Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
The 1960s elegance behind Go's regexp
Search
Jalem Raj Rohit
March 19, 2017
Programming
200
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
The 1960s elegance behind Go's regexp
The presentation is given at FOSS Asia Summit 2017
Jalem Raj Rohit
March 19, 2017
More Decks by Jalem Raj Rohit
See All by Jalem Raj Rohit
Training and leveraging graph embeddings at scale
dawny33
2
110
Lessons learned from building serverless, distributed architecture
dawny33
1
150
Regression Analysis: The good, the bad and untold
dawny33
2
440
Understanding Serverless Architectures
dawny33
2
1.6k
Other Decks in Programming
See All in Programming
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
540
霧の中の代数的エフェクト
funnyycat
1
430
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
150
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
170
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
8
3.3k
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
What's New in Android 2026
veronikapj
0
190
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
350
生成AI導入の「期待外れ」を乗り越える ー 開発フロー改革が目指す、真の組織変革
starfish719
0
2.1k
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
220
自作OSでスライド発表する
uyuki234
1
3.9k
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
It's Worth the Effort
3n
188
29k
30 Presentation Tips
portentint
PRO
1
350
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Raft: Consensus for Rubyists
vanstee
141
7.6k
New Earth Scene 8
popppiees
3
2.4k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
Designing for Performance
lara
611
70k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Faster Mobile Websites
deanohume
310
32k
From π to Pie charts
rasagy
0
240
Transcript
The 1960s elegance behind Go’s regexp 19 MarchFOSS Asia ‘17
Jalem Raj Rohit
What this talk is about? About the two approaches to
regex matching. - One used in almost all standard regex interpreters, like Python, Perl, etc - The other one used in some implementations like, awk, grep, sed, etc And Go, of course
What exactly are Regular Expressions? - It’s a style of
describing character strings - If a string successfully describes a regex, then it is called a match
Examples: Let’s say e1 matches “s” and e2 matches “t”:
➔ Alternation If e1 | e2 ⇒ s or it ➔ Concatenation e1 e2 ⇒ st. ➔ e1* 0 or more s ➔ e1+ 1 or more s
Perl vs Golang time comparison for matching a?a?a?aaa with respect
to the string length
Aaaand welcome to: The world of super awesome Computer Science
! and Super awesome algorithms !
Meet Finite Automata - It’s also known as State Machines
- ← This one is a Deterministic Finite Automata (or a DFA)
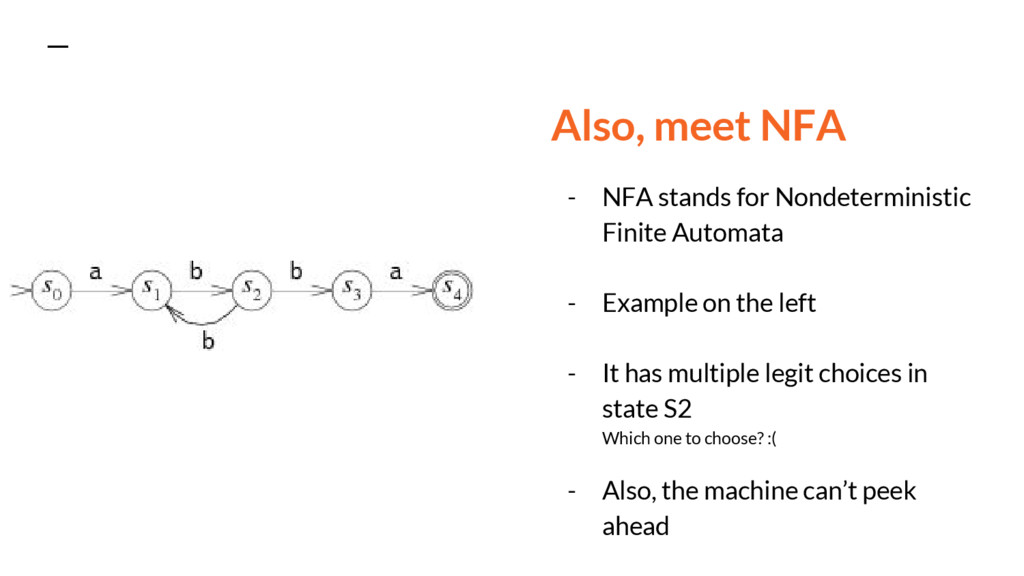
Also, meet NFA - NFA stands for Nondeterministic Finite Automata
- Example on the left - It has multiple legit choices in state S2 Which one to choose? :( - Also, the machine can’t peek ahead
Converting Regexes to NFAs - This would be the basic
unit of the NFA - Concatenation be like: - Aaaand alternation
Perl’s algorithm at work - Also, called the backtracking approach
- Time complexity grows exponentially for pathological regex matches, as the string size grows. - Literally, out of the window
Can we make this better?
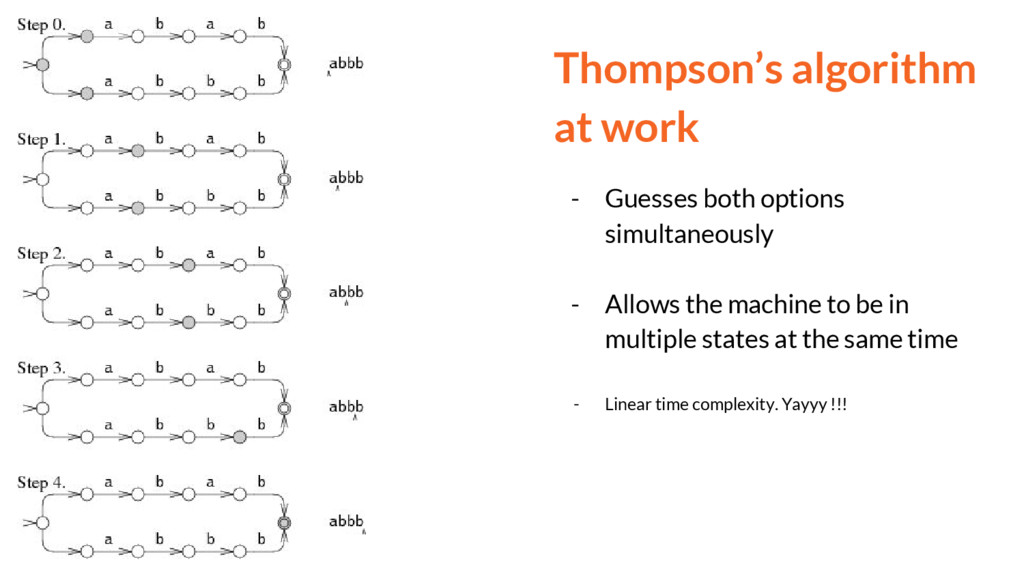
Thompson’s algorithm at work - Guesses both options simultaneously -
Allows the machine to be in multiple states at the same time - Linear time complexity. Yayyy !!!
Again, comparison of the algorithms
Again ….
Special Shoutout to GopherData - An attempt to bring together
Go’s and gophers’ efforts in Data Science and Analytics - Github: https://github.com/gopherdata - Twitter: https://twitter.com/GopherDataIO
THANK YOU - Github: Dawny33 - Twitter: @data__wizard (<-- 2
_’s there) - Facebook: rajrohit.33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}