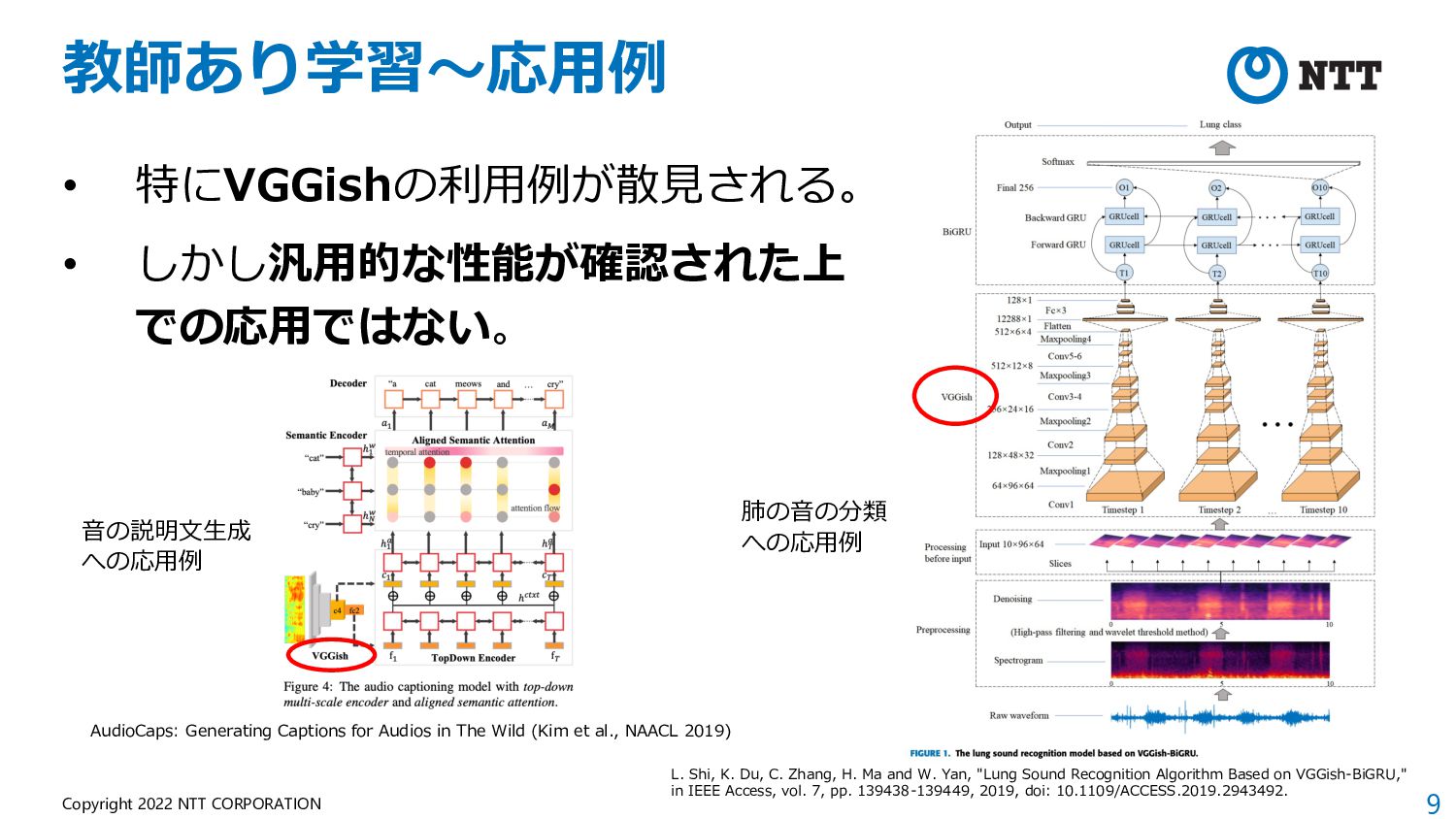
での応⽤ではない。 AudioCaps: Generating Captions for Audios in The Wild (Kim et al., NAACL 2019) L. Shi, K. Du, C. Zhang, H. Ma and W. Yan, "Lung Sound Recognition Algorithm Based on VGGish-BiGRU," in IEEE Access, vol. 7, pp. 139438-139449, 2019, doi: 10.1109/ACCESS.2019.2943492. ⾳の説明⽂⽣成 への応⽤例 肺の⾳の分類 への応⽤例
CLIPのようなインパクトには達していない様⼦。 • ⾳声認識は、wav2vec2 以降のモデルがインパクトをもって迎えられている様⼦。 • 今後 Foundation Models の⼀つに数えられるかどうかは、 これからの発展次第か? “A foundation model is any model that is trained on broad data at scale and can be adapted (e.g., fine-tuned) to a wide range of downstream tasks; current examples include BERT [Devlin et al. 2019], GPT-3 [Brown et al. 2020], and CLIP [Radford et al. 2021].” Bommasani, Rishi, et al. "On the opportunities and risks of foundation models." arXiv preprint arXiv:2108.07258 (2021). 近年、GPT-31)のように、これまでとは桁違いに⼤きな ニューラルネットワークを⼤きなデータセットを使って⻑い 時間かけて学習して作ったモデルが次々と登場している。こ のようなモデルは⼀度作れば⾮常に多くの様々なタスクに利 ⽤することができる。このようなモデルはFoundation Model2)とよばれており、最初は⾃然⾔語処理でスタートし たが、画像、⾳声、制御など他の分野にも進出しつつある。 【PFN岡野原⽒連載】Foundation Model︓巨⼤モデルが今後のAIシステムの基礎となるか”, ⽇経ロボティクス, No. 84 (2022).
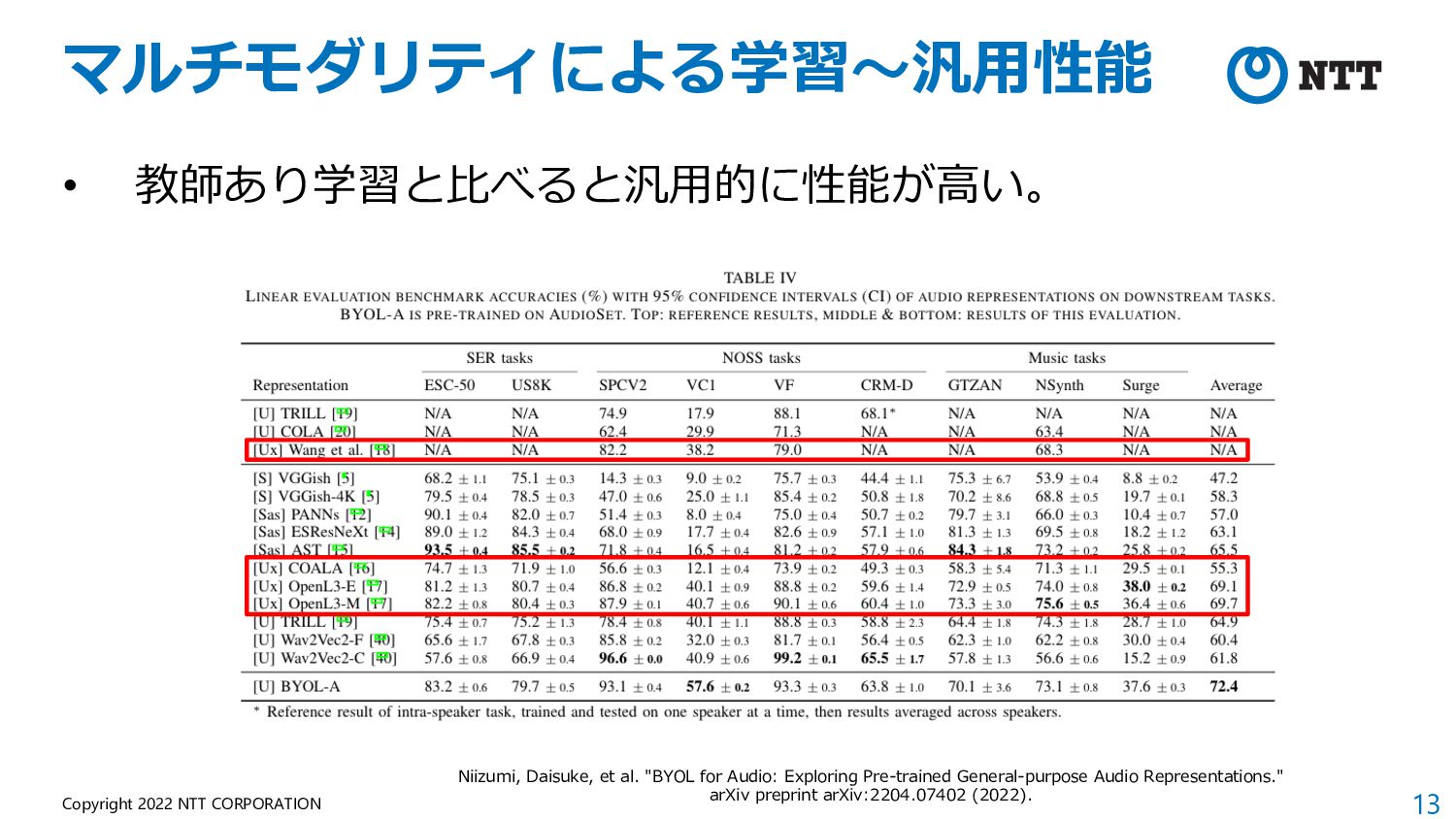
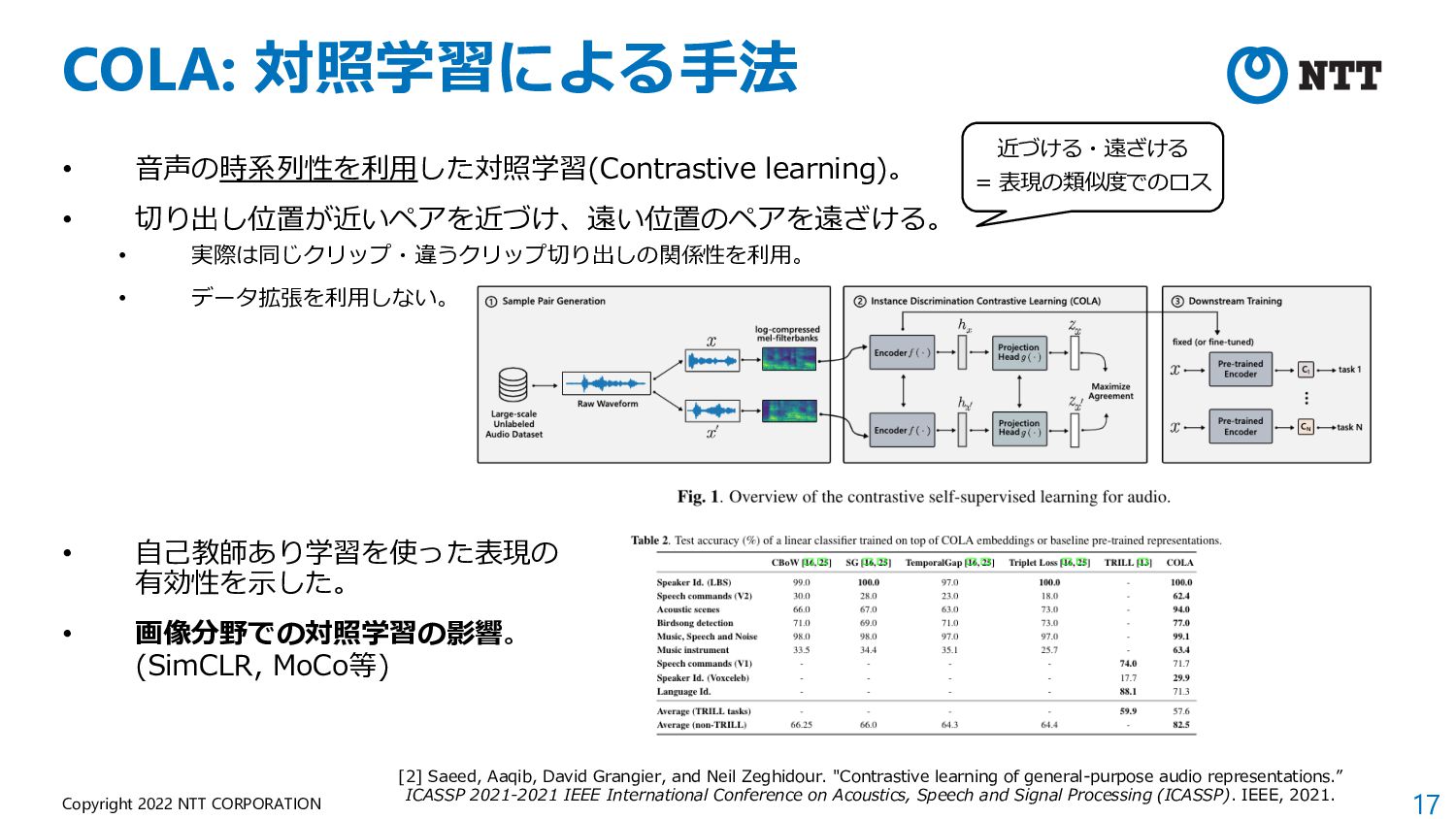
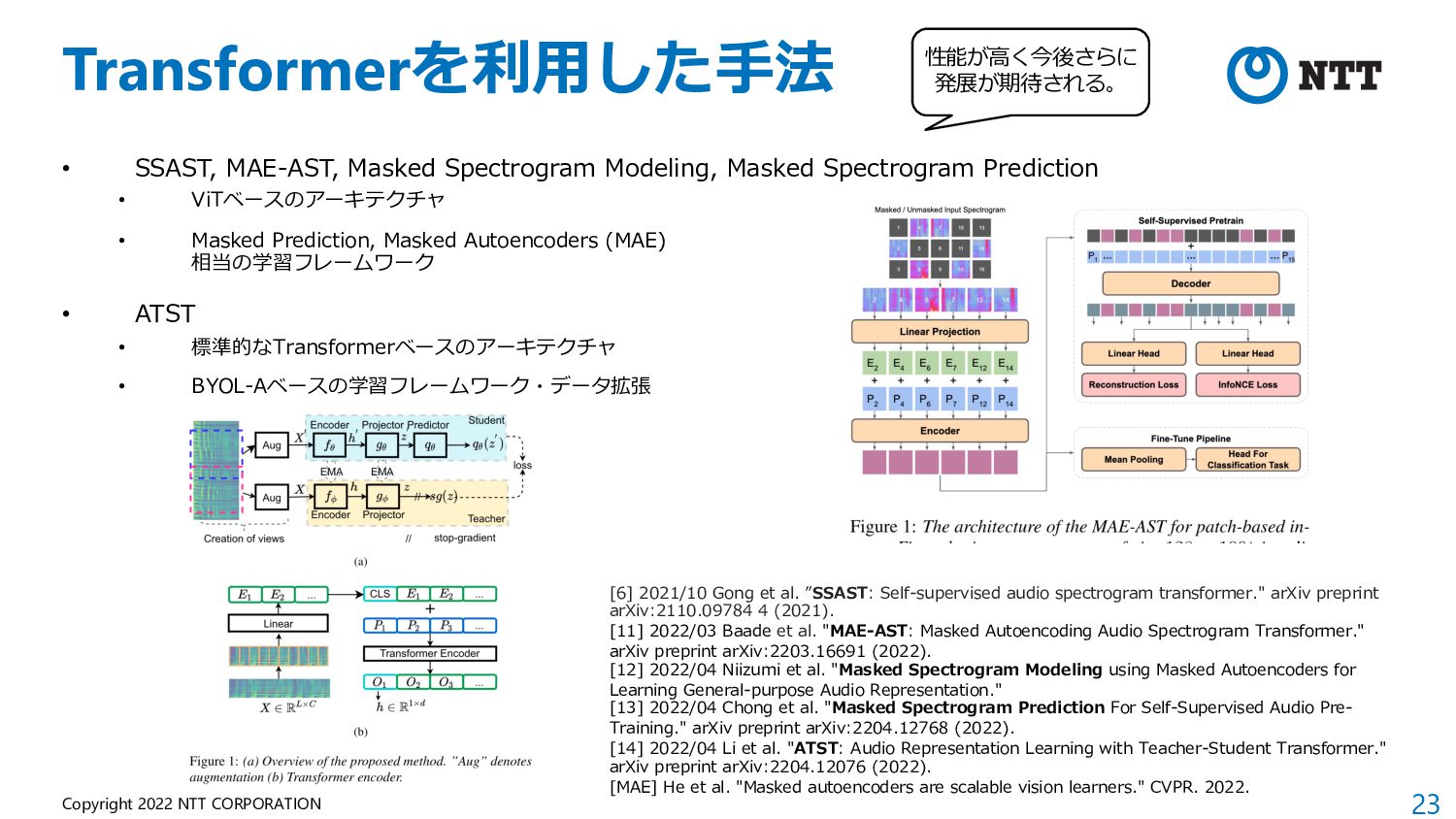
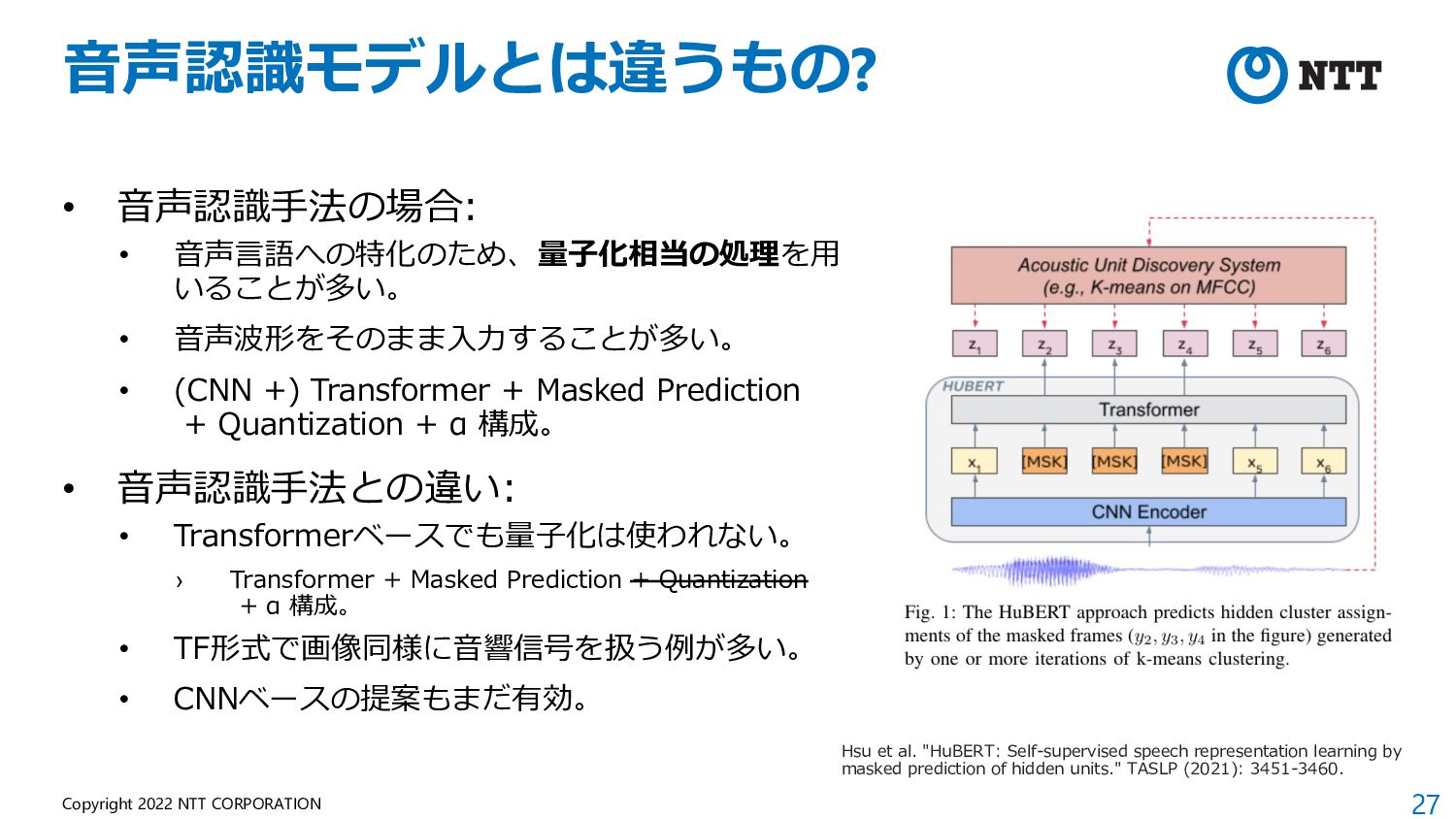
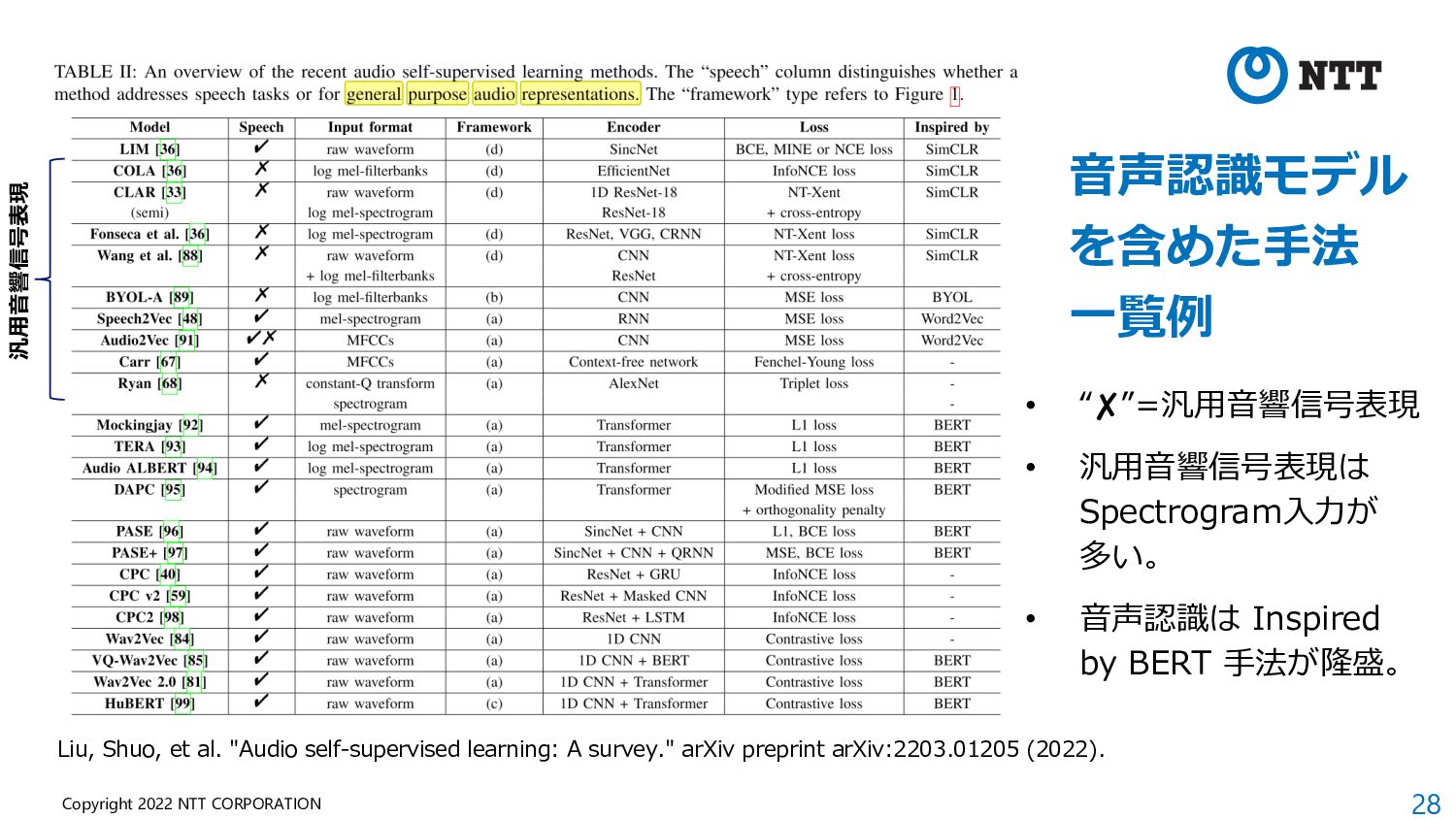
of Audio Representations) • NeurIPS 2021 Competition Track の⼀つとし て開催された際に提案されたベンチマーク。 • What approach best generalizes to a wide range of downstream audio tasks without fine-tuning? • 学習⽅法やデータセットを問わず、Frozenモデ ルの表現を19タスクで評価。 • ⾮意味的⾳声、⾳楽、環境 から幅広いタスク構成。 (マイナーなデータセットが 多く、⾳楽よりな印象) • 現在はHEAR Benchmark という名称で公開。 https://hearbenchmark.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 Copyright 2022 NTT CORPORATION 汎⽤⾳響信号表現: ~2022/6の⼿法⼀覧 [1] 2019/05 Self-supervised](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_14.jpg){kind=link}
![16 Copyright 2022 NTT CORPORATION 汎⽤⾳響信号表現: ~2022/6の⼿法⼀覧 [1] 2019/05 Self-supervised](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_15.jpg){kind=link}
{kind=link}
![18 Copyright 2022 NTT CORPORATION 汎⽤⾳響信号表現: ~2022/6の⼿法⼀覧 [1] 2019/05 Self-supervised](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_17.jpg){kind=link}
![19 Copyright 2022 NTT CORPORATION BYOL-A: BYOLを利⽤した⼿法 [3] Niizumi, Daisuke,](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_18.jpg){kind=link}
![20 Copyright 2022 NTT CORPORATION 汎⽤⾳響信号表現: ~2022/6の⼿法⼀覧 [1] 2019/05 Self-supervised](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_19.jpg){kind=link}
{kind=link}
![22 Copyright 2022 NTT CORPORATION 汎⽤⾳響信号表現: ~2022/6の⼿法⼀覧 [1] 2019/05 Self-supervised](https://files.speakerdeck.com/presentations/f0cf1e3d93234f1db67b5b00446badbf/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}