new LAMP Daniel Demmel @daaain • Hey everyone! • Today I’m here to talk about a different approach to working with web apps, which was a big mindset shift for me, so I’m very excited to share it with you!
like to talk a bit about water, as different ways of accessing it have a lot of interesting parallels to web apps! • As you probably know, water is a very precious resource. A clean water supply is the single most important determinant of public health. • The plaque on this photo is in the memory of William Pranket in the village of Stoke Sub Hamdon, where his well was the only source of water until the early 20th century
are relatively recent, and far from consistent around the World • A good example is Hong Kong, where until 1964 water rationing was a constant reality, occurring more than 300 days per year • In the worst crisis, water was delivered only every 4 days for 4 hours each time • In this photo you can see how bad the situation became, people had to queue in the sun for hours to get some water from the public well
problems: • People need to potentially go very far from their house, and queue while the water is drawn for the people in front of them • It’s impossible to completely isolate the well and the water source from contamination (as you can see in this illustration), which leads to doubtful safety • Relying on a single groundwater reserve or spring, each well is exposed to droughts, making water temporarily unavailable at times
BY-SA 4.0], via Wikimedia Commons • While current municipal water systems of course aren’t perfect either, the service is much better than public wells • They make access to water quick, by bringing it close to the point of use through an extensive network • Water coming out of the tap is safe – it’s difficult to compromise the sealed, underground pipes • Supply is reliable – the available water sources are interconnected and widely distributed, getting rid of inconsistencies
alone are not quite enough to enact change… • This is the map of the infections in the Broad Street cholera outbreak in Soho, London, as drawn by a physician John Snow in his study in 1854 • All the incidents were centred around the Broad Street pump, a public water access point • Snow’s hypothesis was that contaminated water, not air, was the source of illness and he designed the World’s first double blind experiment to verify his theory
been people, the scientific evidence left the Members of Parliament unmoved and no substantive action was taken • That is, until 4 years after the study, when the historic heatwave of 1858 came • Temperatures soaring well above 40°C made the level of the river Thames drop dramatically, exposing more than 2 metres of raw sewage, which quickly started to ferment and caused an unbearable stink • As the recently rebuilt Houses of Parliament were right next to the river, the stench suddenly created a very strong political will for action where the science could not, so the drafting and passage of new laws to fund a new sewer scheme – on a scale the World hasn’t seen before – happened in just 18 days
to the Web? • As you might have guessed, wells represent the current centralised app server paradigm • But what do I mean by “centralised app server”? I used LAMP in the title of the talk, but what I’m going to talk about is true for all stacks, where there is a constantly running application daemon on a server somewhere, responsible for dynamically responding with some web content, be it written in PHP, Ruby, Java, Go, Javascript, .NET, Python or anything else • I call them “app servers” to create a distinction with web servers (like Apache or Nginx), ones which you need no matter what, to listen and send HTTP responses even if you just have the simplest HTML file to show
most requests Content often stored in a database Scaleability needs careful consideration both in app code and infrastructure • So the characteristics of this architecture is: • Executing some application code for most requests – at the very least rendering templates • Content often stored in a database – where constructing a page might mean complicated queries • Orchestrating multiple server instances for scaling can be tricky, both from an application code and infrastructure perspective
Resource use • So what’s wrong with this approach? • It’s just a bit too easy to have problems with performance, security, reliability and resource use • Let’s have a look at these one by one
and do database queries, no matter how well it is optimised, the response will take some time to prepare • Caching can help with the issue, but it’s tricky to get right as I’ll explain in a moment • Also, unless you have a massive hosting budget and some dedicated dev ops time to set up instances in different regions, and tie them together with load balancers, the further people are from your server, the bigger their network delay be – if you ever used the web in Australia, it’s not fun • Google AMP and Facebook Instant Articles wouldn’t be around if this wasn’t a huge problem, but is creating walled gardens really a great solution?
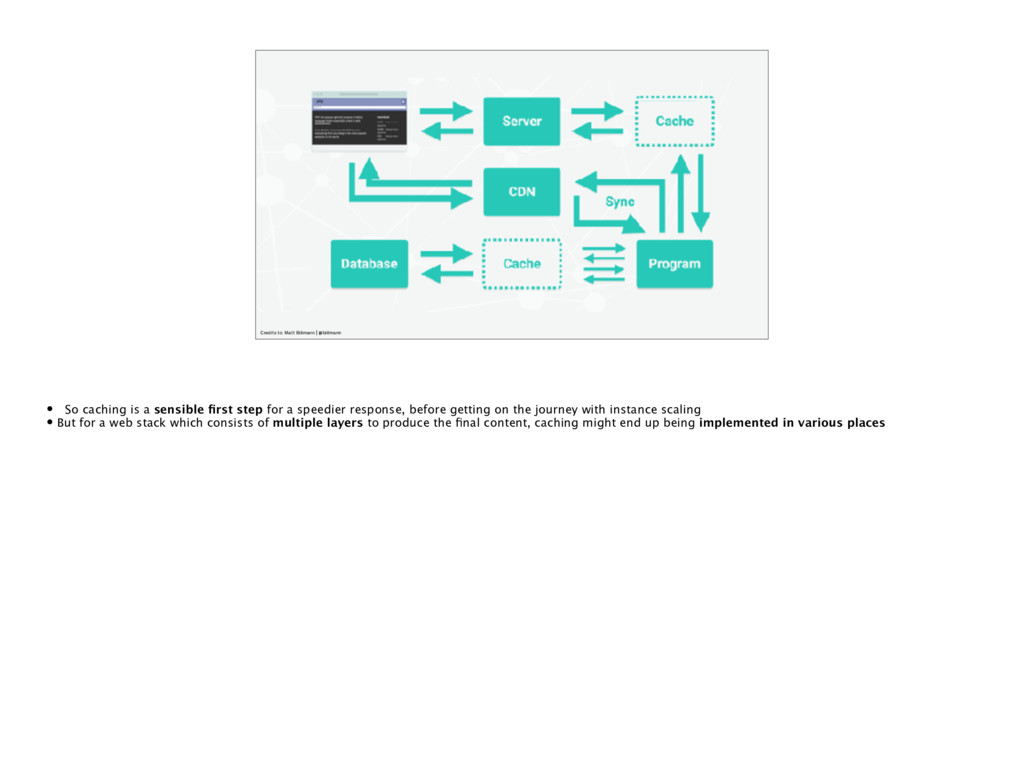
a sensible first step for a speedier response, before getting on the journey with instance scaling • But for a web stack which consists of multiple layers to produce the final content, caching might end up being implemented in various places
of multi layer cache can quickly spiral out of control • Invalidating cache is one of the hardest problems in software development, so doing it in multiple places and between multiple disciplines becomes truly mind bending • So what started as a simple web site or web app will start to require some serious infrastructure and tooling work
nowadays without a serious security vulnerability exposed in one back-end framework or another, and possibly even more undisclosed ones silently exploited • And it’s not because they are poorly written, but the more they try to do for us, the bigger the potential attack surface is, especially in the hands of less security conscious users and developers, which let’s be honest, is most of us • While fixing a security problem might mean a few sleepless nights for developers, a mass data breach can easily mean a collapsed business due to evaporating trust • Despite this, keeping on top of security updates is usually very low on most web team’s todo list
web sites: it’s a problem if no one bothers to visit them, or if they suddenly see a lot of visitors and they stop responding • What’s the worst is that in most cases they can’t even show read only content, so even though the server side app should really only be needed for user interaction, the content itself also becomes inaccessible - Reddit is the perfect example for this
by Jonathan Koomey, a Stanford University professor: • Data centres worldwide are estimated to have ten million unused servers, which could be hiding a potential cost of 30 billion dollars • So around 30% of the world’s physical servers are sitting in a “comatose” or “zombie” state, as no information or compute services have been processed for at least six months • Even more surprisingly, a similar percentage of virtual machines are also zombies, despite them being more expensive and easier to manage • If shut down, the servers could reduce electricity load by at least 4GWs, not even mentioning the cost of manufacturing and housing them • These numbers are just the tip of the iceberg (as servers which are idle most of the time but do some work every now and then are excluded), so the potential cost and environmental savings are huge
talked about the problem, let me walk you through the promise of this fabled new way of doing things • The piped water in my little story at the beginning represented a new approach, which can be described as “distributed asset delivery with serverless computing” • So there are two important parts in this – admittedly quite long – name: • Firstly, the distributed asset delivery means finding a way to deliver a web app’s assets (be that HTML, CSS, Javascript, images, fonts, videos, and so on) from a web server as close to visitors as possible • Secondly, to handle any sort of user interaction which needs data manipulation, communication, payments or any action really, in a way which avoids running your own, persistent app servers
assets by compiler before deployment Dynamic functionality delivered through APIs Distributed delivery of static assets, typically using Content Delivery Networks • So what are the characteristics of this approach? • Content and assets are preprocessed as much as possible before deployment • Any dynamic functionality and data is delivered through APIs – accessible both at compile time and in the browser client • Static assets are served up from a distributed host – typically a CDN
fast, client only, can work offline Illustration credit: Google • So how does something built with this architecture would look like from a visitor’s point, or in other words the front-end side? • If you have a look at how progressive web apps work, they pretty much embody the idea: • You start out with an application shell built from static assets, very similar to native mobile apps, just without the extra friction of discovery and explicit download • The content inside can be pre-rendered for the first load, but a Single Page Application takes over navigation and data loading on the client side, once the Javascript app bootstrapped • With browsers implementing Service Workers, this means complete offline support using the existing app shell and already downloaded data • So once running, these apps only need to connect to APIs, which can be served up completely independently of where the application assets are originally from
from the DNS response ? • So this provides us with a potential for a big mindset shift, but first of all let me give you a quick introduction to CDNs • The acronym stands for Content Delivery Networks, and they are mostly known for delivering videos and images as a way to take some of the heavy load off web servers • But there’s no reason for us to stop there, why not use CDNs as the first point of contact right from the DNS response? • Interestingly this would take us one step closer to Tim Berners-Lee’s original vision of a distributed web, where even catastrophic events can’t take the entire network down – in stark contrast with the AWS S3 outage this February, which took several massive services down, despite only happening in just one of their data centres in the US • And the biggest irony was that Amazon engineers themselves were unable to update their status dashboard as it relied on the same host • That said, today’s CDNs are still centrally controlled networks of servers, but the largest ones have hundreds of independent endpoints (or in industry jargon: Points of Presence) around the World – including places which are not the US and Europe, I can assure you they do exist! • What makes using CDNs easier nowadays is that they are more and more scriptable through APIs, so for example easier to flush content, even just partially • My current favourite host is Netlify, they are pretty much the Heroku of smart CDN based hosting and also do some great open source work in this space • But the future can be completely distributed: IPFS – which stands for InterPlanetary File System – mixed up ideas and technologies from BitTorrent and the blockchain amongst others
– summoned only when there’s work • But since CDNs can only work with static content, for any interaction requiring computing we still need to connect to an API • These APIs of course do need a server to run on, but it doesn’t need to be a constantly running one provisioned and managed by you, eating money even when not in use or getting overloaded so you need to scramble to scale • Serverless functions (or Function as a Service) can be a great solution for a lot of backend needs, especially when they are connected to a managed database to persist state and data • But Sports Direct, Deliveroo, Uber or any other firms employing zero hours contractors are waking up to the reality that they can’t wiggle out of all their responsibilities… • …despite all the hype, these serverless functions of course still won’t write, deploy and maintain themselves…
done quickly and cheaply By Alan D Cirker [CC BY 3.0], via Wikimedia Commons • So before writing a single line of code, you can be even better off considering servicefull APIs, or in other words hosted services offered as APIs • While the idea has been around since Web 2.0 was a thing, nowadays you can find great services even for core functions like: • Auth0 for authentication and authorisation • Firebase for storing user data • Contentful for creating content on an editor friendly interface, and so on • So unless you’re dealing with a service already on a massive scale, the developer time and worry you can save will more than pay for the cost of these “humble sweatshops”
to people: colleagues, (open source) collaborators, customers, workers, suppliers, etc in all their diverse and emotional selves • If you think these metaphors were a bit contentious, you’re totally right • But rather than having the intention of making fun of the people who are suffering, I’d actually like to use this platform to dedicate a few sentences to them • I think we – the tech community as a whole – aren’t doing a great job at giving enough respect to people around us • Which is in stark contrast with who much we obsess about computers and gadgets • So if you take away only one thing from this talk, let that be taking a moment every now and then to think about the impact of your work and your words on the people around you and in the wider World, especially if they are not like you
/ or fastest PoP •Scales to demand •More difficult to code yourself in a corner • I split each of these between the two parts, so the distributed asset delivery via CDNs and serverless computing • So performance with CDNs is a joy to see really, since they are only dealing with files and each visitor will get them from the nearest endpoint, load times are pretty much instant • At the same time, computing on serverless infrastructure automatically scales to whatever the demand is (except for the most extreme cases) • While in your own server no one stops you from shooting yourself in the foot, in a Function as a Service you have to work within limits, so for example on AWS Lambda any execution has to finish within 300 seconds, which might sound like a lot, but knowing the constraints will make you think about splitting up, measuring and optimising functions earlier
access •Transient nature •Security updates between runs • Just a bunch of files on a CDN is practically impossible to hack, but even better, there’s not much in it to do, so it’s unlikely many people will even try • The virtual machines and containers running your serverless code are transient by nature, so they don’t stick around long enough to give people time to hack into • Also, once they are spun down, security updates can be applied right away without any disruption, so next time they run, you’ll get a freshly updated container image
to migrate files •Quick to scale •Even cold start is acceptable speed • Due to their distributed nature, CDNs are very resilient to denial of service attacks, but even if a well resourced adversary manages to take one down, migrating files to another one is not difficult • Serverless infrastructure mostly operates on containers, which are very quick to spin up, so unless you go completely nuts with dependencies, even cold starts will be at an acceptable speed
•Less networking •Minimised idling •Scaling on demand • Again, since CDNs serve only files, there’s not much computing they need to do other than routing • But also, by using and endpoint close to visitors, less network hops will be used, saving on using resources on each switch on the way • And with serverless, idle time is minimised by cleaning up containers after a very short time, while at the same time you also don’t need to over-provision due to the ability to scale on demand • These translate to big savings both in terms of monetary and environmental resources
to “progressive web app pipeline” • So how can you get started, you must be thinking “surely it’s a lot of work to do all these new things”? • Well, it used to be, and only big and tech heavy organisations like the Guardian, Google or Alibaba could afford to develop custom solutions for them in house • But hey, it’s 2017 and I work for a studio where we often don’t have more that 6 weeks to turn projects around from business problems to a few versions deployed, so I wouldn’t be here if there weren’t tools available to do most of the hard work for me • Static website generators have been around for years now, and people have great times with them producing websites based around content • But these are static web sites, lacking the modern browser based powers of web apps which people more and more expect now • So it was only a matter of time until a new generation emerged, which I call “progressive web app pipelines” and will explain them in a moment
Static website generator (Jekyll, Hugo, etc) HTML + CSS (+ JS?) • But first let’s have a look at what static website generators do, just so it’s clear what I’m talking about • The poster child for these is Jekyll, which is the Ruby based generator behind Github Pages • It’s been around for ages and is remarkably good at producing simple and fast websites, taking it way beyond the original role of generating documentation sites for open source projects • The way it works is taking Markdown content files with YAML metadata and putting them in various Liquid templates • This process does a great job at producing HTML and CSS, but Javascript is just an afterthought, stuck in the jQuery era of DOM selectors
do these new progressive web app pipelines do beyond that? • This diagram is from Gatsby, an open source tool which just emerged from a full rewrite with the final 1.0 version released last Thursday • So what makes it a big deal? • First, it takes more than files as input, there are already plugins out there which can dump data from APIs like Contentful’s, Twitter’s or Instagram’s • Second, it aggregates all the content and assets and creates a GraphQL API to work with them, so you can have custom queries co-located with front-end components, including generating image sizes appropriate for various contexts • Third, it generates a fully formed PWA together with pre-generated JSON data files, ready to be deployed on a static host • Some key ingredients in this are: • React, with its mature support for server side (or in this case compile time) generation and great ecosystem of tools like the Redux state manager • And Webpack with its similarly huge ecosystem, as an advanced build tool providing the pipeline and plugins for processing all assets
worshipping Gatsby, there’s another similar open source tool called Phenomic which is also well worth checking out, especially if you don’t want to use React for any reason, as they are working on supporting multiple Javascript single page application choices
application assets, not just code • What makes all of these tools tick though is a big, fat asset compiler, which does the hard work at build time • What this means is some high level orchestration code, which makes – in these cases – Webpack and its plugins work smoothly together and lets you focus on application code • A few years back I used to dread setting toolchains up, as it meant either a lot of hand coding and head scratching or trying to understand and strip code out of boilerplates • But in both cases usually ending up with compilation times slowing down a few weeks into development • Luckily nowadays that’s mostly history with incremental builds, live browsers refresh, hot module replacement and state replays, without having to spend a lot of time manually piecing these together
be Markdown files only • For dynamic content and data on the input side of these pipelines there are headless CMSs and hosted database APIs • What this means in practice is that website content writers can work on a nice visual editing interface and the content output can be accessed only via an API, making it a headless CMS • This in contrast with the more monolithic CMSs responsible for rendering content in their on templates and locking you into their ways of doing things • Similarly, to store user generated data you can use something like Firebase and use the public content (like comments, uploads, and so on) as input in your static site • This way any time there’s a change either in your code or the data sources, you can trigger a rebuild using a web hook
I would like to share a few cases studies with you • A lot of you probably already read articles on Smashing Magazine, but in case not, it’s a big, international publishing company, mostly writing about front-end development • A year or so ago they decided to replace their overstretched Wordpress back-end with a static website generator • They used Jekyll at first, then switched to Metalsmith to be able to use Handlebars templates which can also be rendered on the front-end
compilation time first ⇩ 2-5 minutes incremental compilation • They have a fair amount of content, so using static compilation out of the box meant that the linearly increasing compilation time spiralled to 2 hours for each change which of course wasn’t very useful • Moving on to using incremental builds (mostly by making sure to only process images if they actually changed by comparing timestamps) and splitting content per language, they managed to go down to 2-5 minutes builds depending on the number of images added
where devices are increasingly catching up in processing power and having modern browsers, but storage space is still precious and networks are a bit patchy, the impact of progressive web apps with offline capabilities and are much more important • So Twitter set out to write a lightweight web client as an alternative to their downloadable apps
being static content and the feed is tailored to each user, they had to put in place a small Node service for initial server side rendering • But the browser application itself is making full use of PWA features and CDN based asset delivery, so they managed to offer a great experience while cutting costs by an order of magnitude • I honestly see no reason why they couldn’t use a lot of this on the desktop site too, so curious to see when will they make the jump
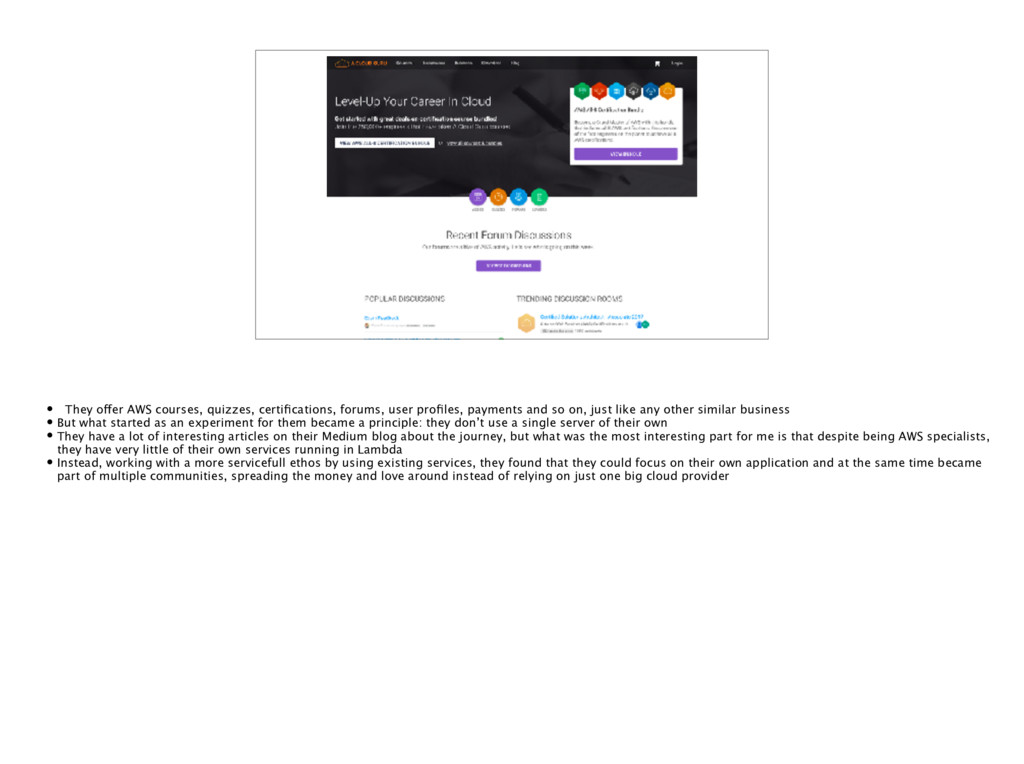
payments and so on, just like any other similar business • But what started as an experiment for them became a principle: they don’t use a single server of their own • They have a lot of interesting articles on their Medium blog about the journey, but what was the most interesting part for me is that despite being AWS specialists, they have very little of their own services running in Lambda • Instead, working with a more servicefull ethos by using existing services, they found that they could focus on their own application and at the same time became part of multiple communities, spreading the money and love around instead of relying on just one big cloud provider
you could see there are a lot of different ways to put this approach into use and methods you can deploy independently, so the one big thing I’d like to leave with you is: • When designing your service architecture, ask yourself the question if you really need to have a server running somewhere • And of course there are many perfectly valid reasons to have them, on the current project I’m on we’re actually developing an API and some transactional pages with Ruby on Rails, as the service is for a children’s hospital with plans to roll out throughout the NHS, we didn’t want to freak them out with something they’d struggle to find maintainers for or would have concerns around data we can’t answer – that said, the hospital employee interface is going to be a PWA which uses Rails as an API only! • But as a father of two, I can assure you that while bringing your own babies into existence is for sure an exhilarating thing (especially in the conception stage), but the responsibility of looking after them is going to stick, so you have to be careful with how many can you comfortably handle
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![By de:Benutzer:Alex Anlicker [GFDL], via Wikimedia Commons By Brandonrush [CC](https://files.speakerdeck.com/presentations/c138d981a66549b08d8aa759db8daaa6/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}