G itH ub Создана для облегчения разработки GPGPU приложений на C++ Удобная нотация для векторных выражений Автоматическая генерация вычислительных ядер во время выполнения Поддерживаемые технологии OpenCL (Khronos C++ API, Boost.Compute) NVIDIA CUDA OpenMP Исходный код доступен под лицензией MIT https://github.com/ddemidov/vexcl
Основная идея не нова: 1995: Todd Veldhuizen, Expression templates, C++ Report. 1996: Blitz++: библиотека C++ для научных расчетов, сравнимая по произодительности с Фортраном 77/90. Сегодня: Armadillo, Blaze, Boost.uBLAS, Eigen, MTL, и т. д. VexCL использует этот подход для автоматической генерации вычислительных ядер OpenCL/CUDA
совместимыми: Иметь один размер Быть расположенными на одних и тех же устройствах Что можно использовать в выражениях: Векторы, скаляры, константы Арифм. и логич. операторы Встроенные функции Пользовательские функции Генераторы случайных чисел Сортировка, префиксные суммы Временные значения Срезы и перестановки Редукция (сумма, экстремумы) Произв. матрицы на вектор Свертки Быстрое преобразование Фурье
возвращает индекс текущего элемента вектора. Нумерация начинается с offset , элементы на всех устройствах нумеруются последовательно. Необязательный параметр size задает размер выражения. Линейная функция: 1 vex::vector<double> X(ctx, N); 2 double x0 = 0, dx = 1e−3; 3 X = x0 + dx ∗ vex::element_index(); Один период функции синуса: 1 X = sin(2 ∗ M_PI / N ∗ vex::element_index());
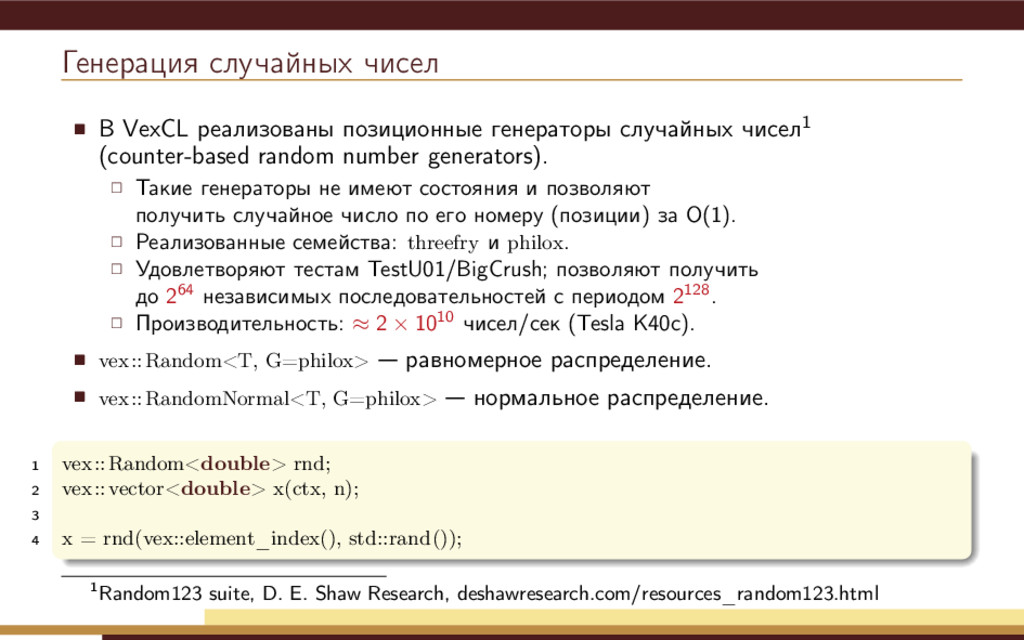
(counter-based random number generators). Такие генераторы не имеют состояния и позволяют получить случайное число по его номеру (позиции) за O(1). Реализованные семейства: threefry и philox. Удовлетворяют тестам TestU01/BigCrush; позволяют получить до 264 независимых последовательностей с периодом 2128. Производительность: ≈ 2 × 1010 чисел/сек (Tesla K40c). vex::Random<T, G=philox> равномерное распределение. vex::RandomNormal<T, G=philox> нормальное распределение. 1 vex::Random<double> rnd; 2 vex::vector<double> x(ctx, n); 3 4 x = rnd(vex::element_index(), std::rand()); 1Random123 suite, D. E. Shaw Research, deshawresearch.com/resources_random123.html
получить значение типа T. Виды редукции: SUM, SUM_Kahan, MIN, MAX Скалярное произведение 1 vex::Reductor<double> sum(ctx); 2 double s = sum(x ∗ y); Число элементов в интервале (0, 1) 1 vex::Reductor<size_t> sum(ctx); 2 size_t n = sum( (x > 0) && (x < 1) ); Максимальное расстояние от центра 1 vex::Reductor<double, vex::MAX> max(ctx); 2 double d = max( sqrt(x ∗ x + y ∗ y) );
(x − y) , ˙ y = Rx − y − xz, ˙ z = −bz + xy. Необходимо решать большое число систем Лоренца для различных значений R. Будем использовать Boost.odeint. 20 10 0 10 20 20 0 20 0 10 20 30 40 50
dt = ˙ x = f (x, t), x(0) = x0. Применение Boost.odeint: 1 Определяем тип переменной состояния (что такое x?) 2 Определяем системную функцию (f ) 3 Выбираем алгоритм интегрирования 4 Выполняем интегрирование по времени
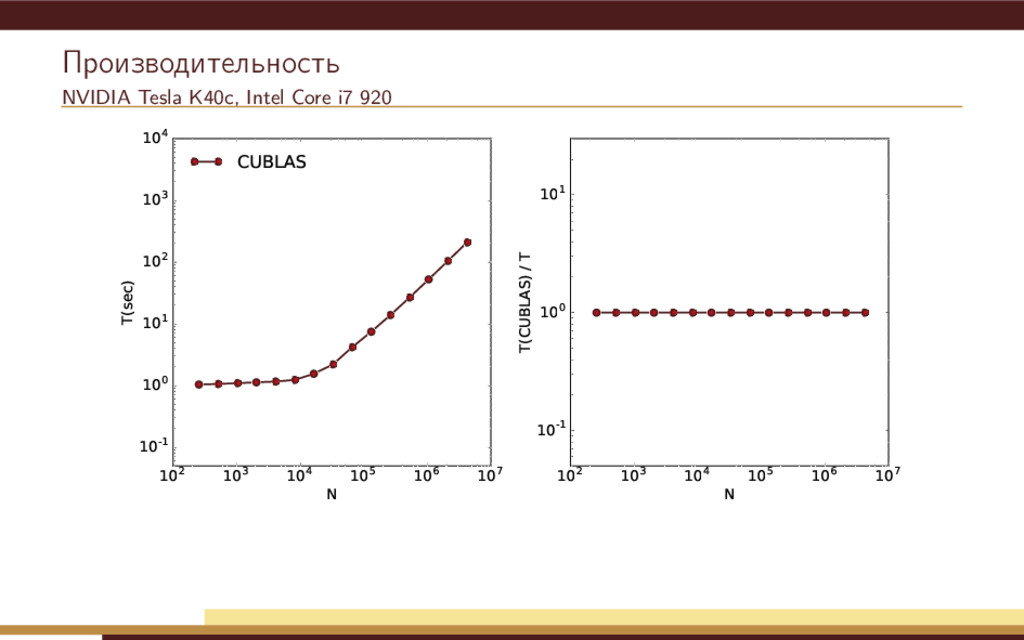
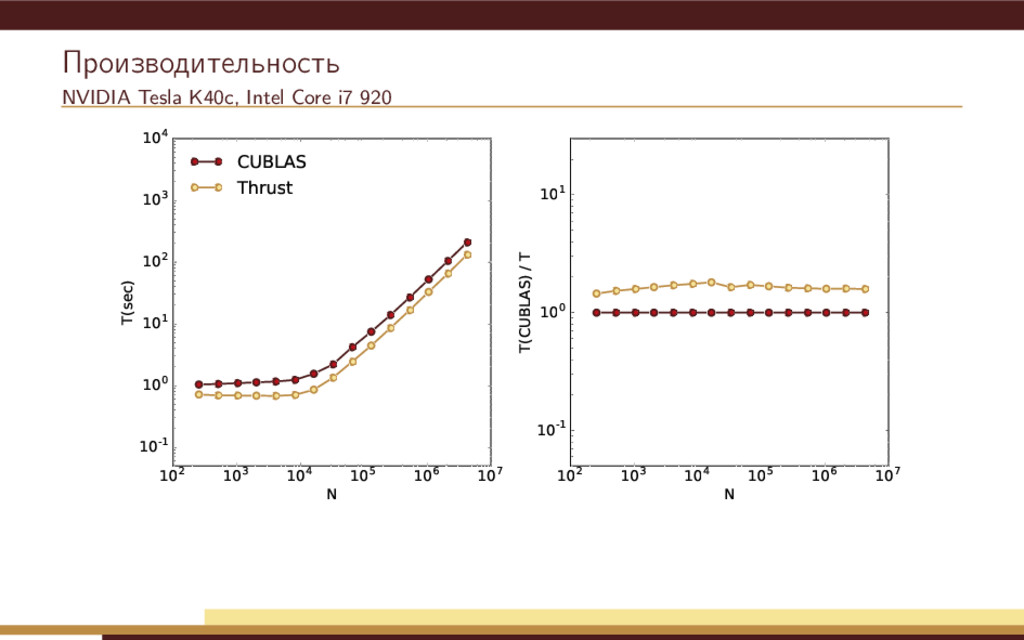
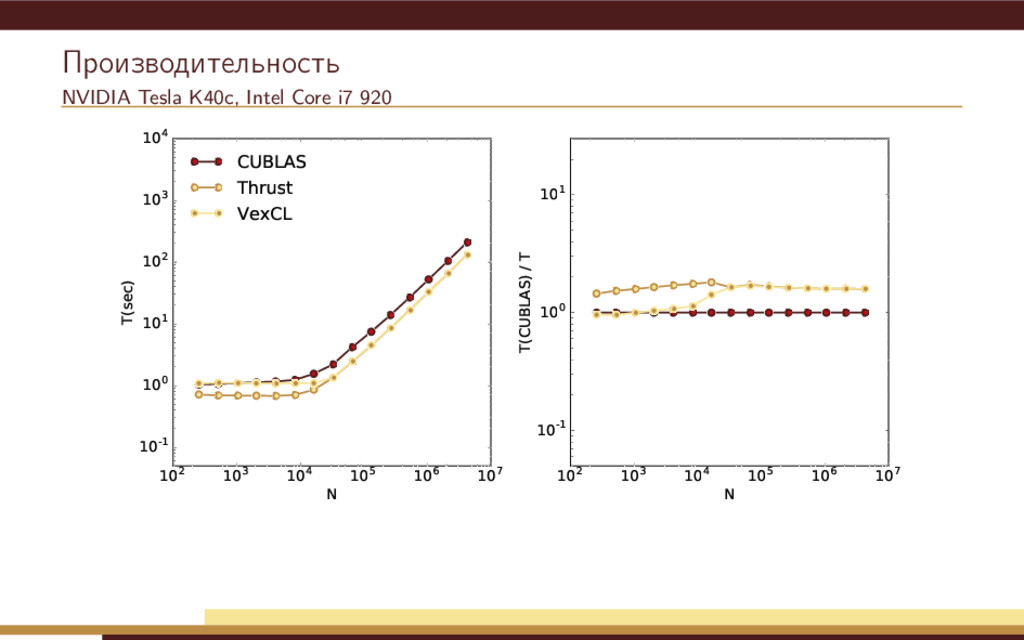
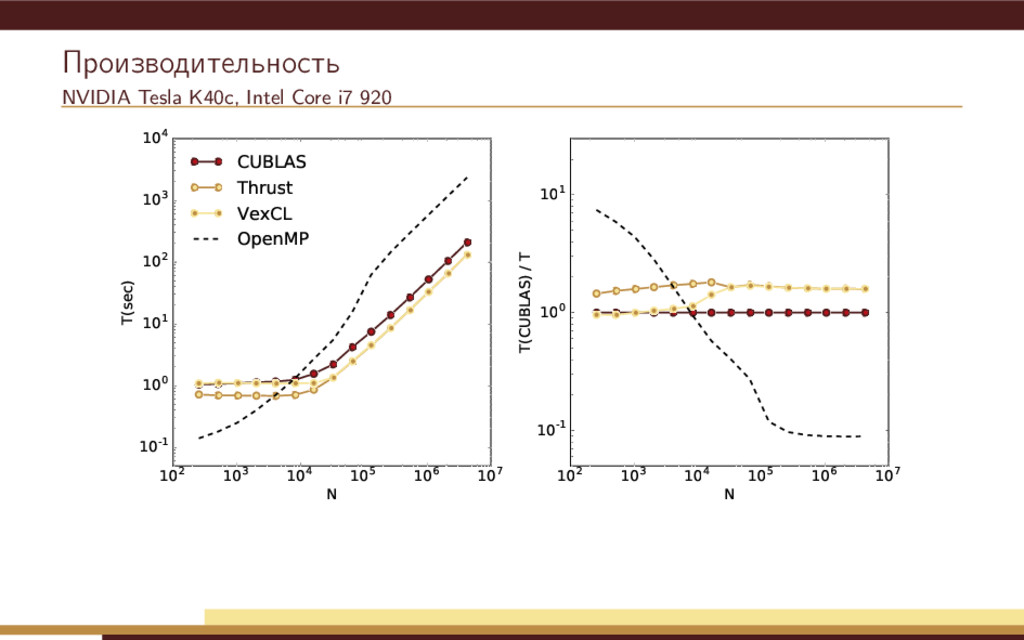
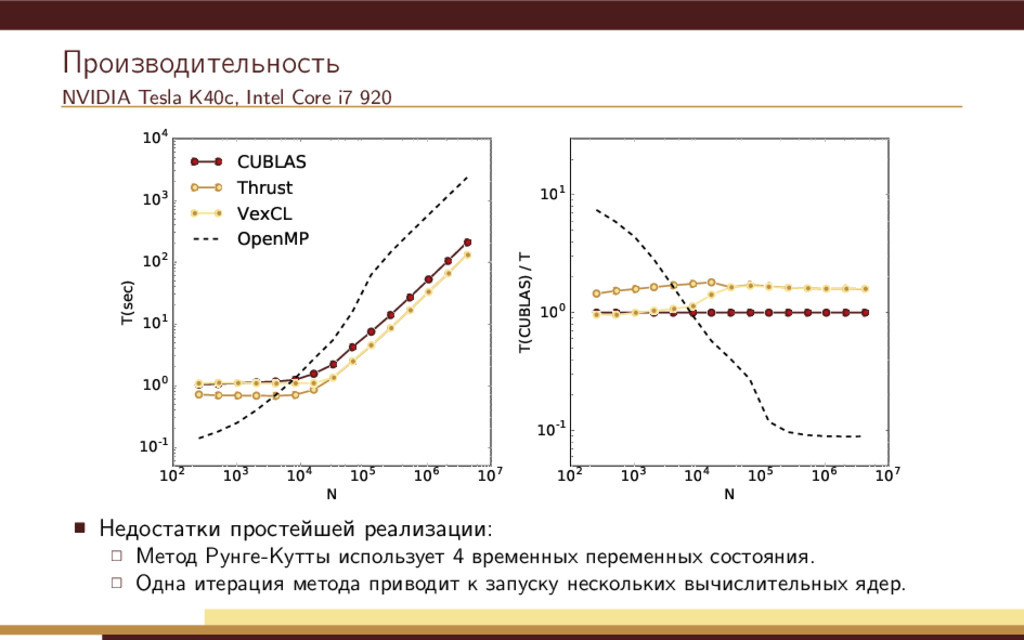
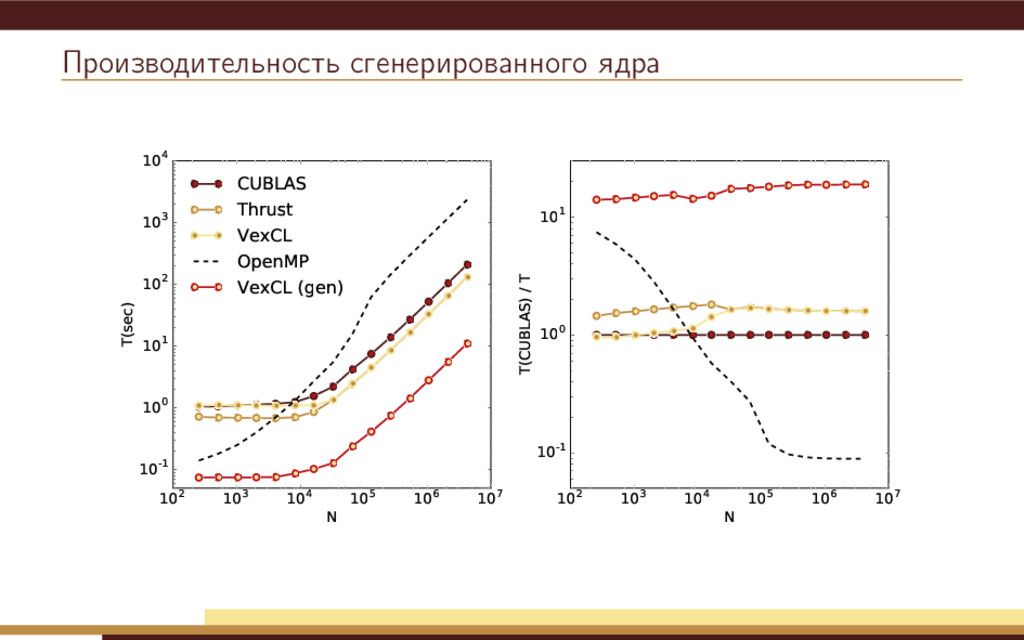
104 105 106 107 N 10-1 100 101 102 103 104 T(sec) CUBLAS Thrust VexCL OpenMP 102 103 104 105 106 107 N 10-1 100 101 T(CUBLAS) / T Недостатки простейшей реализации: Метод Рунге-Кутты использует 4 временных переменных состояния. Одна итерация метода приводит к запуску нескольких вычислительных ядер.
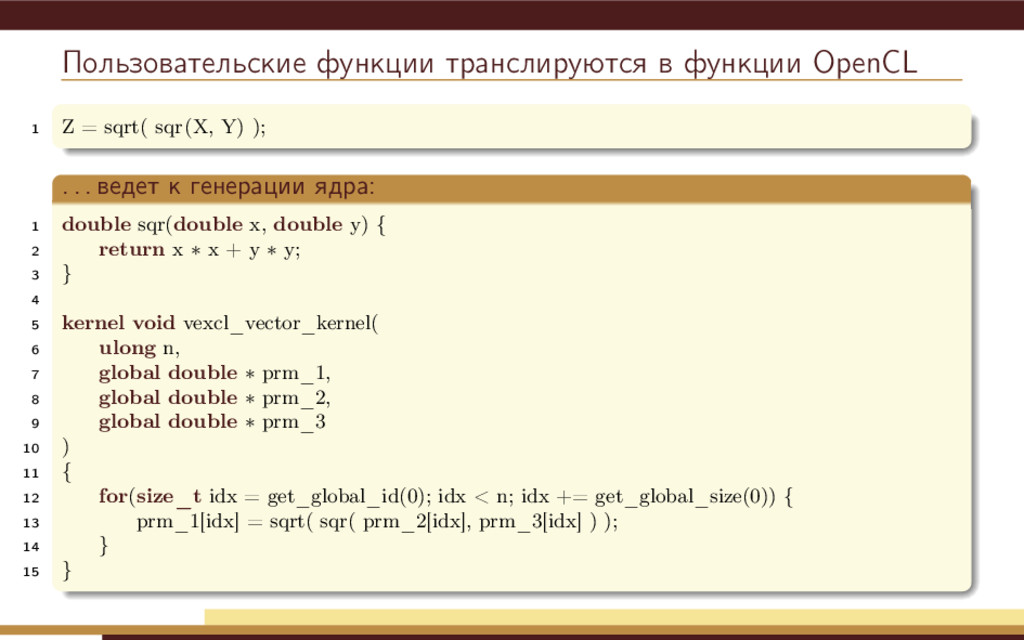
Любые операции с переменными этого типа выводятся в текстовый поток: Код 1 vex::symbolic<double> x = 6, y = 7; 2 x = sin(x ∗ y); Результат 1 double var1 = 6; 2 double var2 = 7; 3 var1 = sin( ( var1 ∗ var2 ) );
Любые операции с переменными этого типа выводятся в текстовый поток: Код 1 vex::symbolic<double> x = 6, y = 7; 2 x = sin(x ∗ y); Результат 1 double var1 = 6; 2 double var2 = 7; 3 var1 = sin( ( var1 ∗ var2 ) ); Простая идея: Запишем последовательность действий алгоритма. Сгенерируем монолитное ядро OpenCL. Ограничения: Строго параллельные алгоритмы (без взаимодействия между потоками). Не допускаются ветвления.
быстрой разработки научных GPGPU приложений. Производительность часто сравнима с ядрами, написанными вручную. [1] D. Demidov, K. Ahnert, K. Rupp, and P. Gottschling. Programming CUDA and OpenCL: A Case Study Using Modern C++ Libraries. SIAM J. Sci. Comput., 35(5):C453 – C472, 2013. doi:10.1137/120903683 [2] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9_7
с целью оценки нефтегазоносности геологических объектов. Гетерогенный вычислительный кластер занимает 38 место в Top50 по России Для ускорения расчетов используется VexCL
ОДУ на GPU с помощью VexCL. [1] D. Demidov, K. Ahnert, K. Rupp, and P. Gottschling. Programming CUDA and OpenCL: A Case Study Using Modern C++ Libraries. SIAM J. Sci. Comput., 35(5):C453 – C472, 2013. doi:10.1137/120903683 [2] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9_7 Volodymyr Kindratenko Editor Numerical Computations with GPUs
of Texas at Austin, USA https://github.com/libantioch/antioch Гидродинамические расчеты с учетом химических реакций Для расчетов на GPU используется VexCL PECOS Predictive Engineering and Computational Sciences Predictive Uncertainty Quantification of An Ablating Entry Vehicle Heatshield Roy H. Stogner, Benjamin Kirk, Paul Bauman, Todd Oliver, Kemelli Estacio, Nicholas Malaya, Marco Panesi, Juan Sanchez The University of Texas at Austin March 16, 2015 R. Stogner Ablating Heatshield UQ March 16, 2015 1 / 25
of Texas at Austin, USA https://github.com/libantioch/antioch Гидродинамические расчеты с учетом химических реакций Для расчетов на GPU используется VexCL Entry Vehicle Physics Full System, Uncertainties • High enthalpy aerothermochemistry, hypersonic flow • Submodel uncertainties (turbulence, nitridation, kinetics) • Numerical limitations (discretization, UQ error) • Modeling unknowns (missing/wrong physics?) R. Stogner Ablating Heatshield UQ March 16, 2015 3 / 25
https://gitlab.com/mmoelle1/FDBB Библиотека алгоритмов для вычислительной гидродинамики VexCL поддерживается как один из возможных бакендов Fluid Dynamics Building Blocks2 Armadillo ArrayFire Blaze Blitz++ Eigen IT++ MTL4 uBLAS VexCL ViennaCL ... Low-level Unified wrapper function API to core functionality of ETL’s: make temp, tag, tie, +, -, *, /, abs, sqrt, ... High-level SFET’s for conservative/primitive variables, EOS, invis- cid/viscous fluxes, flux Jacobians, and Riemann solvers 2https://gitlab.com/mmoelle1/FDBB.git 11 / 45
ottingen, Germany Ускорение до 20x по сравнению с CPU Реализовал преобразование Фурье и генерацию случайных чисел в VexCL GEORG-AUGUST-UNIVERSITÄT GÖTTINGEN ZENTRUM FÜR INFORMATIK ISSN 1612-6793 NUMMER ZAI-BSC-2013-15 Bachelorarbeit im Studiengang „Angewandte Informatik“ GPU-Implementierung eines Multi-Skalen-Schätzers zur lokal-adaptiven Bildentrauschung Pascal Schmitt* betreut durch Prof. Axel Munk Lehrstuhl für Wissenschaftliches Rechnen Bachelor- und Masterarbeiten des Zentrums für Informatik Georg-August-Universität Göttingen 12. August 2013 * [email protected]
данных лидара в реальном времени с помощью GPU Ускорение 1000x по сравнению с примитивным алгоритмом на CPU Real-Time localisation based on range template matching accelerated by an GPU Boris Smidt University of Antwerp Antwerp, Belgium Email: [email protected] Rafael Berkvens University of Antwerp Antwerp, Belgium Email: [email protected] Maarten Weyn University of Antwerp Antwerp, Belgium Email: [email protected] Abstract—A ship requires a location and an orientation to navigate trough a channel or river. We propose the usage of the radar system and a map to get a correct location. Because this is a large problem we will focus on the localization part of the problem and use a laser range finder instead of radar. We compared an iterative closest point(ICP) algorithm and a grid filter to solve the localization. We used an Graphics Processing Unit to accelerate the grid filter algorithm and achieved a 1000 fold in performance compared to a naive CPU algorithm. This allowed us to track the robot. We chained up two grid filters to improve the sampling efficiency of the grid filter this is called a multi resolution grid filter. This enabled us to check the location at the map resolution. The result is a real time algorithm achieve a 99.9 % accuracy within 0.5m and a rotational accuracy of 90% at 1.5 degree. The ICP algorithm however is unable to do a global localization nor could it improve a generated GPS coordinate. We concluded that the grid filter is a viable solution to solve the localization problem when calculated using a GPU. I. INTRODUCTION A ship requires a location and an orientation to navigate trough a channel or river. However a GPS returns a broad location without orientation and thus is not a viable solution. We propose the usage of a radar system for localization. The radar scan will be compared to the map of the channel to extract the location. This is a large and complex problem and has to be split up into multiple problems. These include radar sensor models, sensor fusing and localization. This paper limits itself to the localization process. We will use a laser range finder instead of a radar. Because the laser range finder provides less data and is therefor easier to use. To solve the localization problem we will use matching algorithms. The first algorithm is the Iterative Closest Point (ICP) algorithm. This algorithm iteratively matches two pointclouds: the range scan and the map. A point cloud is a set of points, this research uses 2D data thus our pointclouds are a set of two 2D points. The second algorithm is a template matching algorithm, the grid filter, this is a correlation based algorithm. The grid filter tries to match the range data to the map in certain possible positions and orientations and returns the weight of these tests. II. ACCELERATION FRAMEWORKS The purpose of this paper is to create real-time algorithms. This means that the calculation time of the algorithm may not exceed the update time of a scan. The LMS100 laser has a scan frequency between 25 and 50Hz, this equals 40 to 20ms of calculation time. The following frameworks are used to improve the algorithm performance. OpenMP [1] is a compiler based library and works by using compiler hints to parallelize the code. The library supports multiple parallel programming models. But the main focus is the fork-join model. The programmer has to manually manage the number of threads used. OpenCL [1] is a programming language and framework to support multiple kinds of computing devices including CPU, GPU, FPGA and DSP. The parallel programming model used in OpenCL is the data parallel model e.g. vector operations. OpenCL uses kernels to parallelize the code. This is a small C99 syntax function which gets executed on the selected computing device. The kernel is compiled at runtime which enables system specific optimization. These kernels are mostly used to replace the loop body. The main drawback of OpenCL is code portability. The code has to be written for a certain computing device e.g a CPU kernel will be different from a GPU kernel. Another problem of the OpenCL C/C++ SDK is verbosity, a 100 lines of code [2] has to be written to call a simple kernel. OpenCL 1.x only has C as a kernel language thus every kernel had to be rewritten for different data types. This is solved in version 2.1 by offering a new kernel language named OpenCL C++ which allows for template meta programming. To solve these issues there are high level wrappers OpenCL C [3]. An alternative to OpenCL is CUDA but this is limited to Nvidia hardware. This research uses OpenCL as a backend because this is the industry standard. VexCL [4] is a vector expression template library for OpenCL/CUDA written in C++. It lets the developer write simple vector arithmetic functions in C++ which drastically reduces the boilerplate code. The library generates the kernel code for these functions at runtime. This has two advantages: it allows the program to generate optimized code for the CPU and GPU and allows for type independent code. VexCL offers some useful features like caching kernels and load managing between the computing devices. The library still offers low level control and can call custom OpenCL kernels. There are other libraries with the same goal as VexCL but these use different strategies. For example ViennaCL wraps CUDA, OMP and OpenCL BLAS libraries into a single unified library. 1
G itH ub https://github.com/ddemidov/amgcl Реализация алгебраического многосеточного метода. Поддерживает несколько вычислительных бакендов: VexCL, CUDA, ViennaCL, OpenMP, . . . Позволяет использовать пользовательские типы и операции. Исходный код доступен под лицензией MIT
Spain http://www.cimne.com/kratos/ Пакет с открытым исходным кодом для инженерных расчетов В качестве решателя по умолчанию используется AMGCL § Large and Complex Models TOWARDS EXASCALE EXTREMELY LARGE MESH NEEDED!! à volume will contain 2000M elements à Will not fit on “few” processors !Good testcase for the “towards exascale challenge” à Now working on BCs
{kind=link}
{kind=link}
{kind=link}
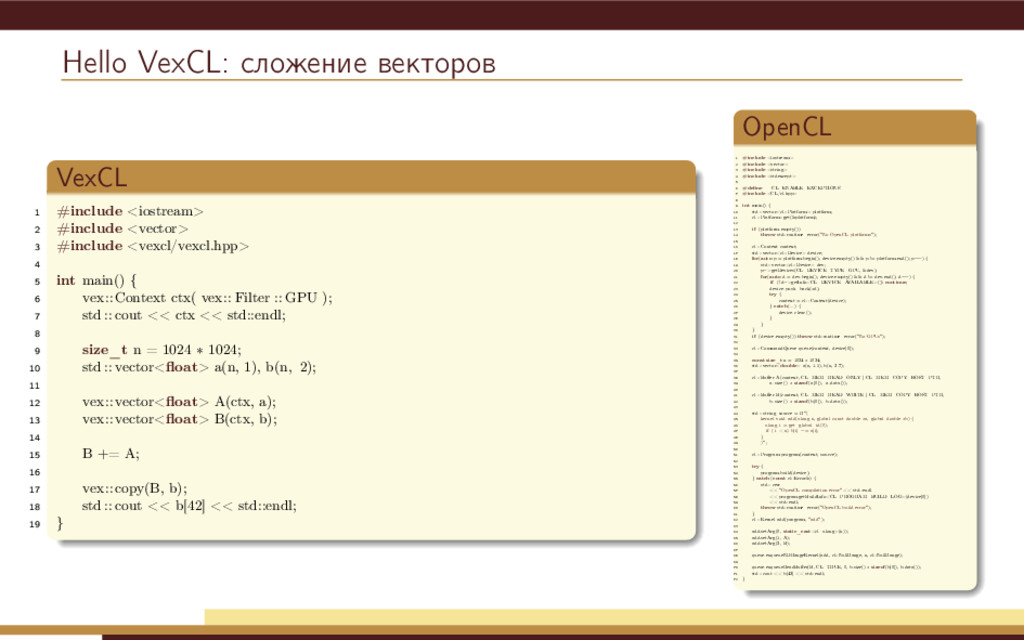{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
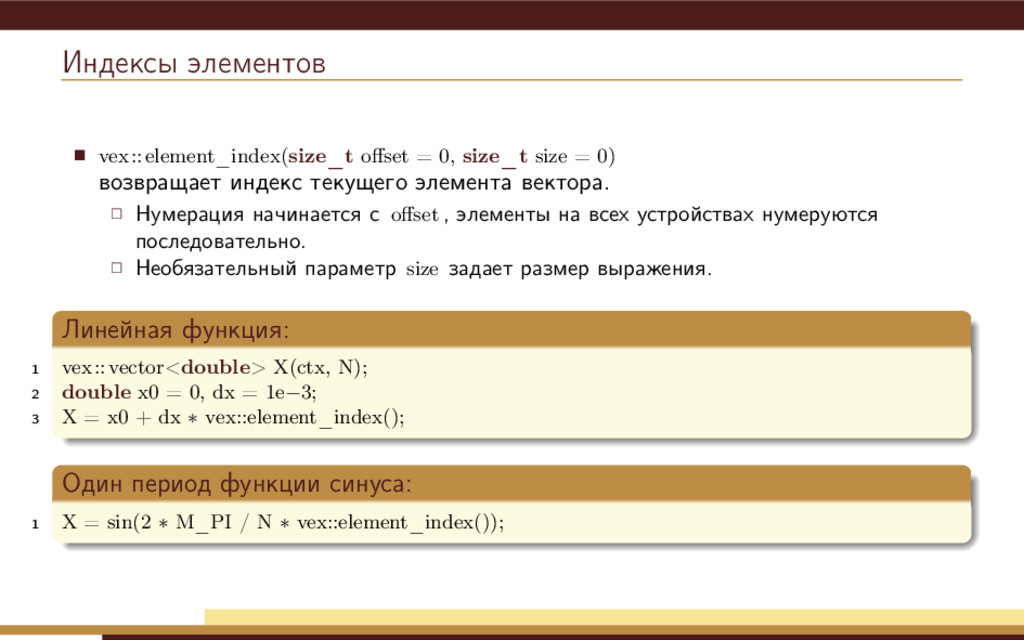{kind=link}
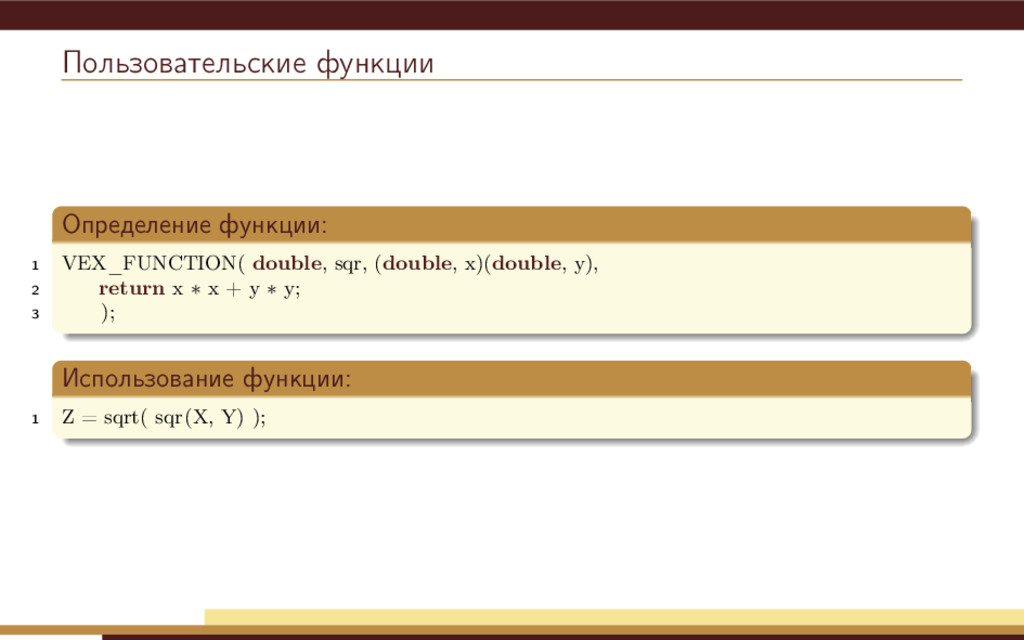{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}