VexCL: Генерация ядер OpenCL/CUDA из выражений C++
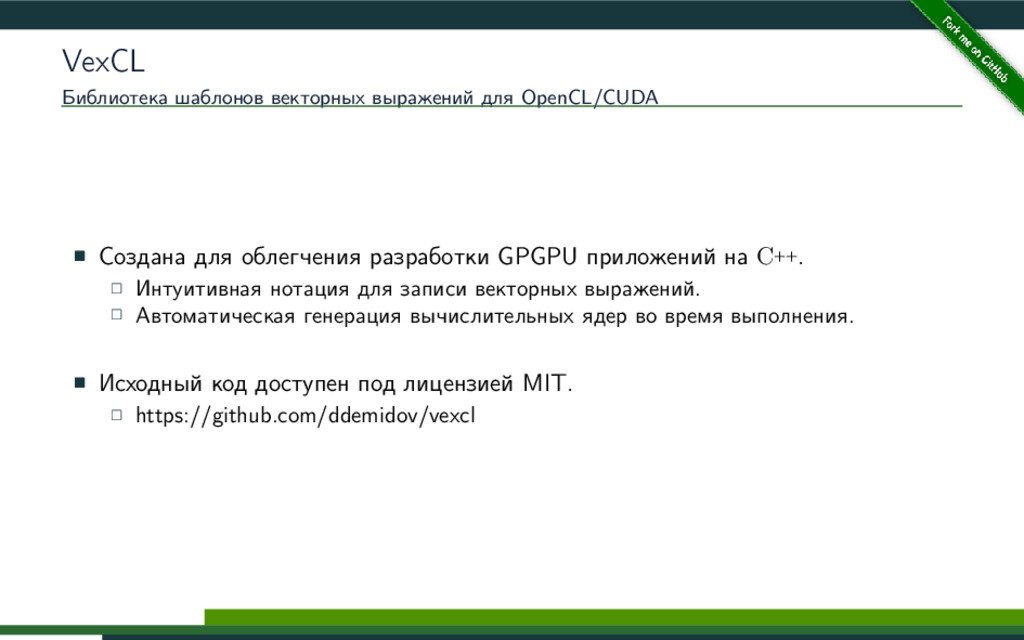
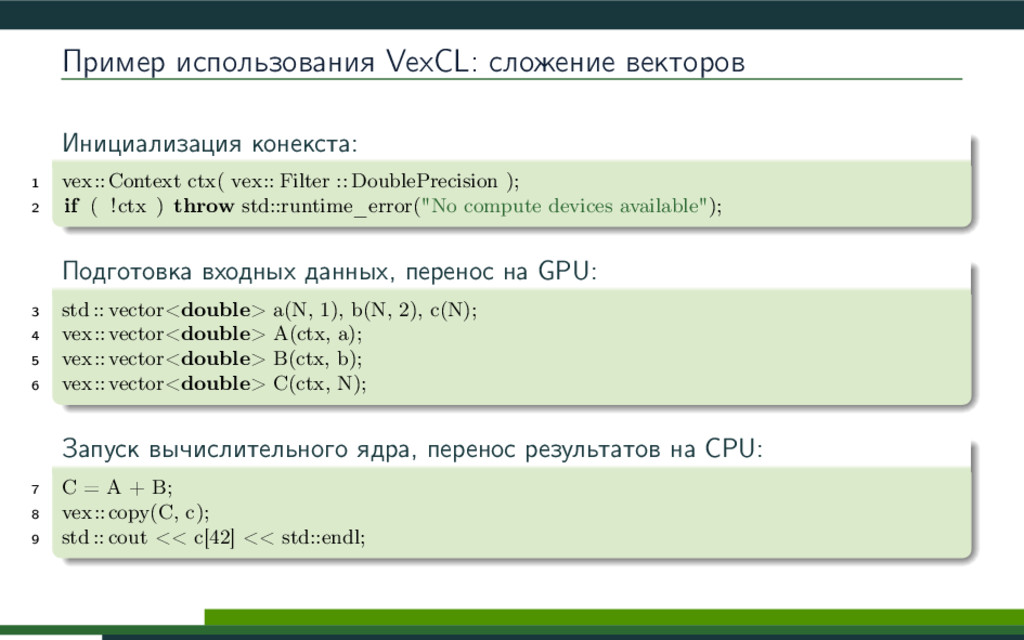
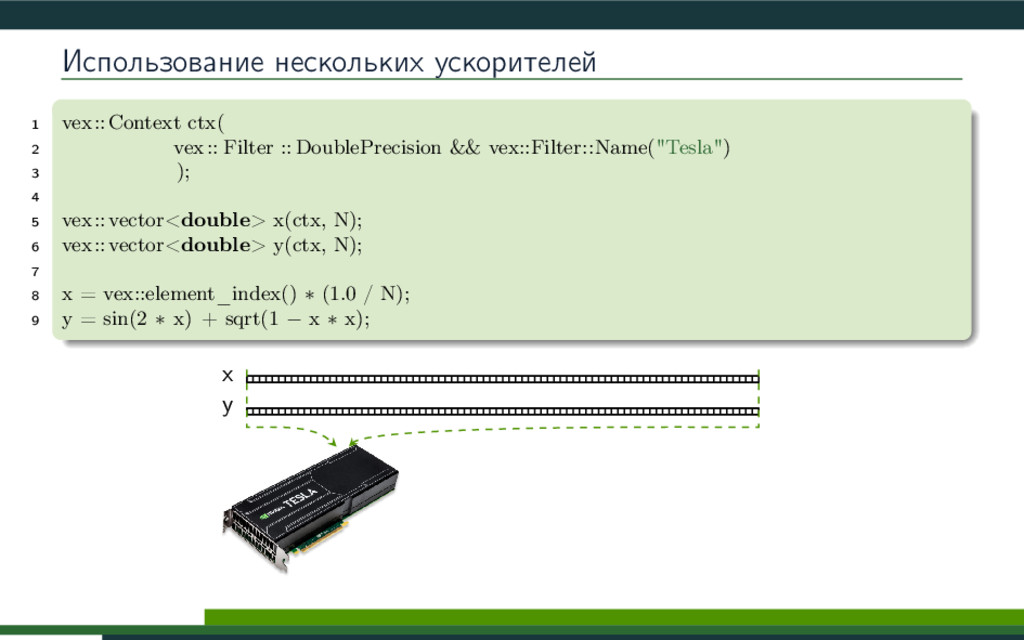
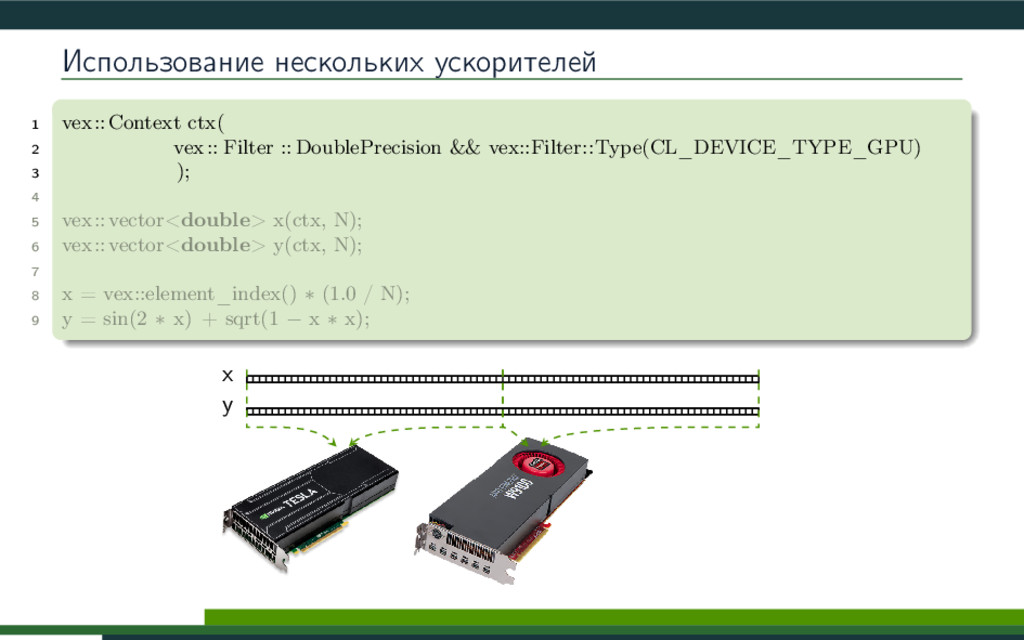
VexCL -- это библиотека с открытым исходным кодом (https://github.com/ddemidov/vexcl), разработанная в КазФ МСЦ РАН, и предназначенная для упрощения разработки C++ приложений, использующих технологии OpenCL/CUDA. Библиотека предоставляет удобную и интуитивную нотацию для записи векторных выражений, и позволяет использовать вычислительные мощности современных видеокарт и арифметических ускорителей. В данном докладе будет рассмотрена методика, применяющаяся в библиотеке VexCL для автоматической генерации эффективных вычислительных ядер OpenCL/CUDA.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
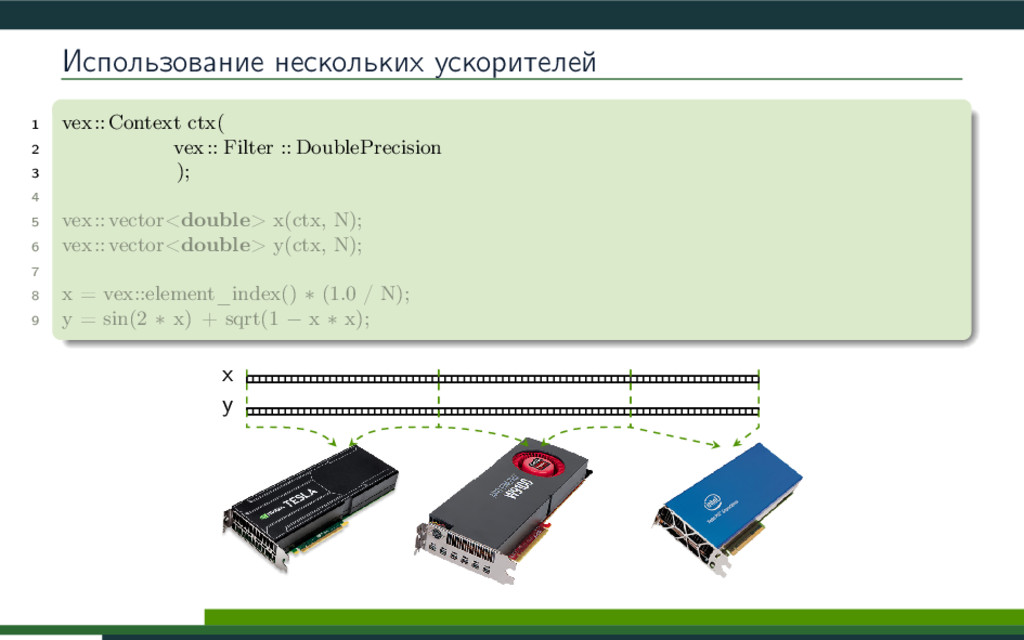{kind=link}
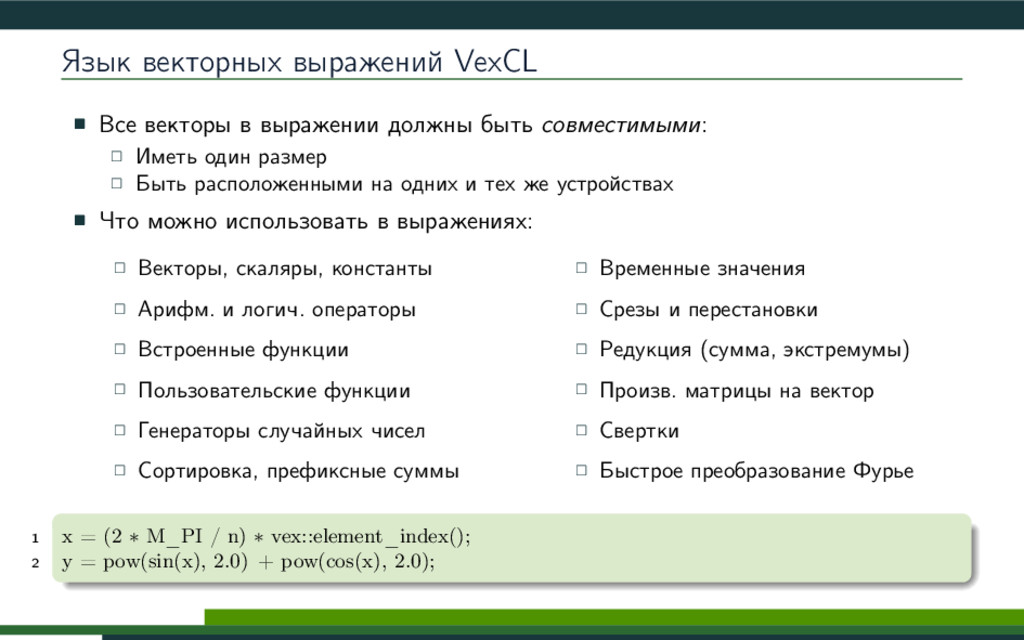{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
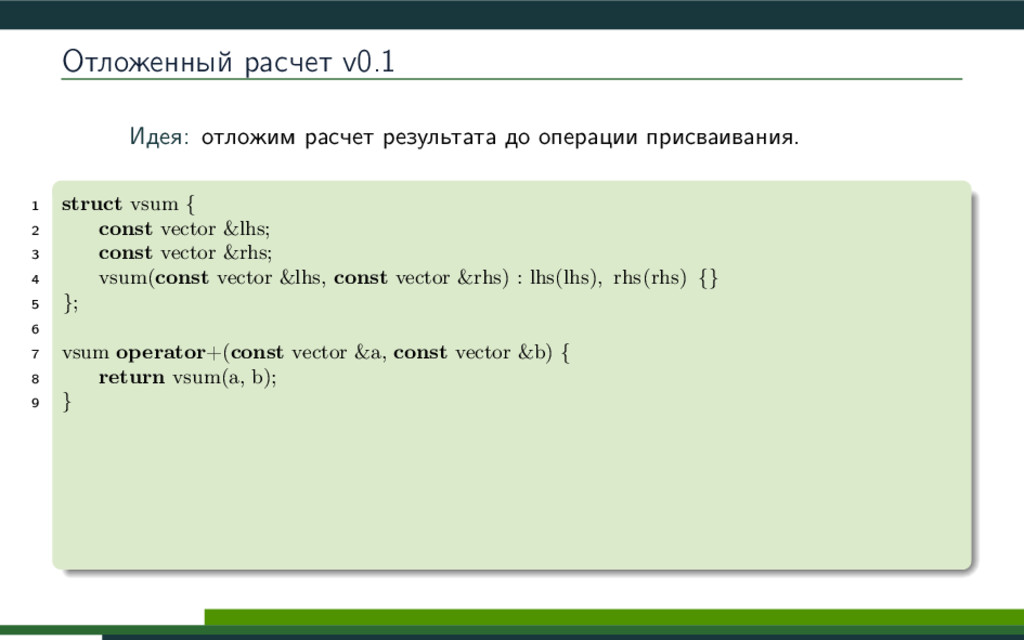{kind=link}
{kind=link}
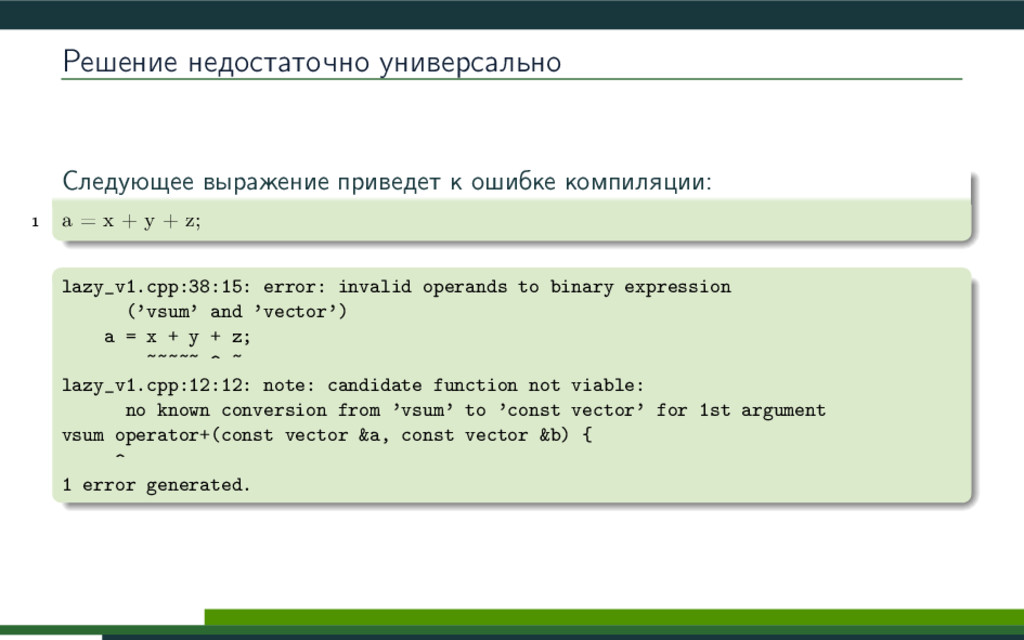{kind=link}
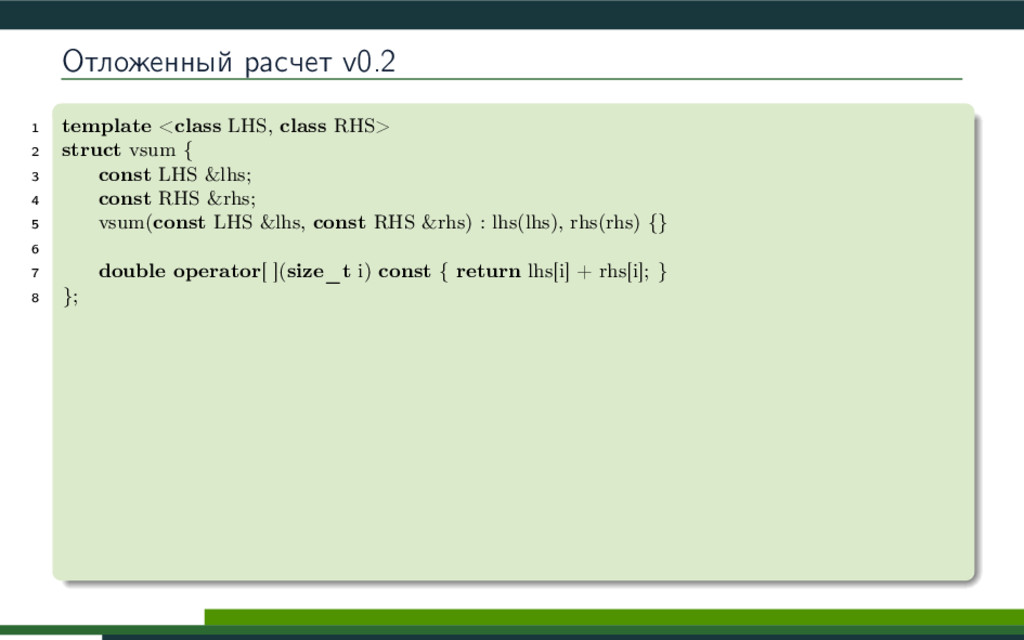{kind=link}
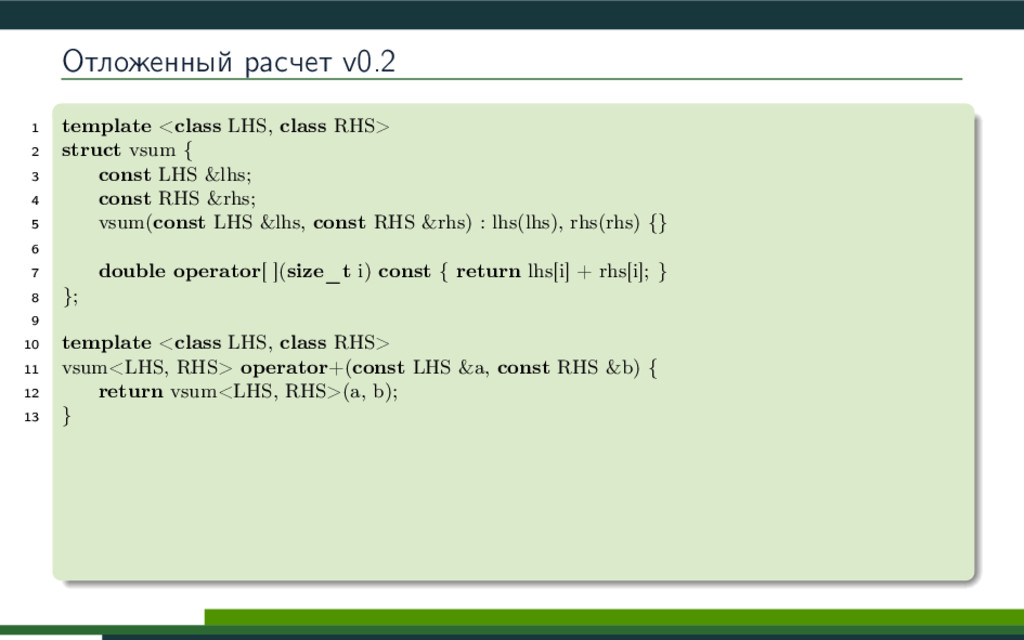{kind=link}
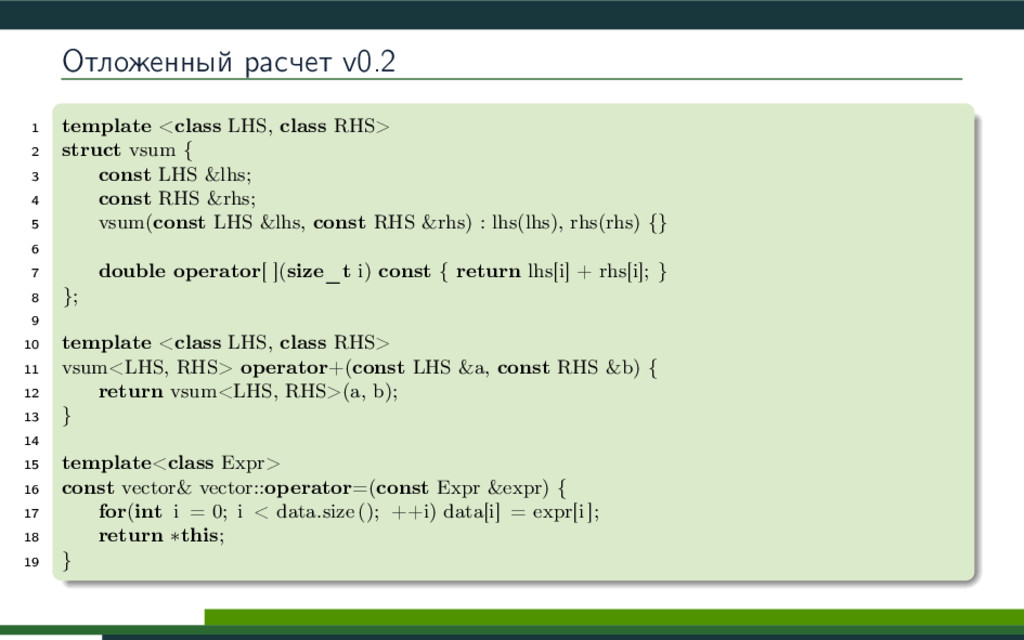{kind=link}
{kind=link}
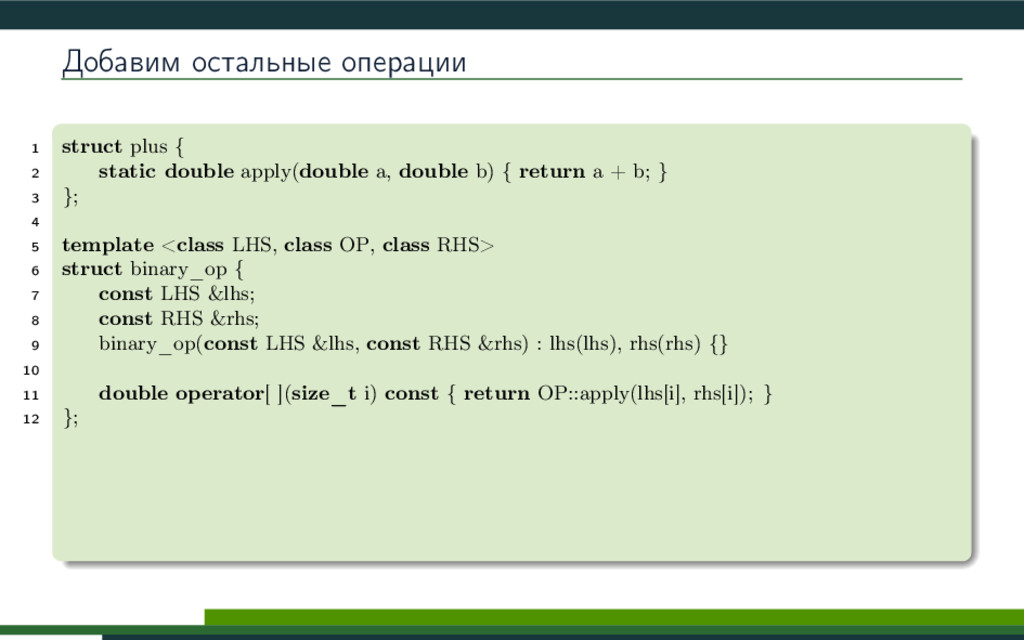{kind=link}
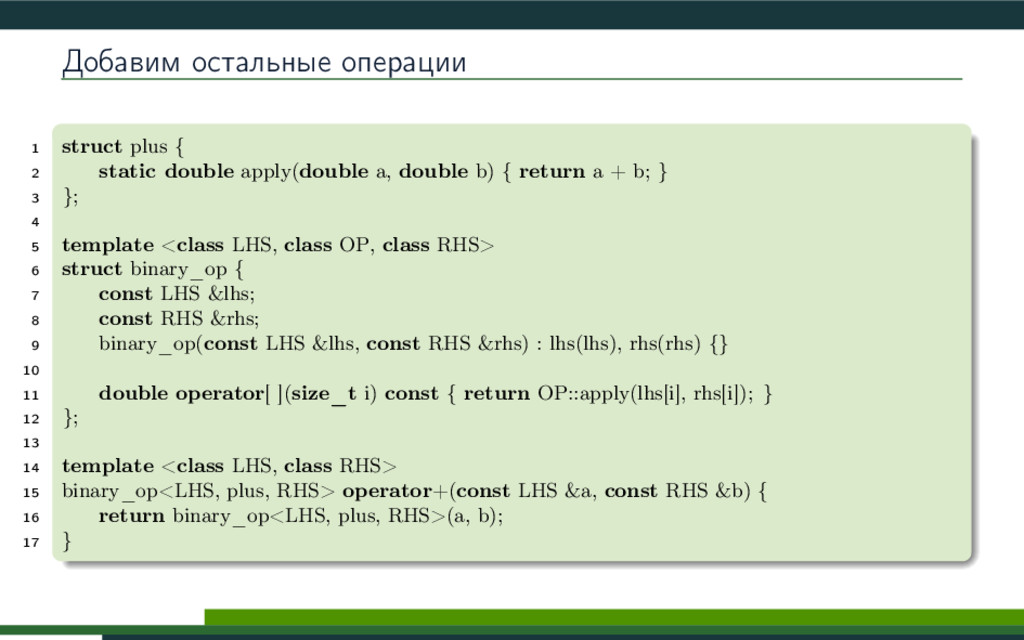{kind=link}
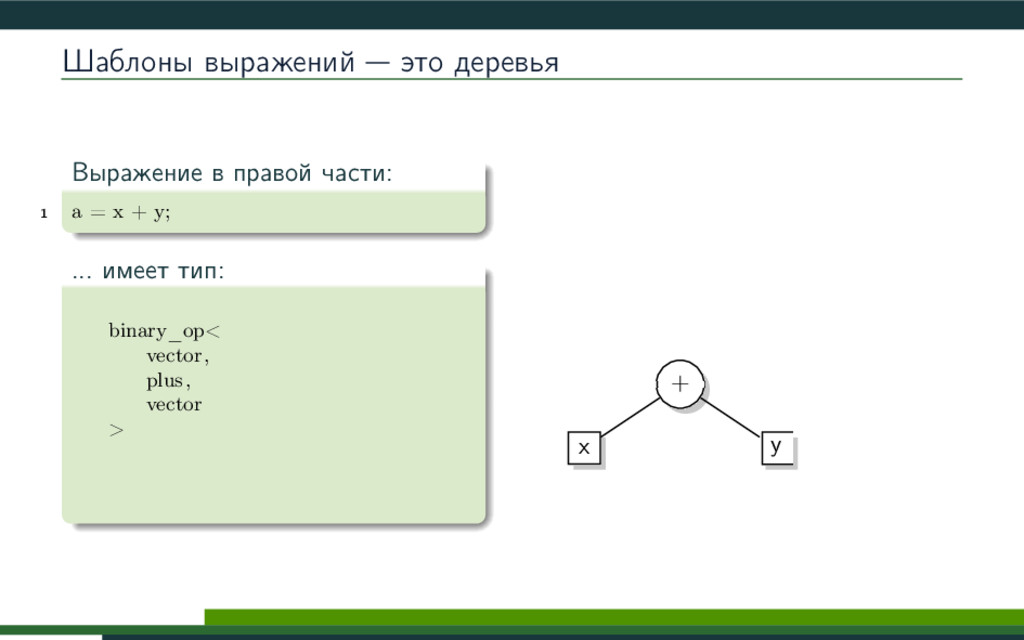{kind=link}
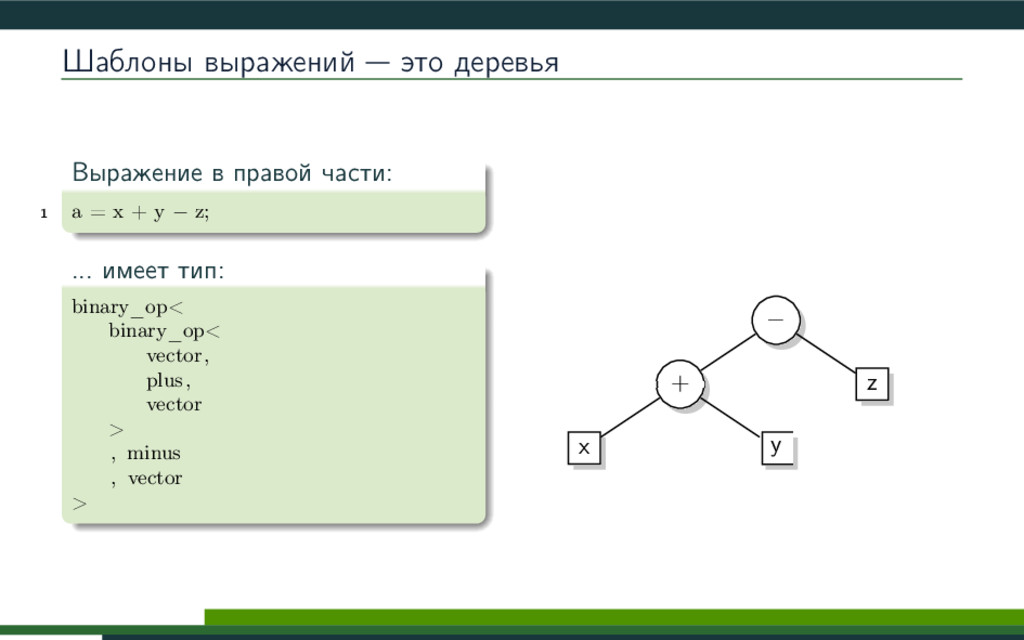{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
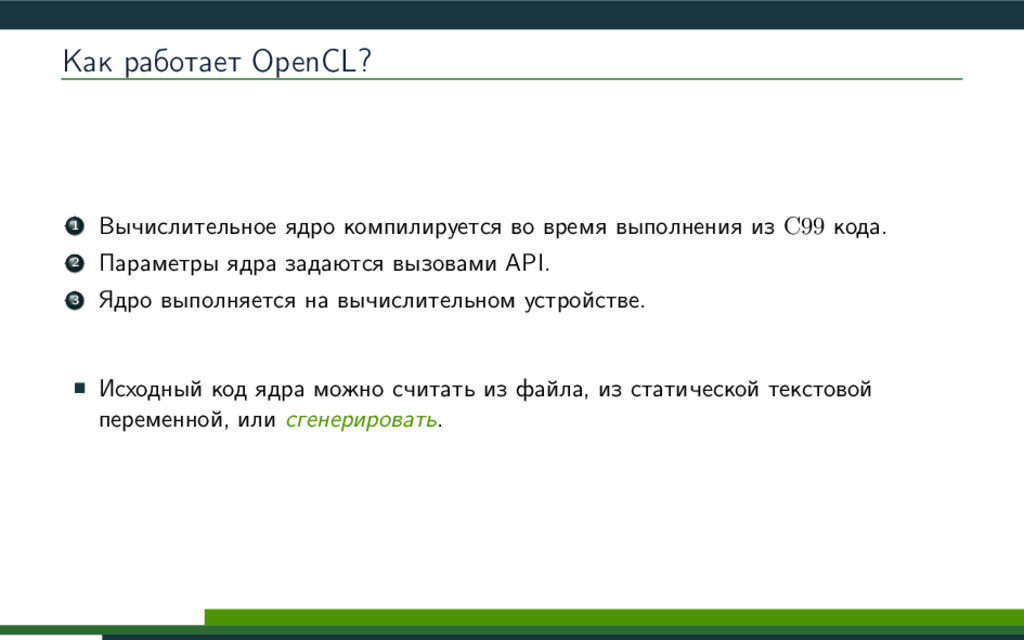{kind=link}
{kind=link}
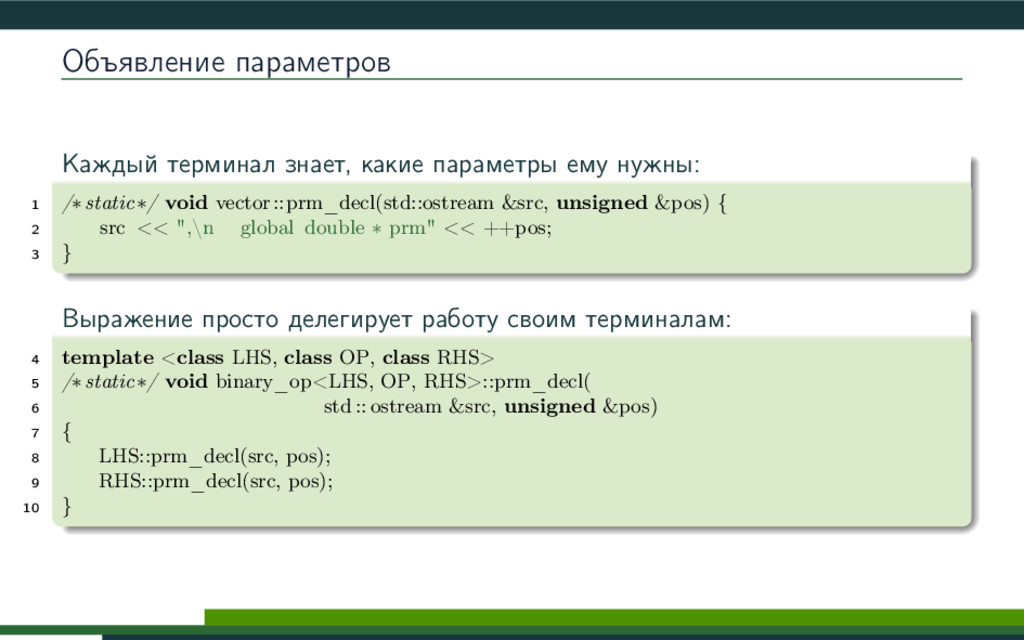{kind=link}
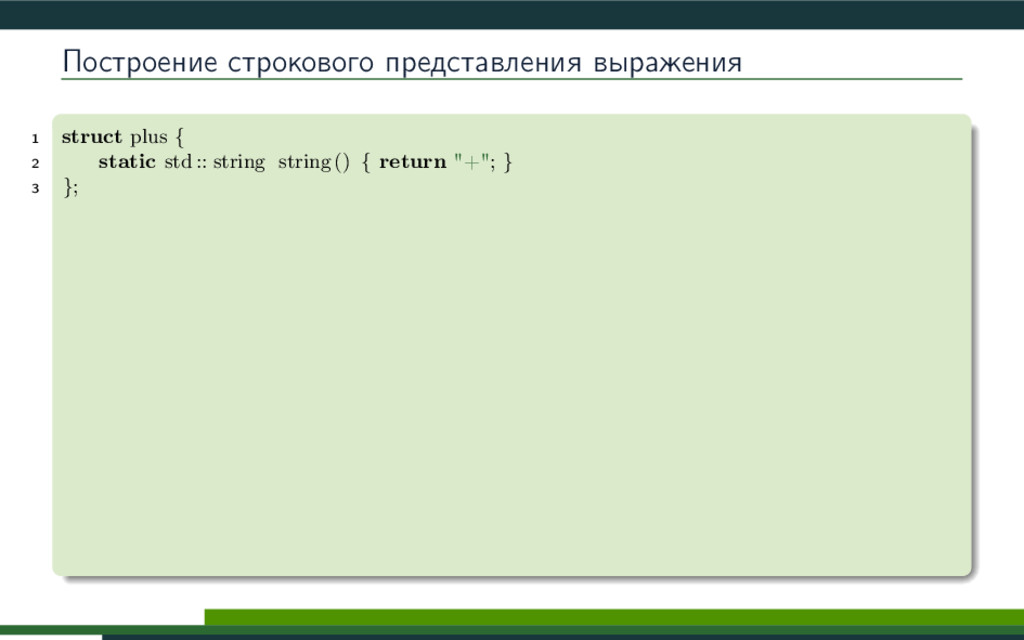{kind=link}
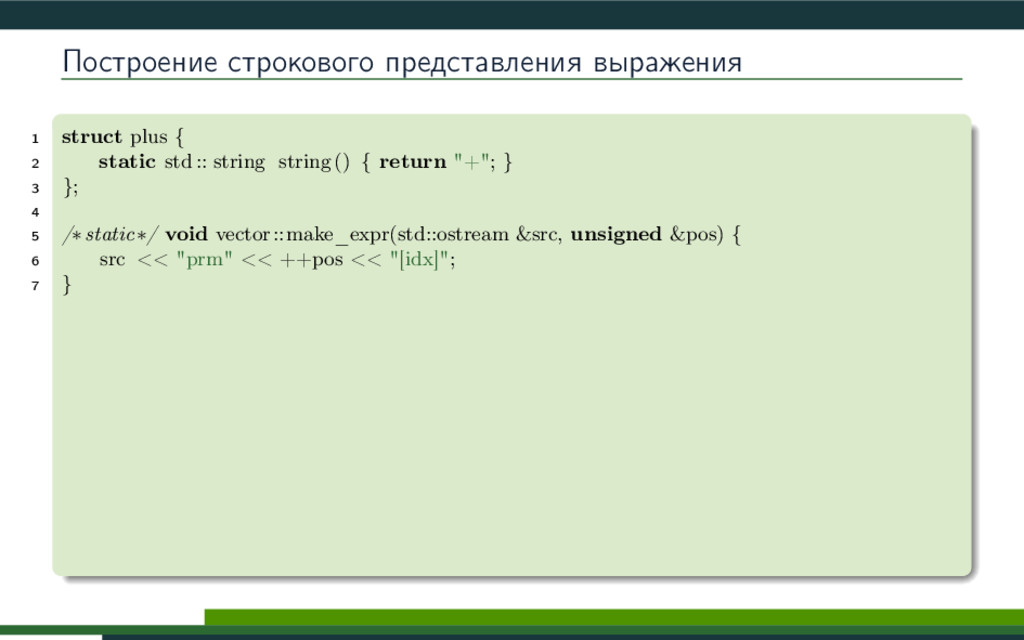{kind=link}
{kind=link}
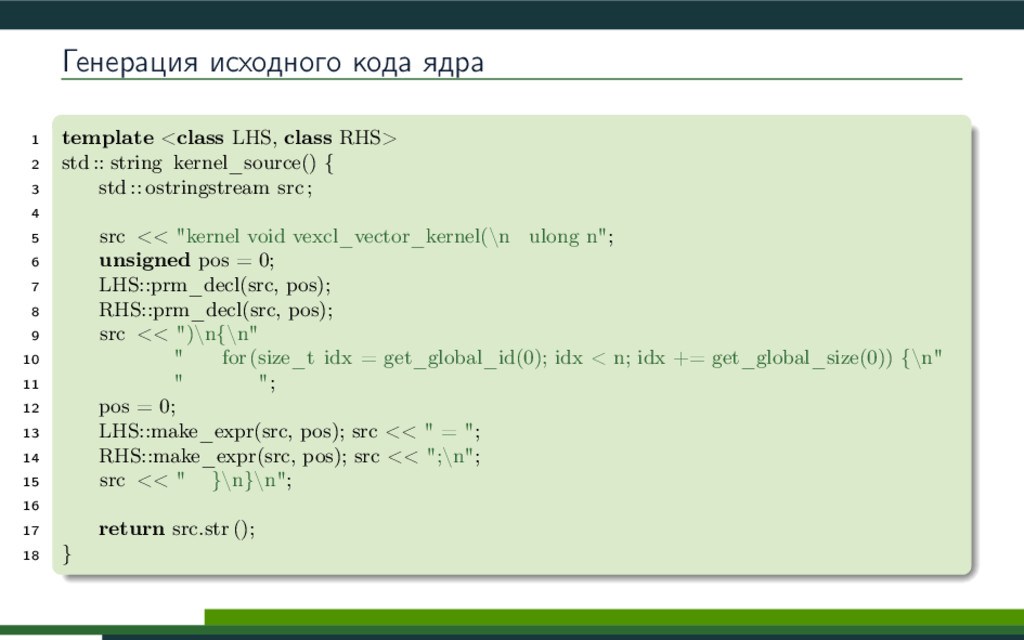{kind=link}
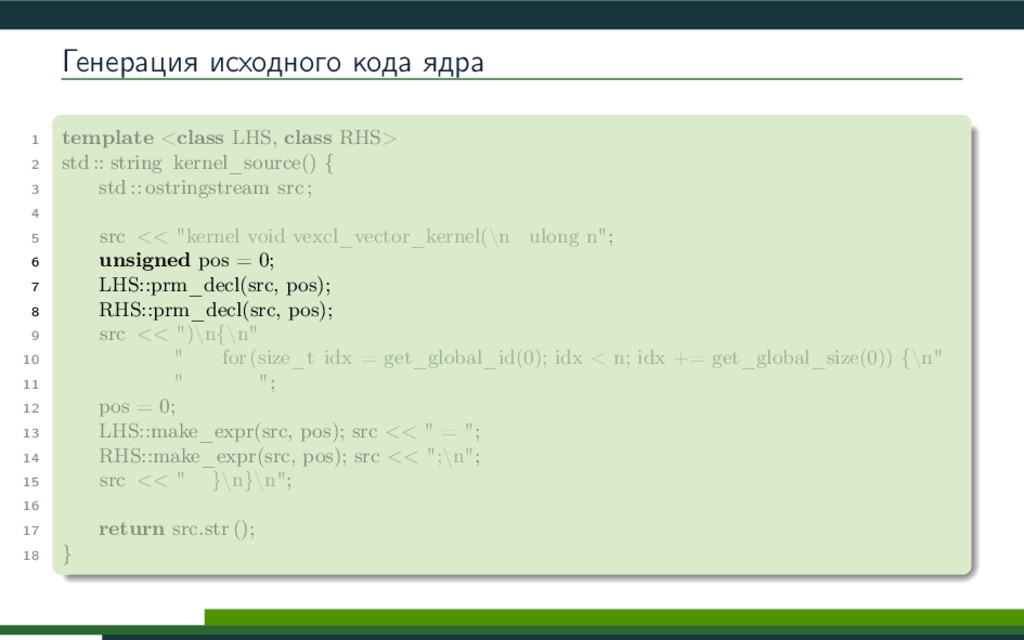{kind=link}
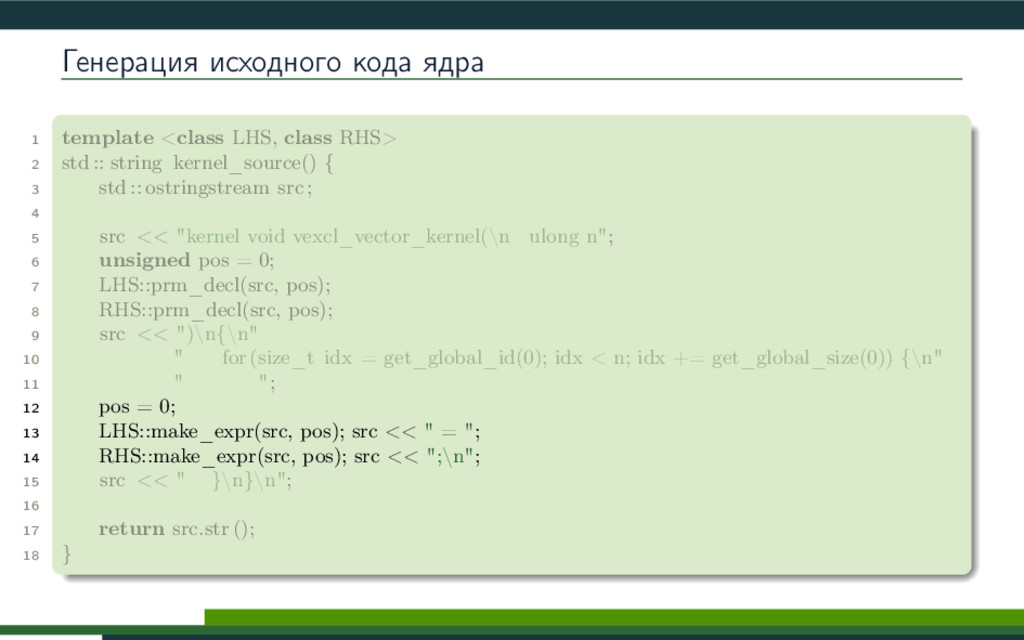{kind=link}
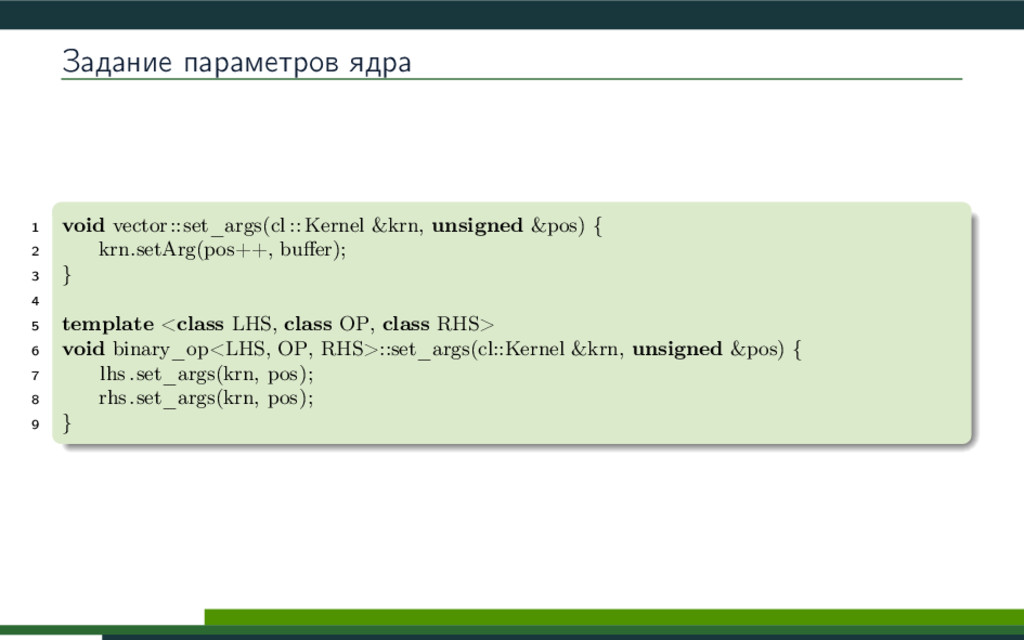{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
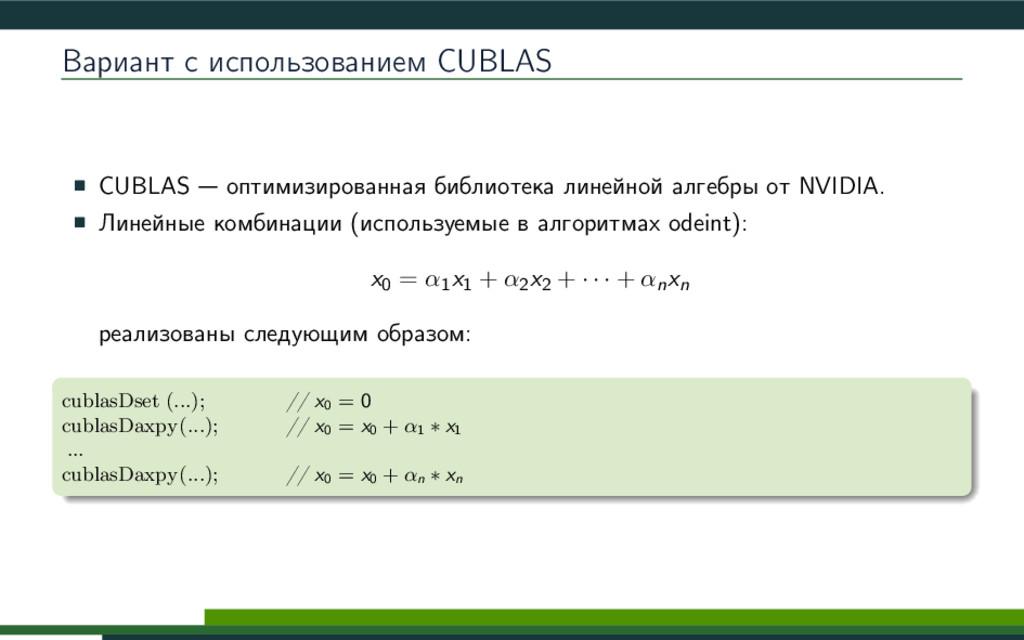{kind=link}
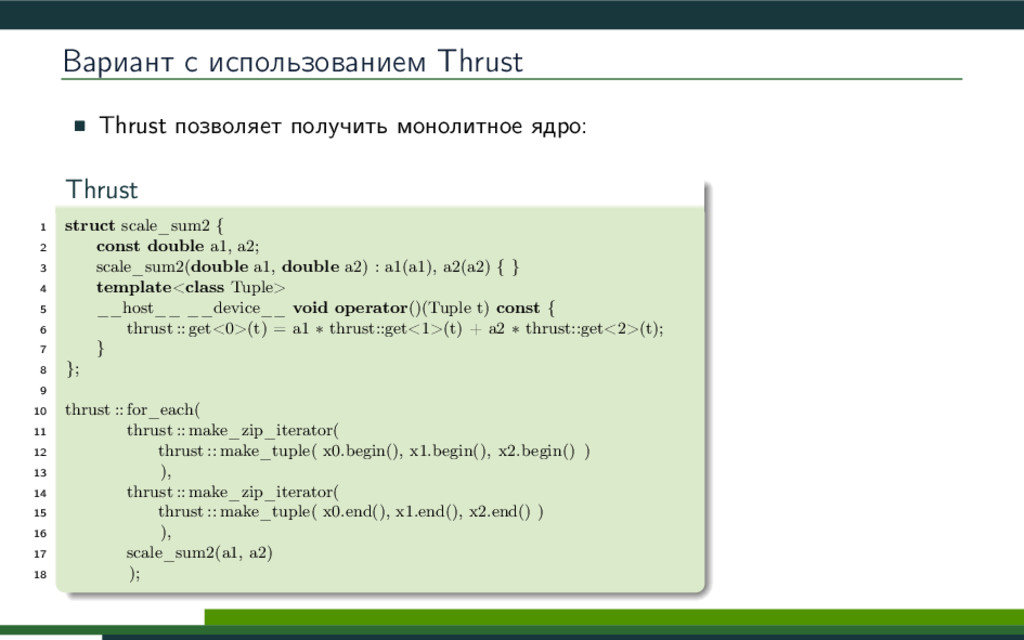{kind=link}
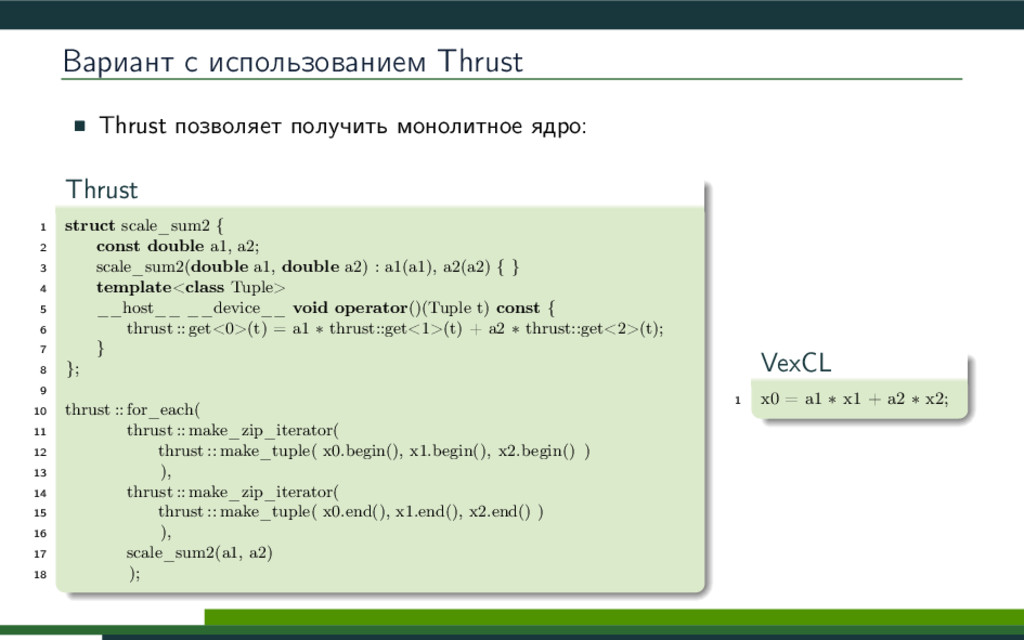{kind=link}
{kind=link}