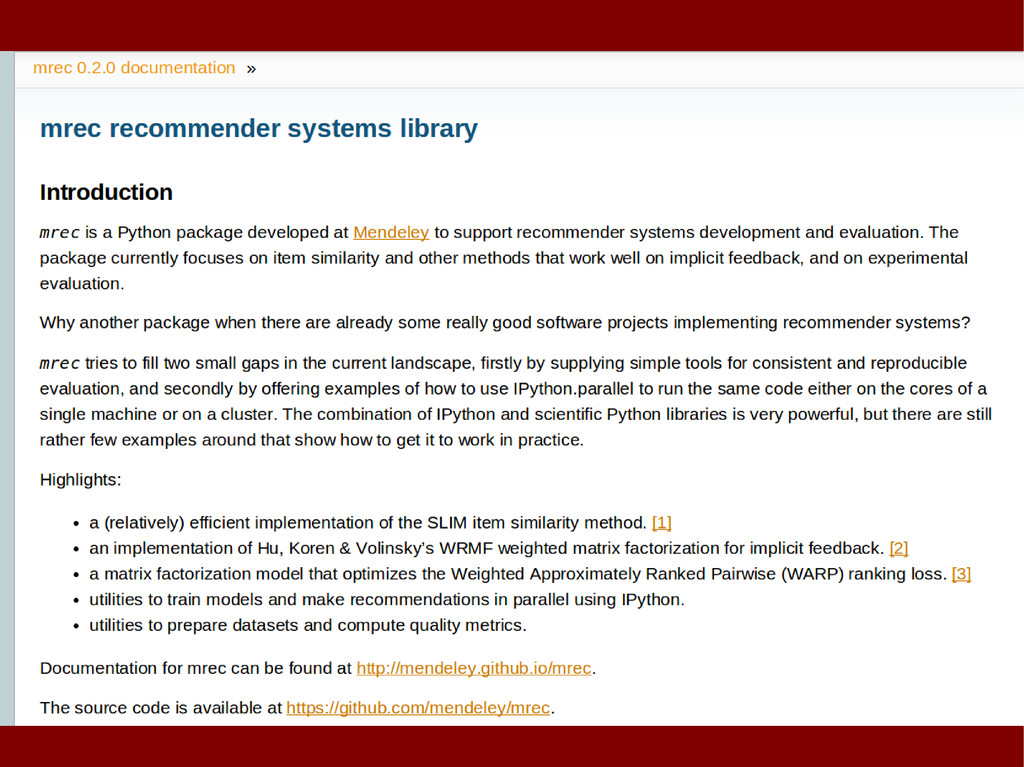
Serve new users asap • Fine to run a special system for either case • Most content leaks • … or is leaked • All serious commercial content is annotated
approach is that all elements the model should rank in the future are presented to the learning algorithm as negative feedback during training. That means a model with enough expressiveness (that can fit the training data exactly) cannot rank at all as it predicts only 0s. The only reason why such machine learning methods can predict rankings are strategies to prevent overfitting, like regularization.” Bayesian Personalized Ranking from Implicit Feedback Rendle et al., 2009
the rating values for those items that a user has deliberately chosen to rate. This kind of data can be collected easily, moreover [RMSE] … can easily be evaluated on the user-item pairs that actually have a rating value in the data. The objective of common real-world rating prediction tasks, however, is often different from this scenario: typically, the goal is to predict the rating value for any item in the collection, independent of the fact if a user rates it or not.” Evaluation of Recommendations: Rating-Prediction and Ranking Steck, 2013
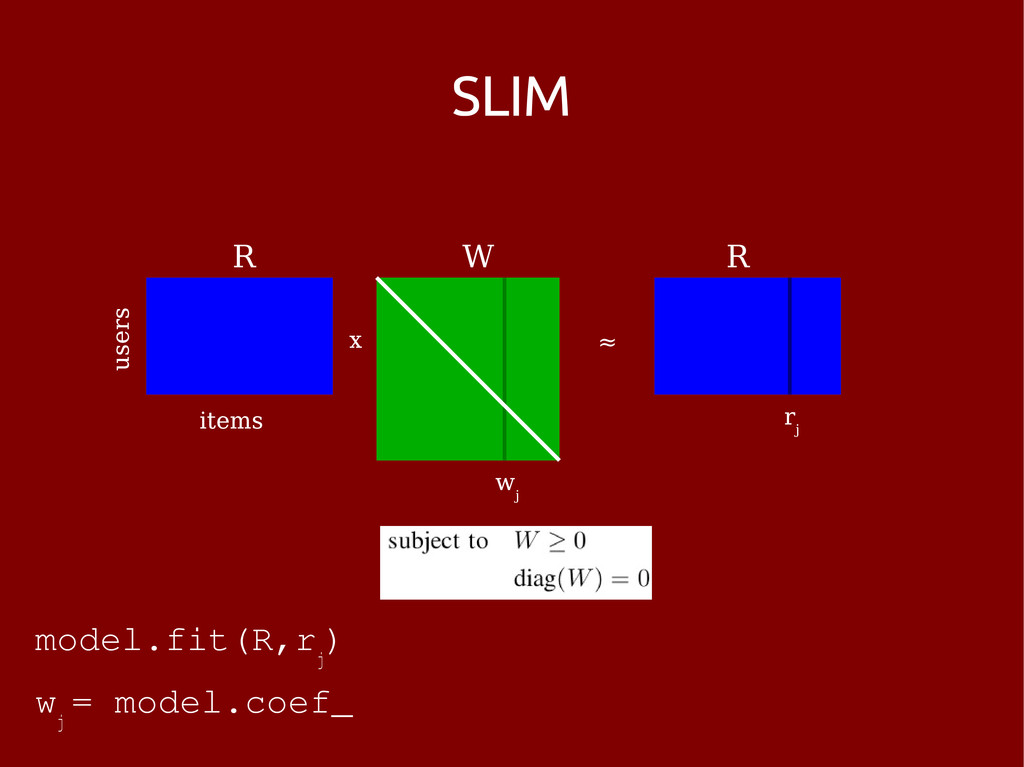
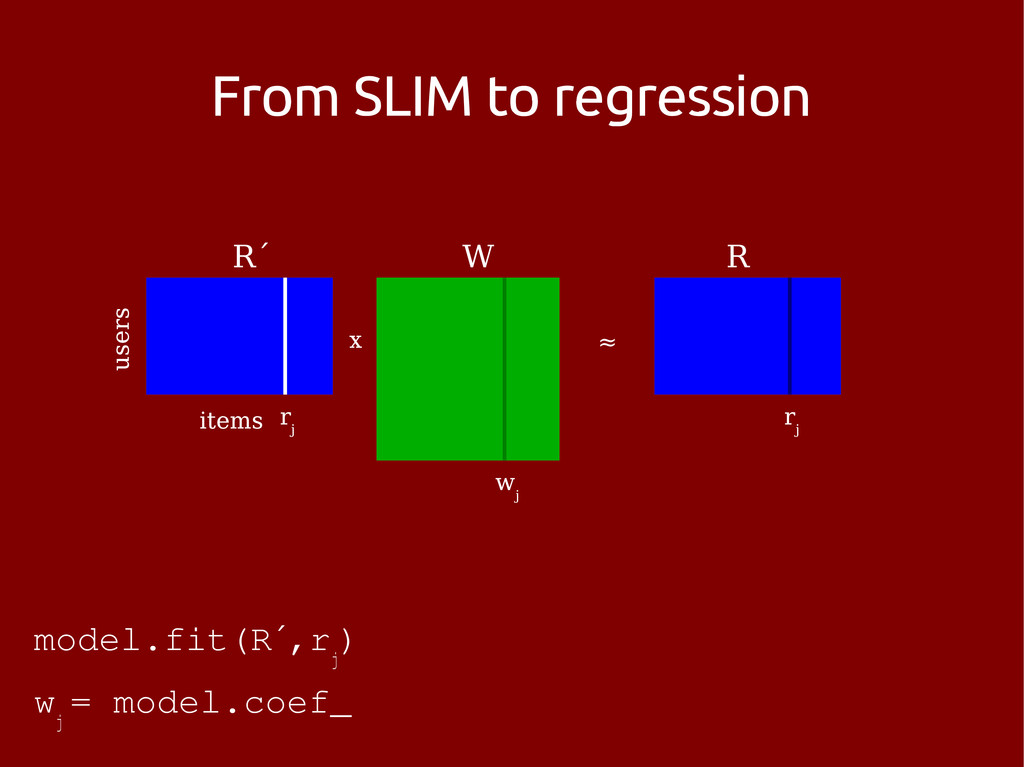
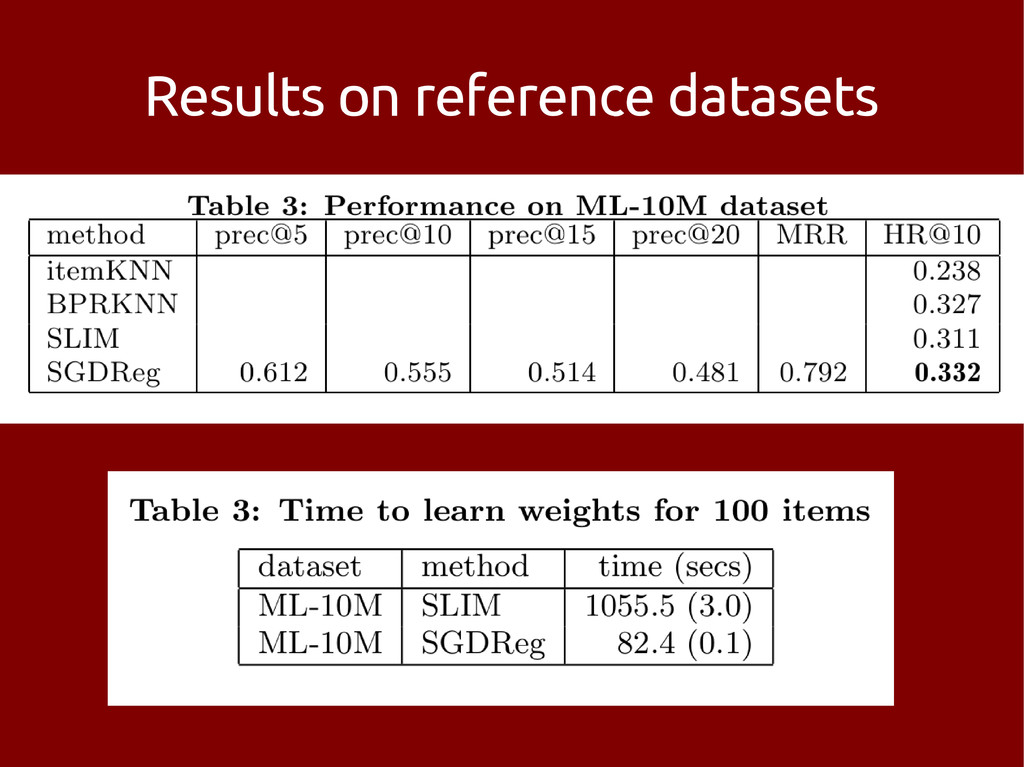
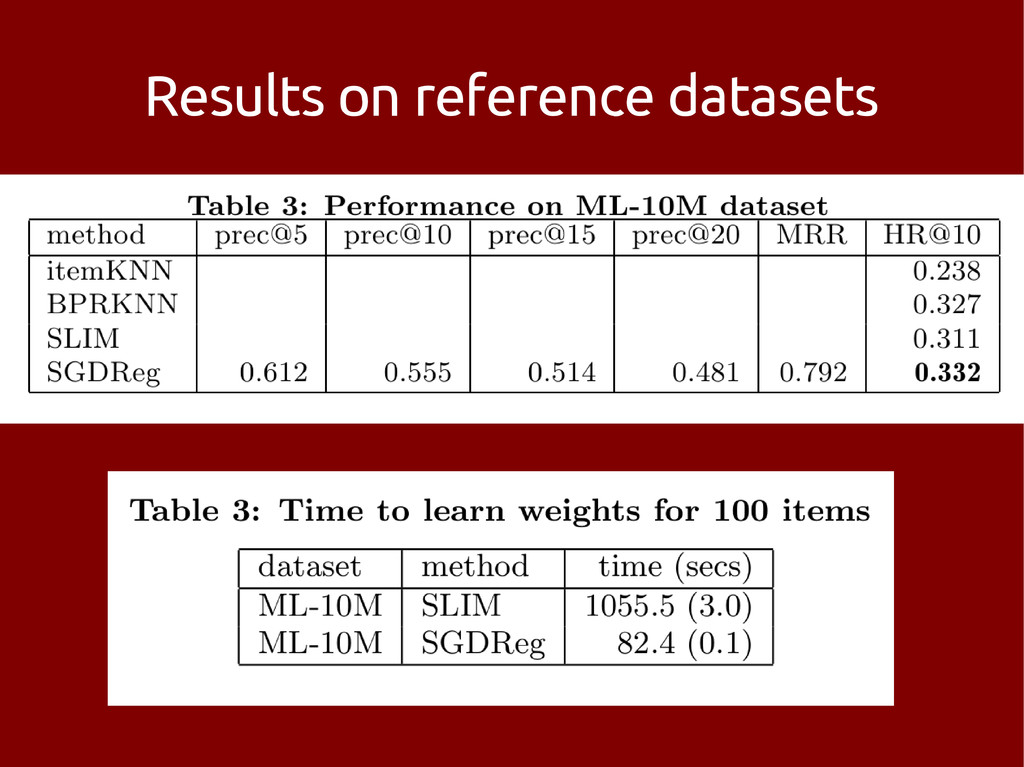
problem – with a constrained target item set • Possible state of the art c. April 2013: – pimped old skool neighbourhood method – matrix factorization and then neighbourhood – something dynamic (?) – SLIM • Use some side data
[1] – Easy extensions to include side data [2] Not so good: – Reported to be slow beyond small datasets [1] [1] X. Ning and G. Karypis, SLIM: Sparse Linear Methods for Top-N Recommender Systems, Proc. IEEE ICDM, 2011. [2] X. Ning and G. Karypis, Sparse Linear Methods with Side Information for Top-N Recommendations, Proc. ACM RecSys, 2012.
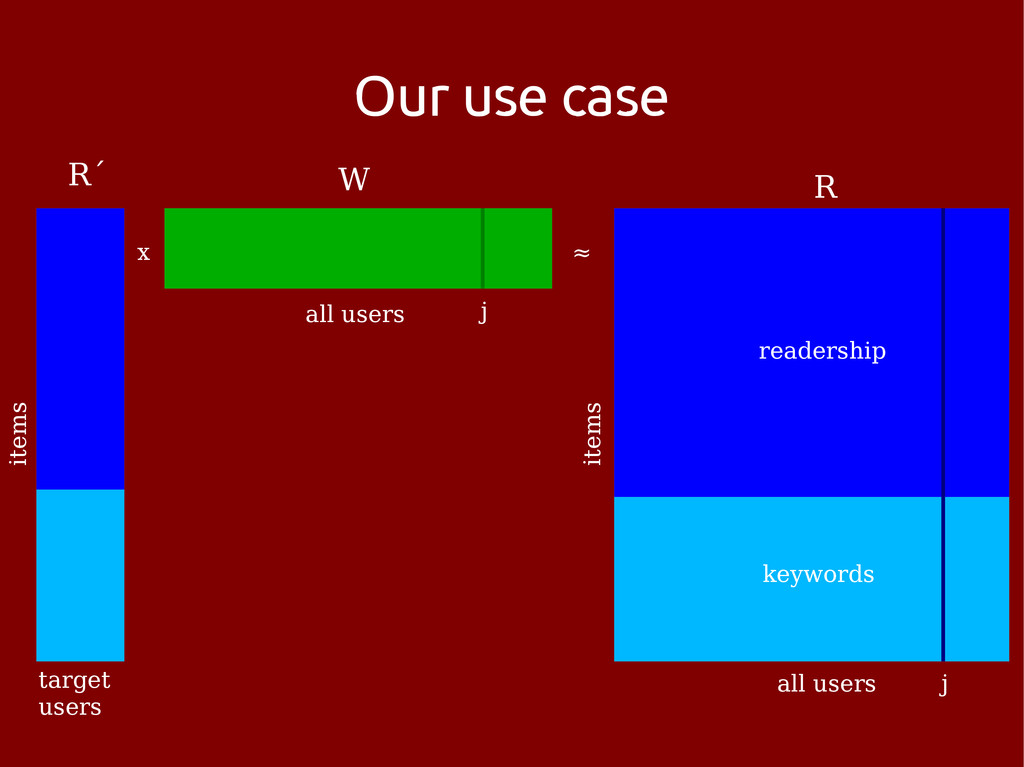
• 5M docs/keywords, 1M users, 140M non-zeros • Constrained to ~100k target users • Python implementation on top of scikit-learn – Trivially parallelized with IPython – eats CPU but easy on AWS • 10% improvement over nearest neighbours • 5% CTR in email test
want sparsest similarity lists that are not too sparse – “too sparse” = # items with < k similar items • Grid search with a small sample of items • Empirically corresponds well to optimising recommendation accuracy of a validation set – but faster and easier
Model fit metrics (e.g. validation loss) don't count – Need a transparent “audit trail” of data to support genuine reproducibility – Just using public datasets doesn't ensure this
– Integrate with recommender implementations – Handle data formats and preprocessing – Handle splitting, cross-validation, side datasets – Save everything to file – Work from file inputs so not tied to one framework – Generate meaningful metrics – Well documented and easy to use
Reports meaningful metrics – Handles cross-validation – Data splitting not transparent – No support for pre-processing – No built in support for standalone evaluation – API is capable but current utils don't meet wishlist
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Solving the Wrong Problem “The problem with [the rating prediction]](https://files.speakerdeck.com/presentations/ed261a105e69013173e40a94ad68b80e/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
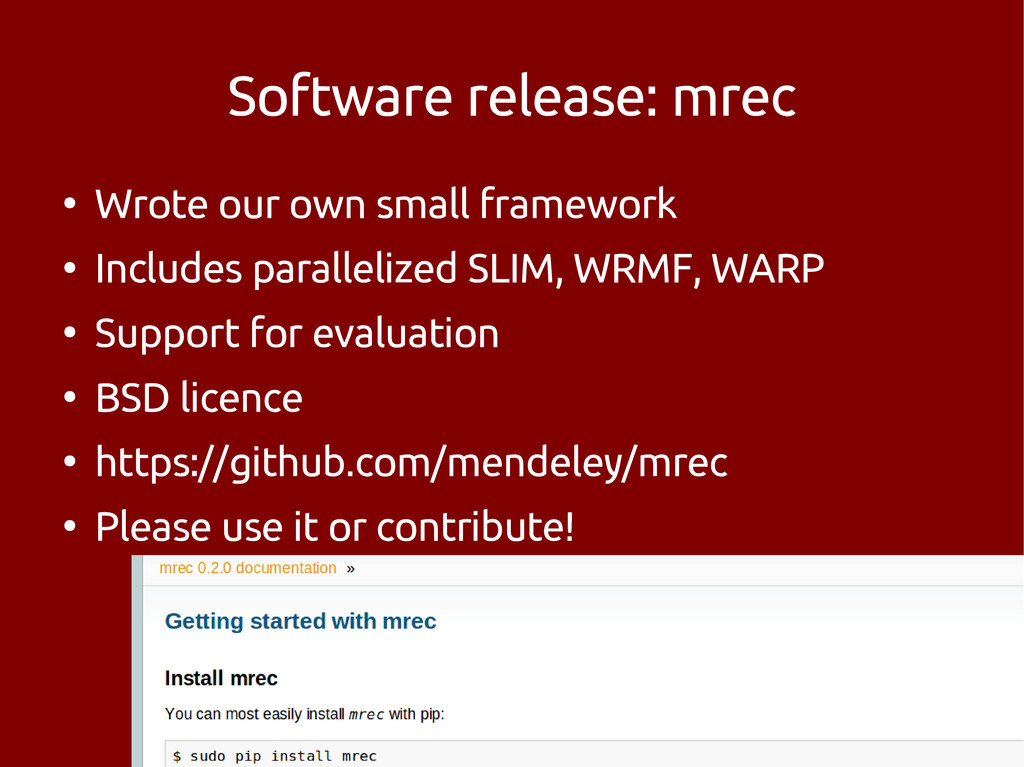
![Thanks for listening [email protected] @gamboviol https://github.com/mendeley/mrec goodbye hello](https://files.speakerdeck.com/presentations/ed261a105e69013173e40a94ad68b80e/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}