[AAMAS22] Lazy-MDPs: Towards Interpretable RL by Learning When to Act
Jacq, Alexis, et al. "Lazy-MDPs: Towards Interpretable RL by Learning When to Act." Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems. 2022.
Jacq, Alexis, et al. "Lazy-MDPs: Towards Interpretable RL by Learning When to Act." Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems. 2022.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
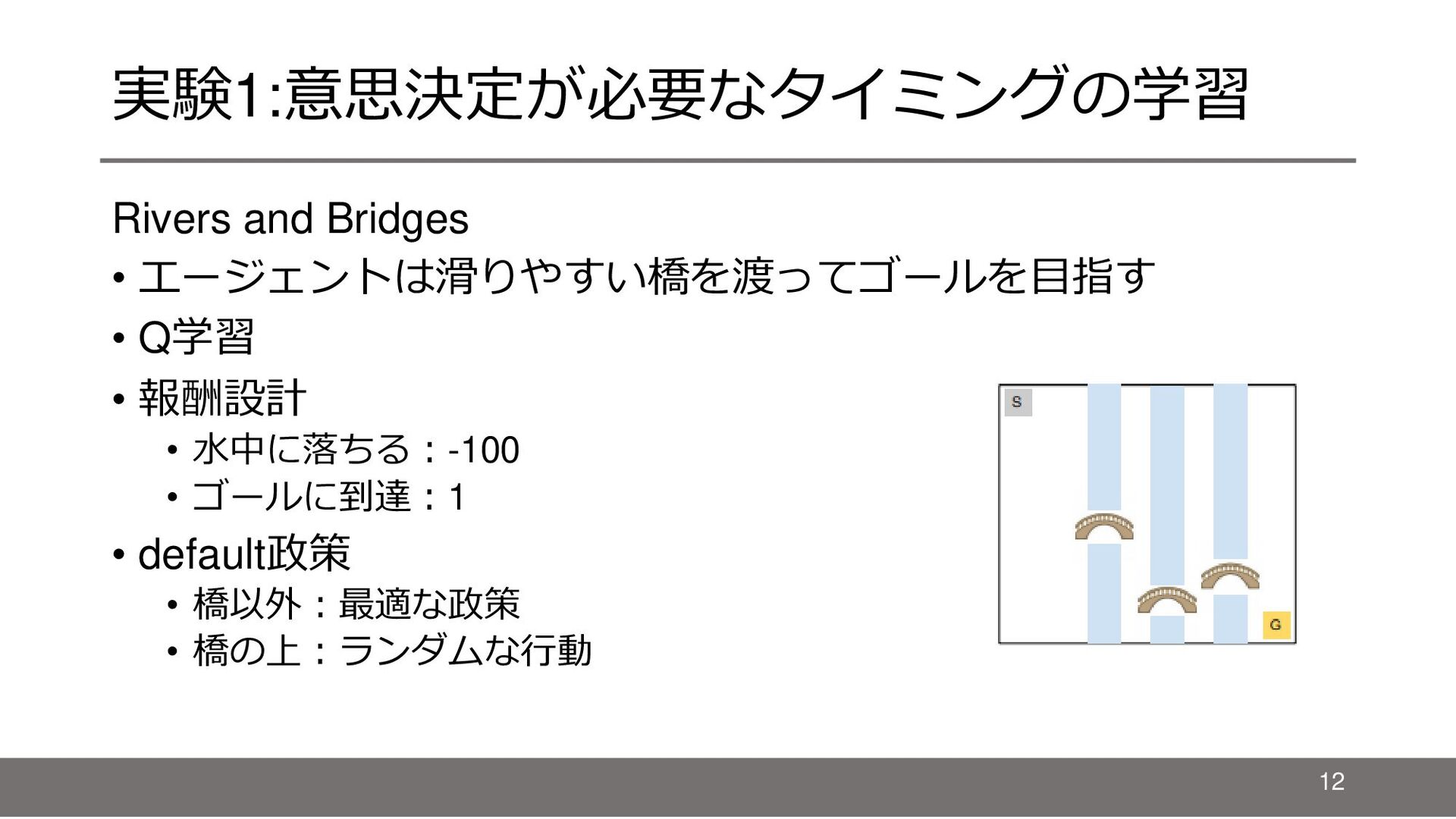{kind=link}
{kind=link}
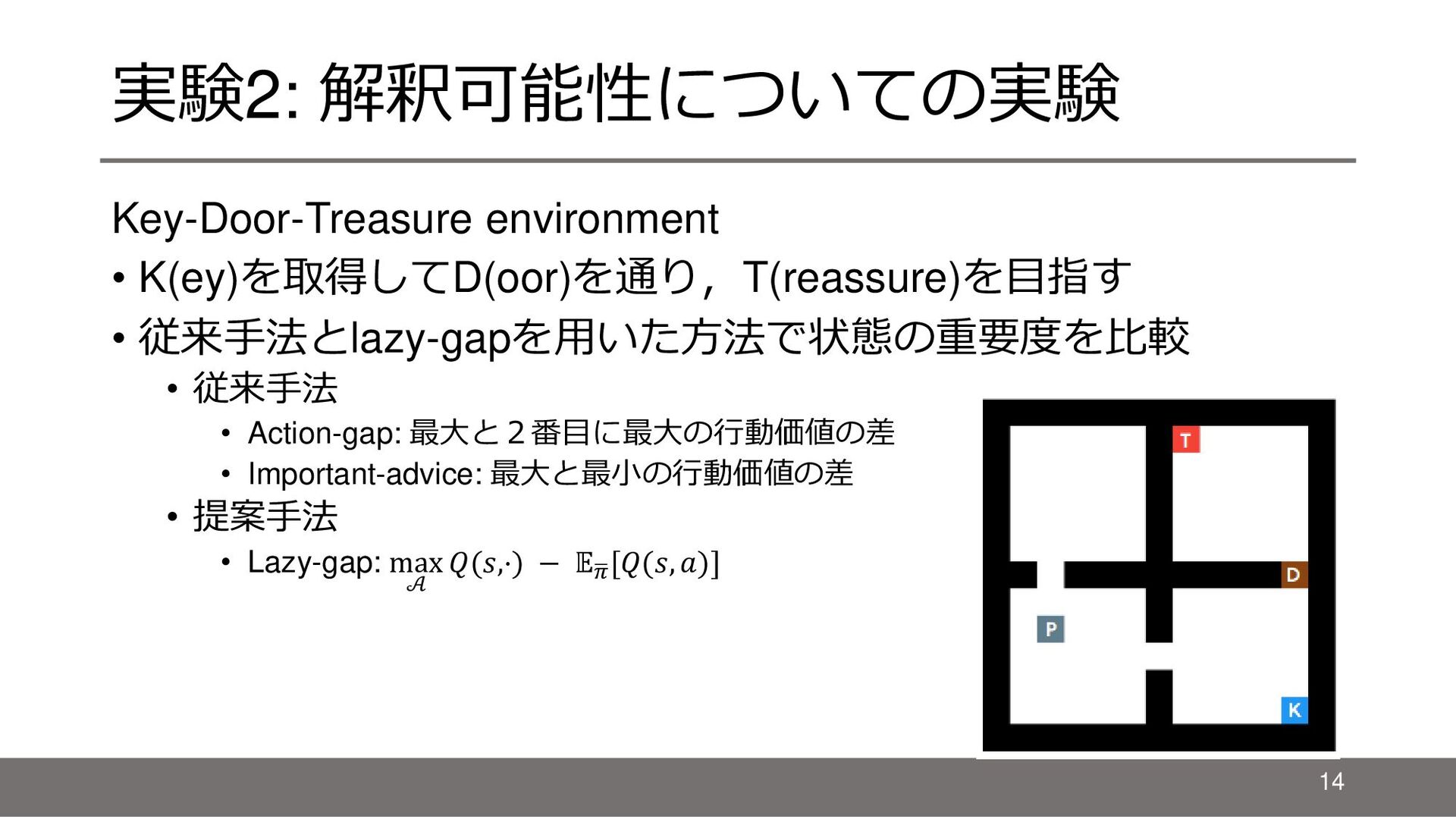{kind=link}
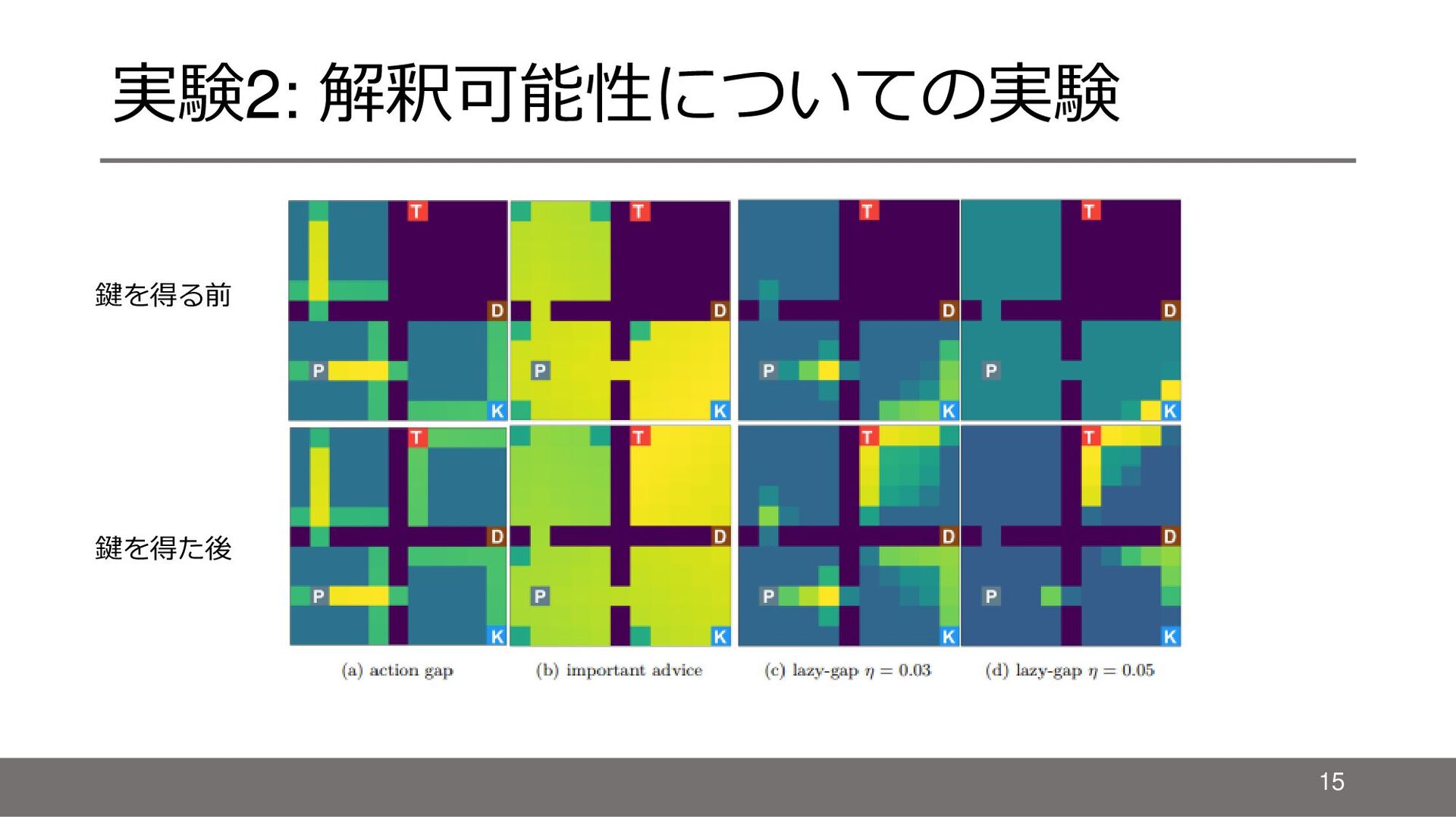{kind=link}
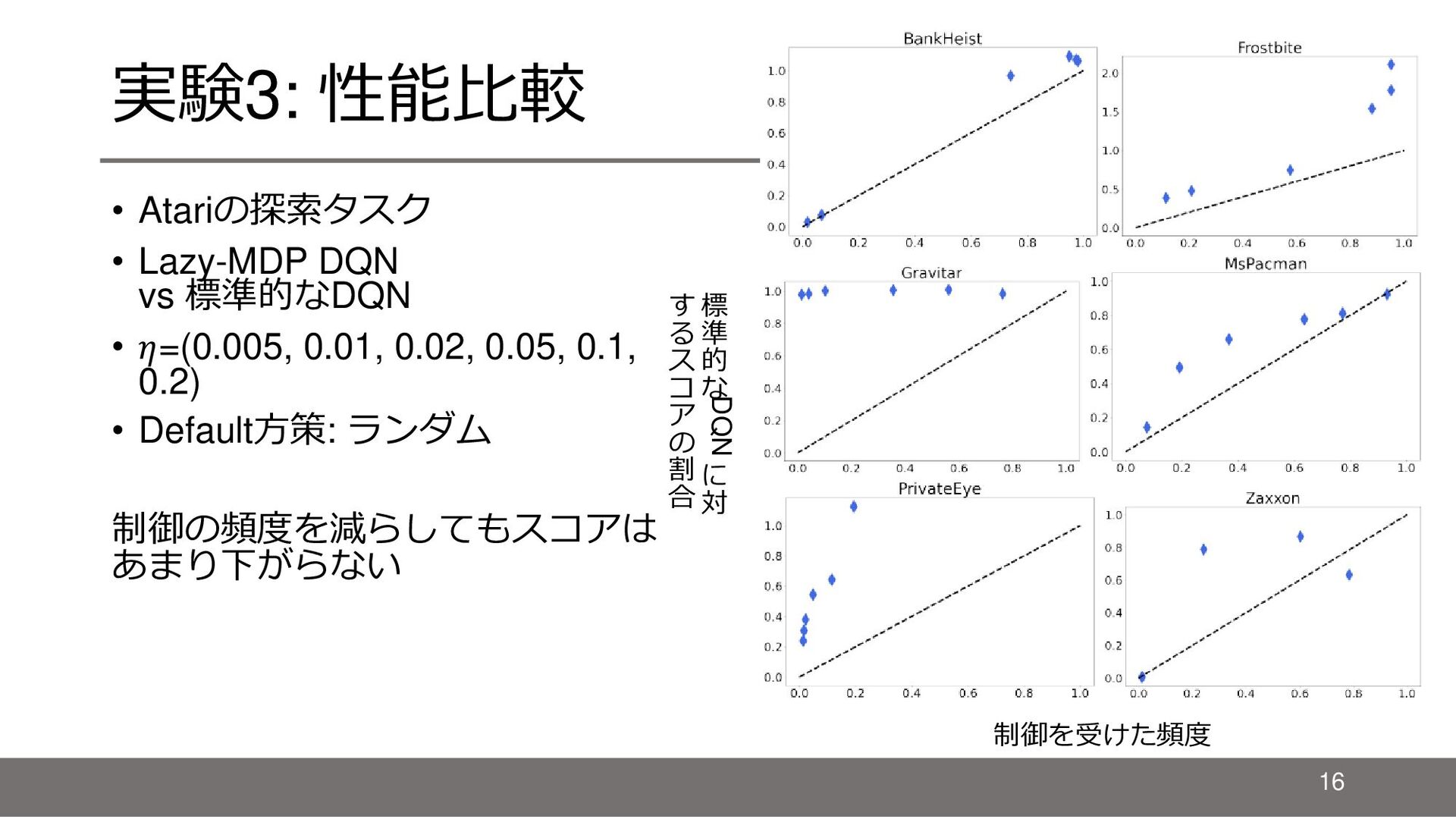{kind=link}
{kind=link}