"value":{"warning":4,"error":3,"fatal":0}}, {"key":[2010,9], "value":{"warning":4,"error":6,"fatal":0}}, {"key":[2010,10],"value":{"warning":7,"error":6,"fatal":0}}, {"key":[2010,11],"value":{"warning":5,"error":8,"fatal":0}}, {"key":[2010,12],"value":{"warning":2,"error":2,"fatal":0}}, {"key":[2011,1], "value":{"warning":5,"error":1,"fatal":0}}, {"key":[2011,2], "value":{"warning":3,"error":5,"fatal":0}}, {"key":[2011,3], "value":{"warning":4,"error":4,"fatal":0}}, {"key":[2011,4], "value":{"warning":3,"error":6,"fatal":0}} ] } !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
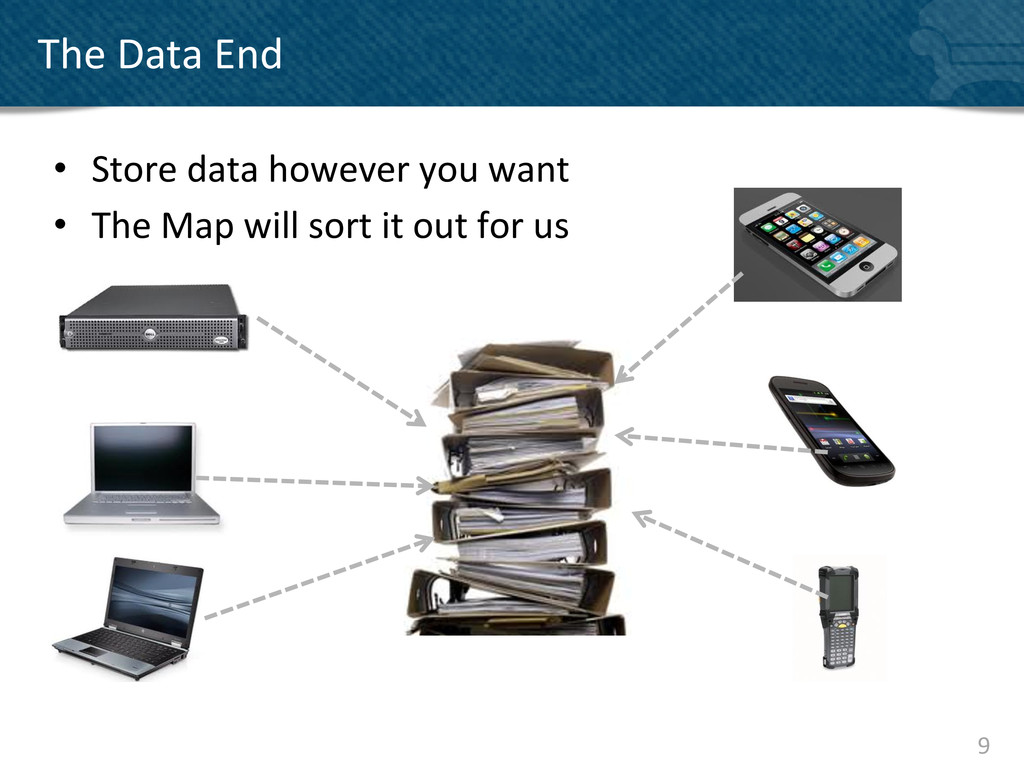{kind=link}
{kind=link}
{kind=link}
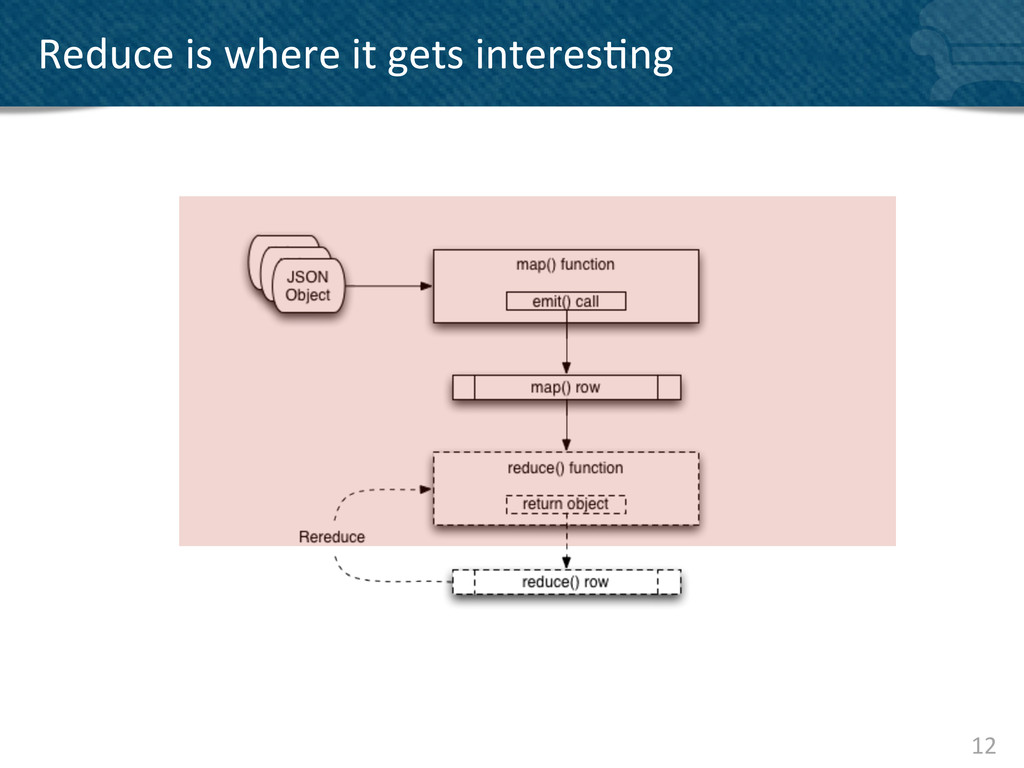{kind=link}
{kind=link}
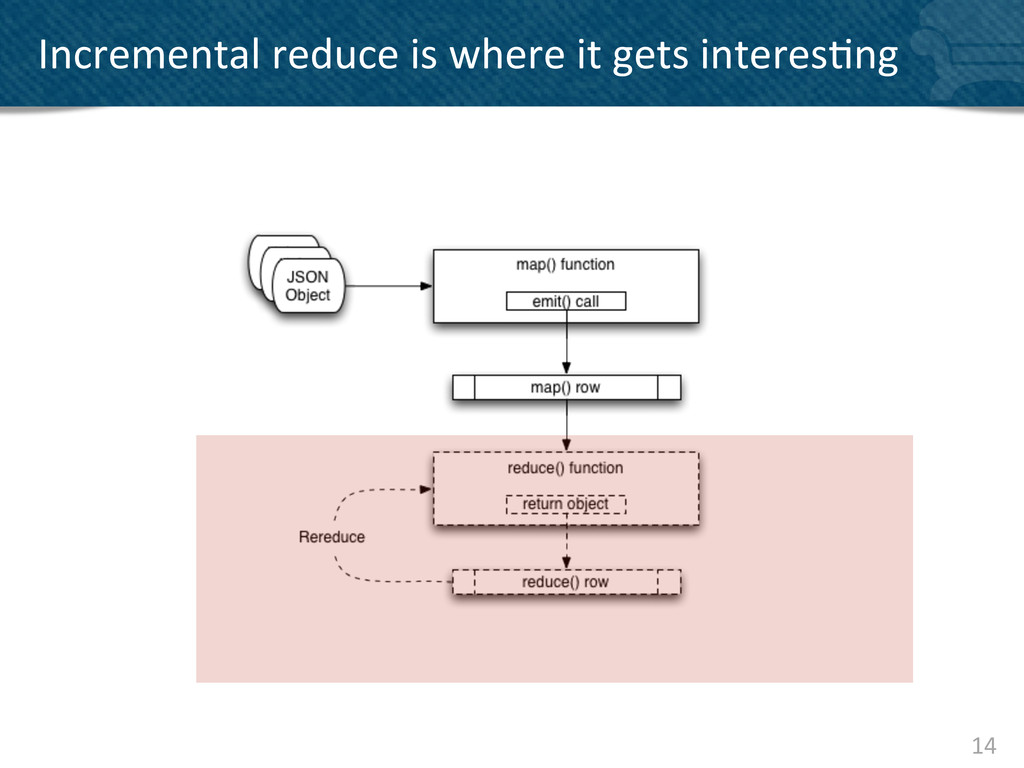{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![20 Complex reduce output {"rows":[ {"key":[2010,7], "value":{"warning":4,"error":2,"fatal":0}}, {"key":[2010,8],](https://files.speakerdeck.com/presentations/50602ab1ccf4a5000204ae4a/slide_19.jpg){kind=link}
{kind=link}
{kind=link}