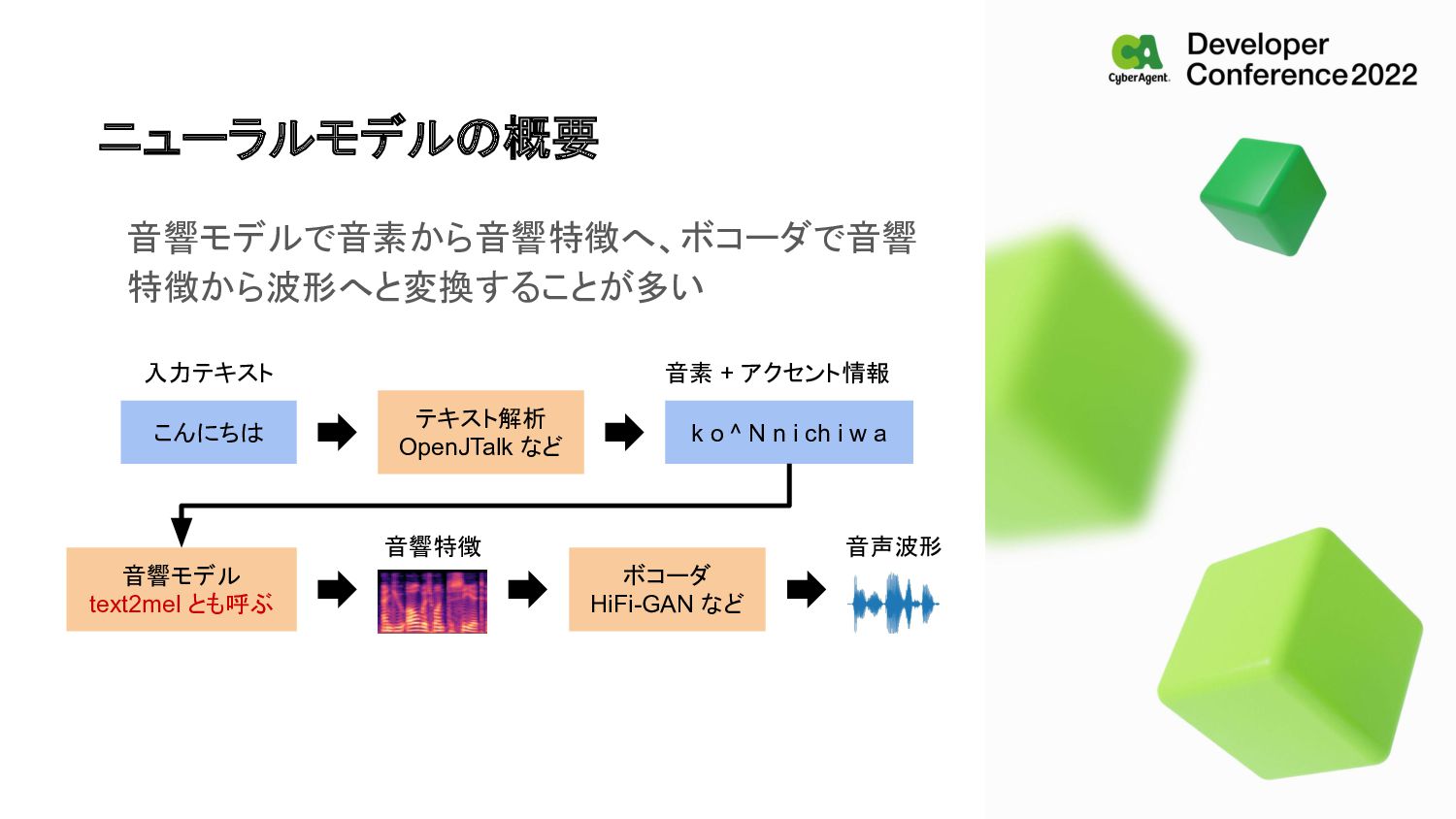
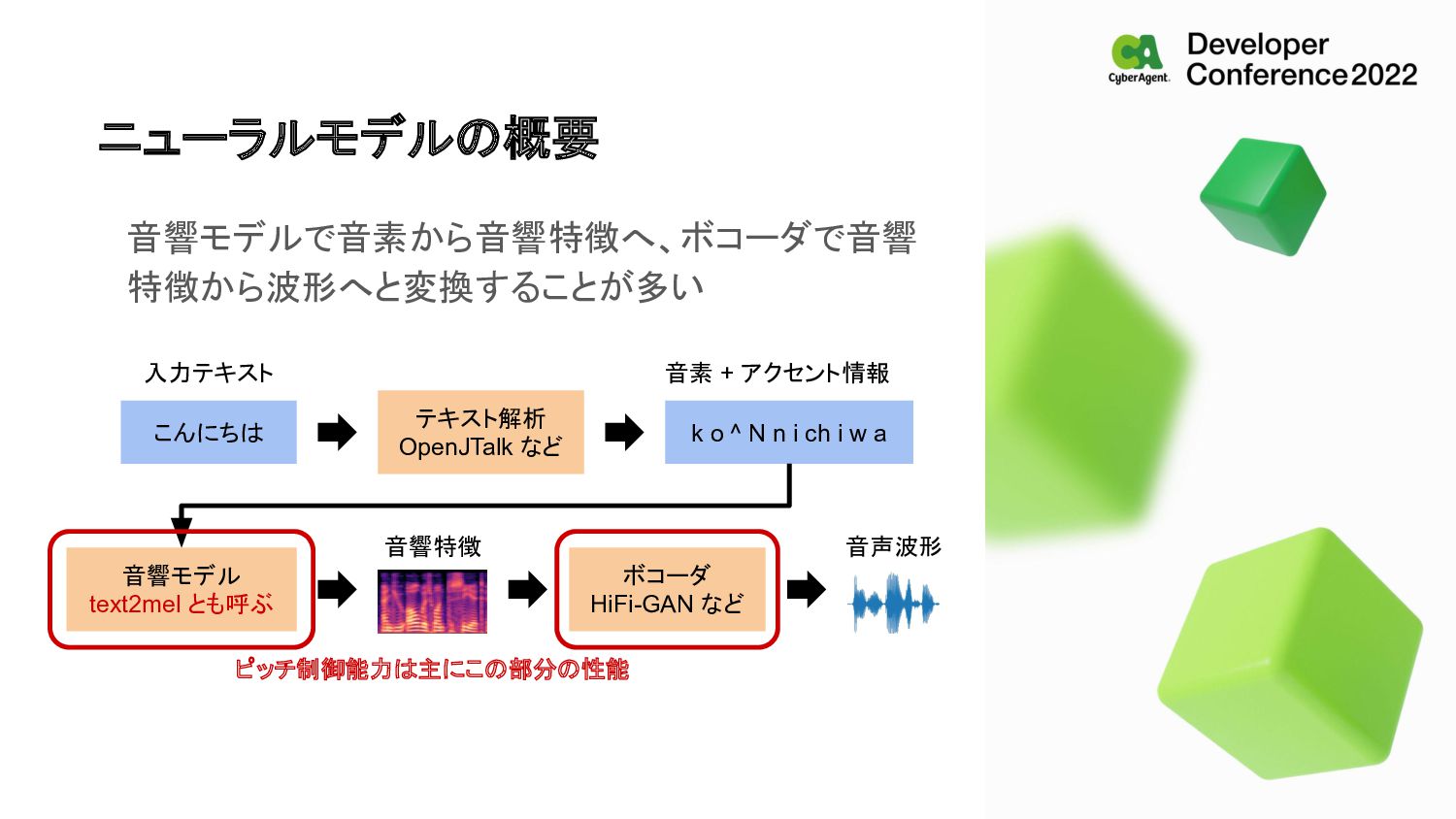
al., IEICE T INF SYST 2021] k 5 -4 o 5 -4 N 5 -3 n 5 -2 i 5 -2 ch 5 -1 i 5 -1 w 5 0 a 5 0 k o ^ N n i ch i w a ( こんにちは 入力テキスト テキスト解析 OpenJTalk など 音素 + アクセント情報 k o ^ N n i ch i w a
音講論(秋) 2014]) OpenJTalk の情報から作ることはできるが、実際の収録音 声は多くの部分でこのアクセントと異なる 収録時に指示しても理想の声になるとは限らない k_L o_L N_H n_H i_H ch_H i_H w_H a_H こんにちは 入力テキスト テキスト解析 OpenJTalk など 音素 + アクセント情報 k o ^ N n i ch i w a
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存のアクセントラベル アクセント型とアクセント核までの距離を表すラベルを加える 手法 [太田他, 音講論(春) 2021] アクセント句の区切りと音高の上昇、下降、そして文末のラ ベルを加える手法 [Kurihara, et](https://files.speakerdeck.com/presentations/6751b81637c9477197909adc14d7eb0e/slide_22.jpg){kind=link}
{kind=link}
![アクセント音声認識 音声認識モデルでアクセント情報を音声から予測する [吉本他, 音講論(春) 2022] (類似: [栗原清, 音講論(秋) 2021]) 音声認識での高低入りトークン誤り率](https://files.speakerdeck.com/presentations/6751b81637c9477197909adc14d7eb0e/slide_24.jpg){kind=link}
![アクセント音声認識からの音声合成 音声合成の制御性能実験 • 台本:ITA コーパス[小口他, 2021-MUS-131]の朗読 324 文 • 話者:プロ声優男女](https://files.speakerdeck.com/presentations/6751b81637c9477197909adc14d7eb0e/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}