Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
A Natural Language Pipeline
Search
ddqz
July 06, 2019
Technology
550
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
A Natural Language Pipeline
Presentation from the spaCy IRL 2019 conference.
ddqz
July 06, 2019
Other Decks in Technology
See All in Technology
CIで使うClaude
iwatatomoya
0
260
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.8k
DatabricksにおけるMCPソリューション
taka_aki
1
250
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.2k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
270
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
350
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
190
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
370
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
400
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
420
SRE Next 2026 何でも屋からの脱却
bto
0
740
Featured
See All Featured
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Raft: Consensus for Rubyists
vanstee
141
7.6k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Deep Space Network (abreviated)
tonyrice
0
220
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
The Spectacular Lies of Maps
axbom
PRO
1
860
The SEO identity crisis: Don't let AI make you average
varn
0
510
A designer walks into a library…
pauljervisheath
211
24k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Transcript
A Natural Language Pipeline
More Input
Knowledge” “A compendium of human...
Library
Physical archives became digital records, encoded with metadata
The internet promised rich dynamic experiences
The internet promised rich dynamic experiences but served us banner
ads
Advertising has and continues to fuel a substantial portion of
the innovation on the internet
What would The Economist look like if it were founded
in 2012?
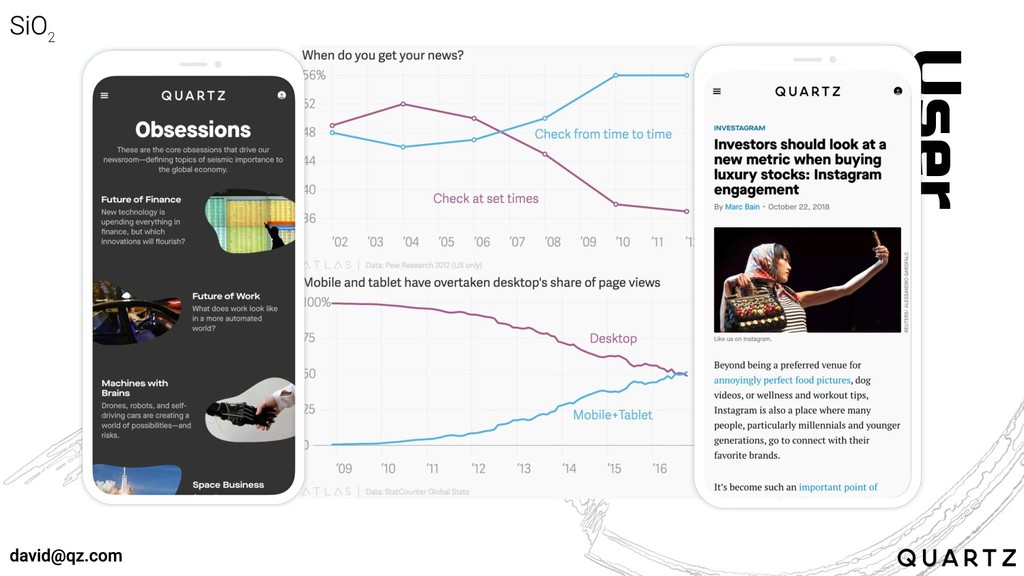
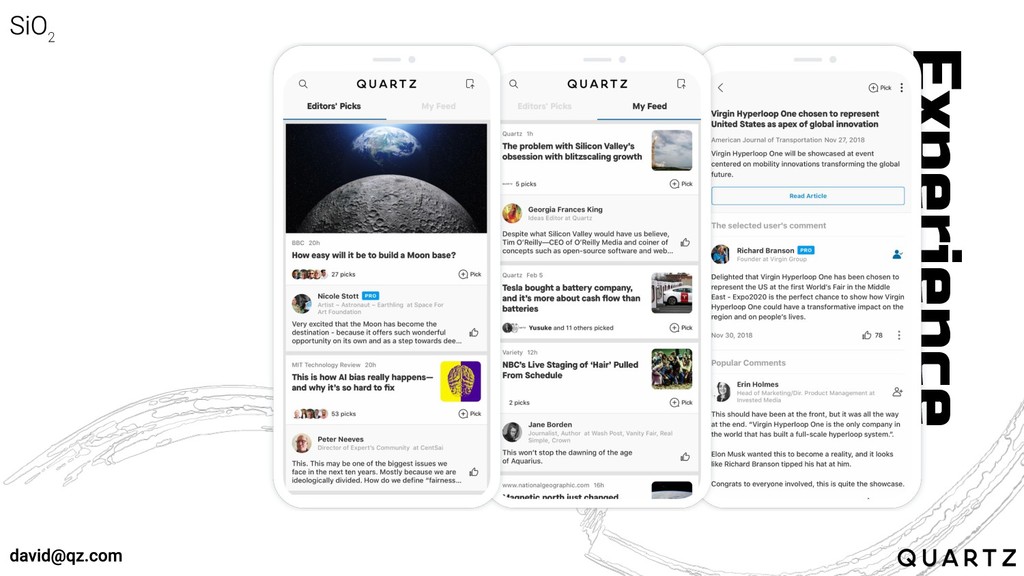
User
First
Experience
“There’s a reason that tech companies are topping the lists
of most valuable companies and brands. Every company is a tech company.” Maggie Chan Jones
Every story, at its core, is a business story
Language
None
None
Stage -> Stenographer -> Editors -> spaCy -> Data Store
<-> Backend <- Slack <- Users Proto-Pipeline
Over eight hours we created data from the content of
the event, building the model in real-time
The model evolved over time
This was the experiment that would evolve into SiO 2
Silicon, a key element in everything from glass to microchips,
is at the core of global business
Oxygen, the journalistic voice Quartz breathes into the global business
news cycle
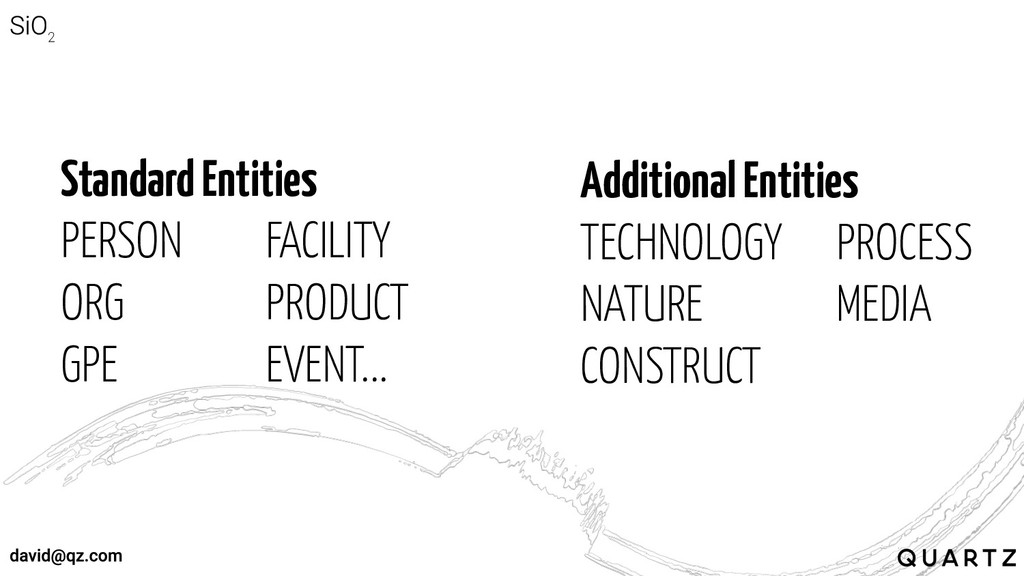
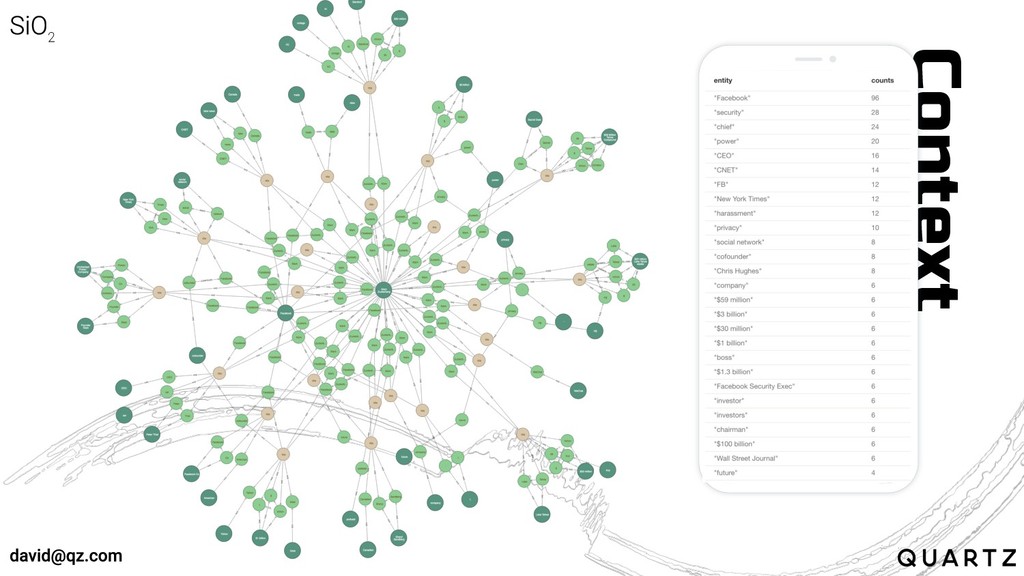
Entities are linguistic anchors, defined by context and around which
context can be inferred
Standard Entities PERSON FACILITY ORG PRODUCT GPE EVENT... Additional Entities
TECHNOLOGY PROCESS NATURE MEDIA CONSTRUCT
70K articles 1.4M blocks of text 85K labeled sentences
Entities
This spaCy model made rich analysis for any given text
easy to do on the fly
Stored analysis of a large corpus is a vital resource
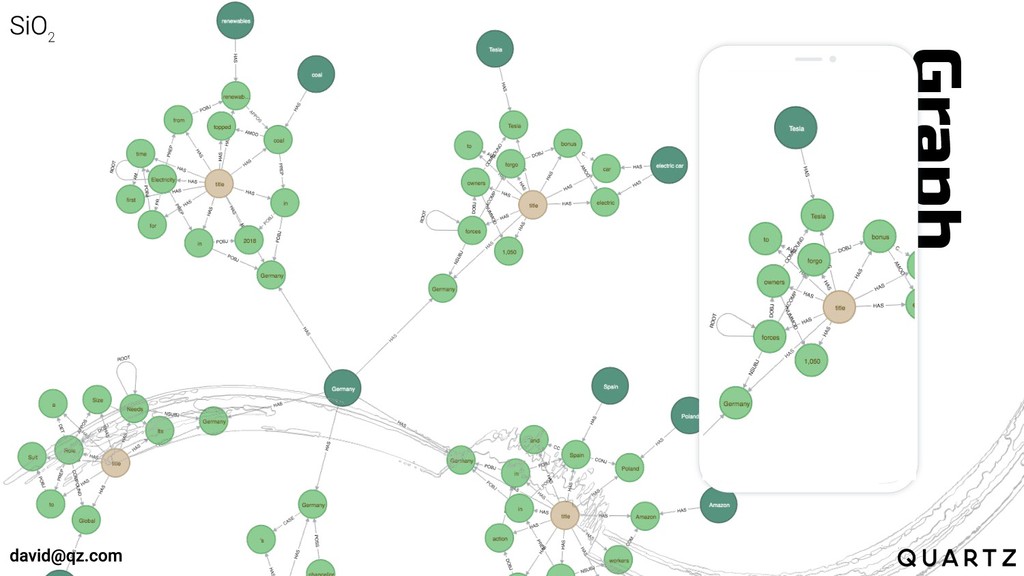
The language graph...
Graph
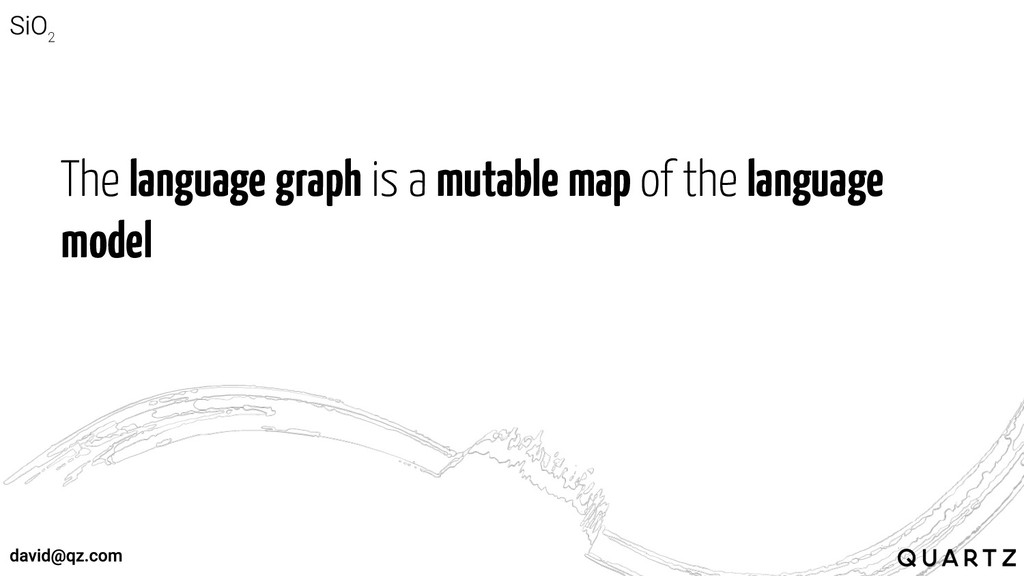
The language graph is a mutable map of the language
model
Any new content is analyzed and then mapped onto the
language graph
Changes made to the graph can then be incorporated into
the next model iteration
The language graph becomes a primary resource for extracting training
data
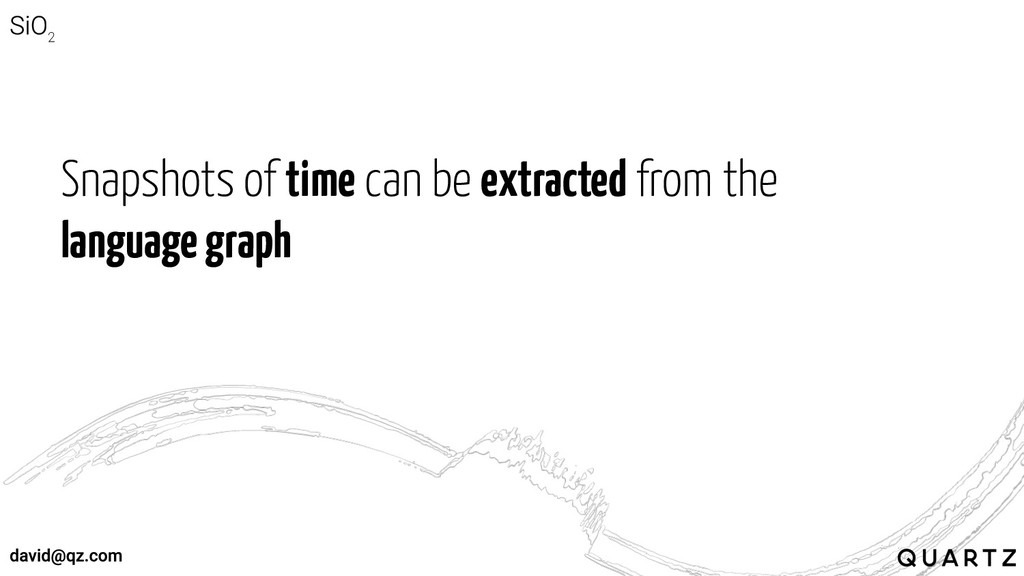
Snapshots of time can be extracted from the language graph
Context can be derived by looking at the relationships in
the language graph
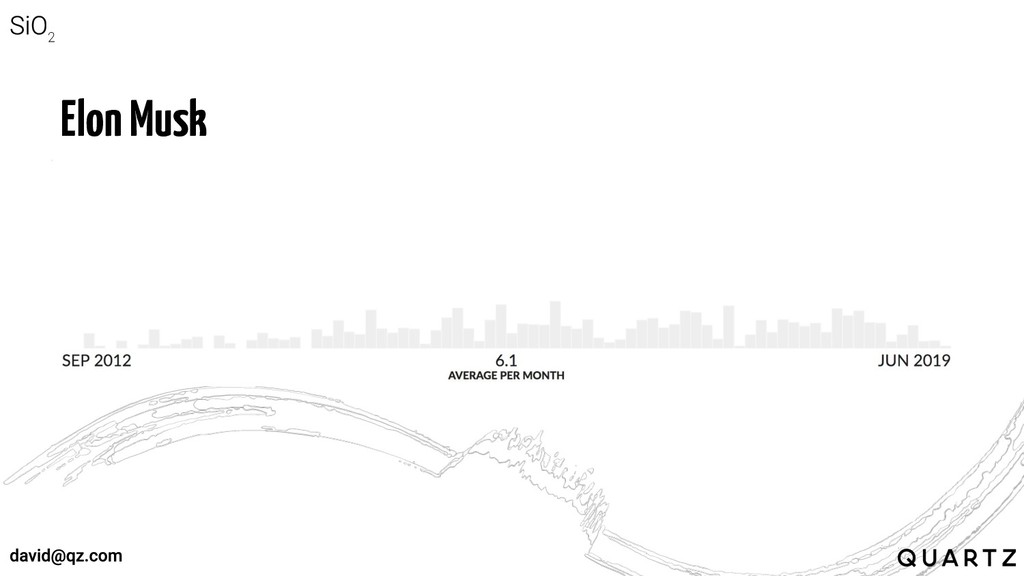
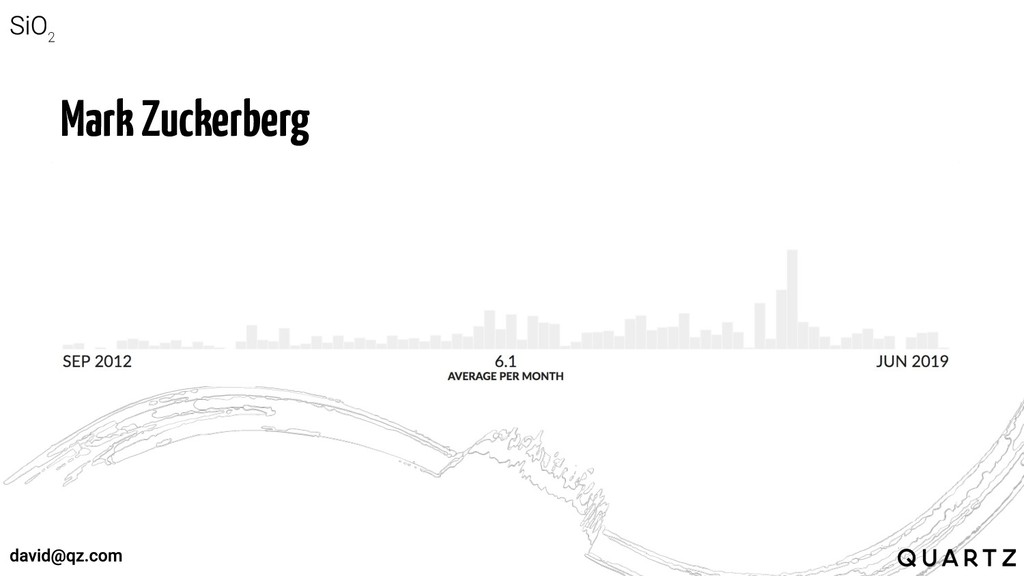
Elon Musk
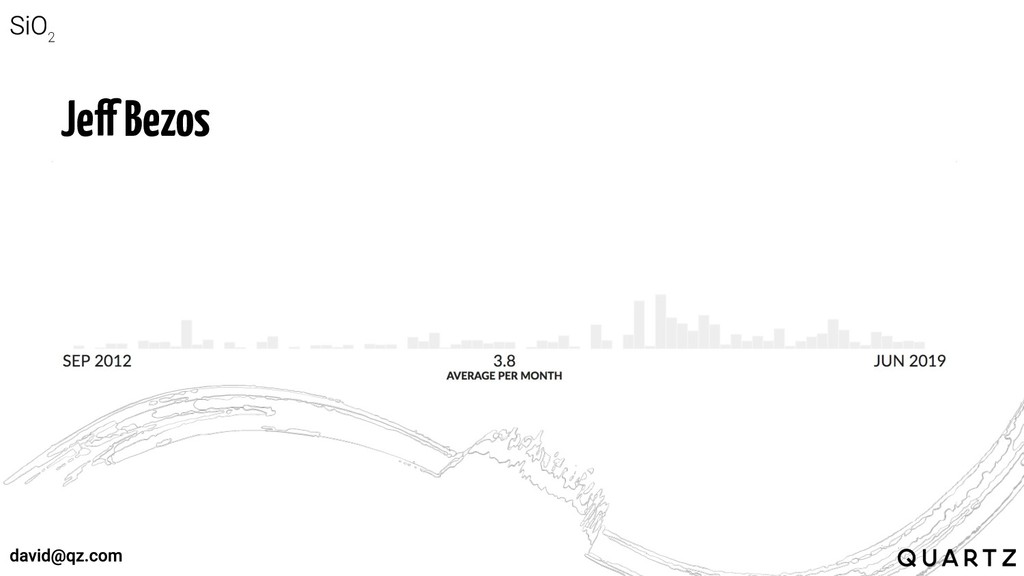
Jeff Bezos
Mark Zuckerberg
Context
SiO 2 is a living Natural Language Pipeline of networked
algorithms trained on the corpus of Quartz to understand the linguistic patterns of global business news
The Pipeline(s) Quartz Corpus -> Training Sentences -> spaCy Content
-> spaCy -> Language Graph Language Graph -> Training Data -> Statistical Models / Classifiers Language Graph -> Training Sentences -> spaCy Unseen Content -> spaCy -> Pre-Processed Text / Vectors -> Statistical Models / Classifiers
Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}