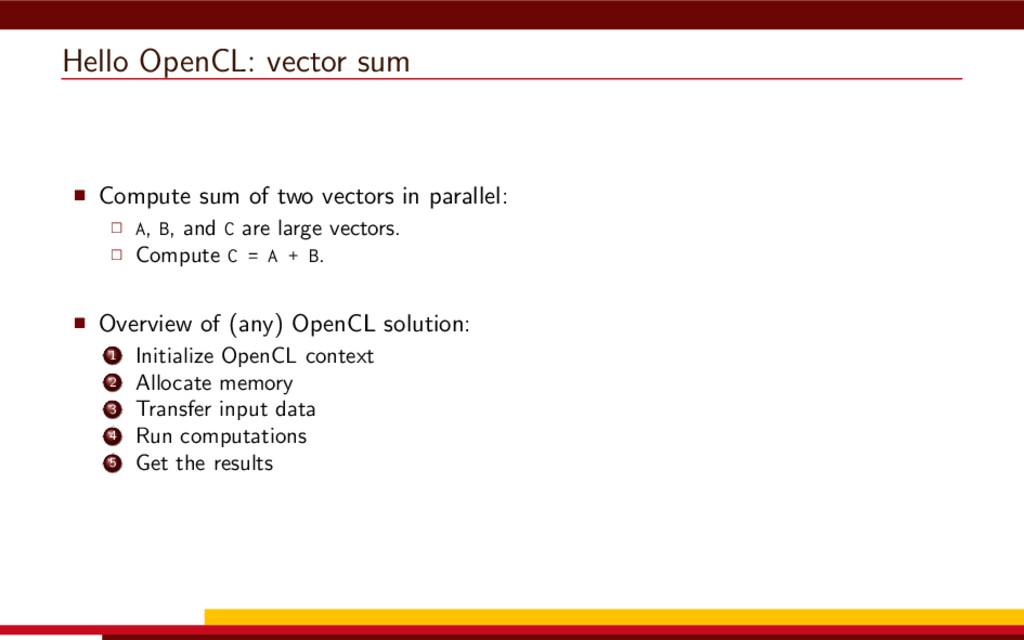
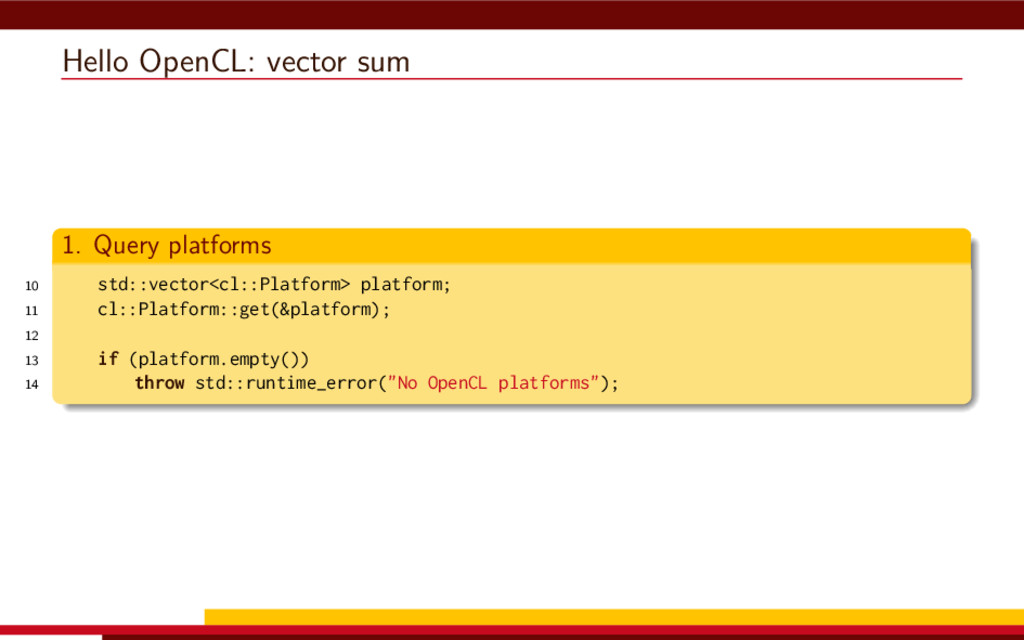
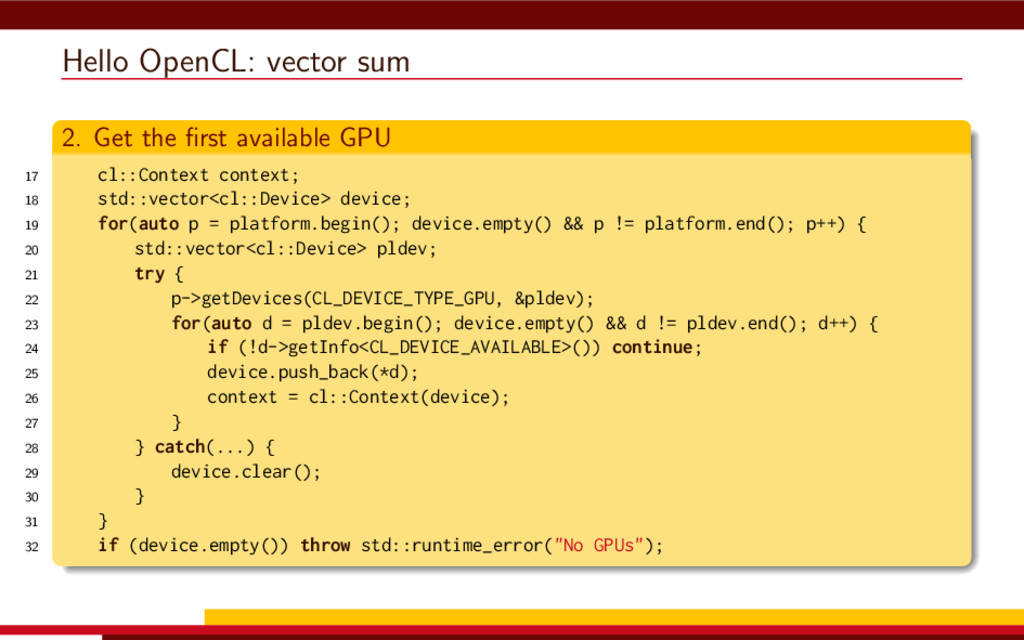
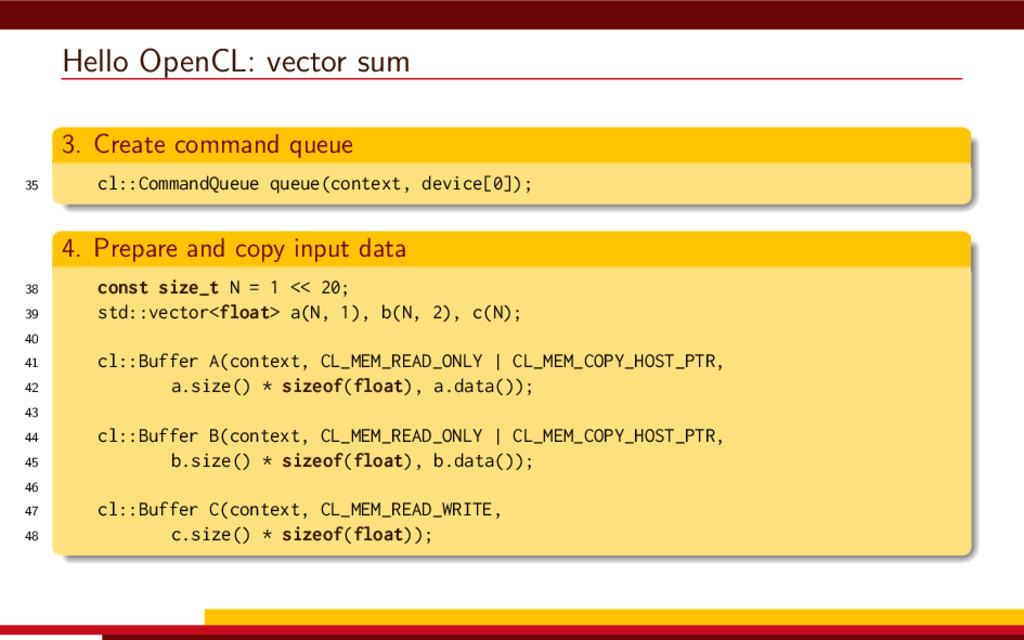
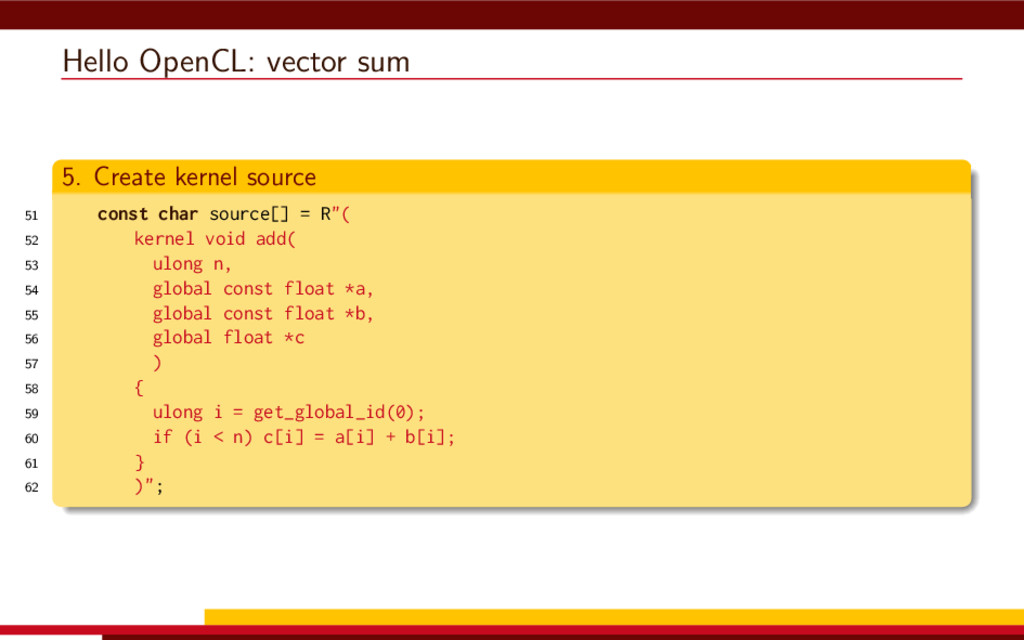
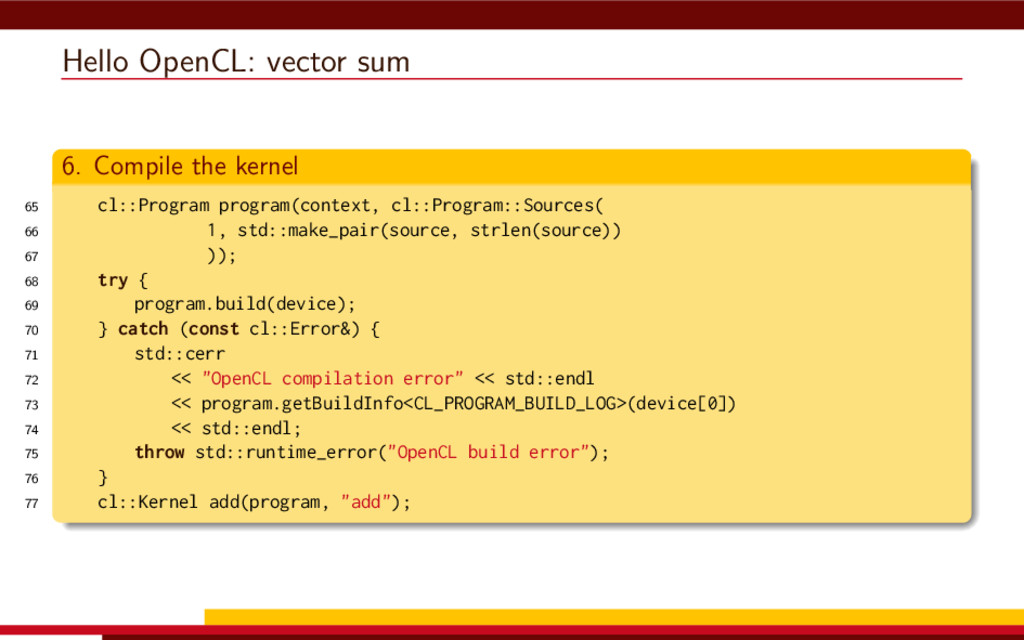
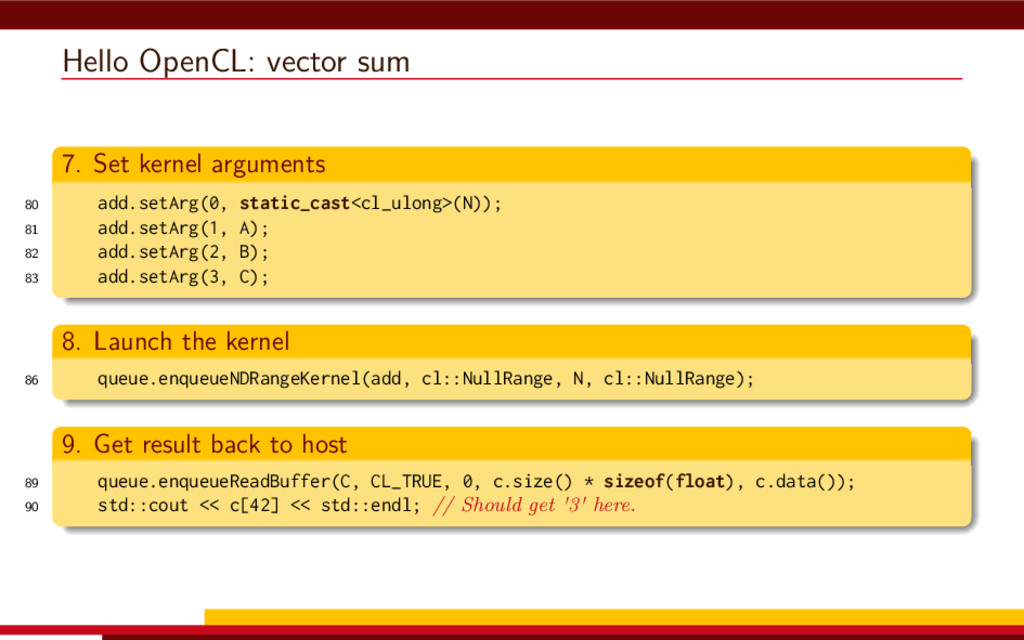
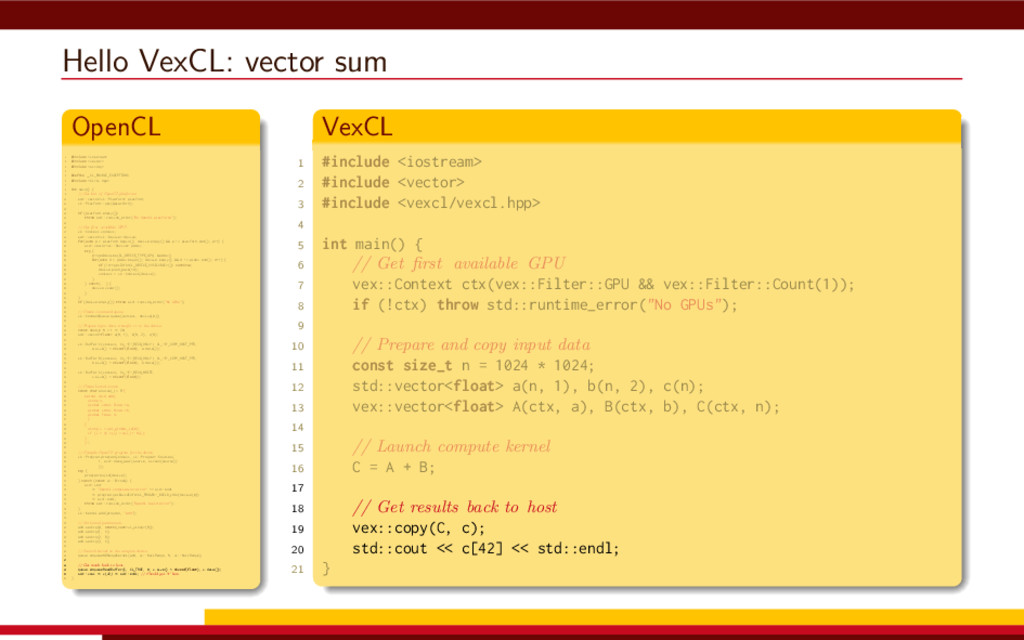
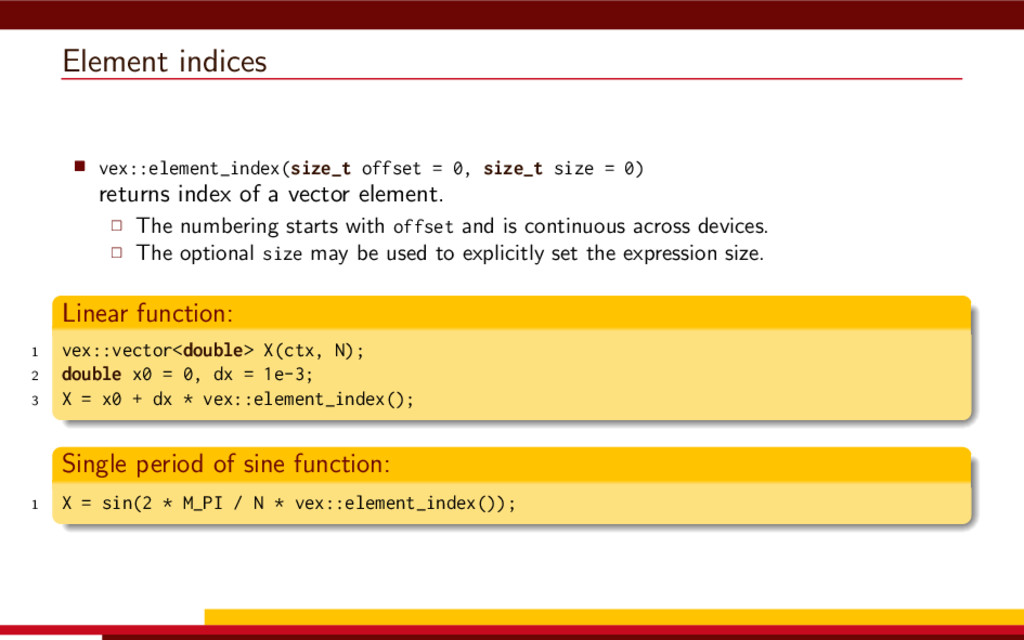
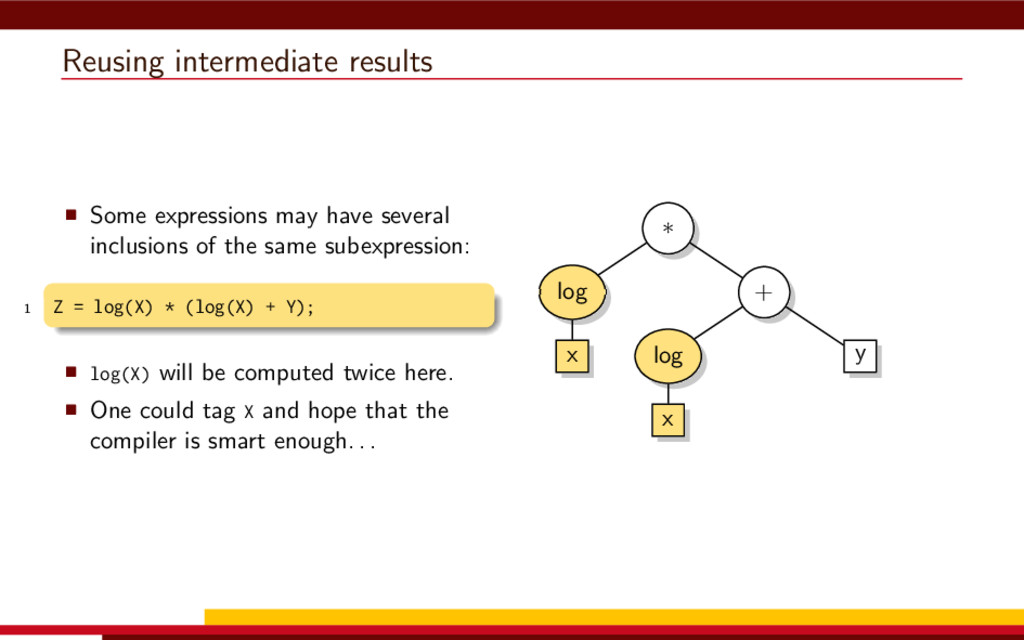
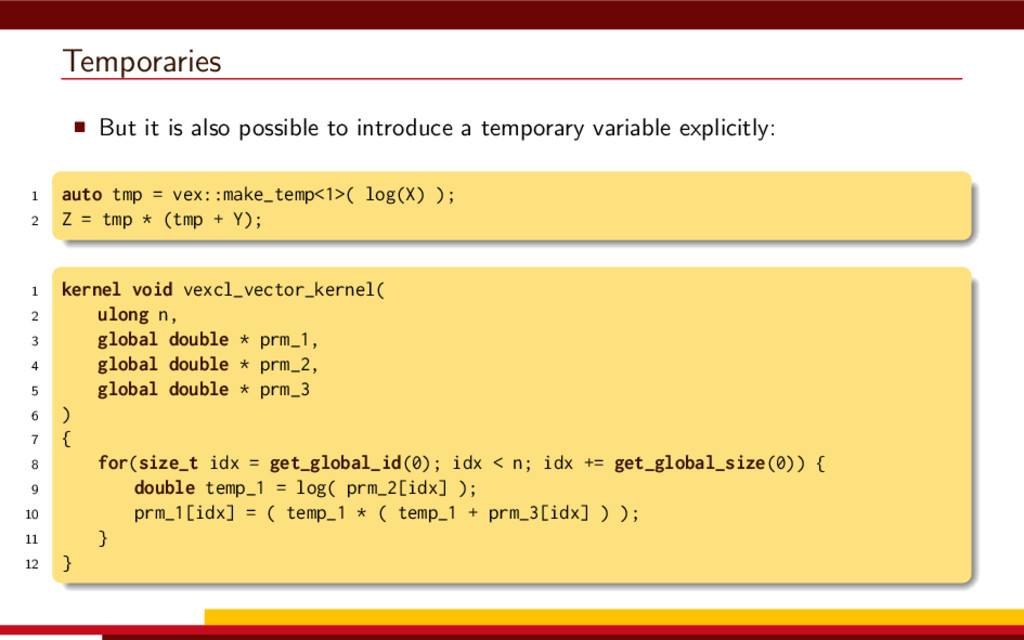
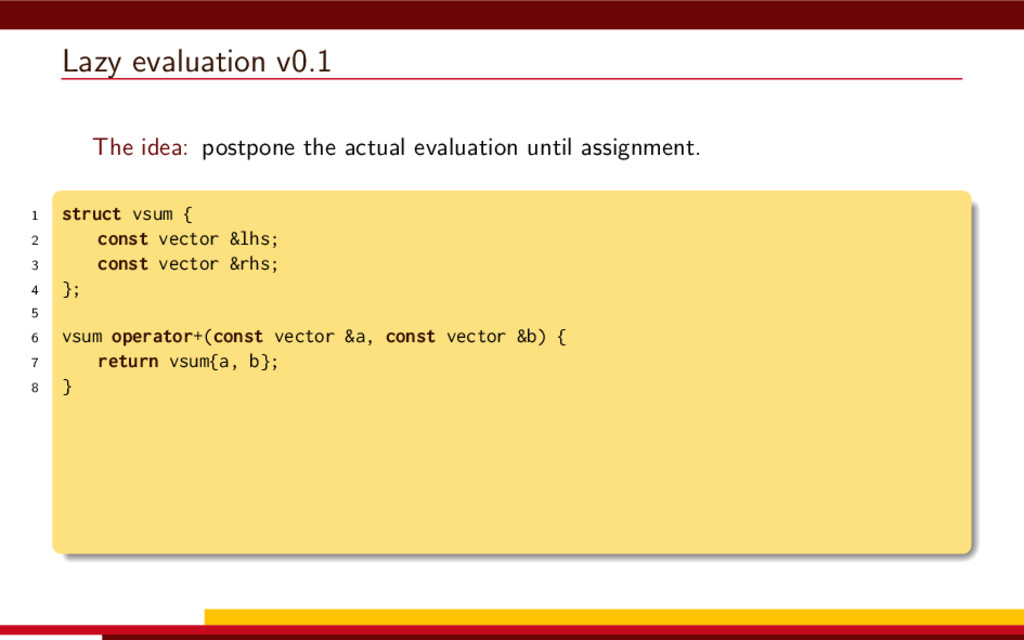
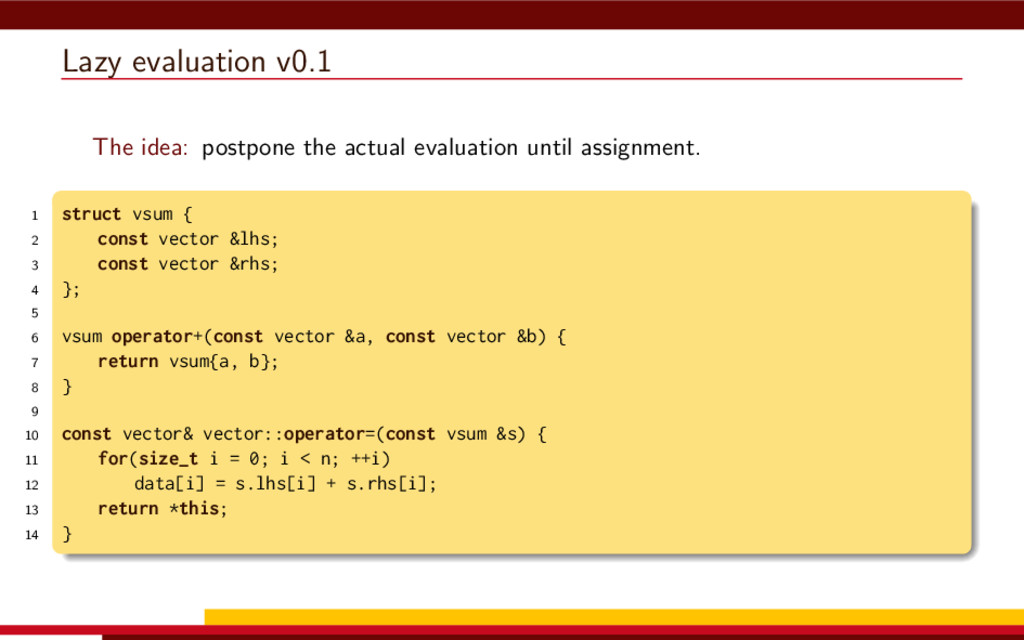
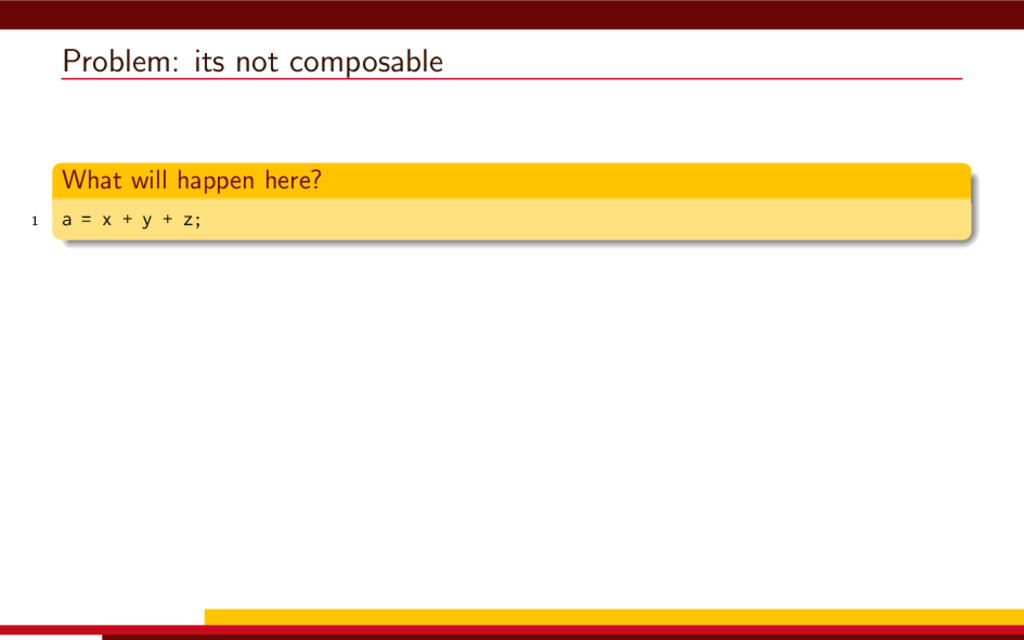
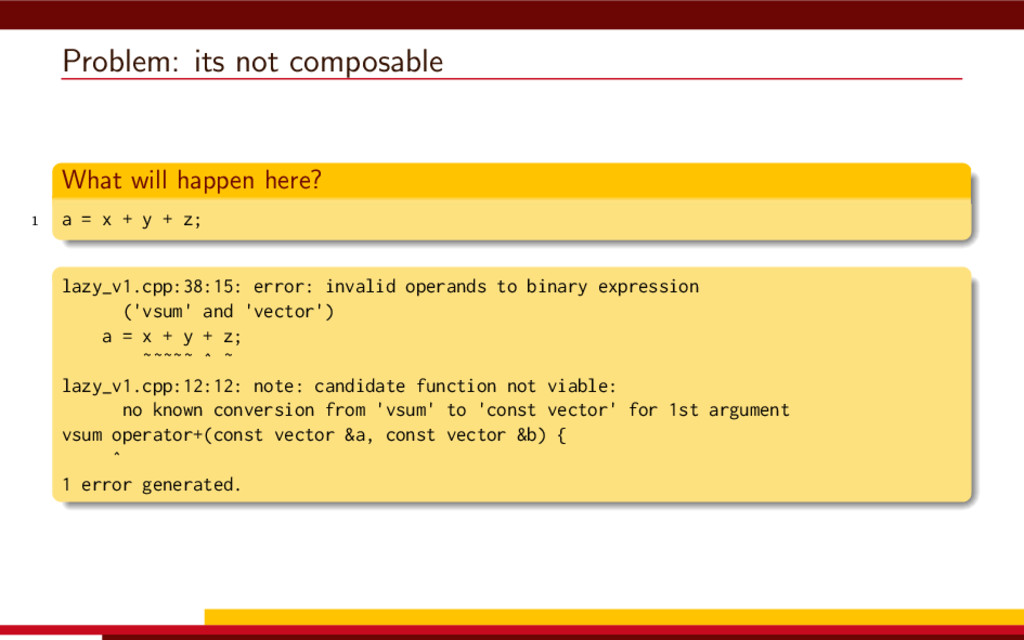
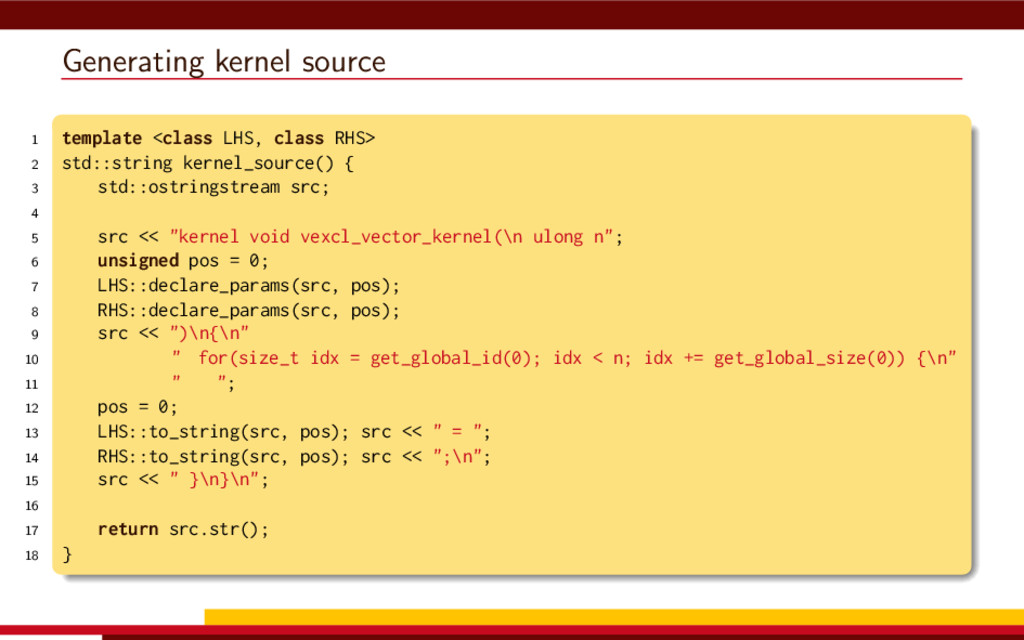
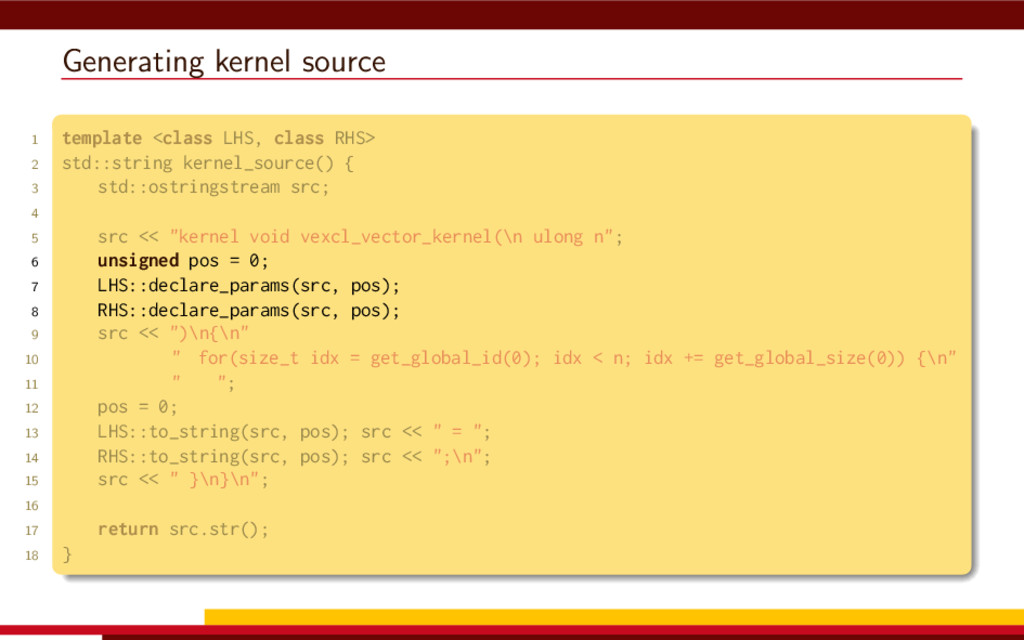
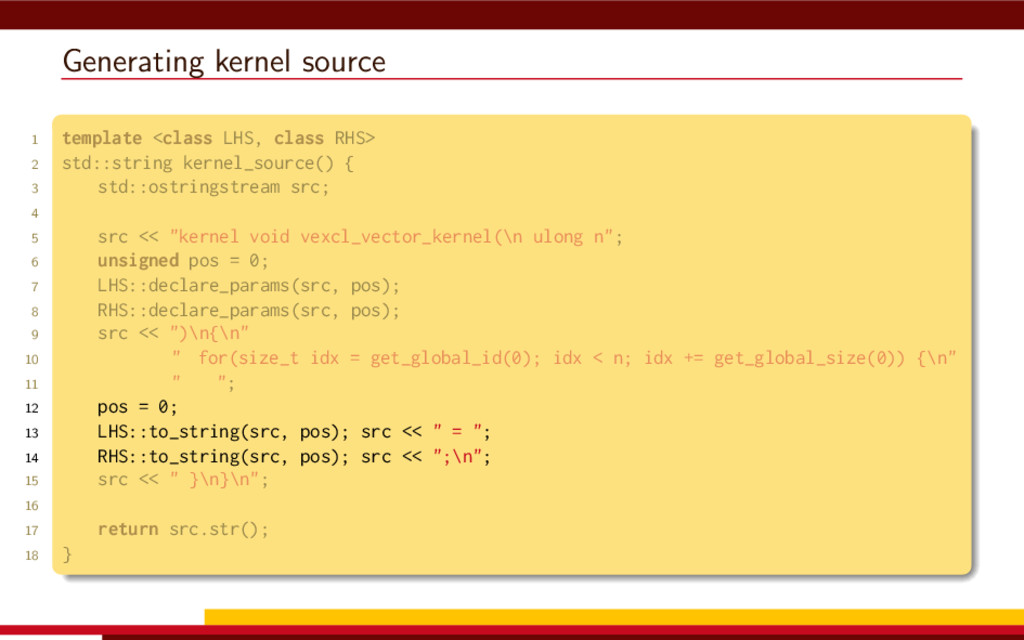
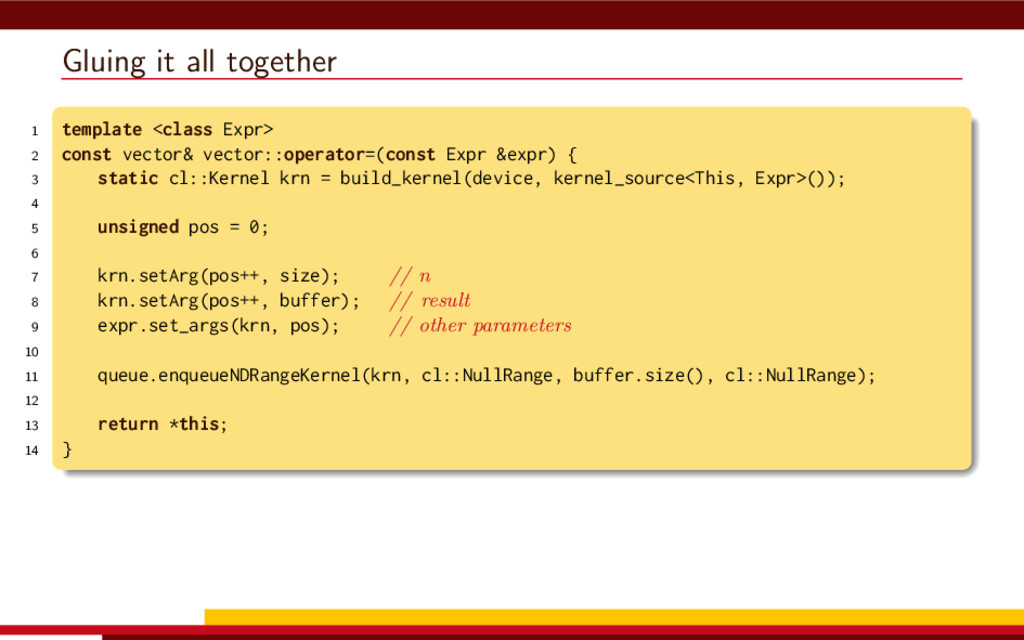
<vector> 3 #include <string> 4 5 #define __CL_ENABLE_EXCEPTIONS 6 #include <CL/cl.hpp> 7 8 int main() { 9 // Get list of OpenCL platforms. 10 std::vector<cl::Platform> platform; 11 cl::Platform::get(&platform); 12 13 if (platform.empty()) 14 throw std::runtime_error("No OpenCL platforms"); 15 16 // Get first available GPU. 17 cl::Context context; 18 std::vector<cl::Device> device; 19 for(auto p = platform.begin(); device.empty() && p != platform.end(); p++) { 20 std::vector<cl::Device> pldev; 21 try { 22 p->getDevices(CL_DEVICE_TYPE_GPU, &pldev); 23 for(auto d = pldev.begin(); device.empty() && d != pldev.end(); d++) { 24 if (!d->getInfo<CL_DEVICE_AVAILABLE>()) continue; 25 device.push_back(*d); 26 context = cl::Context(device); 27 } 28 } catch(...) { 29 device.clear(); 30 } 31 } 32 if (device.empty()) throw std::runtime_error("No GPUs"); 33 34 // Create command queue. 35 cl::CommandQueue queue(context, device[0]); 36 37 // Prepare input data, transfer it to the device. 38 const size_t N = 1 << 20; 39 std::vector<float> a(N, 1), b(N, 2), c(N); 40 41 cl::Buffer A(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, 42 a.size() * sizeof(float), a.data()); 43 44 cl::Buffer B(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, 45 b.size() * sizeof(float), b.data()); 46 47 cl::Buffer C(context, CL_MEM_READ_WRITE, 48 c.size() * sizeof(float)); 49 50 // Create kernel source 51 const char source[] = R"( 52 kernel void add( 53 ulong n, 54 global const float *a, 55 global const float *b, 56 global float *c 57 ) 58 { 59 ulong i = get_global_id(0); 60 if (i < n) c[i] = a[i] + b[i]; 61 } 62 )"; 63 64 // Compile OpenCL program for the device. 65 cl::Program program(context, cl::Program::Sources( 66 1, std::make_pair(source, strlen(source)) 67 )); 68 try { 69 program.build(device); 70 } catch (const cl::Error&) { 71 std::cerr 72 << "OpenCL compilation error" << std::endl 73 << program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(device[0]) 74 << std::endl; 75 throw std::runtime_error("OpenCL build error"); 76 } 77 cl::Kernel add(program, "add"); 78 79 // Set kernel parameters. 80 add.setArg(0, static_cast<cl_ulong>(N)); 81 add.setArg(1, A); 82 add.setArg(2, B); 83 add.setArg(3, C); 84 85 // Launch kernel on the compute device. 86 queue.enqueueNDRangeKernel(add, cl::NullRange, N, cl::NullRange); 87 88 // Get result back to host. 89 queue.enqueueReadBuffer(C, CL_TRUE, 0, c.size() * sizeof(float), c.data()); 90 std::cout << c[42] << std::endl; // Should get '3' here. 91 } VexCL 1 #include <iostream> 2 #include <vector> 3 #include <vexcl/vexcl.hpp> 4 5 int main() { 6 // Get first available GPU 7 vex::Context ctx(vex::Filter::GPU && vex::Filter::Count(1)); 8 if (!ctx) throw std::runtime_error("No GPUs"); 9 10 // Prepare and copy input data 11 const size_t n = 1024 * 1024; 12 std::vector<float> a(n, 1), b(n, 2), c(n); 13 vex::vector<float> A(ctx, a), B(ctx, b), C(ctx, n); 14 15 // Launch compute kernel 16 C = A + B; 17 18 // Get results back to host 19 vex::copy(C, c); 20 std::cout << c[42] << std::endl; 21 }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
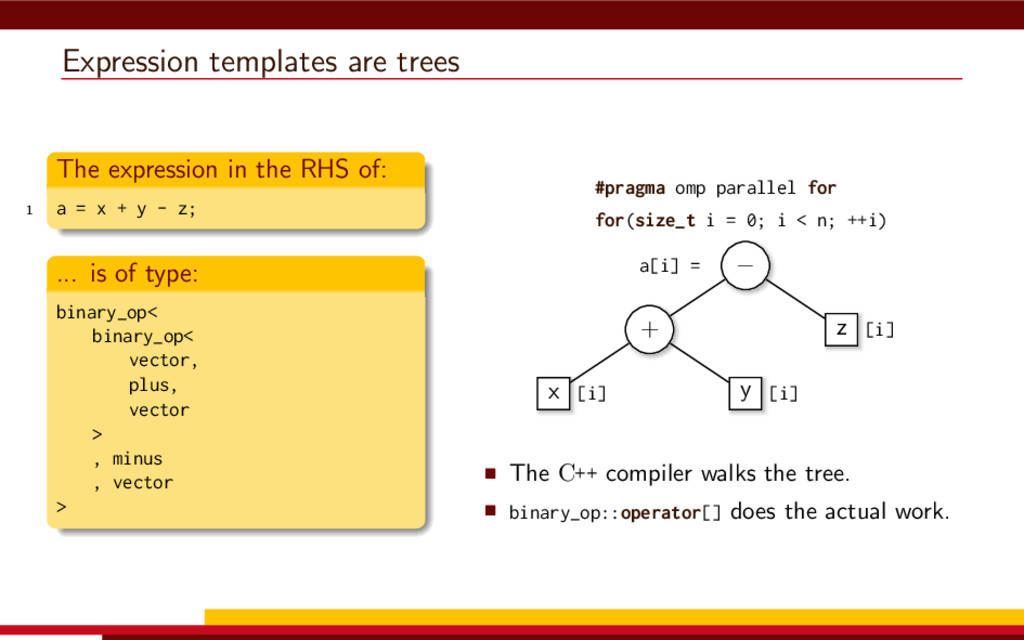{kind=link}
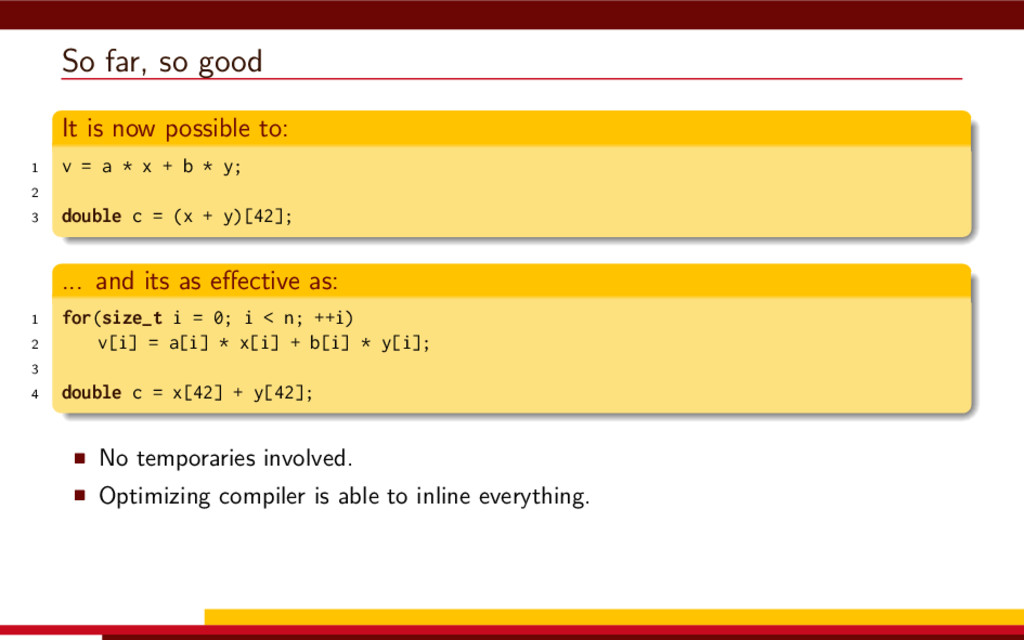{kind=link}
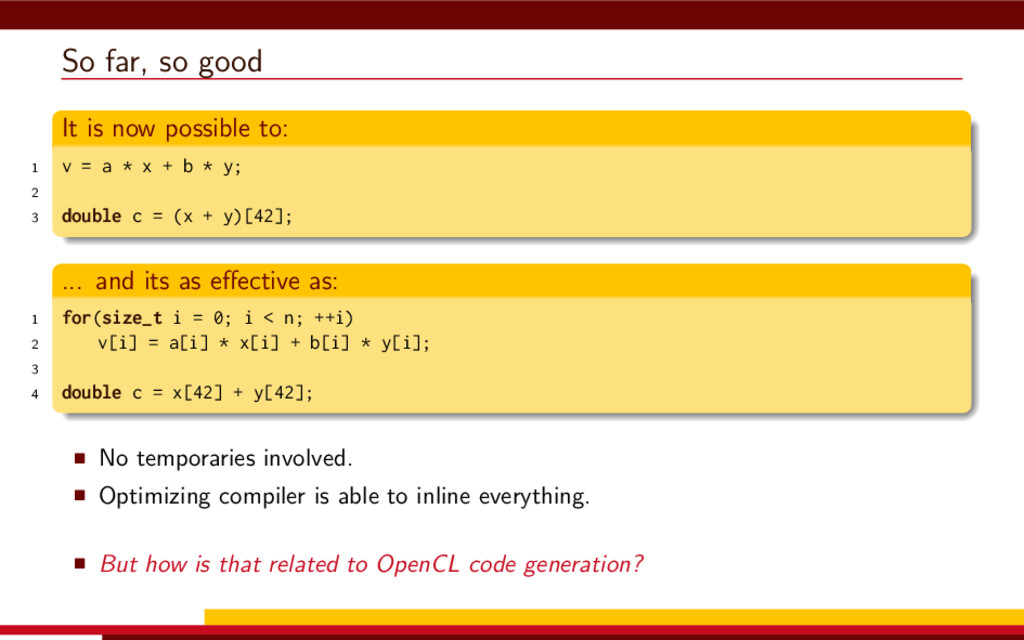{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}