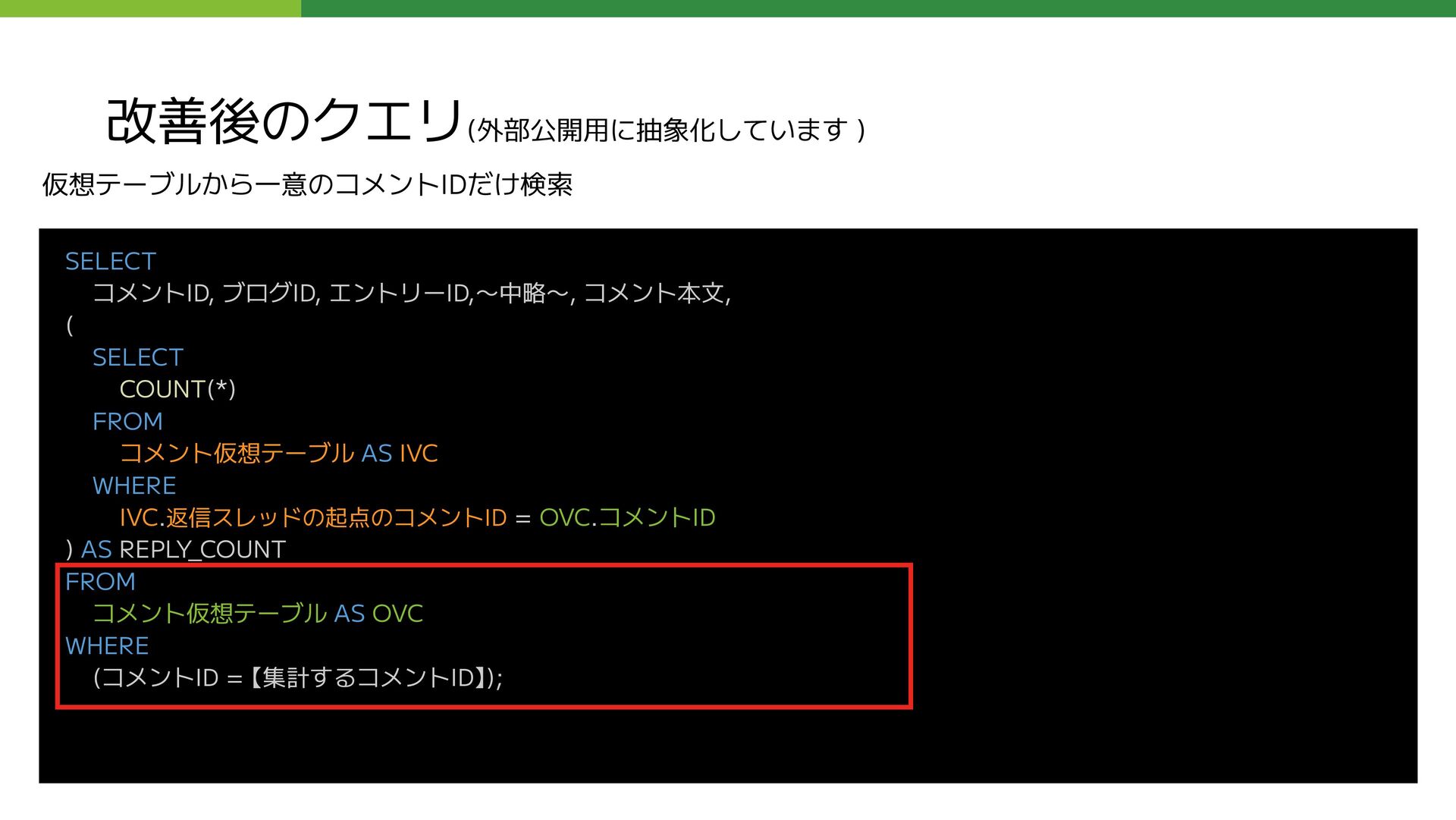
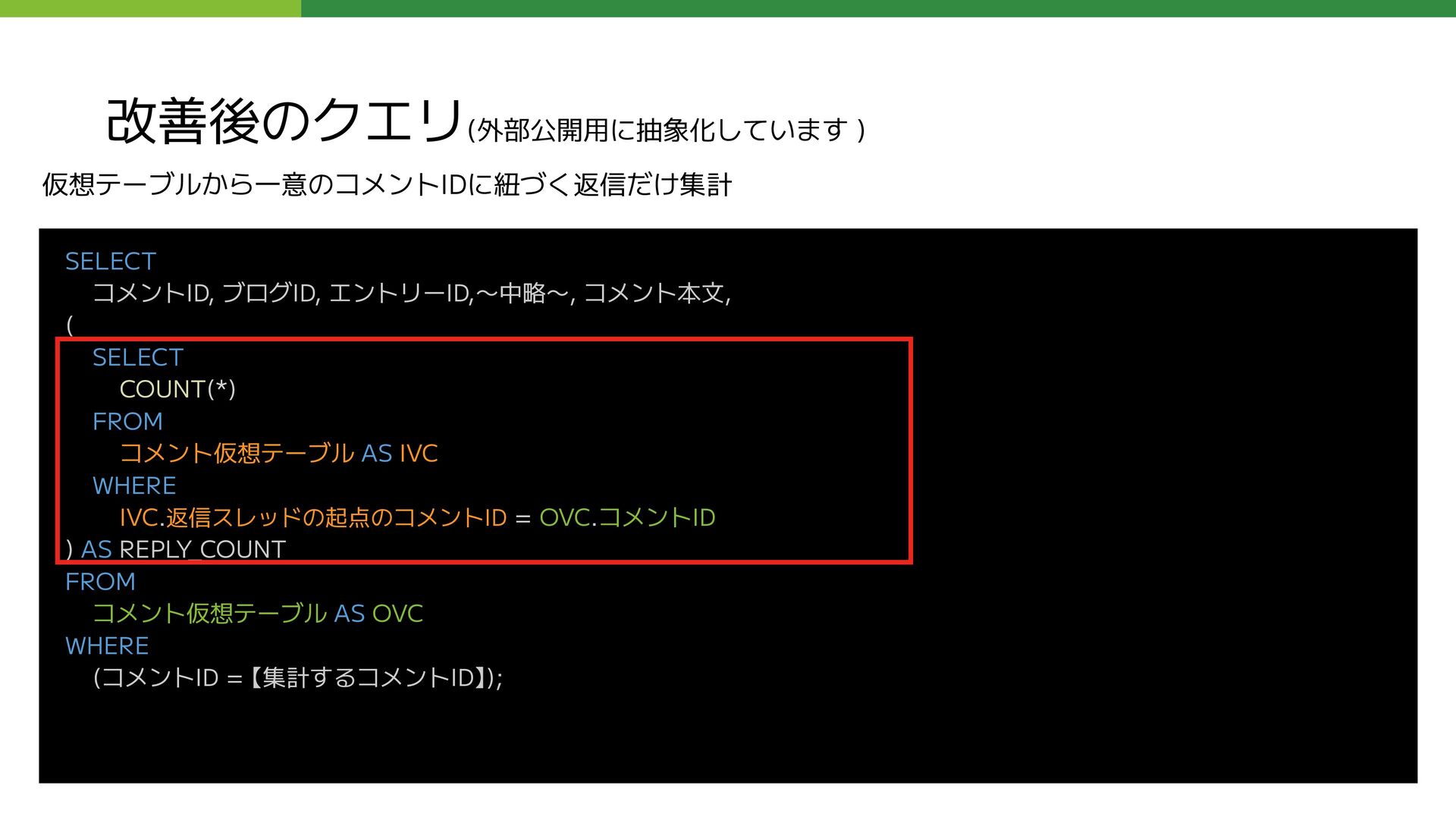
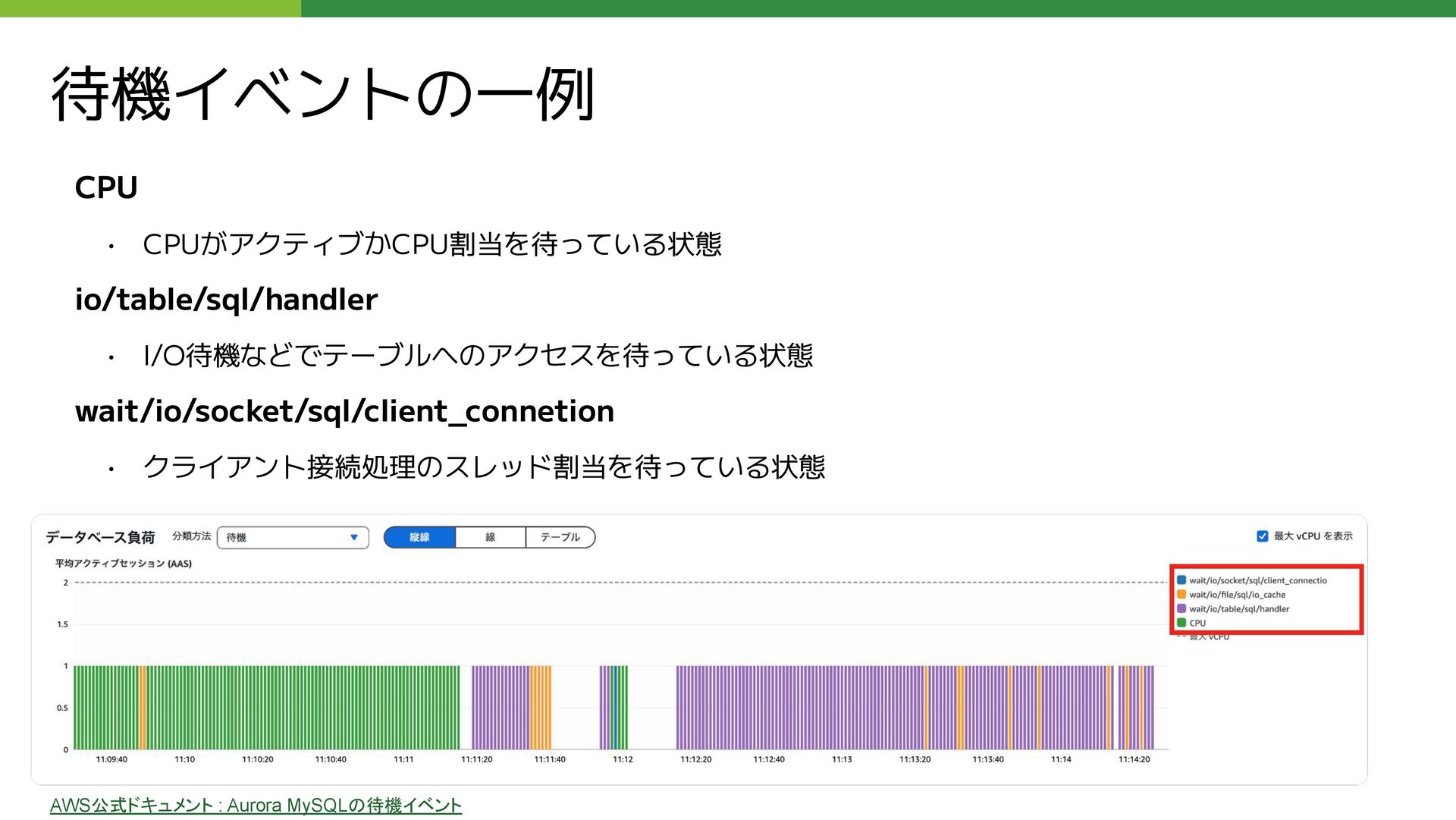
FROM コメント仮想テーブル AS IVC WHERE IVC.返信スレッドの起点のコメントID = OVC.コメントID ) AS REPLY_COUNT FROM コメント仮想テーブル AS OVC WHERE (コメントID = 【集計するコメントID】); 仮想テーブルから一意のコメントIDだけ検索
REPLY_COUNT FROM コメント仮想テーブル LEFT OUTER JOIN ( SELECT 親コメントID as コメントID, COUNT(コメントID) as REPLY_COUNT FROM コメント仮想テーブル WHERE ブログID = 【集計するブログID】 AND 親コメントID is not null GROUP BY 親コメントID ) as T_REPLY_COUNT USING (コメントID) WHERE (コメントID = 【集計するコメントID】);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
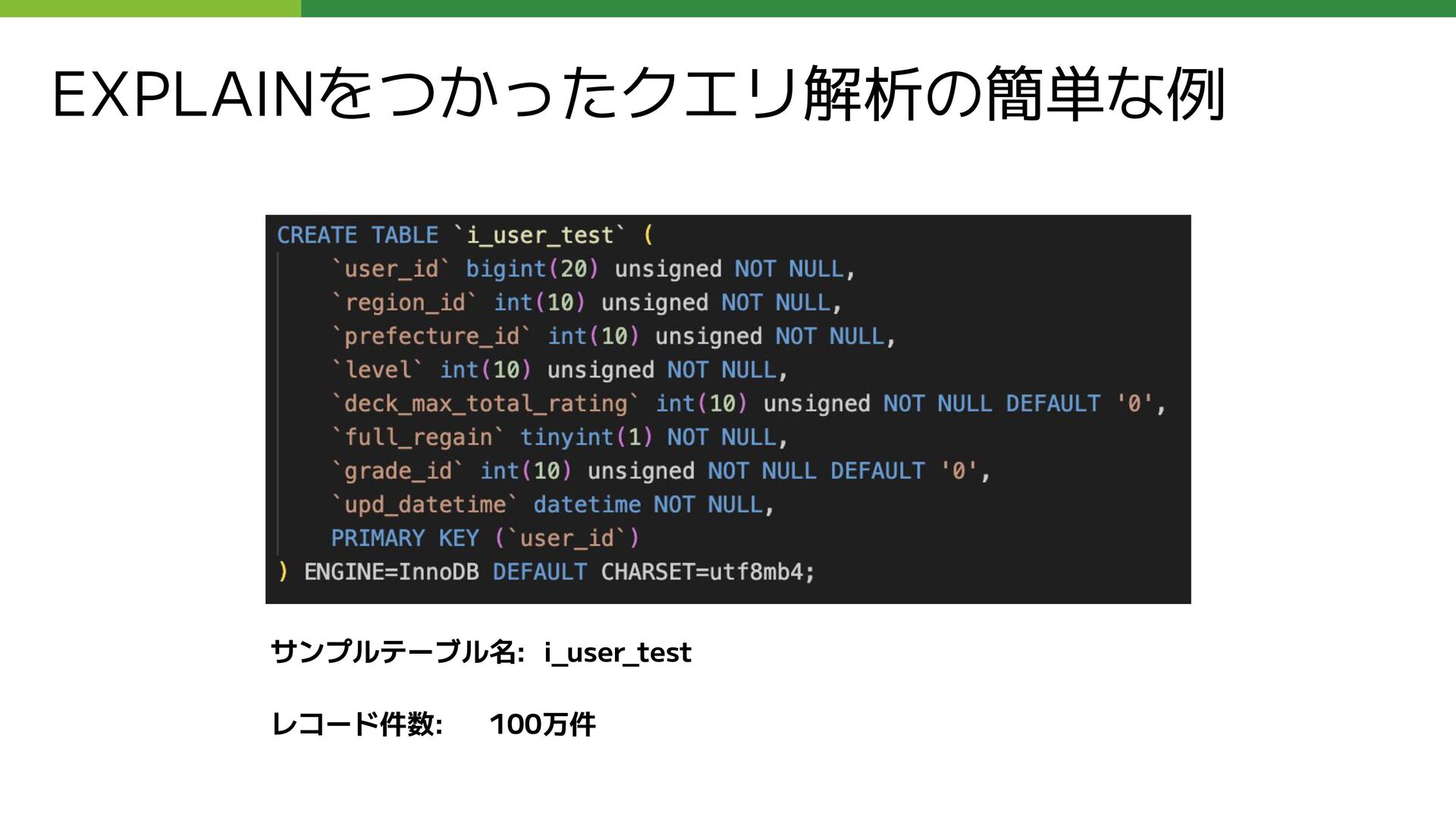{kind=link}
{kind=link}
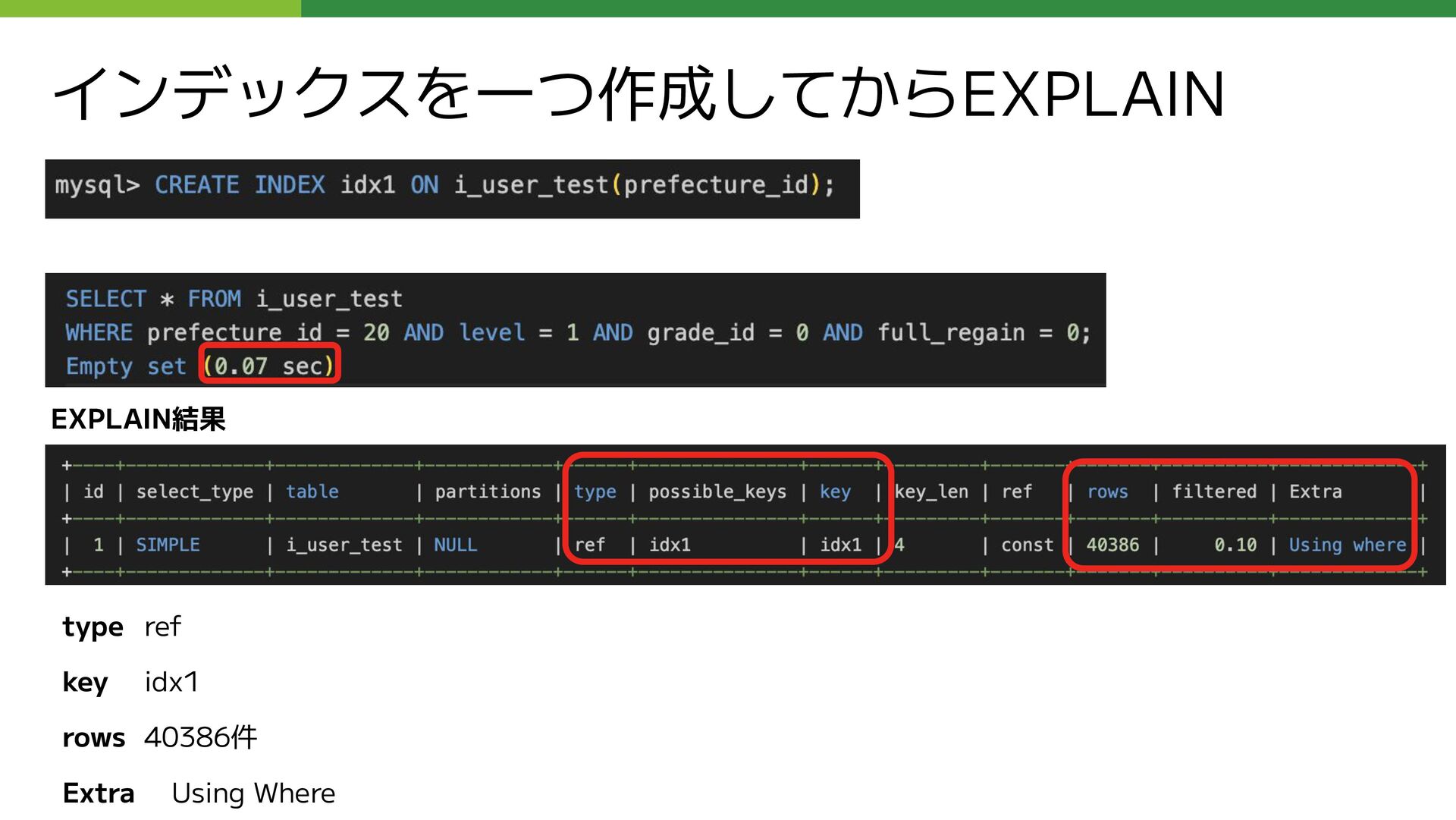{kind=link}
{kind=link}
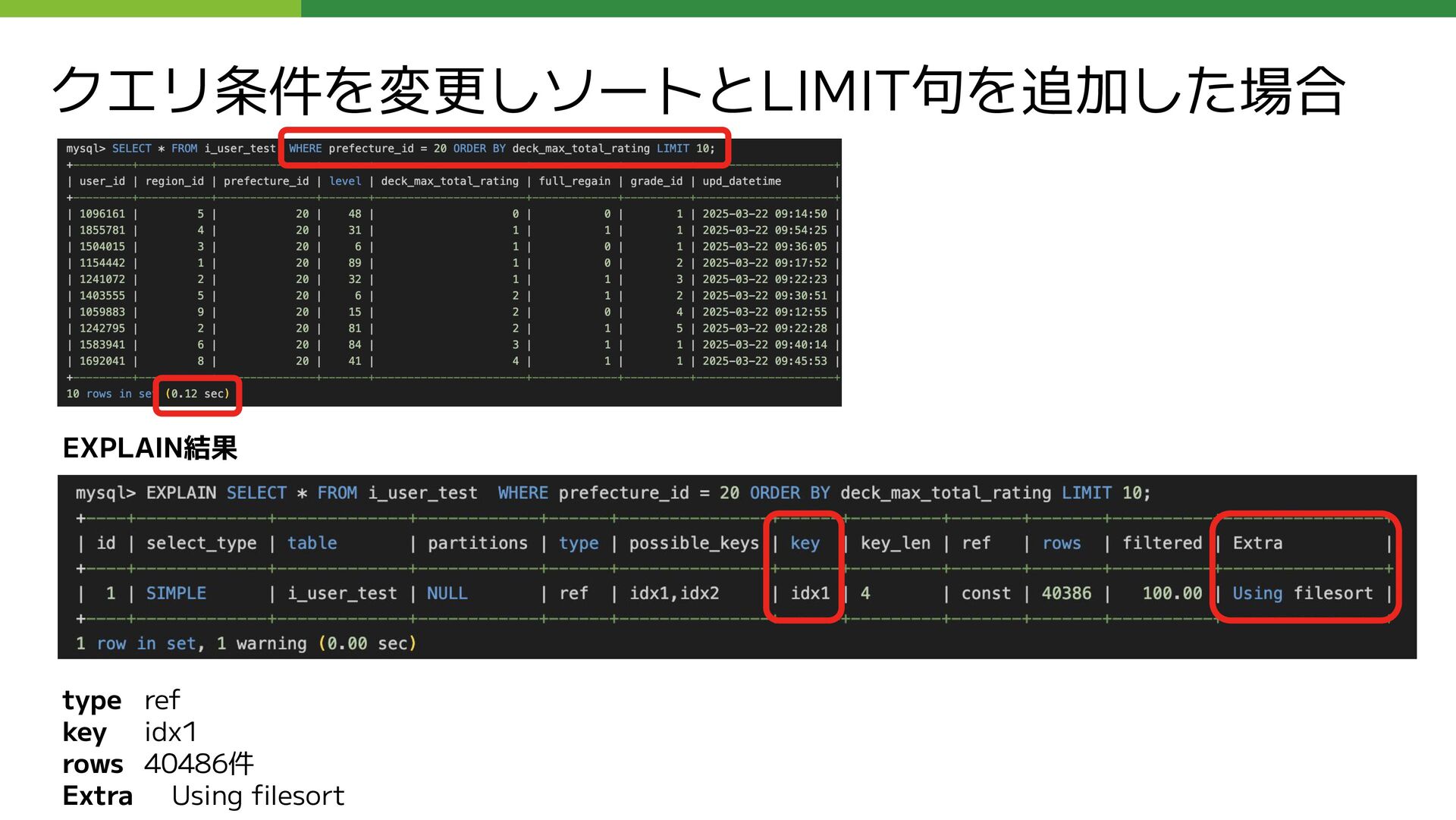{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
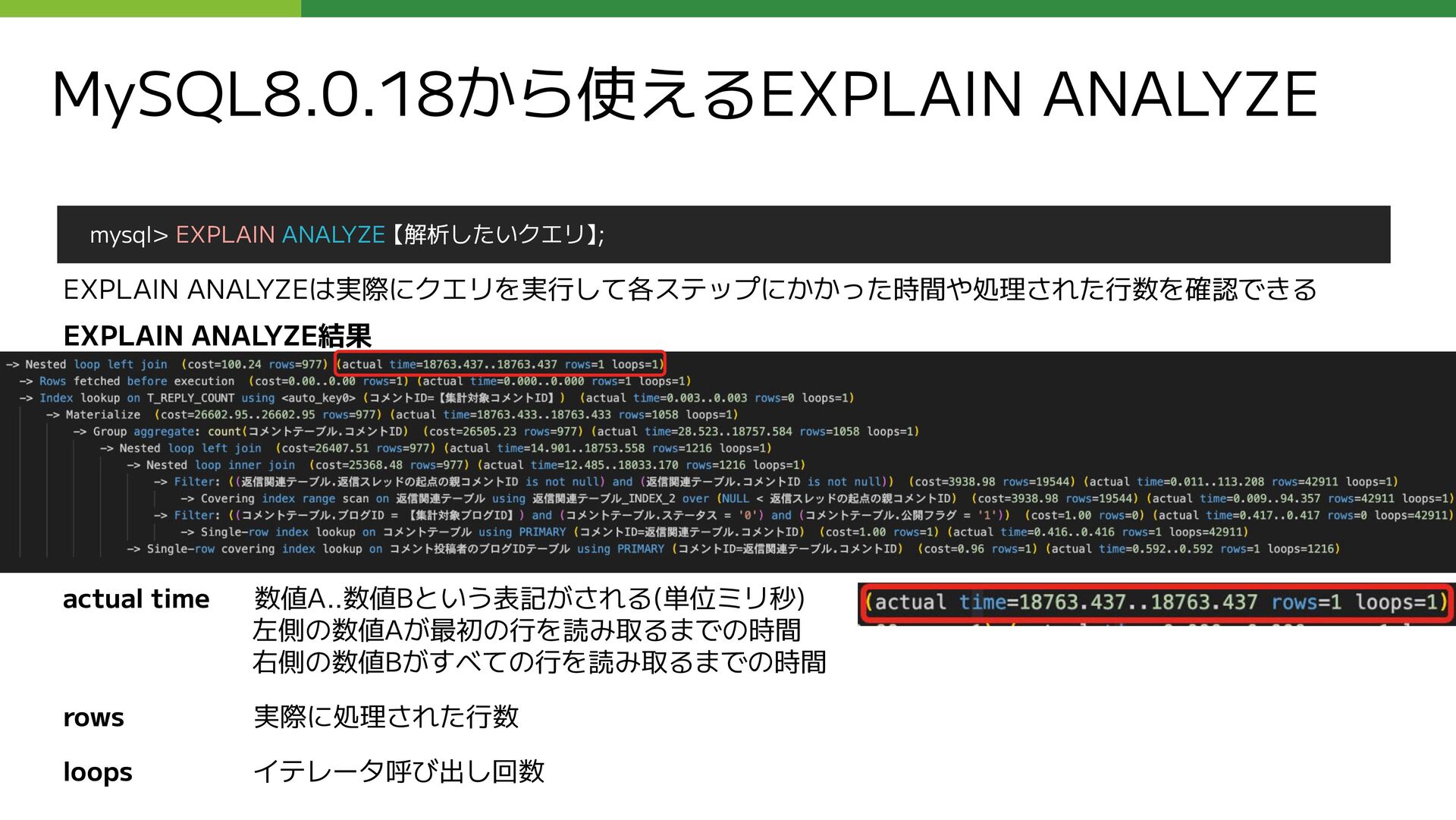{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}