Data team) – Descriptive/exploratory statistics – Clustering – Recommender systems • PhD in Recommender Systems and Machine Learning – Recommender System algorithm design – Optimisation – Dynamic systems
– User ratings – User reviews • Implicit preferences – Preference inferred from logs – Purchases • Additional (content based) data features – Type of the item (e.g. genre for movies) • Context aware features – Time of recommendation – Mood, weather, location – Business objectives (e.g. profit, risk)
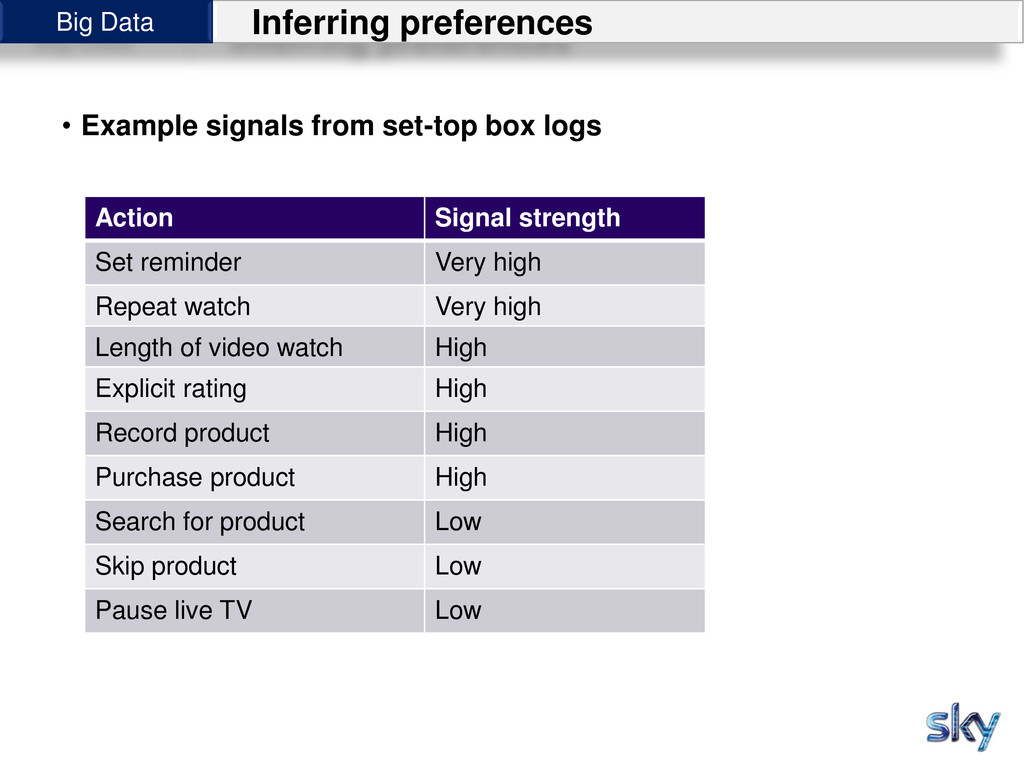
logs Action Signal strength Set reminder Very high Repeat watch Very high Length of video watch High Explicit rating High Record product High Purchase product High Search for product Low Skip product Low Pause live TV Low
package (aggregate, tapply) • sqldf package – SQL like queries • plyr package – Splits the data and combines it after processing – Wide variety of aggregate functions – Intuitive syntax • data.table package – Very fast (ideal for bigger data sets) • reshape package – Additional package for data manipulation (e.g. convert table from wide to long format)
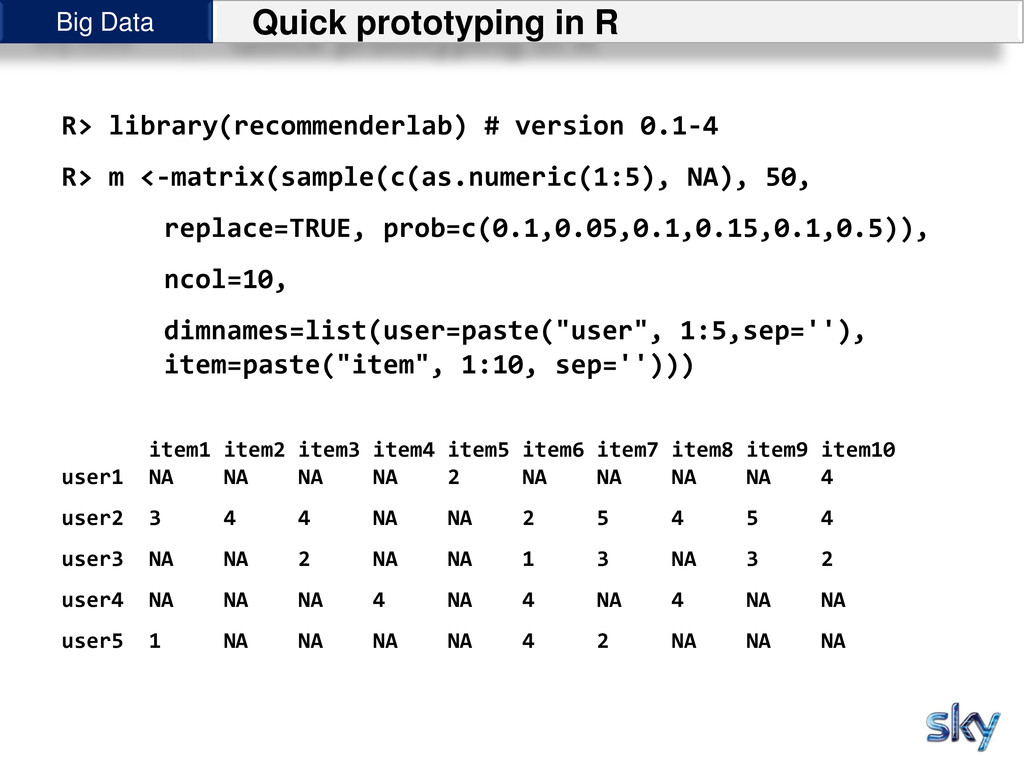
0.1-4 R> m <-matrix(sample(c(as.numeric(1:5), NA), 50, replace=TRUE, prob=c(0.1,0.05,0.1,0.15,0.1,0.5)), ncol=10, dimnames=list(user=paste("user", 1:5,sep=''), item=paste("item", 1:10, sep=''))) item1 item2 item3 item4 item5 item6 item7 item8 item9 item10 user1 NA NA NA NA 2 NA NA NA NA 4 user2 3 4 4 NA NA 2 5 4 5 4 user3 NA NA 2 NA NA 1 3 NA 3 2 user4 NA NA NA 4 NA 4 NA 4 NA NA user5 1 NA NA NA NA 4 2 NA NA NA
<- evaluationScheme (MovieLense,method="split",train=0.8) • k-fold cross-validation R> scheme <- evaluationScheme (MovieLense,method="cross-validation",k=10) • Bootstrap sampling R> scheme <- evaluationScheme (MovieLense,method=“bootstrap",k=10,train=0.8) • Additional parameters – goodRating – defines relevance threshold for top-N evaluators – given – number of (fixed length) items given to use for prediction – train – percentage of users used for training
based on user-based collaborative filtering (explicit ratings). • IBCF - Recommender based on item-based collaborative filtering (explicit ratings). • SVD - Recommender based on SVD approximation (explicit ratings). • POPULAR - Recommender based on item popularity (explicit ratings). • RANDOM - Produce random recommendations (explicit ratings).
packages to enhance recommendation – Most statistical tools are available – Quick prototyping – Compact code – Good visualisation tools • Disadvantages – Some base functions are slow (e.g. loops) – Steep learning curve – Scaling
![Recommender Systems in R Tamas Jambor (@jamborta) [email protected]](https://files.speakerdeck.com/presentations/1489b0c05bee013025f71231381b23b3/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
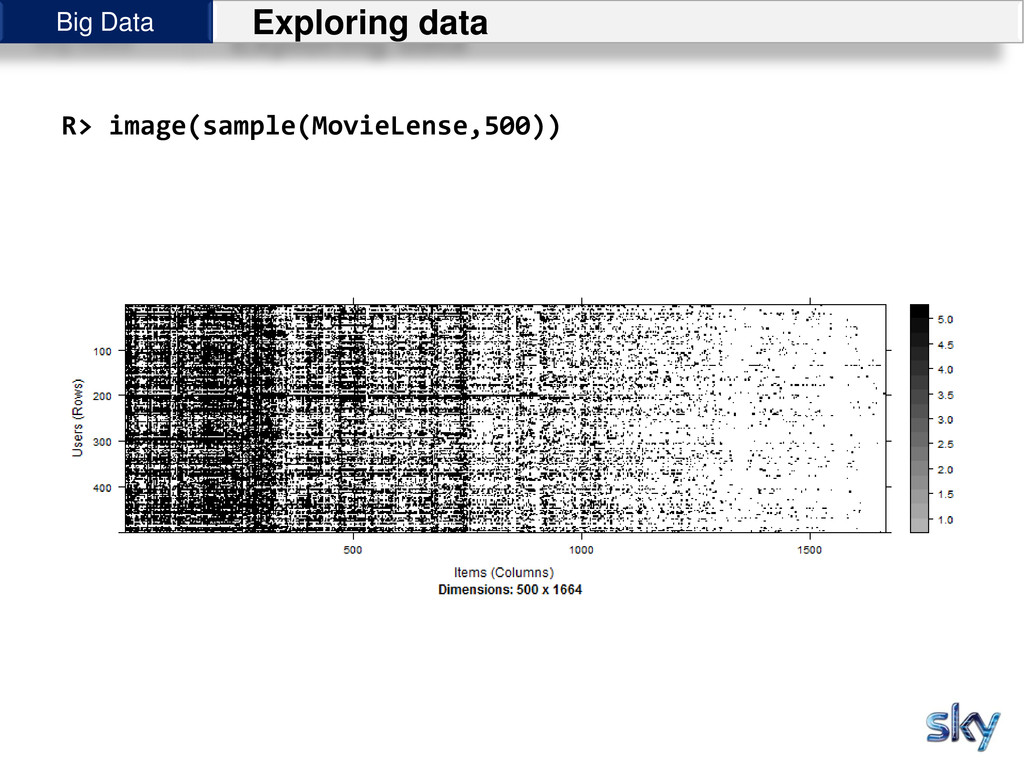{kind=link}
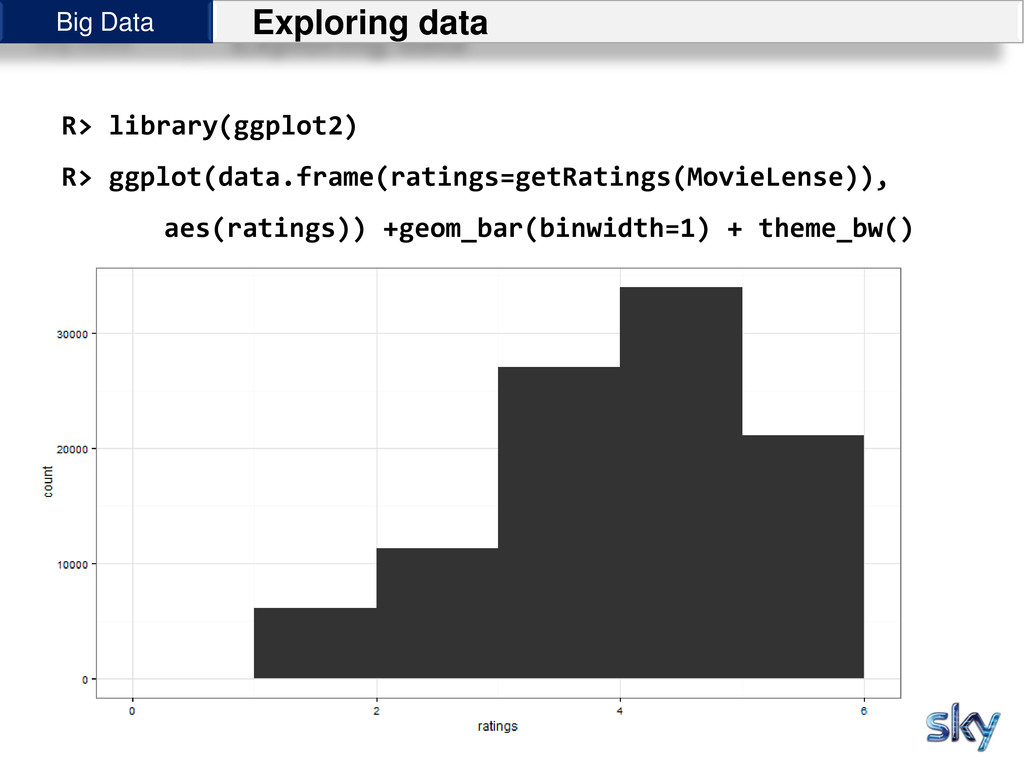{kind=link}
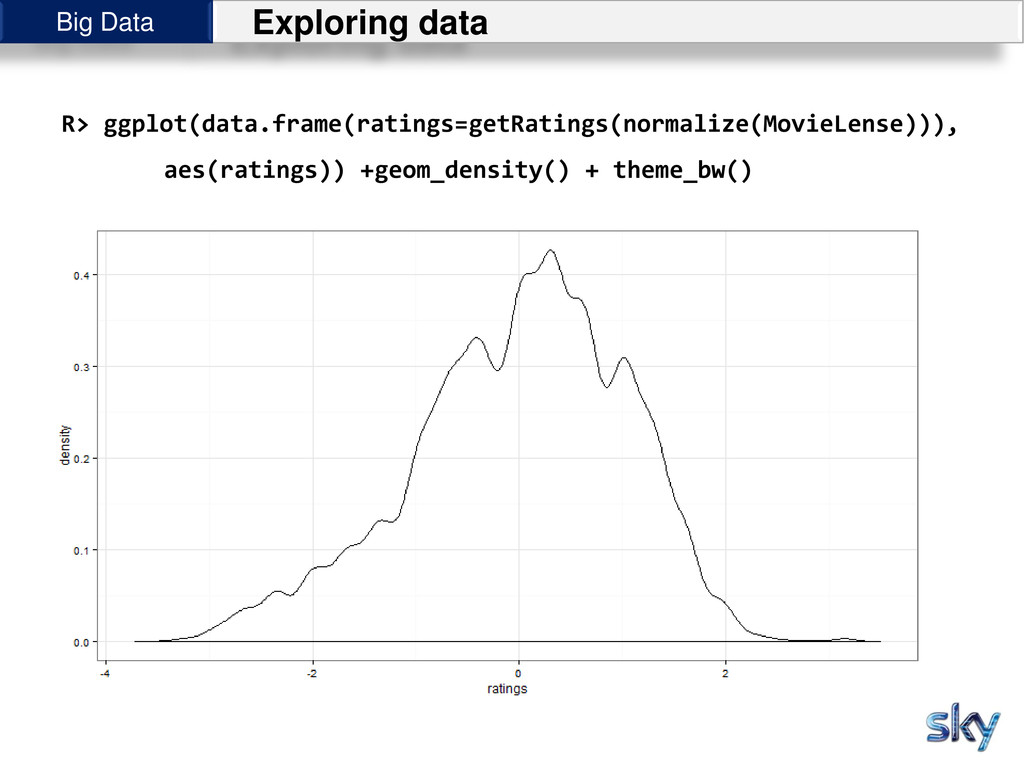{kind=link}
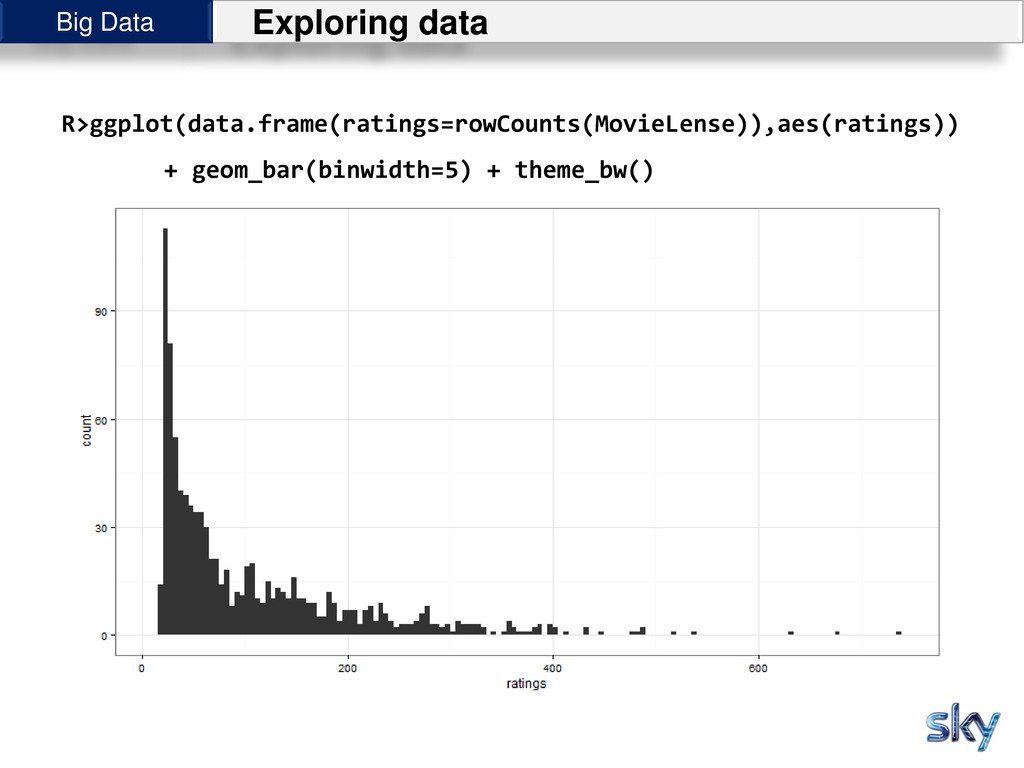{kind=link}
{kind=link}
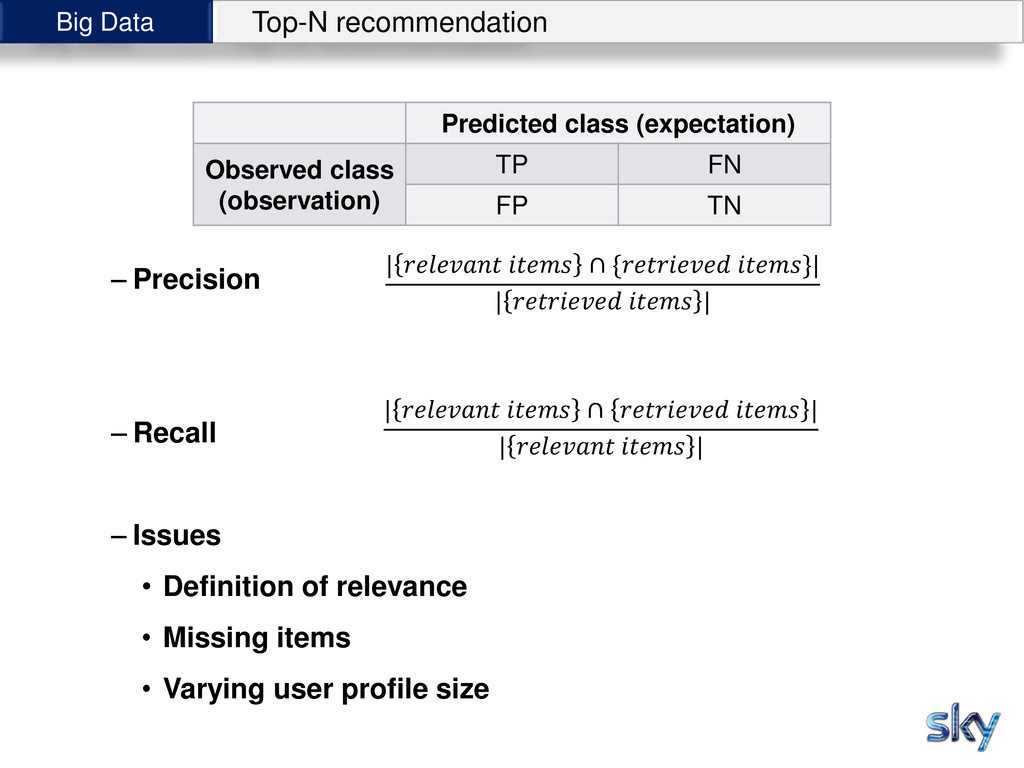{kind=link}
{kind=link}
{kind=link}
{kind=link}
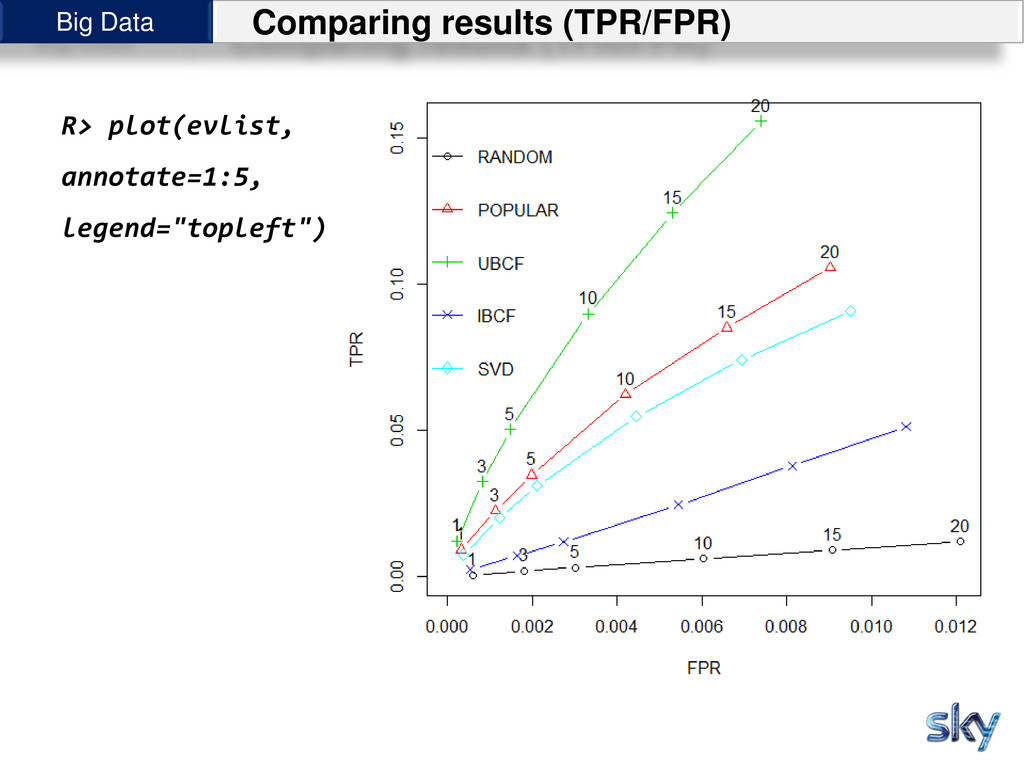{kind=link}
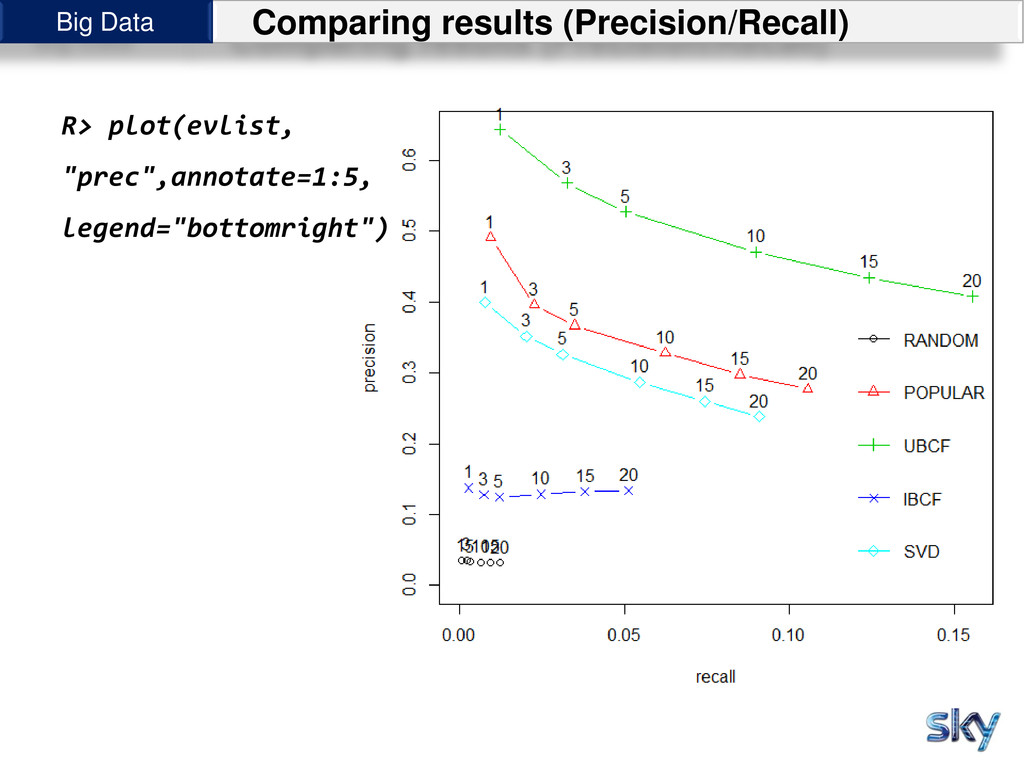{kind=link}
{kind=link}
{kind=link}