m e on G itH ub Created for ease of C++ based GPGPU development: Convenient notation for vector expressions OpenCL/CUDA JIT code generation Easily combined with existing libraries/code Header-only Supported backends: OpenCL (Khronos C++ bindings, Boost.Compute) NVIDIA CUDA OpenMP Maxeler FPGAs (in progress) The source code is available under the MIT license: https://github.com/ddemidov/vexcl
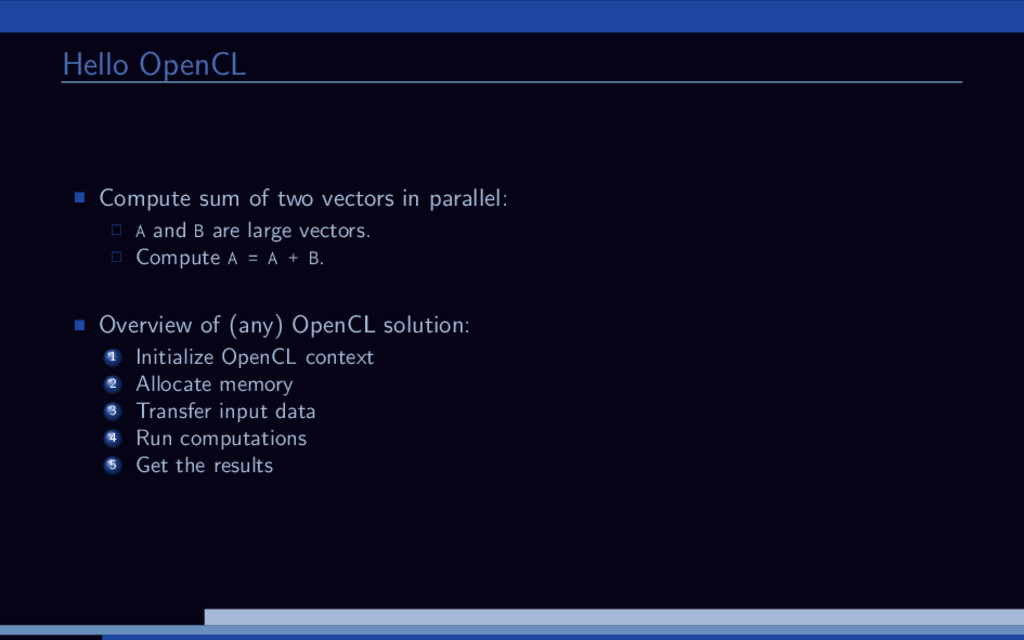
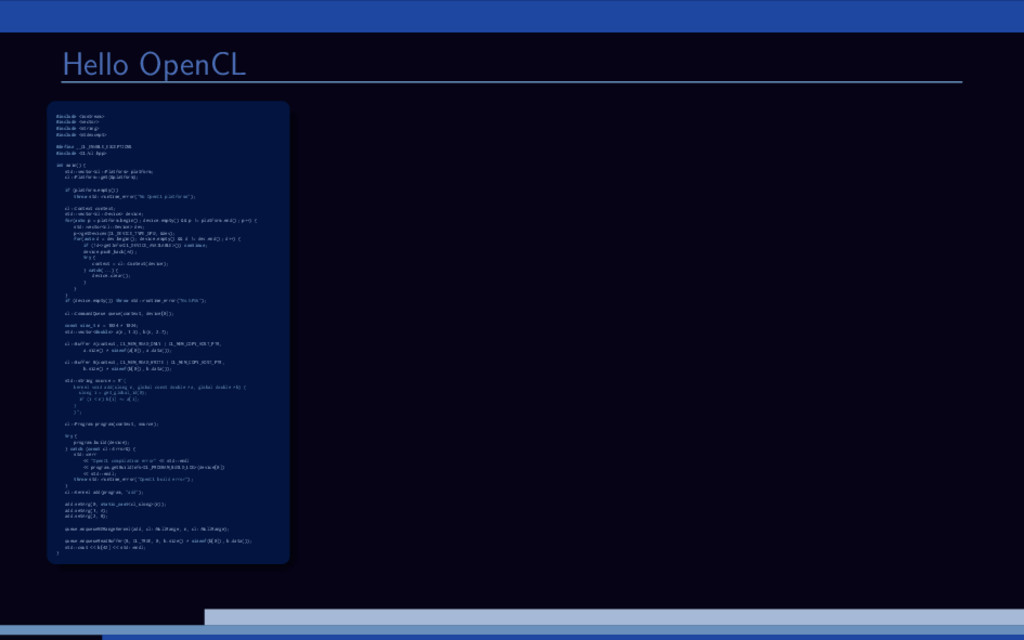
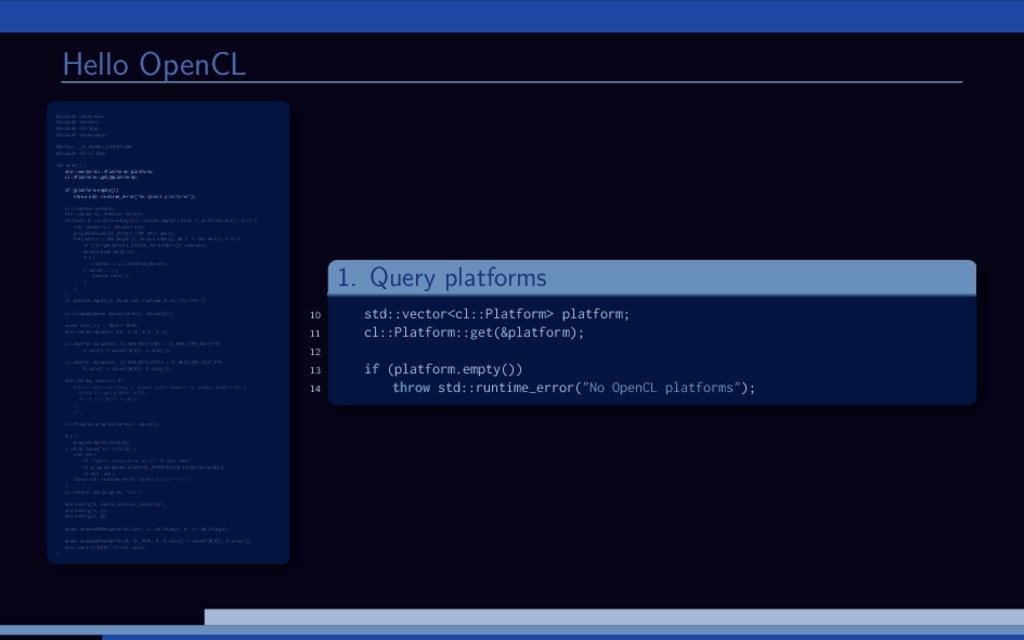
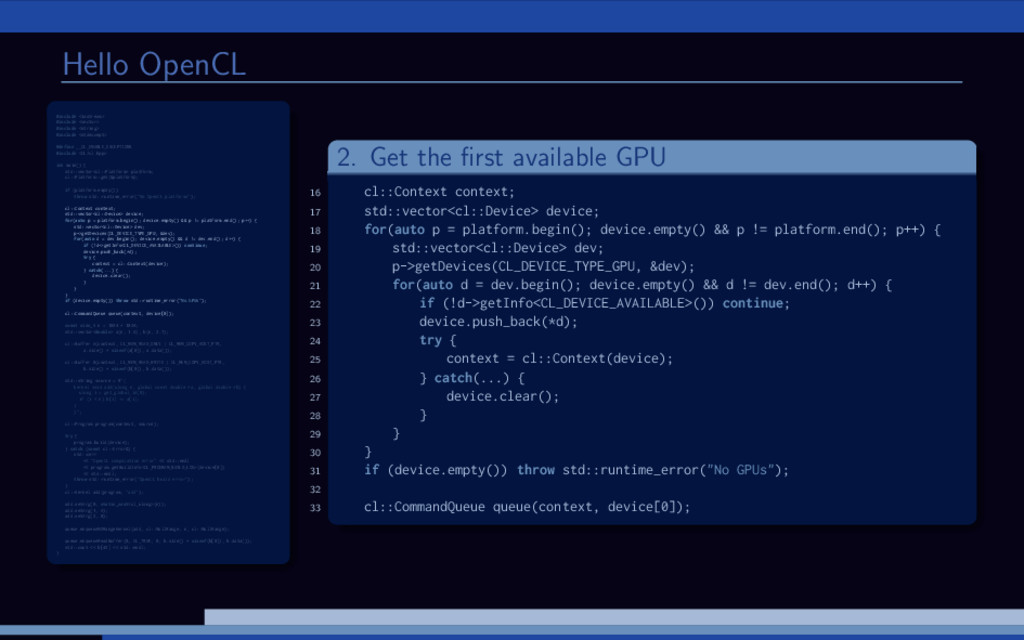
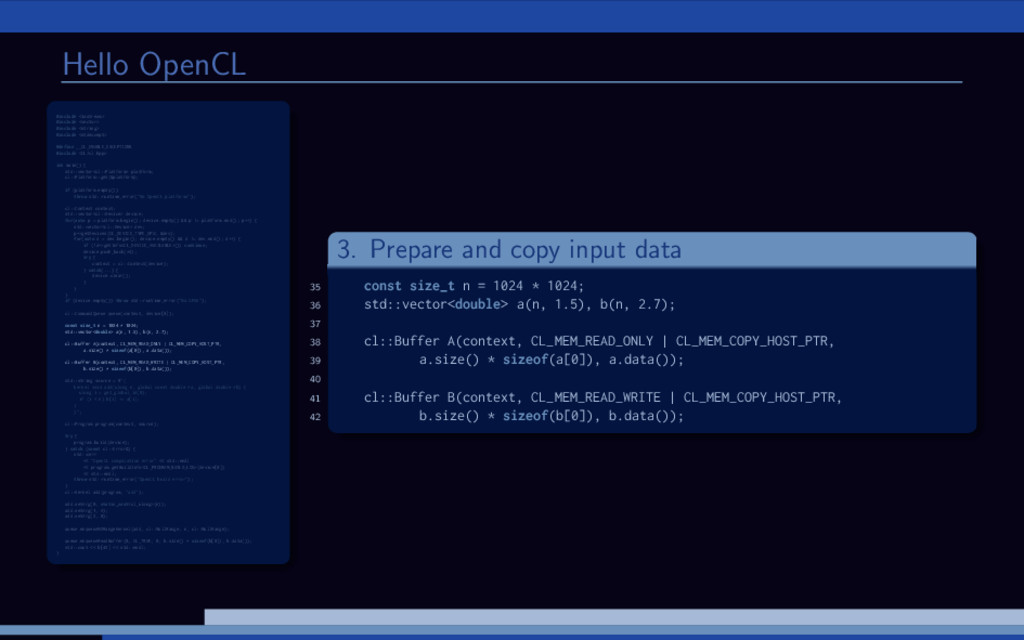
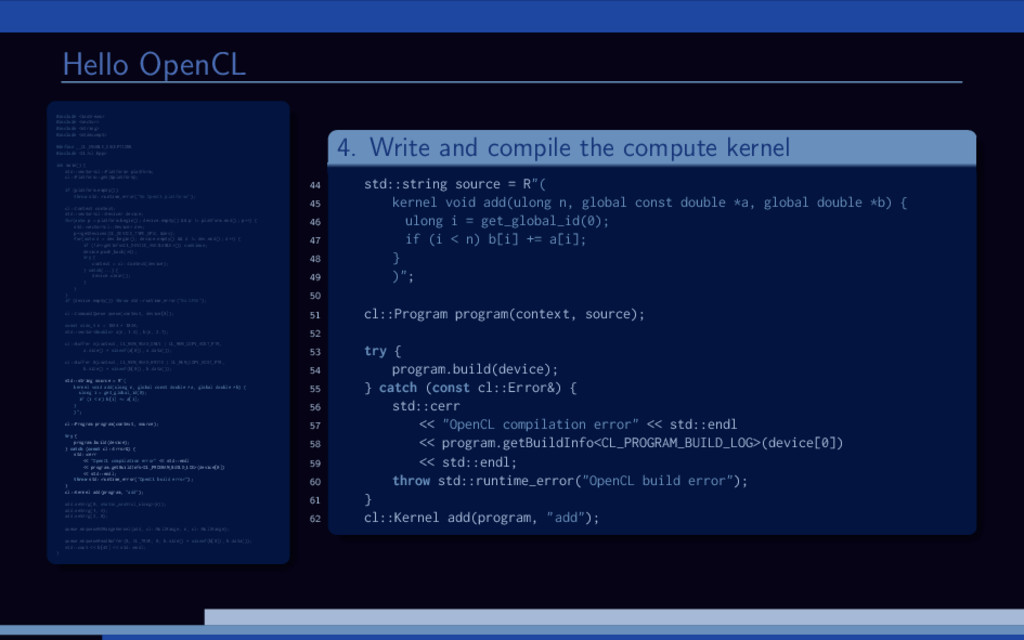
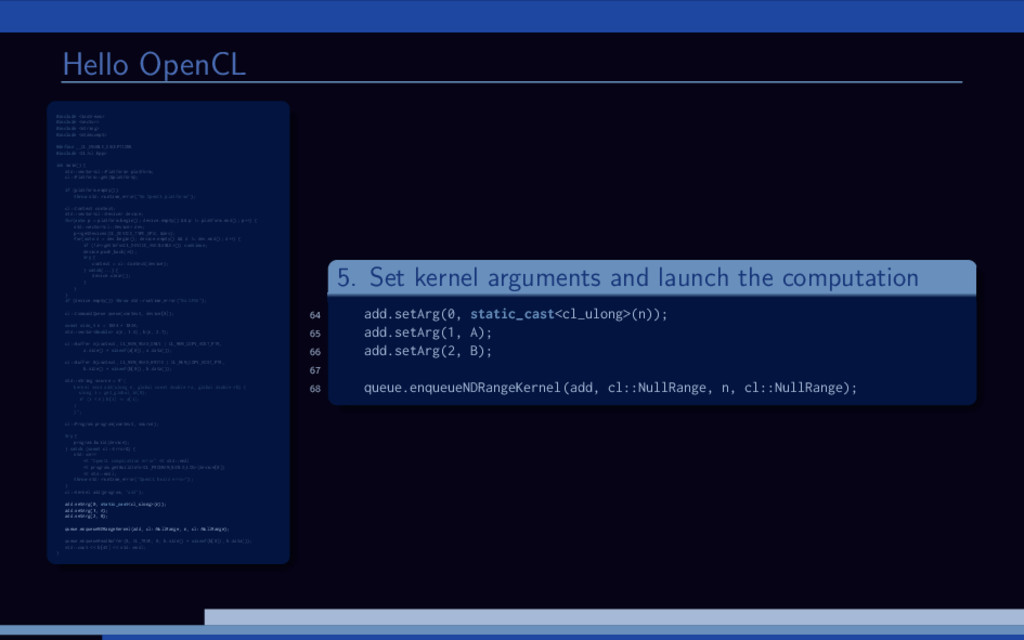
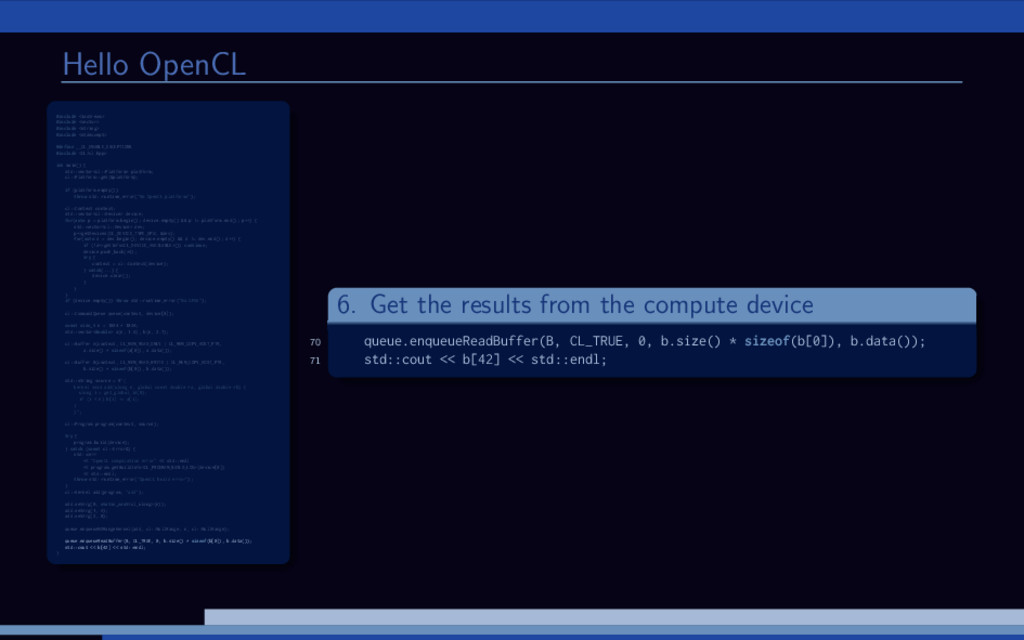
and B are large vectors. Compute A = A + B. Overview of (any) OpenCL solution: 1 Initialize OpenCL context 2 Allocate memory 3 Transfer input data 4 Run computations 5 Get the results
have to be compatible: Have same size Located on same devices What may be used: Vectors, scalars, constants Arithmetic, logical operators Built-in functions User-defined functions Random number generators Slicing and permutations Reduce to a scalar (sum, min, max) Reduce across chosen dimensions Stencil operations Sparse matrix – vector products Fast Fourier Transform Sort, scan, reduce by key
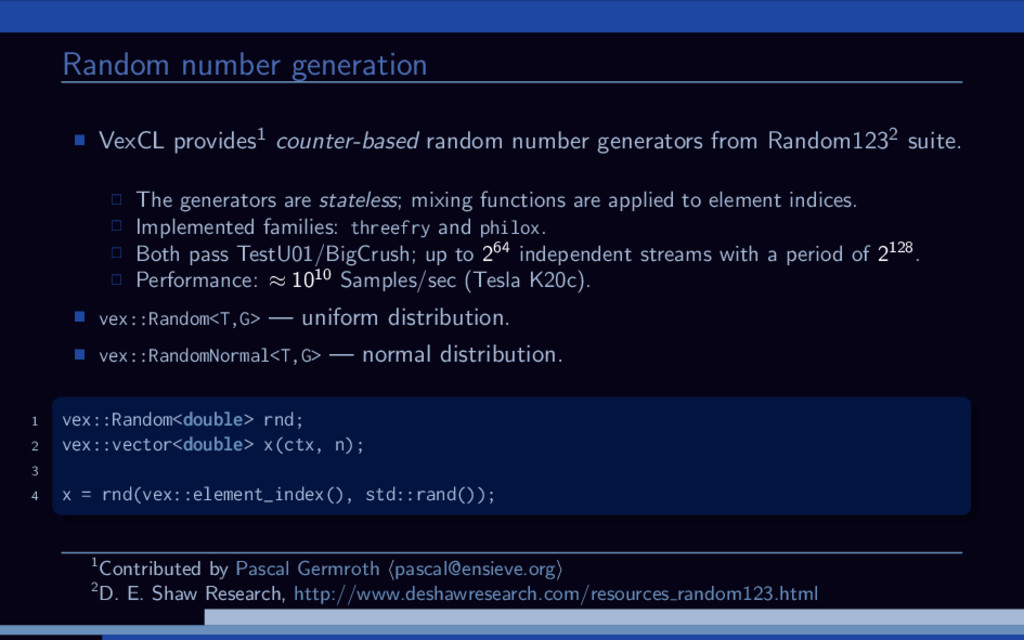
Random1232 suite. The generators are stateless; mixing functions are applied to element indices. Implemented families: threefry and philox. Both pass TestU01/BigCrush; up to 264 independent streams with a period of 2128. Performance: ≈ 1010 Samples/sec (Tesla K20c). vex::Random<T,G> — uniform distribution. vex::RandomNormal<T,G> — normal distribution. 1 vex::Random<double> rnd; 2 vex::vector<double> x(ctx, n); 3 4 x = rnd(vex::element_index(), std::rand()); 1Contributed by Pascal Germroth [email protected] 2D. E. Shaw Research, http://www.deshawresearch.com/resources random123.html
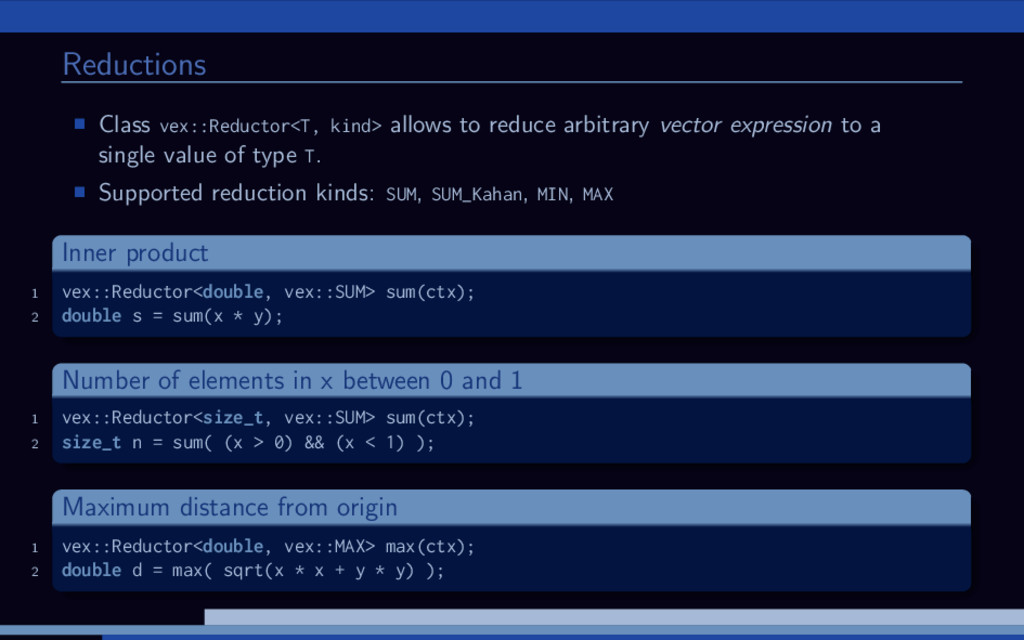
to a single value of type T. Supported reduction kinds: SUM, SUM_Kahan, MIN, MAX Inner product 1 vex::Reductor<double, vex::SUM> sum(ctx); 2 double s = sum(x * y); Number of elements in x between 0 and 1 1 vex::Reductor<size_t, vex::SUM> sum(ctx); 2 size_t n = sum( (x > 0) && (x < 1) ); Maximum distance from origin 1 vex::Reductor<double, vex::MAX> max(ctx); 2 double d = max( sqrt(x * x + y * y) );
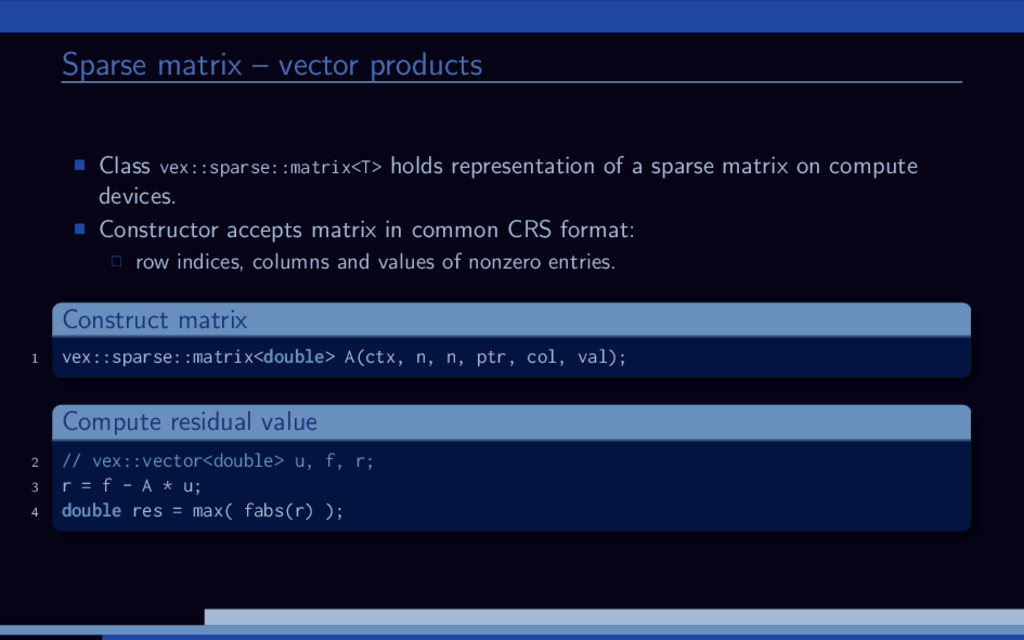
a sparse matrix on compute devices. Constructor accepts matrix in common CRS format: row indices, columns and values of nonzero entries. Construct matrix 1 vex::sparse::matrix<double> A(ctx, n, n, ptr, col, val); Compute residual value 2 // vex::vector<double> u, f, r; 3 r = f - A * u; 4 double res = max( fabs(r) );
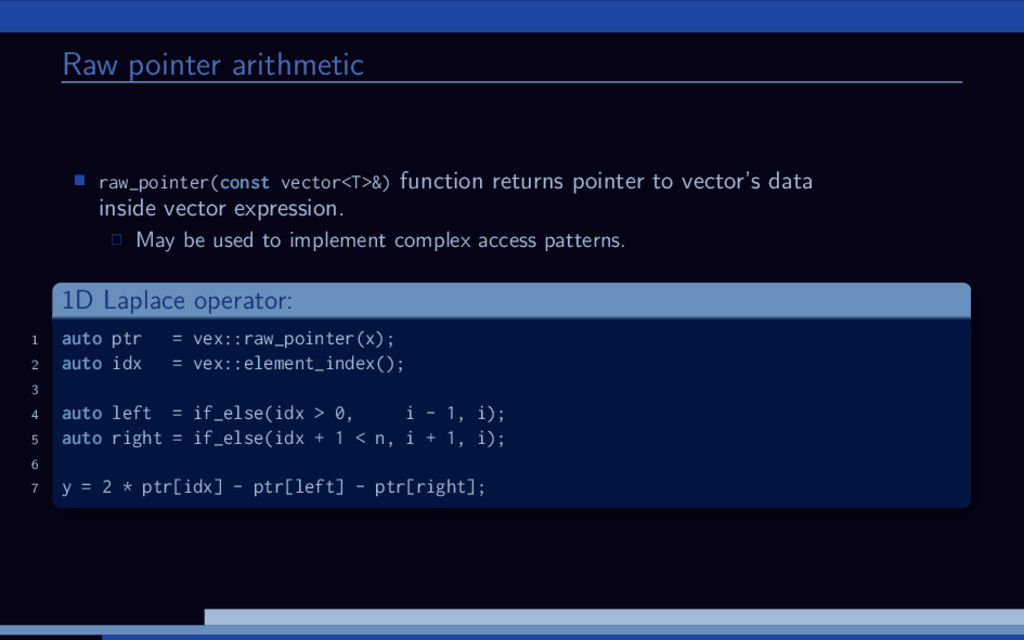
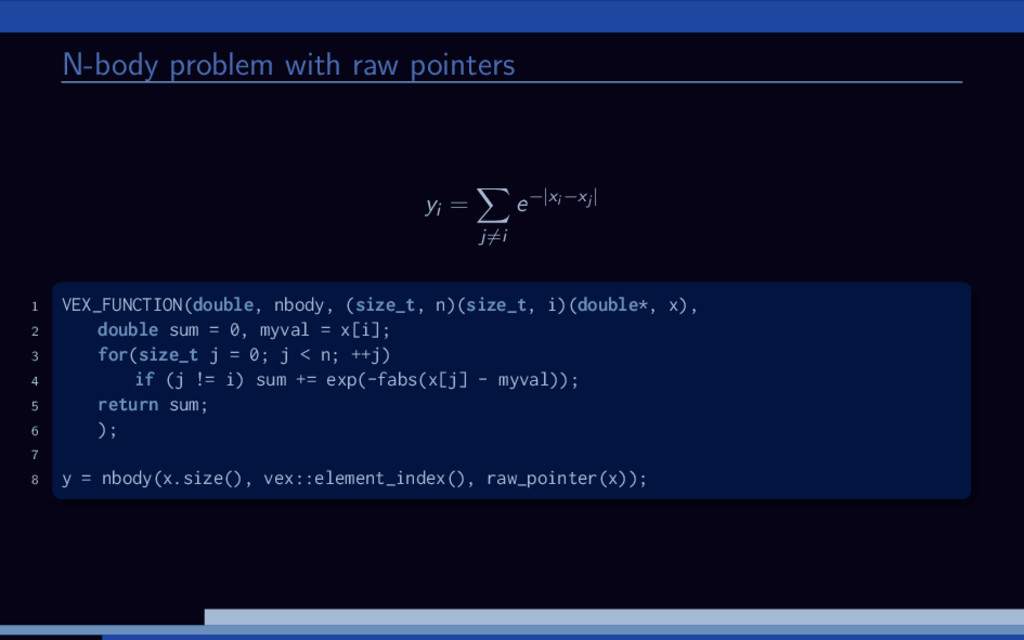
data inside vector expression. May be used to implement complex access patterns. 1D Laplace operator: 1 auto ptr = vex::raw_pointer(x); 2 auto idx = vex::element_index(); 3 4 auto left = if_else(idx > 0, i - 1, i); 5 auto right = if_else(idx + 1 < n, i + 1, i); 6 7 y = 2 * ptr[idx] - ptr[left] - ptr[right];
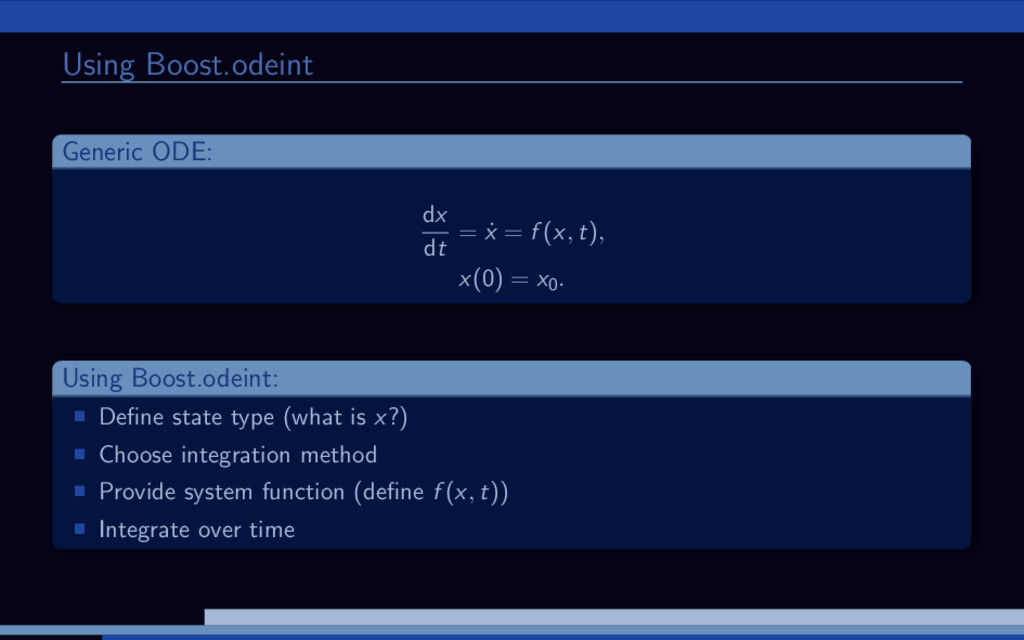
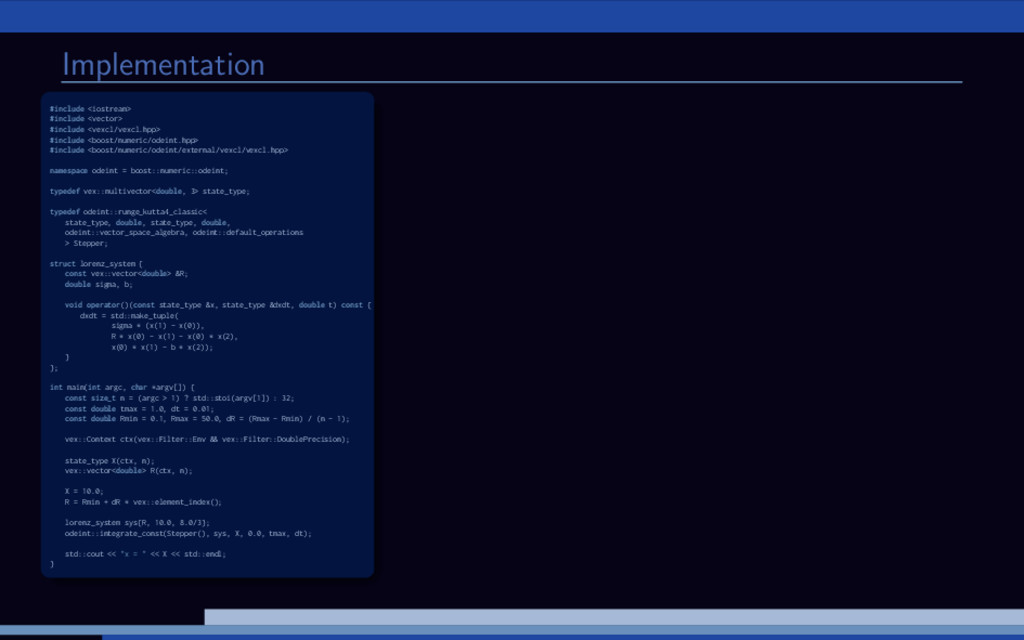
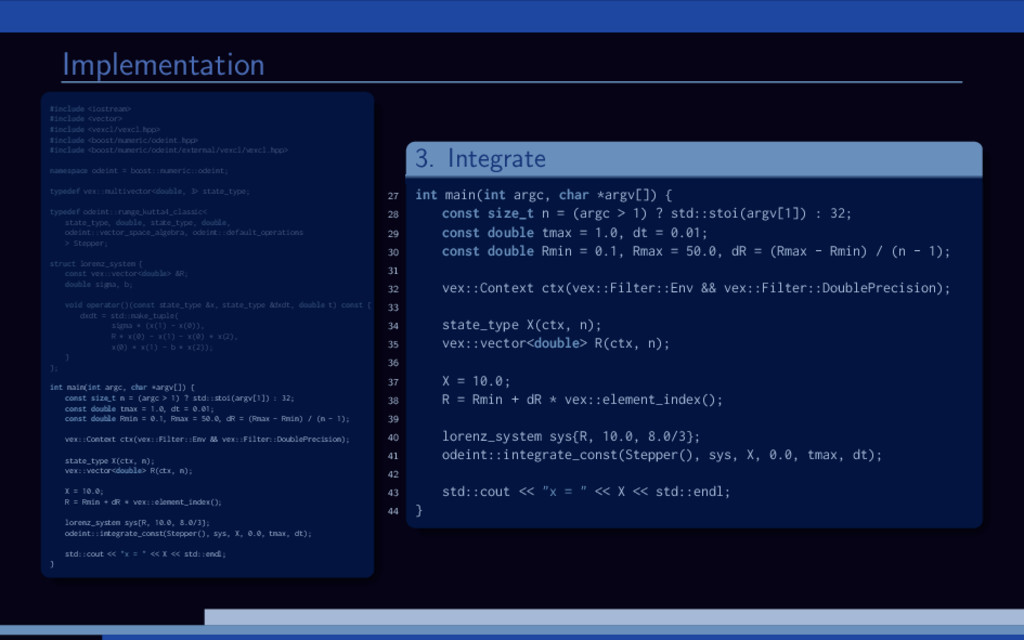
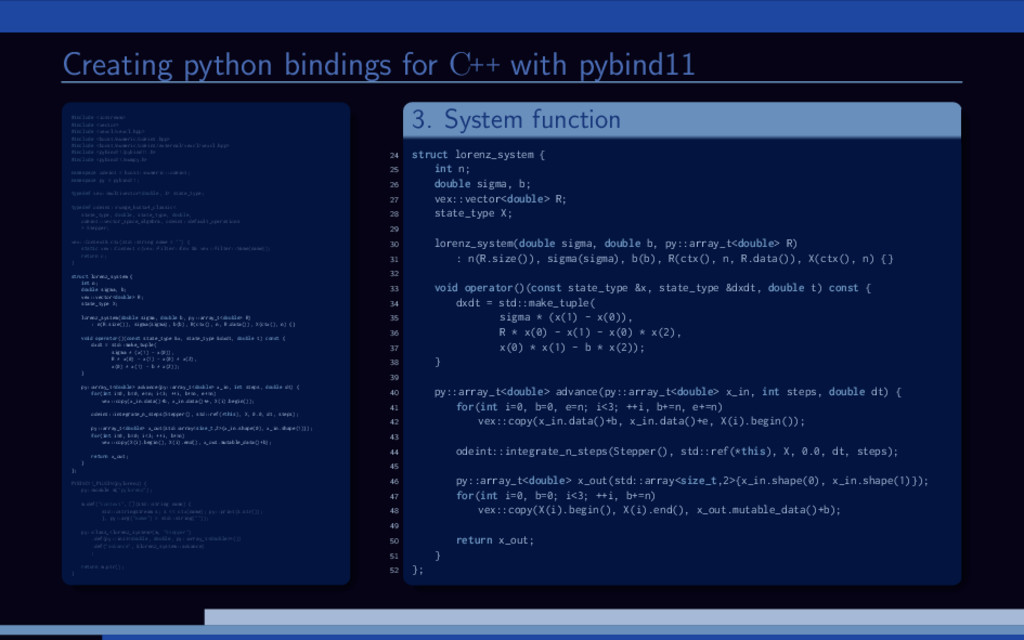
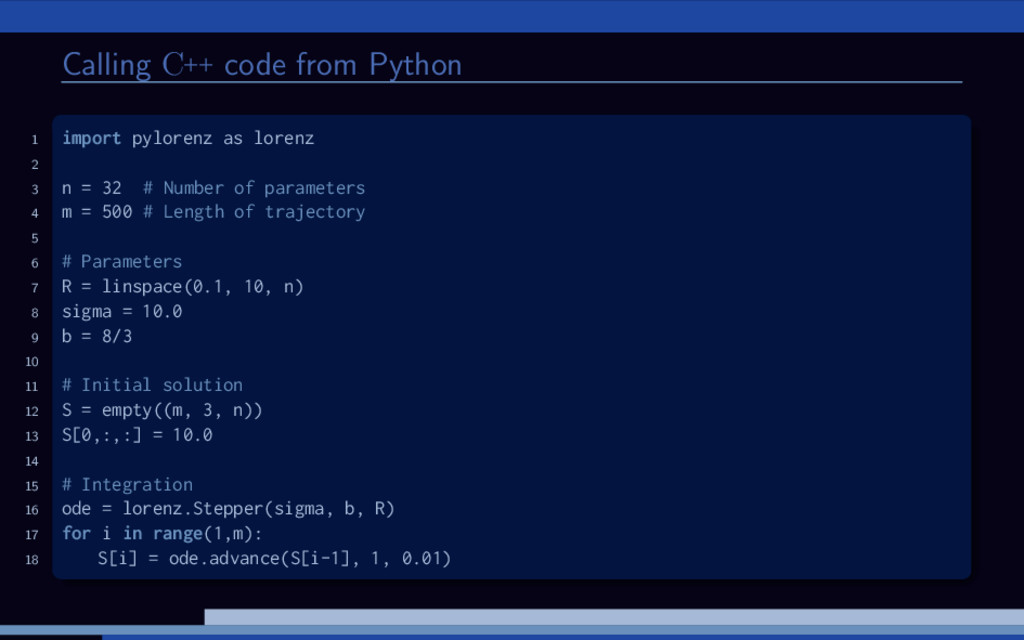
−σ (x − y) , ˙ y = Rx − y − xz, ˙ z = −bz + xy. 20 0 20 20 0 20 40 20 40 60 80 Lorenz attractor trajectory Parameter study for the Lorenz attractor system: Solve large number of Lorenz systems, each for a different value of R. Let’s use Boost.odeint together with VexCL for that. [1] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9 7
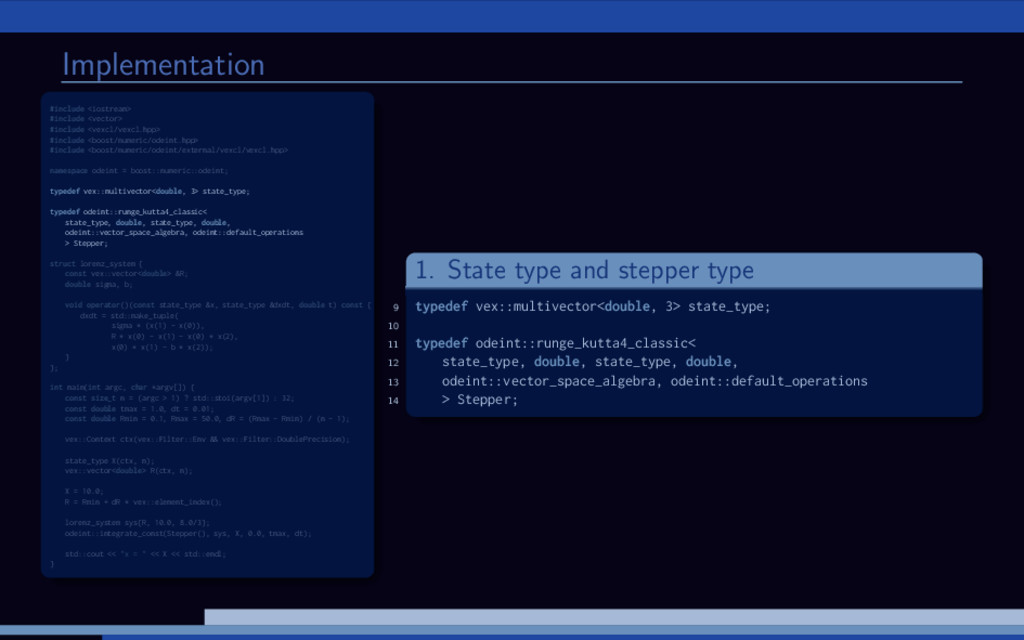
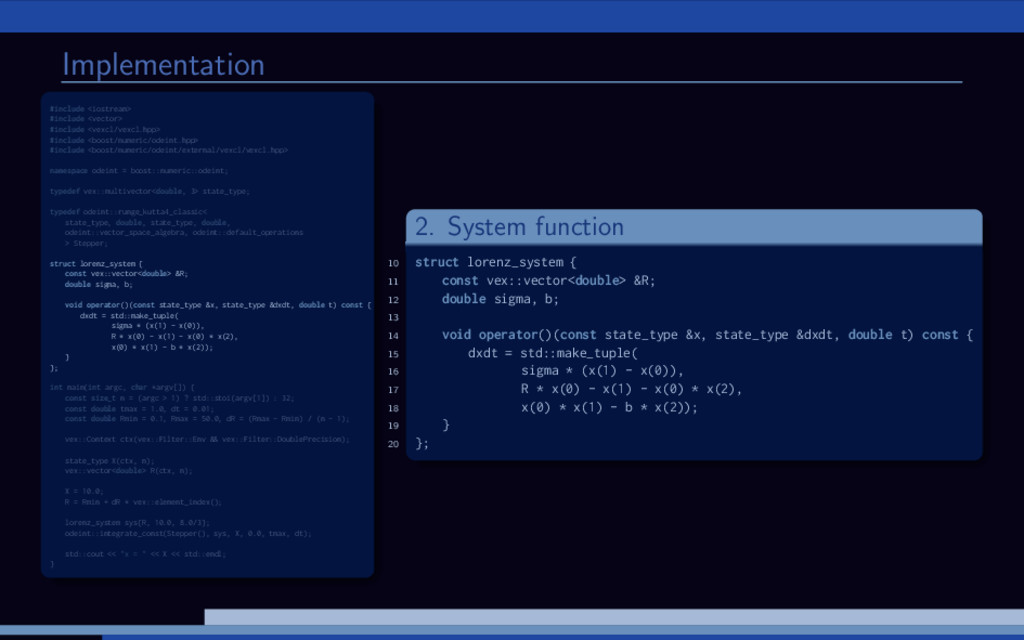
f (x, t), x(0) = x0. Using Boost.odeint: Define state type (what is x?) Choose integration method Provide system function (define f (x, t)) Integrate over time
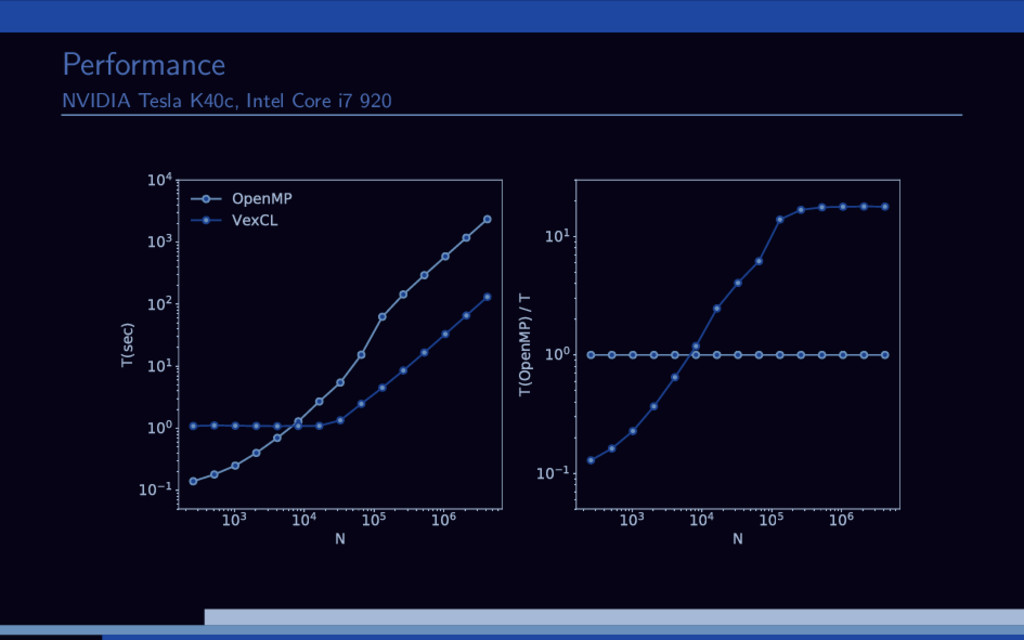
great for fast prototyping of scientific GPGPU applications. The performance is often on-par with manually written kernels. Using custom kernels or third-party functionality is still possible.
great for fast prototyping of scientific GPGPU applications. The performance is often on-par with manually written kernels. Using custom kernels or third-party functionality is still possible. It stresses the compiler greatly. Compilation takes a lot of RAM and a lot of time. But, it’s easy to combine C++ with Python: http://pybind11.readthedocs.io https://xkcd.com/303/
Algebraic Multigrid implementation: https://github.com/ddemidov/amgcl Boost.odeint — numerical solution of Ordinary Differential Equations: https://github.com/boostorg/odeint Antioch — A New Templated Implementation Of Chemistry for Hydrodynamics (The University of Texas at Austin): https://github.com/libantioch/antioch FDBB — Fluid Dynamics Building Blocks ( ): https://gitlab.com/mmoelle1/FDBB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}