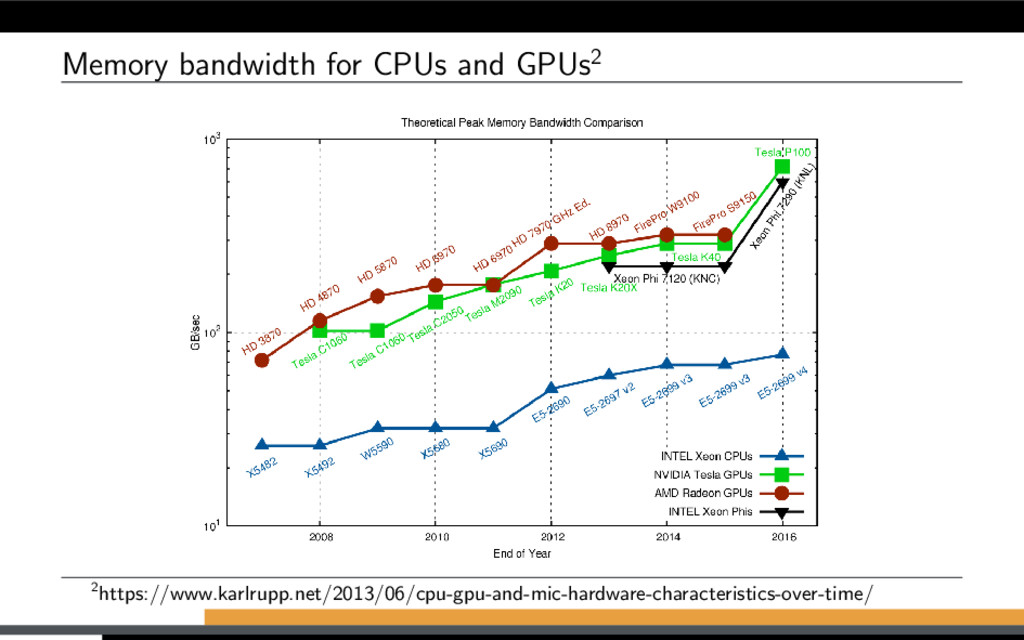
10 systems use accelerators/GPUs Green500 - 6 out of top 10 systems use GPUs PizDaint system (No 3 in Top500) CPU GPU Model Intel Xeon E5-2690 v3 NVIDIA Tesla P100 16GB Peak performance 500 GFLOPS 4.7 TFLOPS Memory bandwidth 68 GB/s 732 GB/s Price $2000 $5700 Max power consumption 135 W 250 W
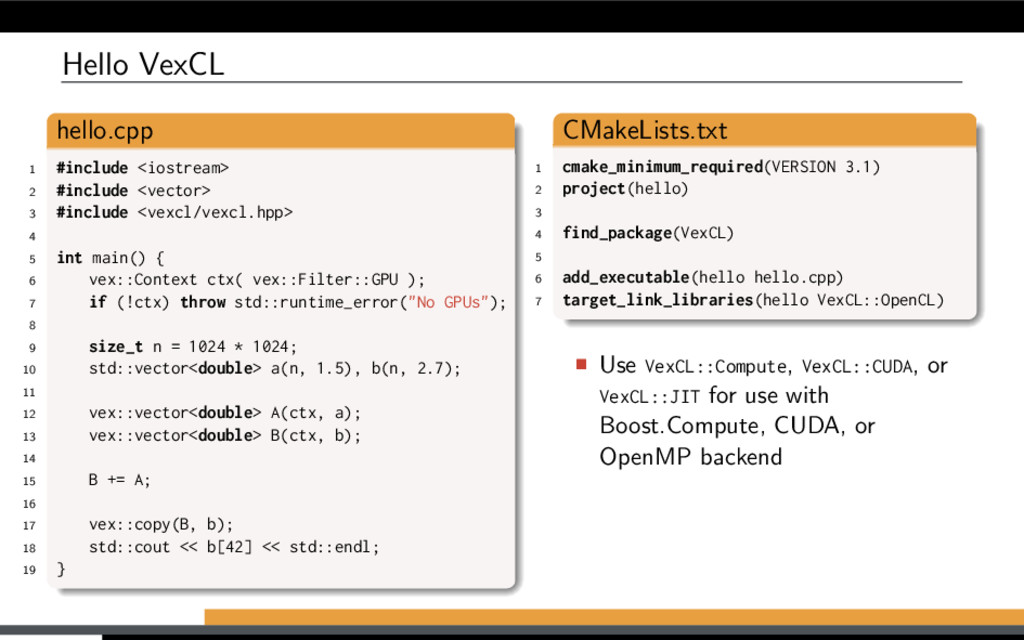
m e on G itH ub Created for ease of C++ based GPGPU development: Convenient notation for vector expressions OpenCL/CUDA JIT code generation Easily combined with existing libraries/code Header-only Supported backends: OpenCL (Khronos C++ bindings) OpenCL (Boost.Compute) NVIDIA CUDA JIT-compiled OpenMP The source code is available under the MIT license: https://github.com/ddemidov/vexcl
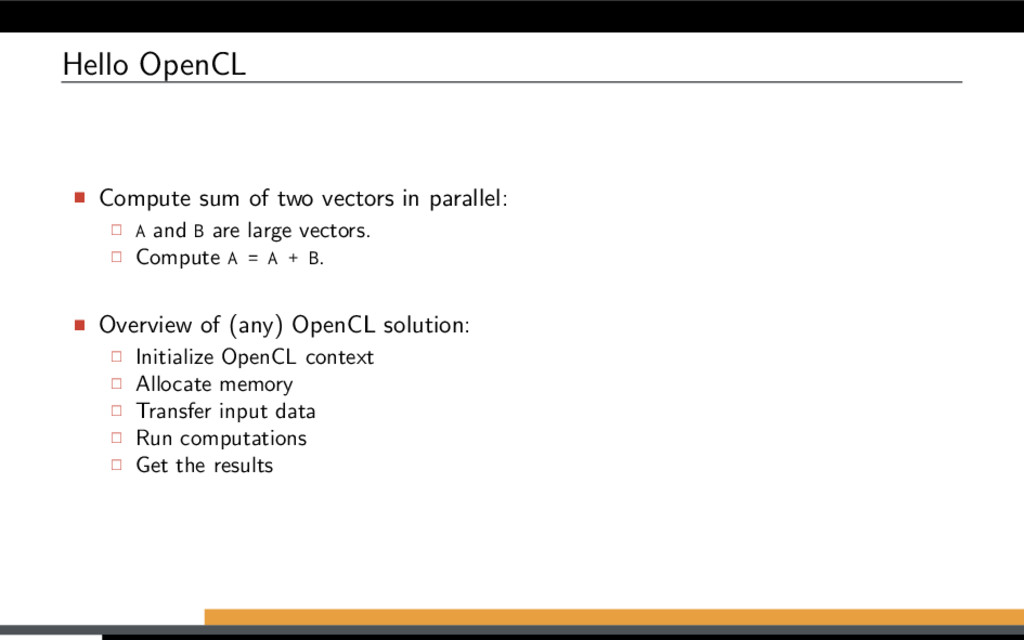
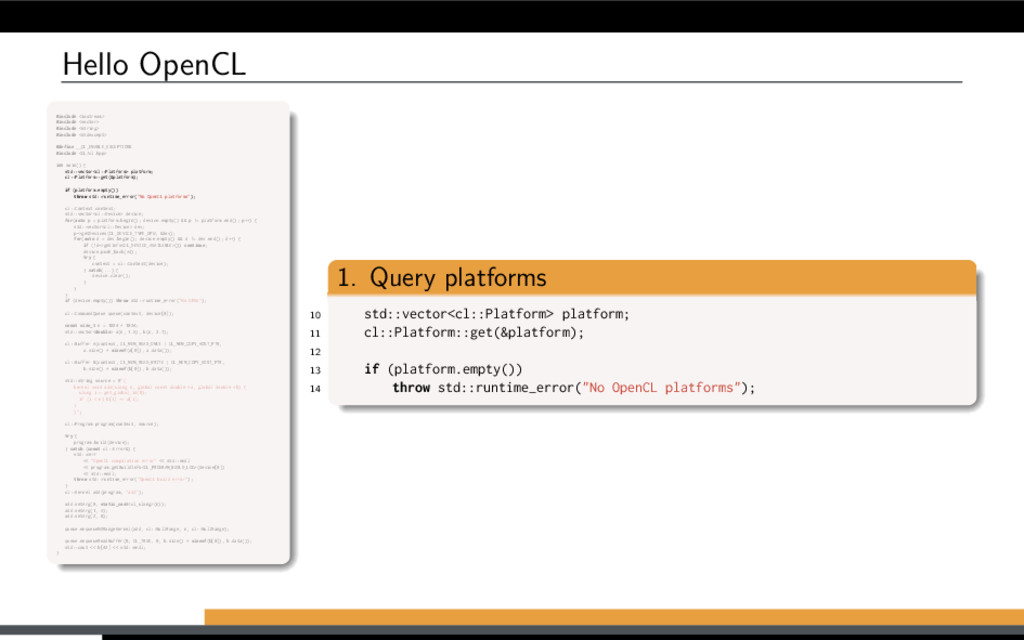
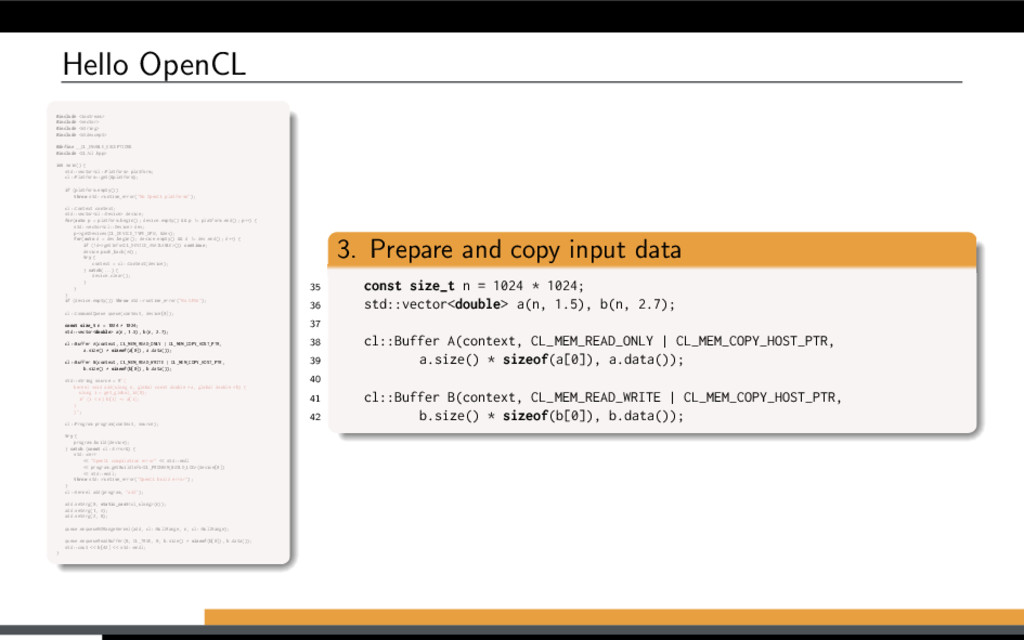
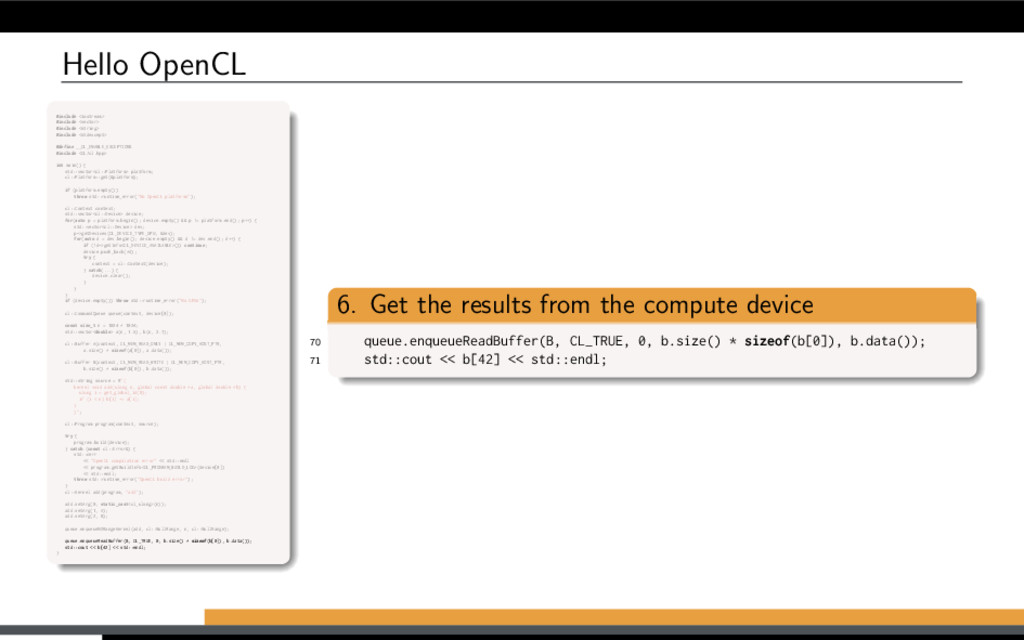
and B are large vectors. Compute A = A + B. Overview of (any) OpenCL solution: Initialize OpenCL context Allocate memory Transfer input data Run computations Get the results
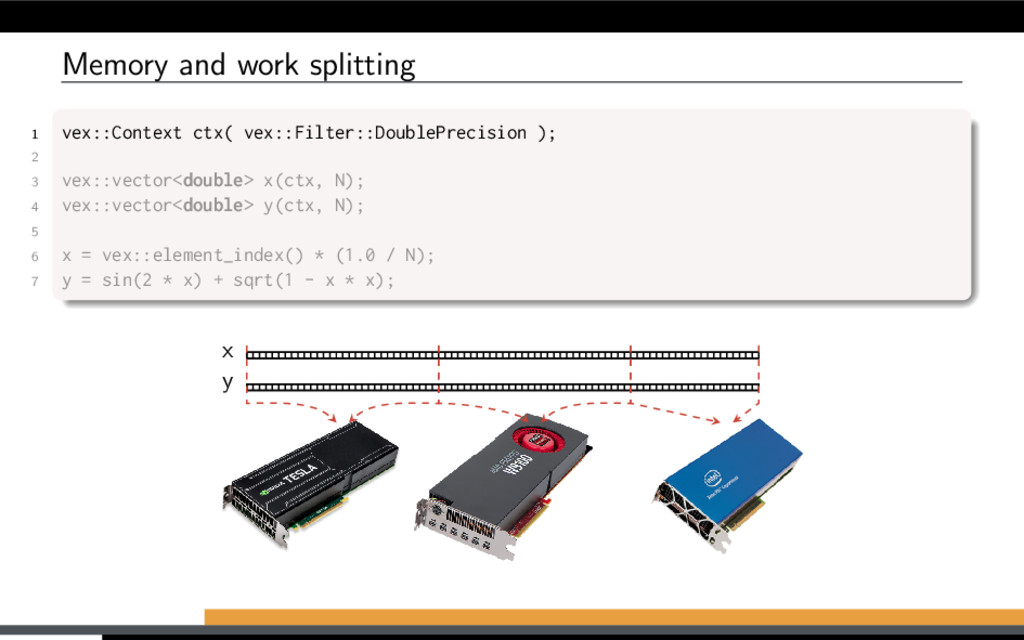
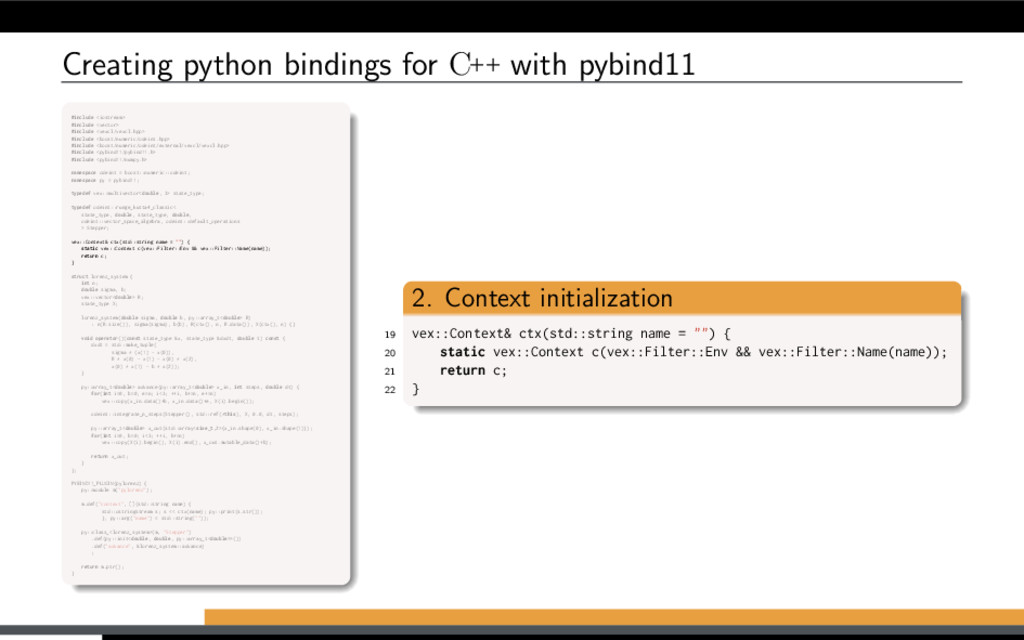
restricted to single-device contexts. VexCL context is initialized from combination of device filters. Initialize VexCL context on selected devices 1 vex::Context ctx( vex::Filter::Any );
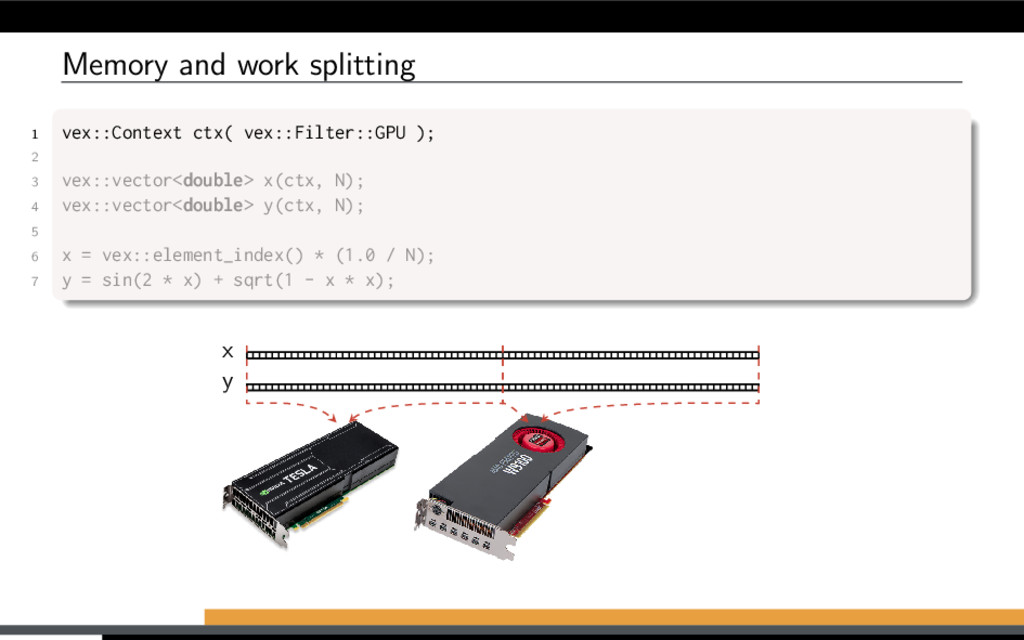
restricted to single-device contexts. VexCL context is initialized from combination of device filters. Initialize VexCL context on selected devices 1 vex::Context ctx( vex::Filter::GPU );
restricted to single-device contexts. VexCL context is initialized from combination of device filters. Initialize VexCL context on selected devices 1 vex::Context ctx(vex::Filter::Name("Intel"));
restricted to single-device contexts. VexCL context is initialized from combination of device filters. Initialize VexCL context on selected devices 1 vex::Context ctx(vex::Filter::GPU && vex::Filter::Platform("AMD"));
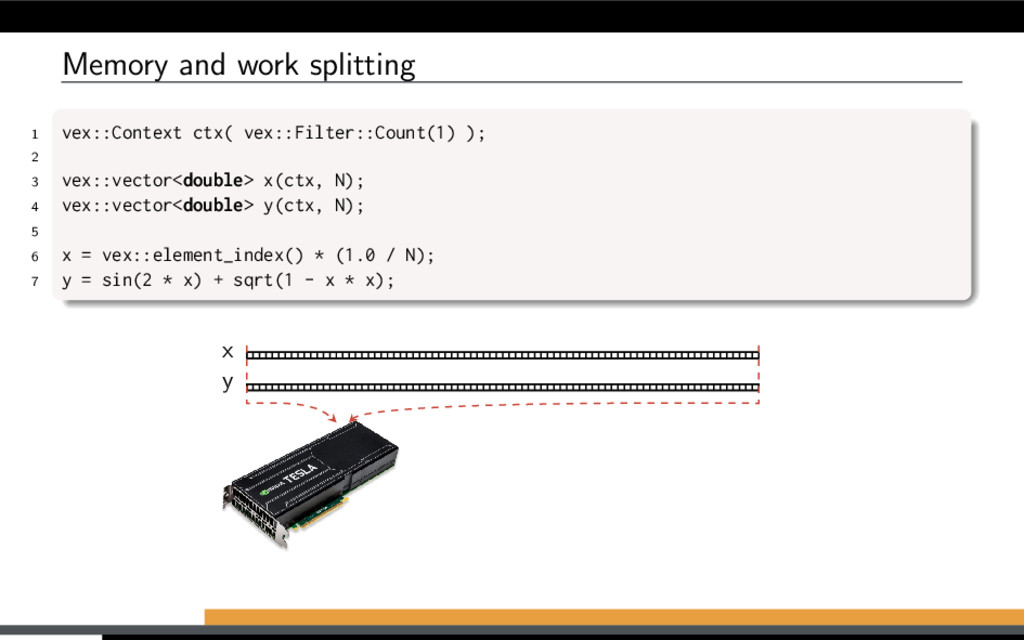
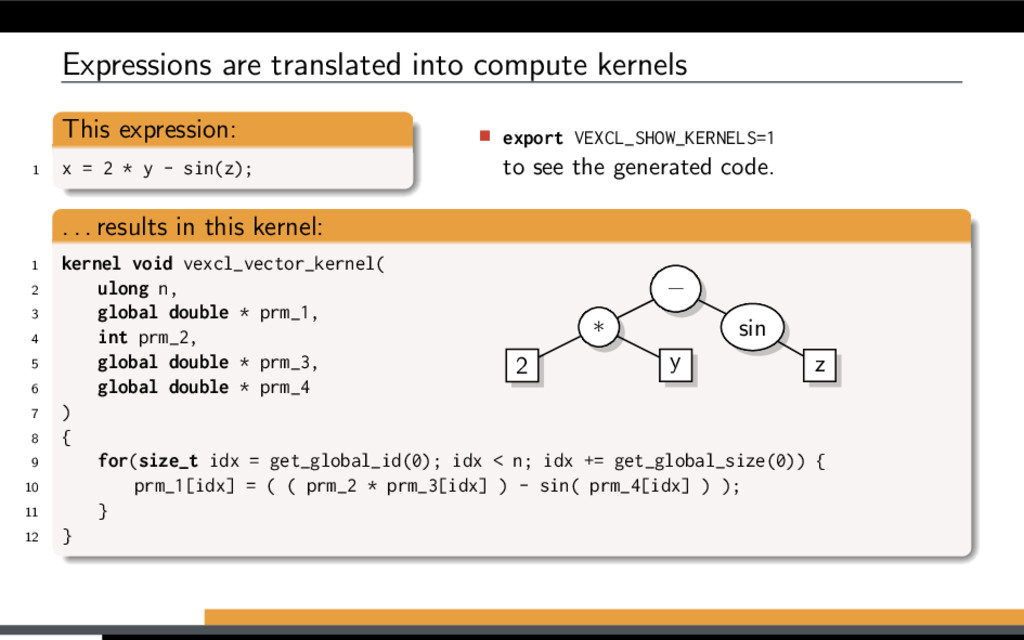
have to be compatible: Have same size Located on same devices What may be used: Vectors, scalars, constants Arithmetic, logical operators Built-in functions User-defined functions Random number generators Slicing and permutations Reduce to a scalar (sum, min, max) Reduce across chosen dimensions Stencil operations Sparse matrix – vector products Fast Fourier Transform Sort, scan, reduce by key
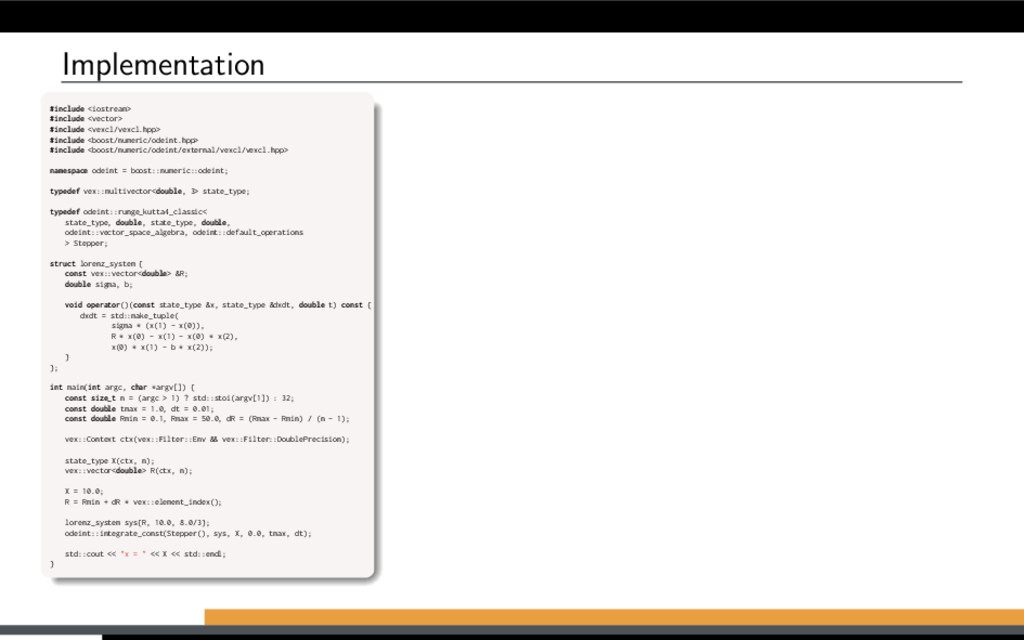
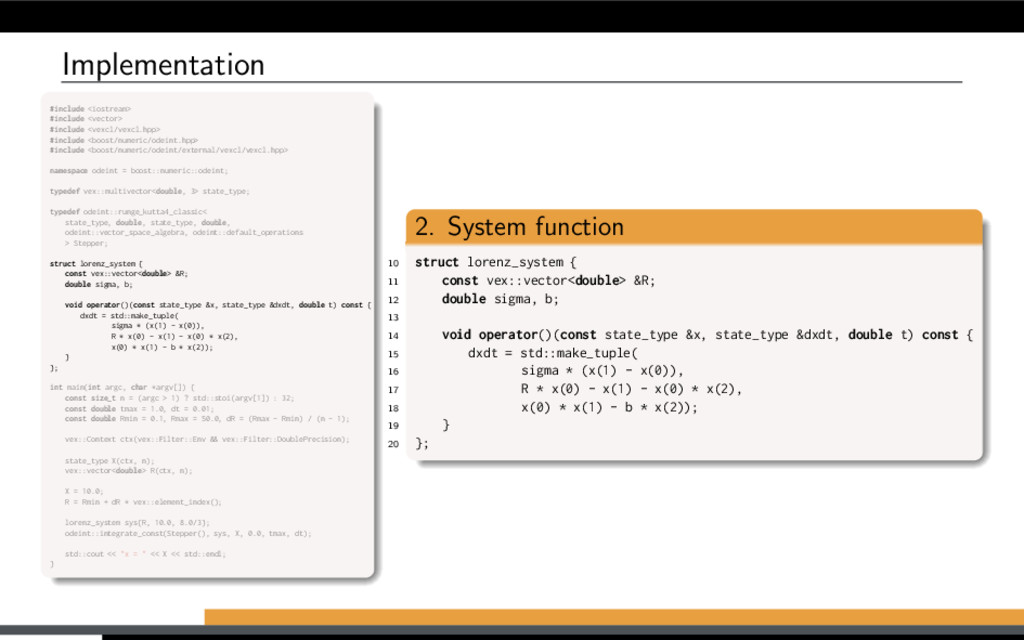
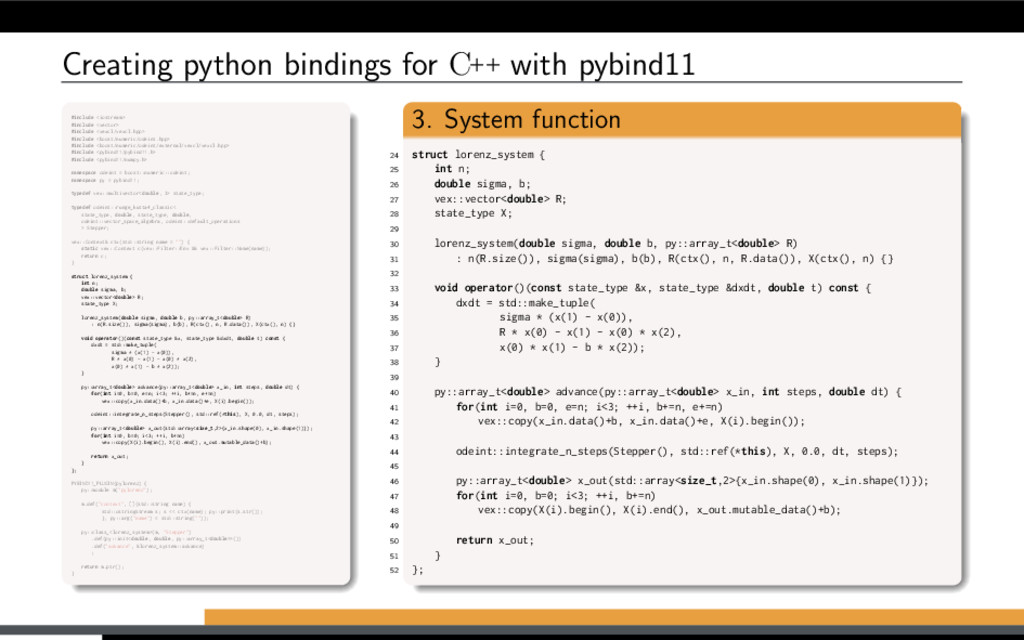
−σ (x − y) , ˙ y = Rx − y − xz, ˙ z = −bz + xy. 20 0 20 20 0 20 40 20 40 60 80 Lorenz attractor trajectory Parameter study for the Lorenz attractor system: Solve large number of Lorenz systems, each for a different value of R. Let’s use Boost.odeint together with VexCL for that. [1] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9 7
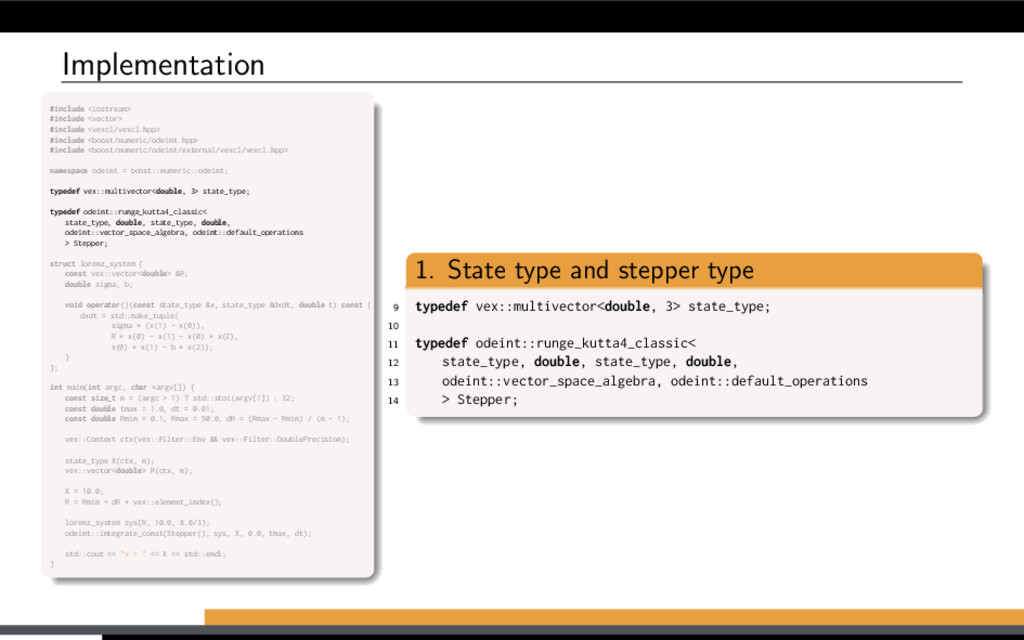
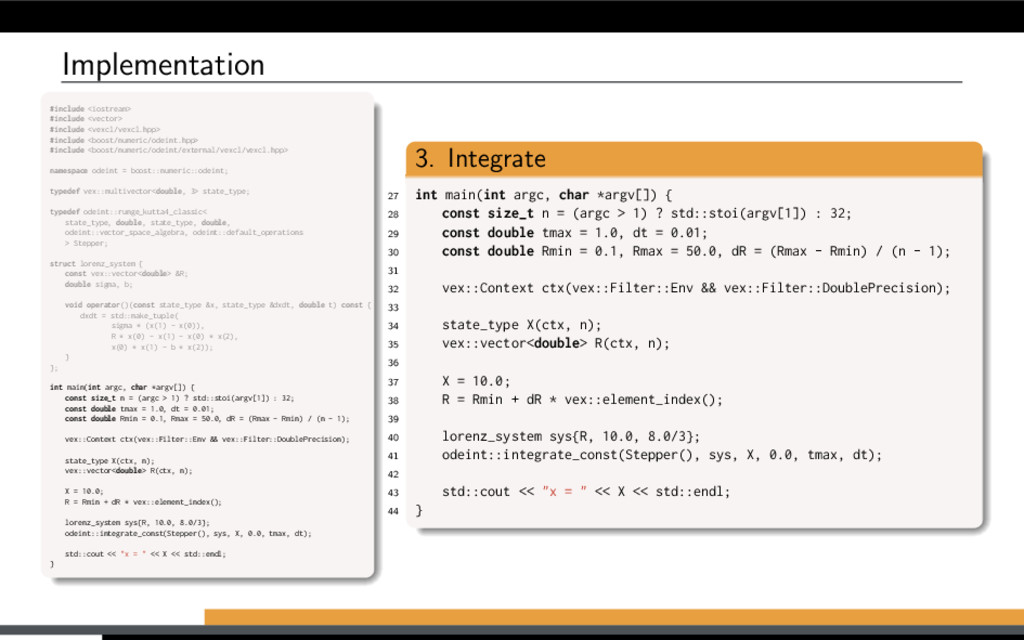
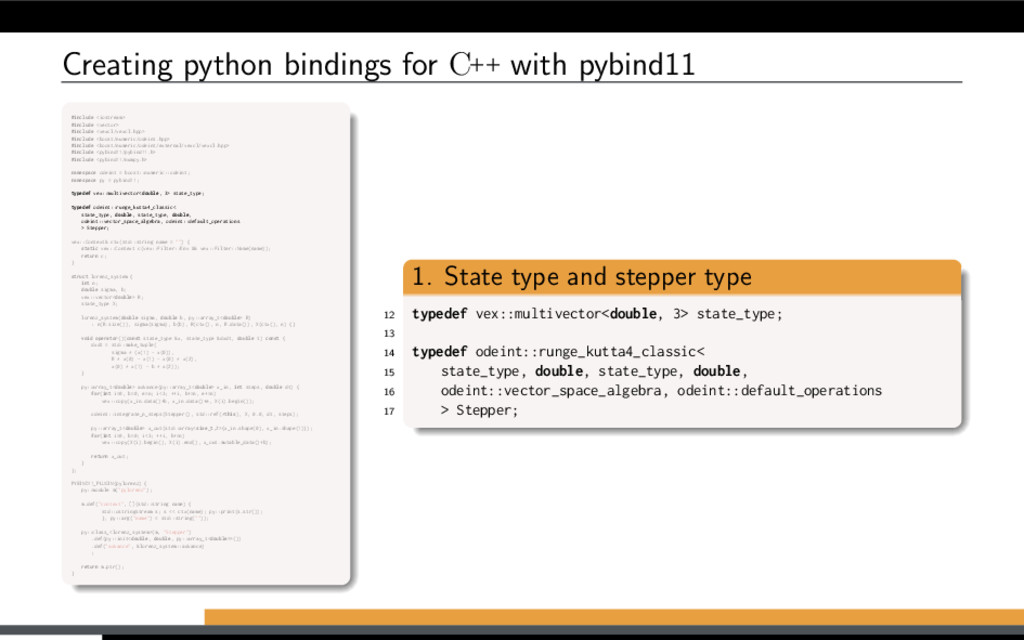
f (x, t), x(0) = x0. Using Boost.odeint: Define state type (what is x?) Choose integration method Provide system function (define f (x, t)) Integrate over time
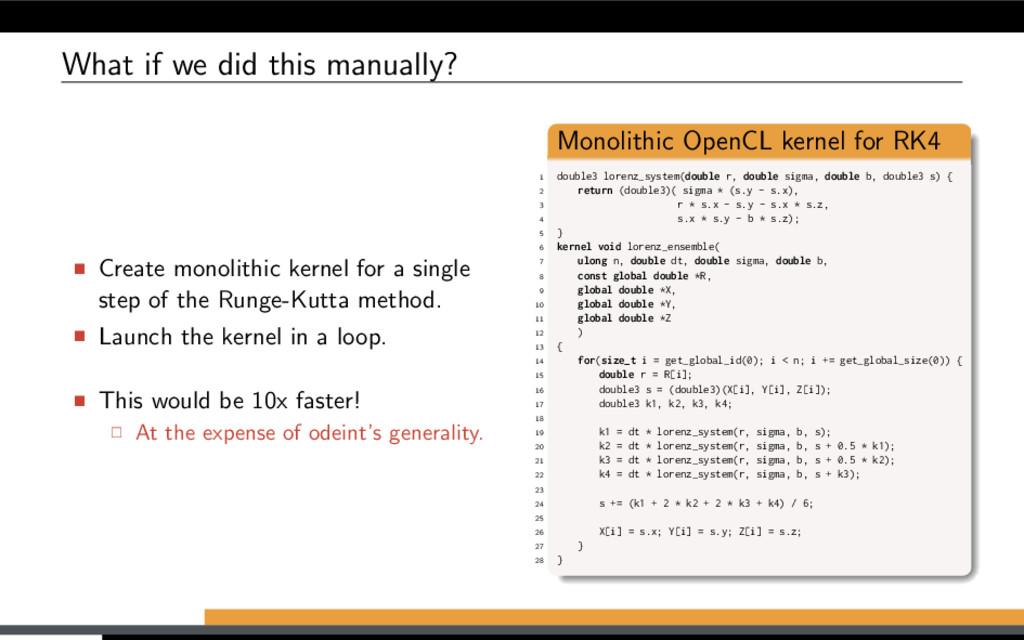
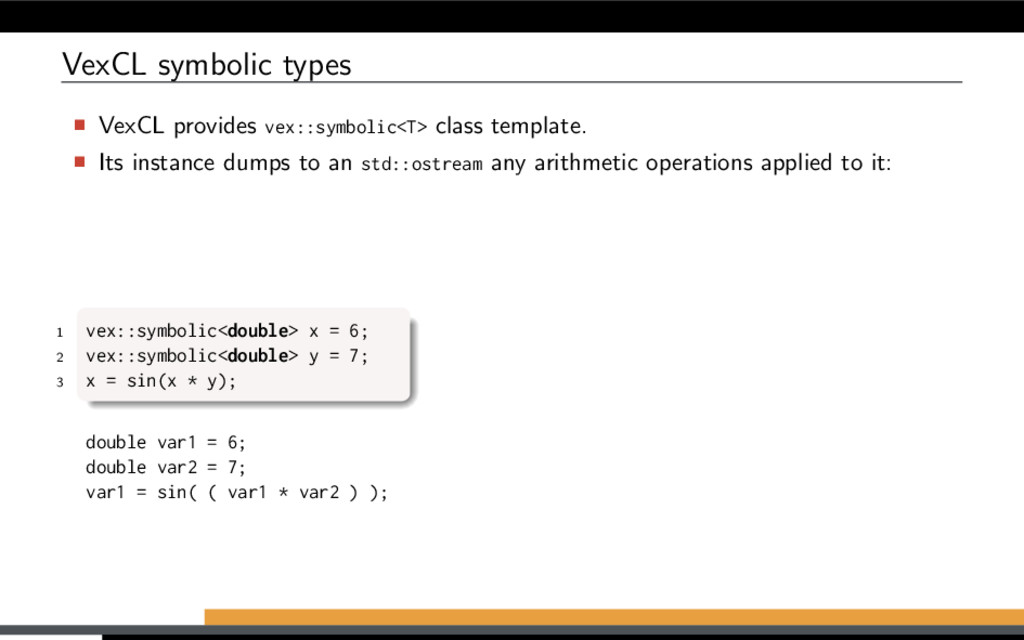
more details): Use vex::symbolic<T> or boost::array<vex::symbolic<T>, N> as state type. Provide generic system functor. Record single step of a Boost.odeint stepper. Generate and use monolithic kernel. [1] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9 7
more details): Use vex::symbolic<T> or boost::array<vex::symbolic<T>, N> as state type. Provide generic system functor. Record single step of a Boost.odeint stepper. Generate and use monolithic kernel. Restrictions: Algorithms have to be embarrassingly parallel. Only linear flow is allowed (no conditionals or data-dependent loops). [1] K. Ahnert, D. Demidov, and M. Mulansky. Solving ordinary differential equations on GPUs. In Numerical Computations with GPUs (pp. 125-157). Springer, 2014. doi:10.1007/978-3-319-06548-9 7
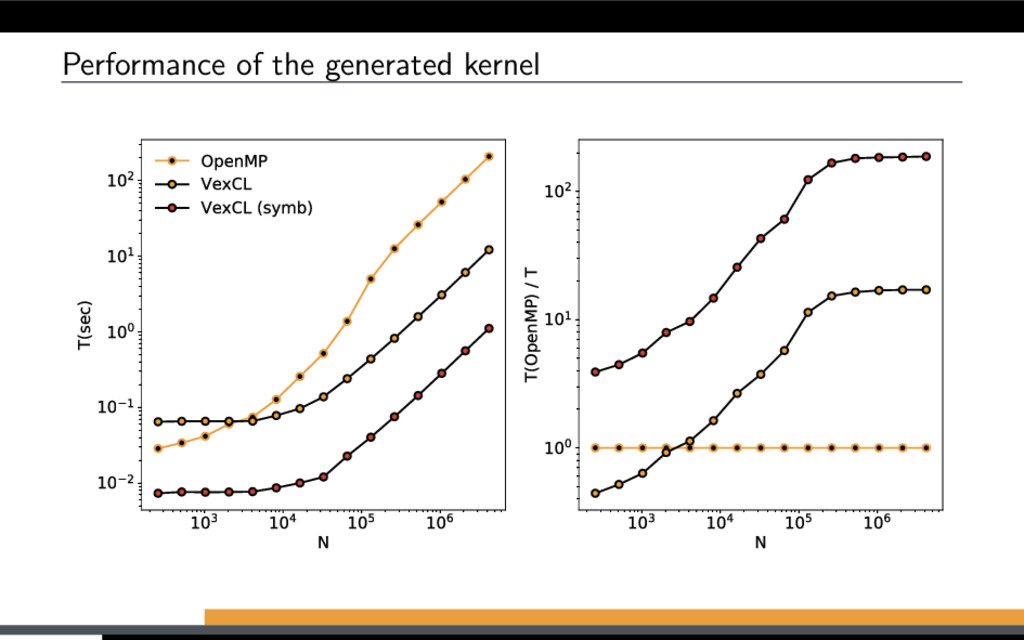
great for fast prototyping of scientific GPGPU applications. The performance is often on-par with manually written kernels. Using custom kernels or third-party functionality is still possible.
great for fast prototyping of scientific GPGPU applications. The performance is often on-par with manually written kernels. Using custom kernels or third-party functionality is still possible. It stresses the compiler greatly. Compilation takes a lot of RAM and a lot of time. But, it’s easy to combine C++ with Python: http://pybind11.readthedocs.io https://xkcd.com/303/
Algebraic Multigrid implementation: https://github.com/ddemidov/amgcl Boost.odeint — numerical solution of Ordinary Differential Equations: https://github.com/boostorg/odeint Antioch — A New Templated Implementation Of Chemistry for Hydrodynamics (The University of Texas at Austin): https://github.com/libantioch/antioch FDBB — Fluid Dynamics Building Blocks (TU Delft): https://gitlab.com/mmoelle1/FDBB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Generate monolithic kernel using Boost.odeint algorithm Overview (see [1] for](https://files.speakerdeck.com/presentations/761b93a33e334e75a58d9fc6d6f73fa4/slide_39.jpg){kind=link}
![Generate monolithic kernel using Boost.odeint algorithm Overview (see [1] for](https://files.speakerdeck.com/presentations/761b93a33e334e75a58d9fc6d6f73fa4/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}