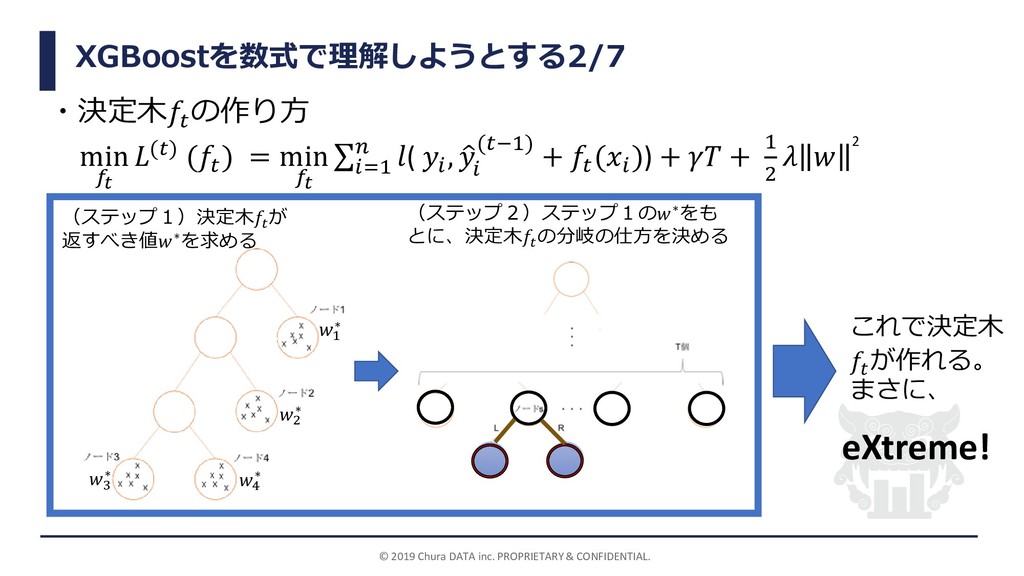
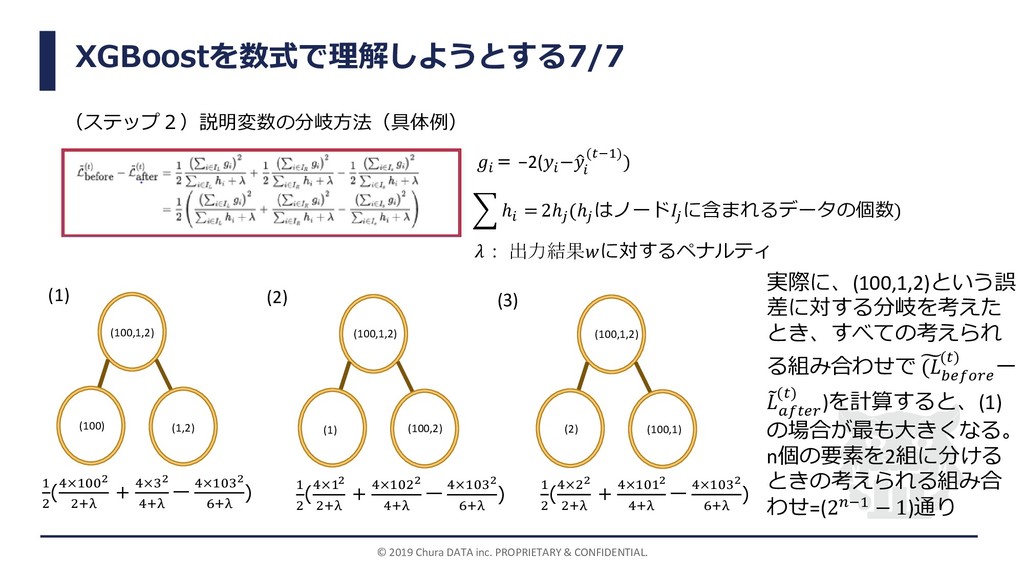
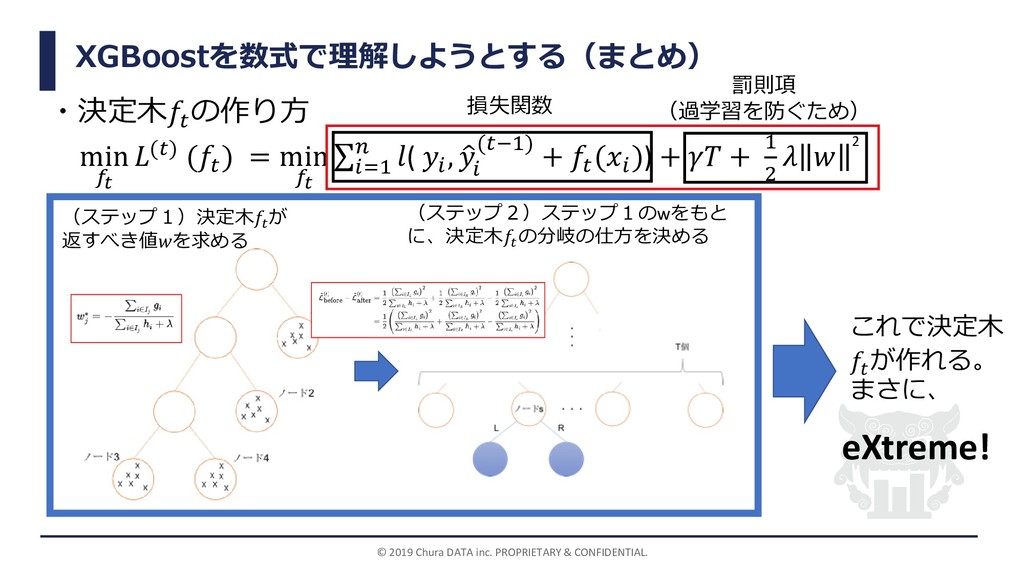
が返すべき値∗について(この式が意味するもの(小話)) ∗= − σ∈ 2ℎ+ = −2( −ො (−1)) ℎ は と出力される集合 に含まれるデータの個数 : の大きさに対するペナルティ (罰則項Ω( )= + 1 2 の式に出てくる) ∗:決定木 が返すべき値∗のj番目要素(ノード の返すべき出力結果) (1 , 2 , 3 , 4 , 5 ) (1 , 2 , 3 ) (4 , 5 ) (2) =4としたときの 1 ∗, 2 ∗の値は、 1 ∗= − σ∈1 2ℎ1+ = − −2 1 + −2 1 + −2(1) 2×3+4 = 0.6 2 ∗= − σ∈2 2ℎ2+ = − −2 0 + −2 0 + −2(0) 2×2+4 = 0 となり、1 ∗の値が直感的によさそうな値 よりも小さくなっていることがわかる。 →過学習を防いでいる。 罰則項のパラメータの値 によって出力結果 1 ∗, 2 ∗ の値が異なる。 左図において、(1 , 2 , 3 , 4 , 5 ) = 1,1,1,0,0 として、(1 , 2 , 3 ) = 1,1,1 , 4 , 5 = (0,0)に分かれた とする。このとき、1 =1、 2 = 0 と出力されることが直感的によさそうだが・・・ 2 ∗ 1 ∗ (1) =0としたときの、 1 ∗, 2 ∗ の値は、 1 ∗= − σ∈1 2ℎ1+ = − −2 1 + −2 1 + −2(1) 2×3+0 = 1 2 ∗= − σ∈2 2ℎ2+ = − −2 0 + −2 0 + −2(0) 2×2+0 = 0 となり、直感的によさそうな出力と、 1 ∗, 2 ∗の値が一致している。 ( 実は、=0のときは算術平均と同 じ式になっている)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}