VexCL - a Vector Expression Template Library for OpenCL
VexCL (https://github.com/ddemidov/vexcl) is a modern C++ library created for ease of OpenCL development with C++. VexCL strives to reduce the amount of boilerplate code needed to develop OpenCL applications. The library provides a convenient and intuitive notation for vector arithmetic, reduction, sparse matrix-vector multiplication, etc. Multidevice and multiplatform computations are supported.
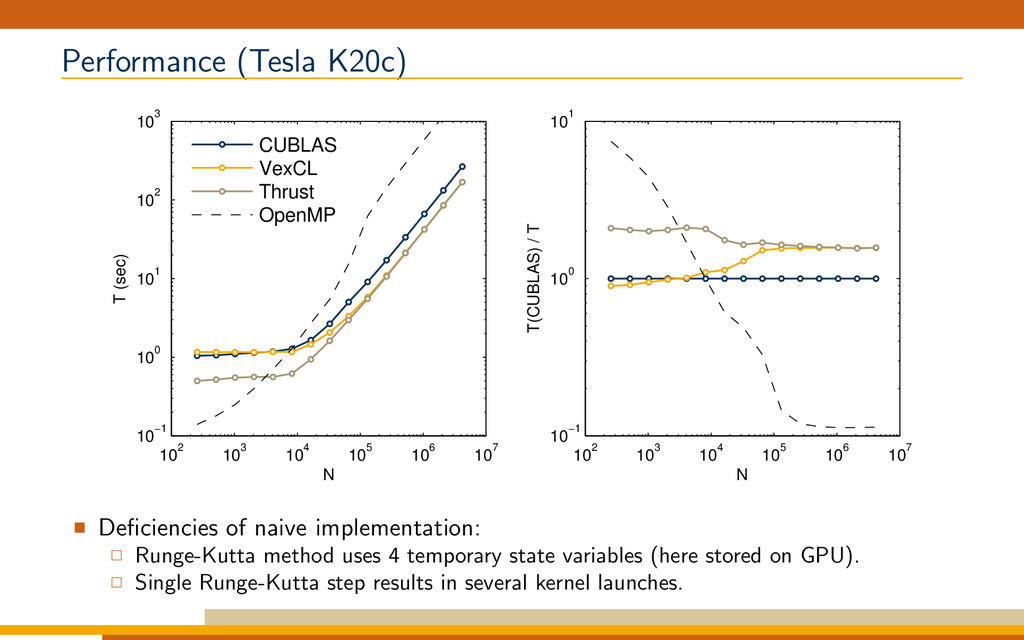
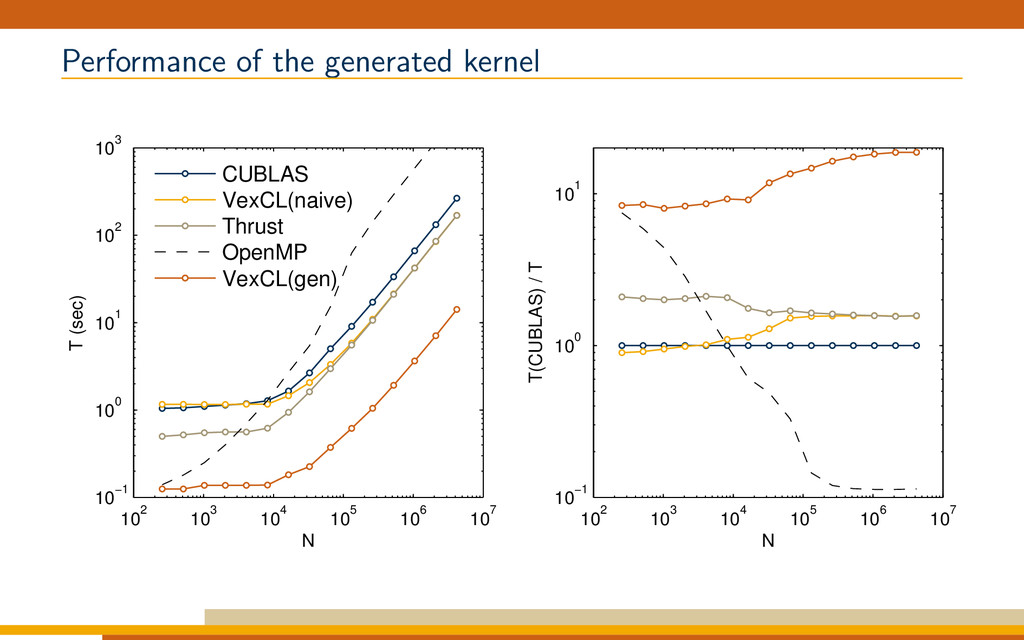
One of the major differences between NVIDIA's CUDA and OpenCL lies in their handling of compute kernels compilation. In NVIDIA’s framework the compute kernels are compiled to PTX code together with the host program. PTX is a pseudo-assembler language which is compiled at runtime for the specific NVIDIA device the kernel is launched on. Since PTX is already very low-level, this just-in-time kernel compilation has low overhead. In OpenCL the compute kernels are compiled at runtime from higher-level C-like sources, adding an overhead which is particularly noticeable for smaller sized problems. At the same time this allows to generate better optimized OpenCL kernels for the problem at hand. The VexCL library exploits this possibility through its JIT code generation facility. It is able to convert generic C++ code to OpenCL at runtime, thus reducing global memory usage and bandwidth. This talk is an introduction to the VexCL interface.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
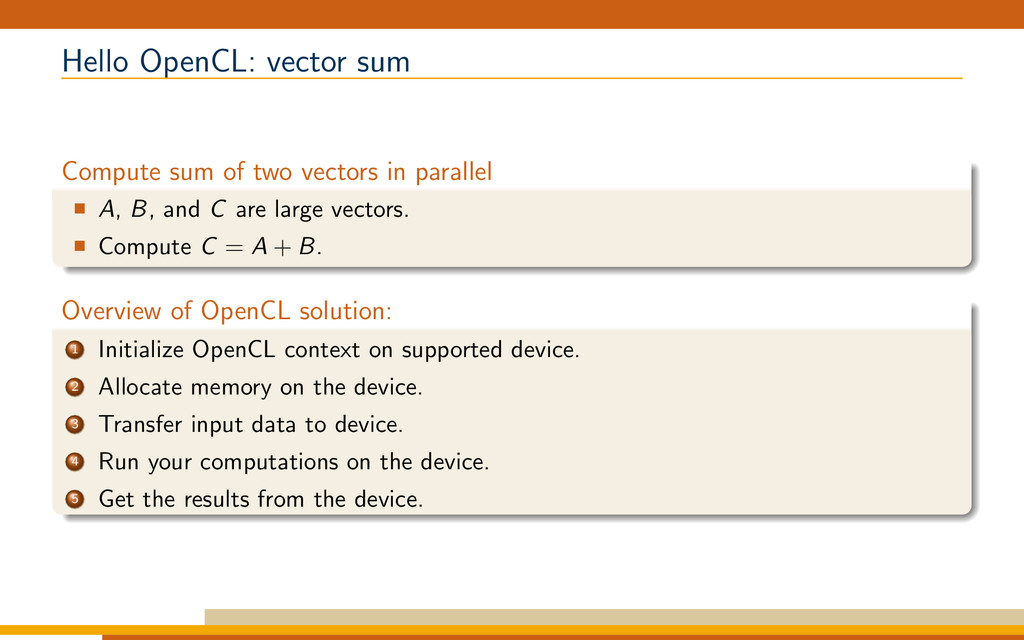{kind=link}
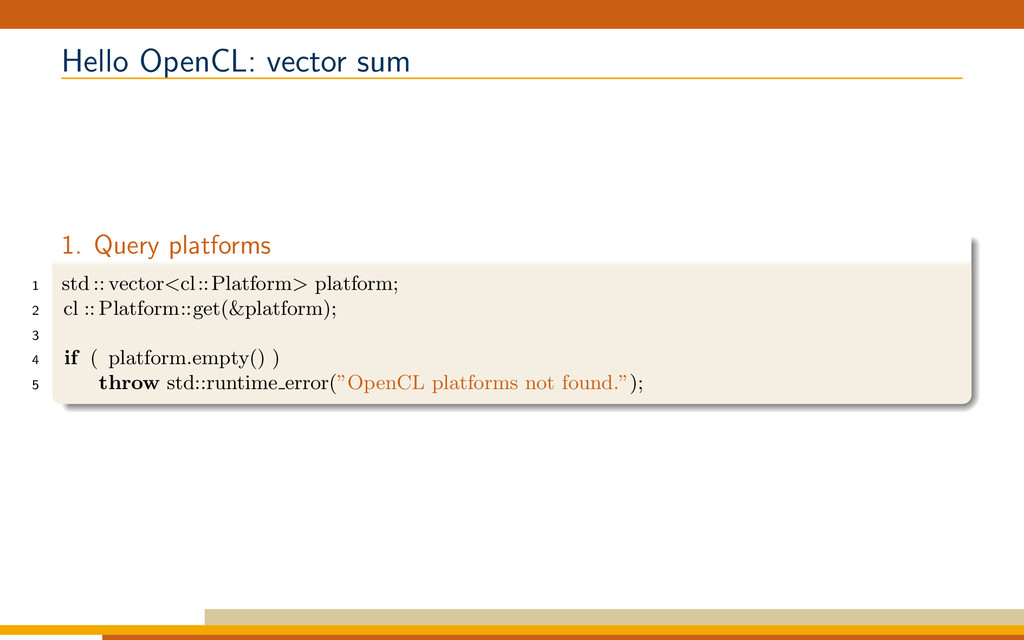{kind=link}
{kind=link}
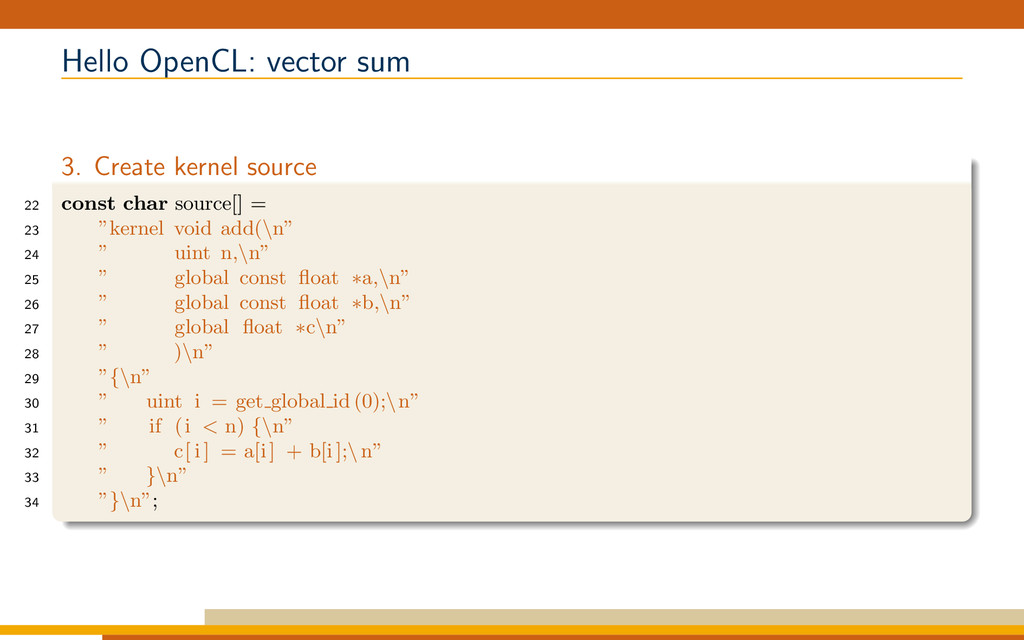{kind=link}
{kind=link}
{kind=link}
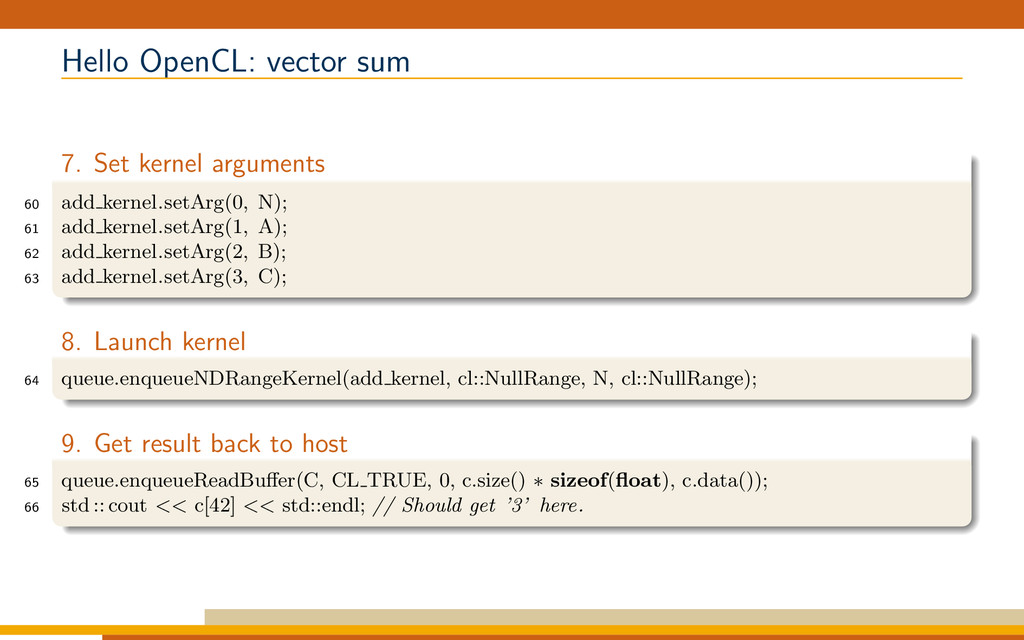{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}