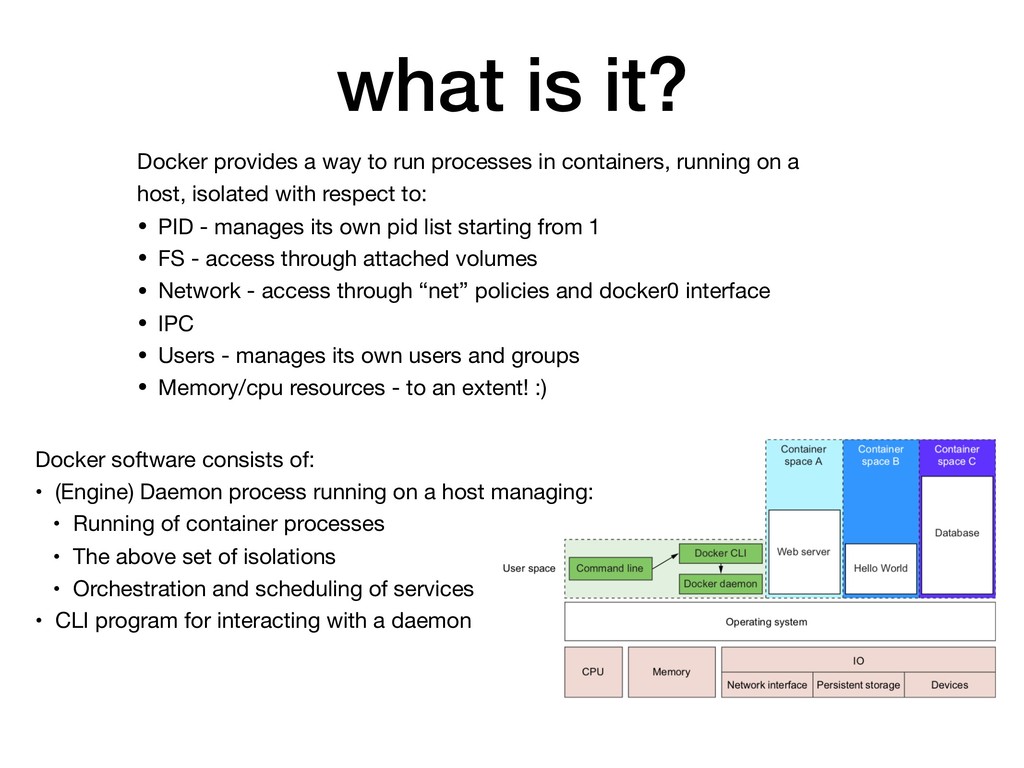
in containers, running on a host, isolated with respect to: • PID - manages its own pid list starting from 1 • FS - access through attached volumes • Network - access through “net” policies and docker0 interface • IPC • Users - manages its own users and groups • Memory/cpu resources - to an extent! :) Docker software consists of: • (Engine) Daemon process running on a host managing: • Running of container processes • The above set of isolations • Orchestration and scheduling of services • CLI program for interacting with a daemon
a file system - layered, so generally maintains a list of FS changes kind of like Git - at the expense of space - only top level is R/W - images can be tagged and stored locally in the image index, and remotely in a registry - provides root access by default When managed individually, images are generally created by this process: - “docker pull <user>/<image>:<tag>” - starting with a OS base image (eg. library/busybox:latest) - “docker run -d” or* “docker create” to apply modifications - “docker diff” to inspect changes - “docker commit” to save the changes to a new image name - “docker push” to push the changes to a repo * the difference between run (-d is detached) and create is that “create” never starts the container
pull busybox:latest docker tag busybox:latest localhost:5000/busybox docker push localhost:5000/busybox docker rmi busybox:latest docker pull localhost:5000/busybox:latest docker run --name mylinux -it localhost:5000/busybox:latest touch helloworld.txt 2> docker ps 2> docker diff mylinux 2> docker commit mylinux localhost:5000/mylinux 2> docker push localhost:5000/mylinux 2> docker rm -f mylinux 2> docker rmi localhost:5000/busybox:latest 2> docker pull localhost:5000/mylinux:latest 2> docker run --name mylinux2 -it localhost:5000/mylinux 2> ls start a registry -> pull latest from docker hub -> make a new tag for our repo -> push the copied image to repo -> remove the busy box image -> test pulling the new image -> run our image with a name -> modify it -> list of running containers -> differences to base image -> commit changes to a new image -> push them to the repo -> remove the old container -> remove the new image -> test pulling the new image -> run our image with a name -> check helloworld.txt is there ->
\ —-entrypoint=“cat” --name mygreatcontainer \ --link registry:reghost \ --cidfile /tmp/web.cid \ -e SOMEPASSWORD=probablyHsbc \ -p 80 \ -p 8000:8080 \ -v /tmp/:/usr/44100334 \ -v /run/lock/apache2/ \ --volumes-from registry \ --net bridge \ -u root:root \ library/busybox:latest run detached -> set the container “entrypoint” -> name container (in docker ps) -> link other container as hostname “reghost” -> save the container ID file here -> set an environment variable -> publish port 80 -> publish port external:internal -> mount a local dir as a volume -> mount a managed volume -> import volumes from a container -> set network setting -> set the running user -> use this image ->
/local/volume:/path/inside/ container w Sharing data with external processes Not portable Managed -v /local/volume Decoupling, and multi-use Less easy to work with Imported —-volumes-from <container> Managing complex setups, transitivity Can’t vary mount point across containers
provides a set of files (imported via volume options), which are then automatically picked up by the parent when running - eg. A node.JS parent image which launches an app.js file in a known folder (also containing node_modules) - Use ONBUILD hooks in non-instantiable parent images, and then have child images provide the implementations called by these hooks. - eg. Configuration for a market-specific implementation of a Global Platform In both of these approaches, the “shape” and control of the image is still provided by the parent image.s
defining, managing and launching services - it provides some level of Orchestration - a service is a set of replicas of a particular docker container - modelled in YML-file, defining systems of services and links between them: registry: build: ./registry ports: - "5555:5000" links: - pump:webhookmonitor environment: - COFFEEFINDER_DB_URI=postgresql://postgres:5432/db - COFFEEFINDER_CONFIG=development - SERVICE_NAME=coffee pump: build: ./pump expose: - "8000" links: - elasticsearch:esnode elasticsearch: image: elasticsearch:1.6 ports: - "9200:9200" command: "-Des.http.cors.enabled=true" docker build -t <user>/<image>:<tag> <image> a container name -> build from this Dockerfile location -> port mapping -> container links -> environment -> port mapping ->
container commands: ps up/down kill restart/start/stop/kill rm scale top logs building commands: build config images Note: this command set is very like the docker cli command set, just at a different level of abstraction
creating and managing fleets of docker daemons - Create a new machine locally with: - Or add an existing remote machine with: docker-machine create --driver virtualbox host1 - List machines: eval "$(docker-machine env host1)” - You can easily switch the active “docker cli” target machine with …then interact as if the machine was local: commands: ls env inspect ssh scp mount start/stop/kill rm docker-machine create --driver none -url=tcp://139.162.3.130:2376 host2
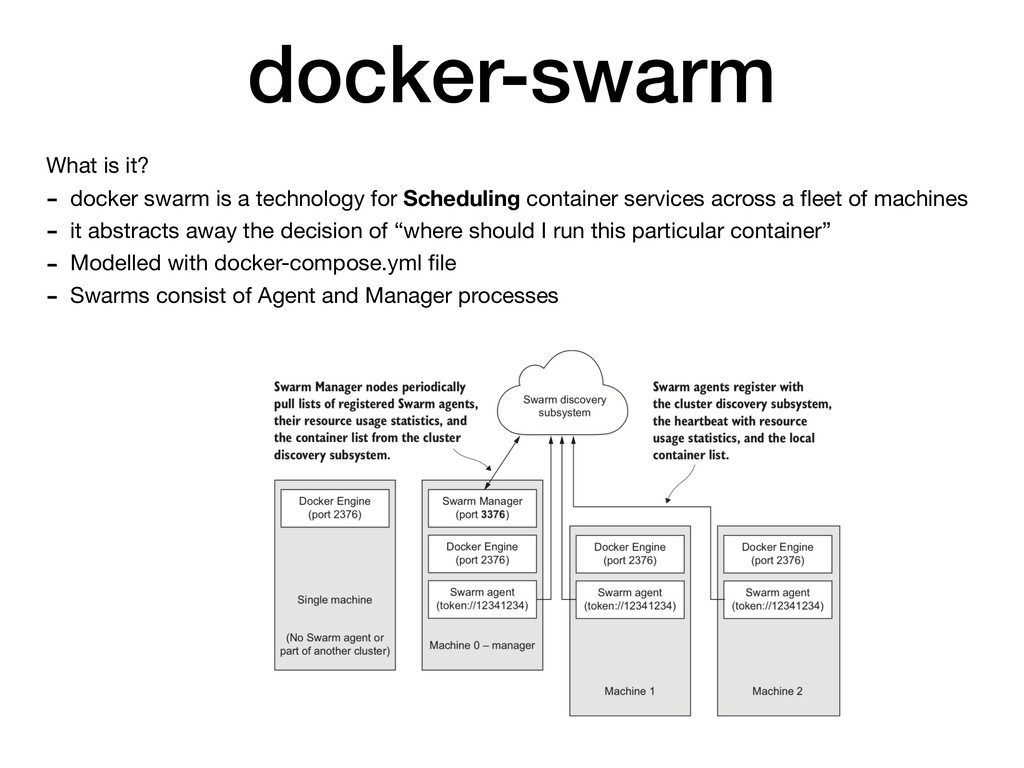
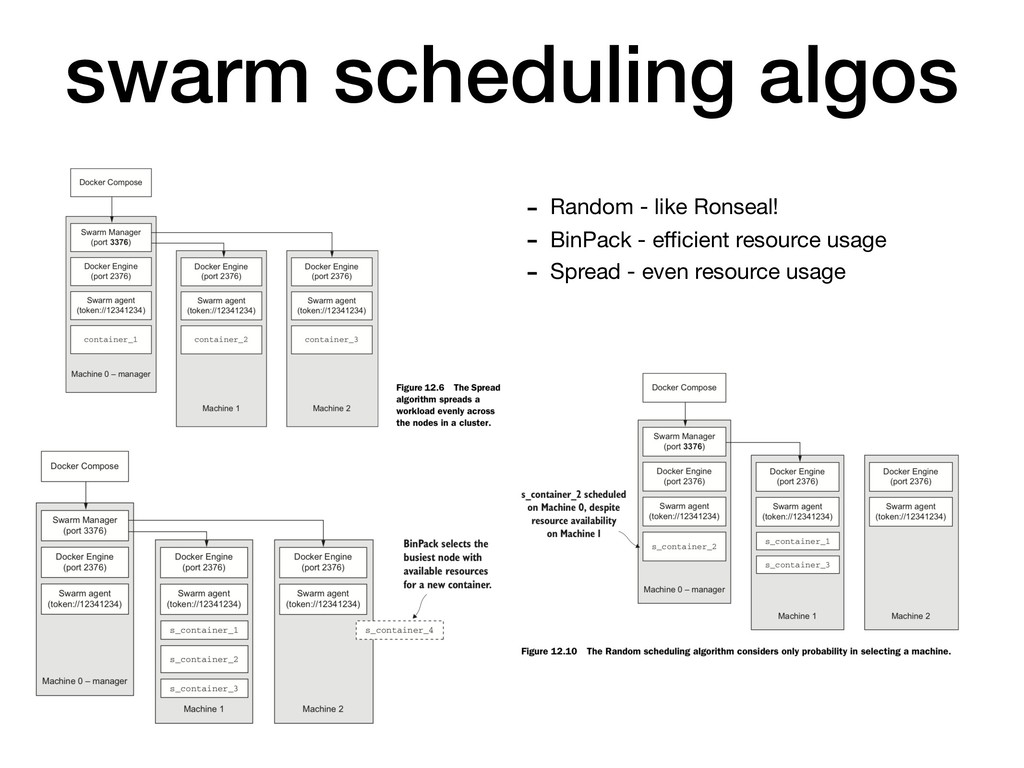
for Scheduling container services across a fleet of machines - it abstracts away the decision of “where should I run this particular container” - Modelled with docker-compose.yml file - Swarms consist of Agent and Manager processes
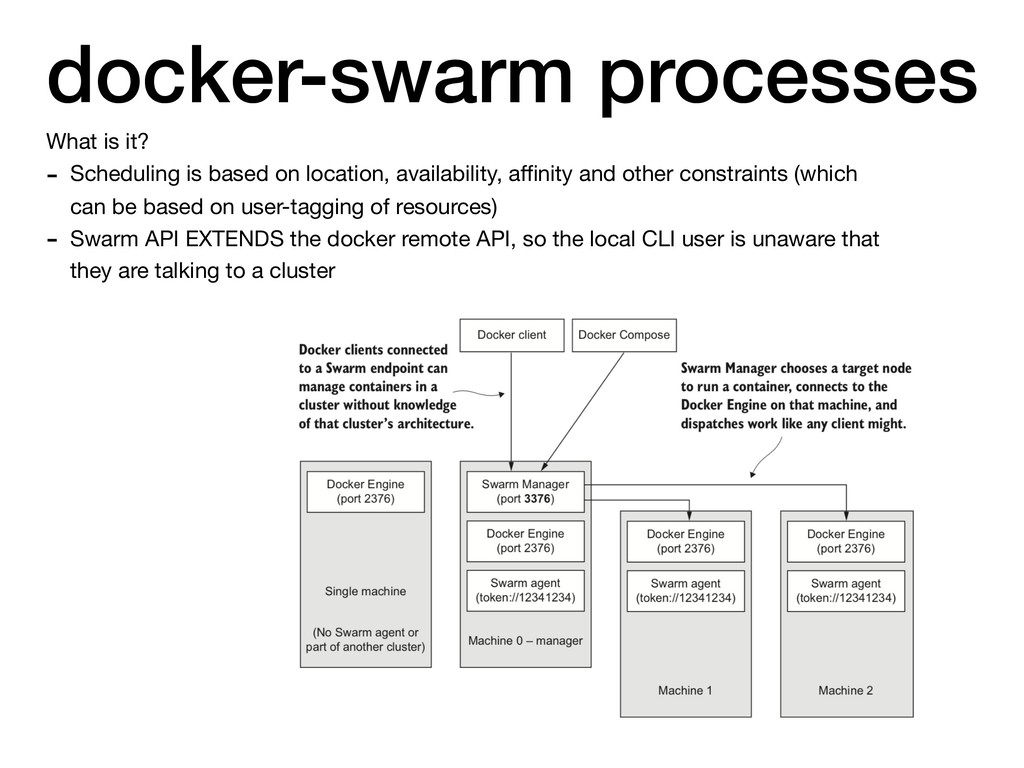
location, availability, affinity and other constraints (which can be based on user-tagging of resources) - Swarm API EXTENDS the docker remote API, so the local CLI user is unaware that they are talking to a cluster
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}