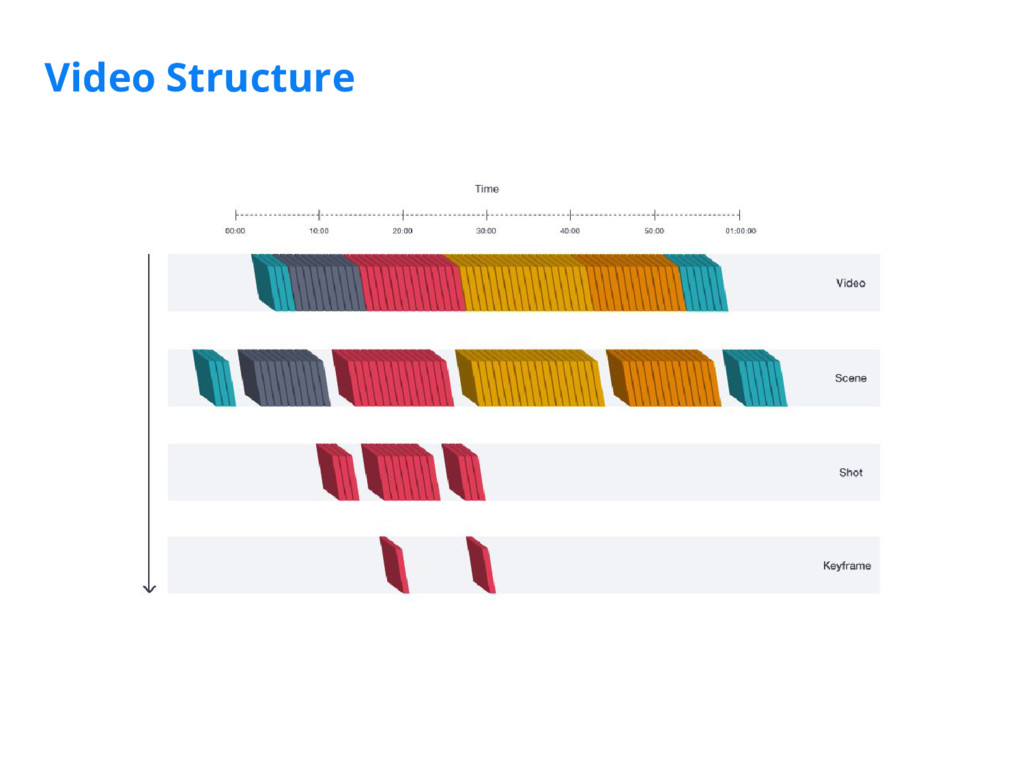
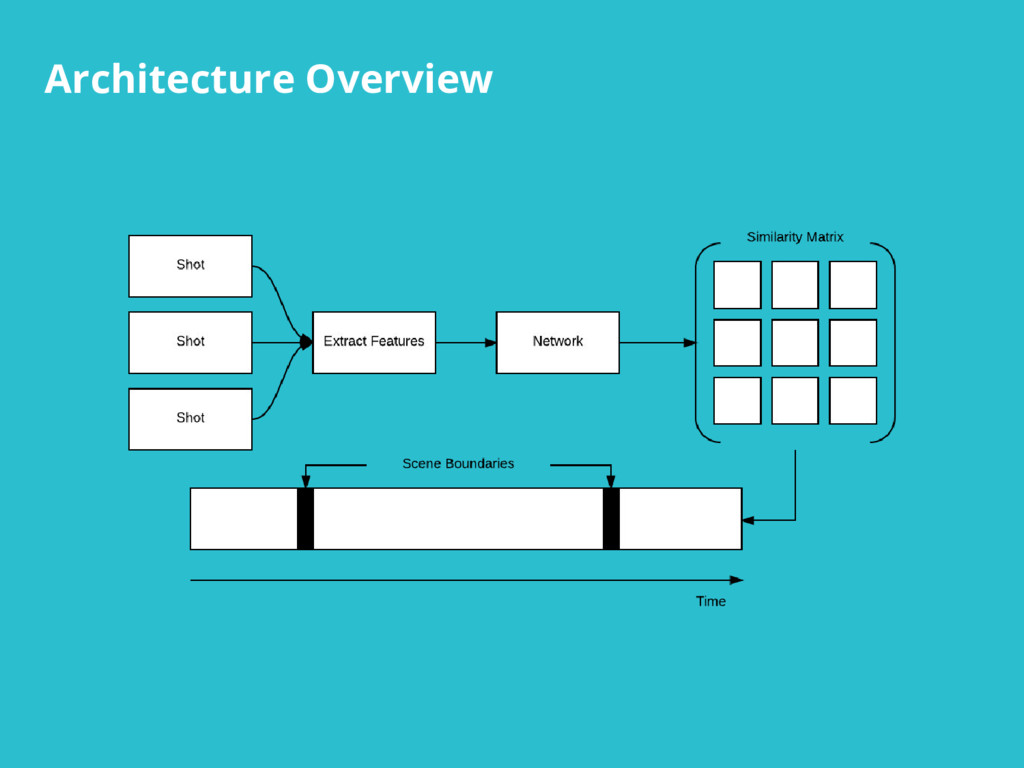
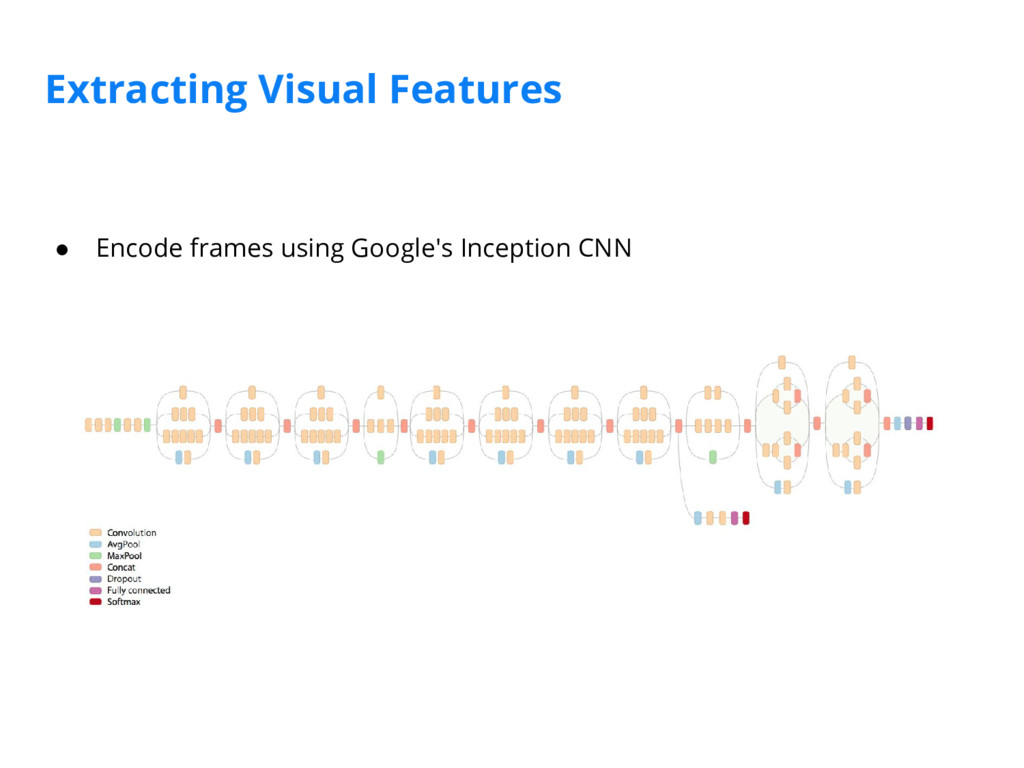
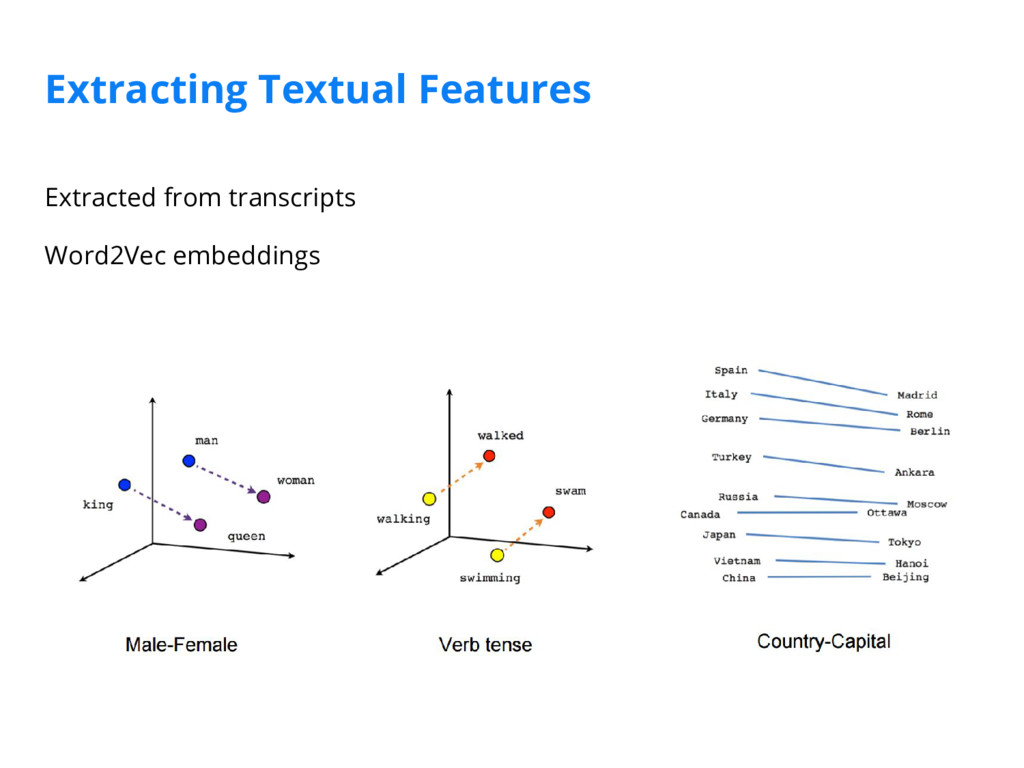
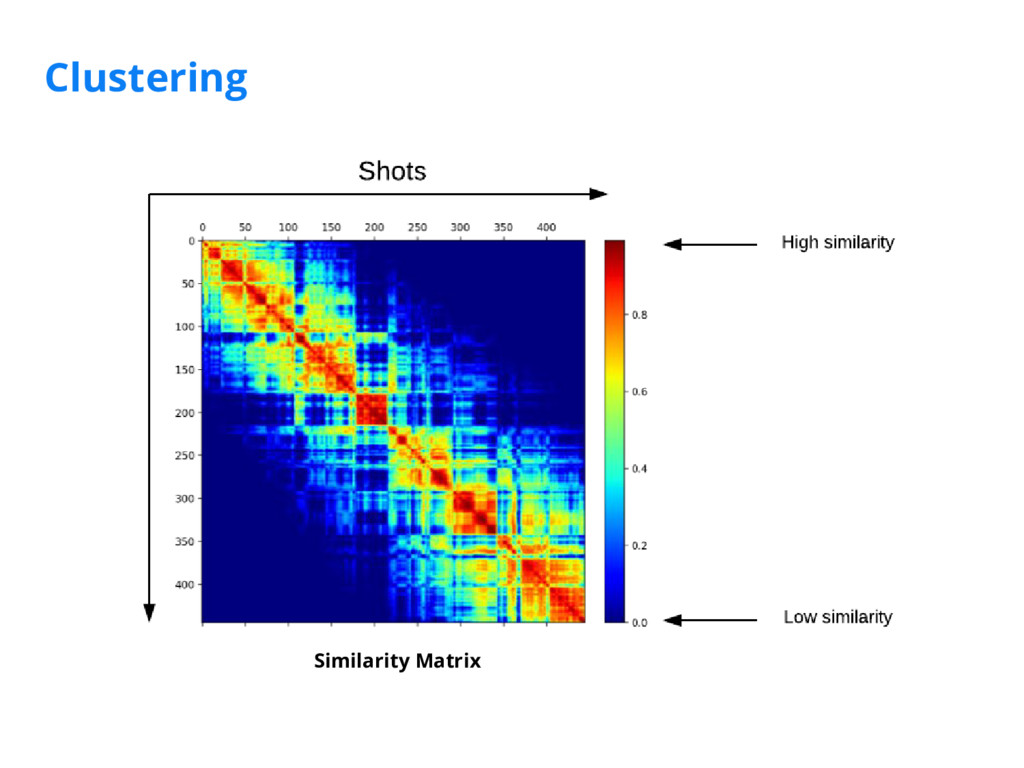
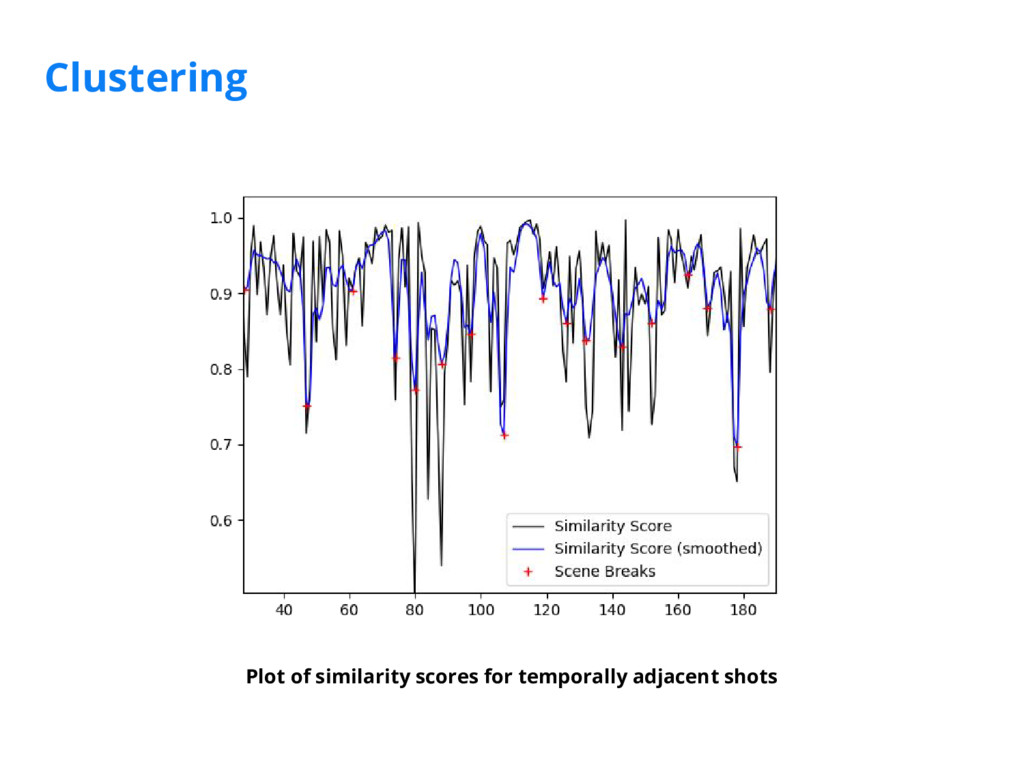
We've implemented a scene detection framework that segments videos into logical story units without the need for a human editor. We achieve this in two steps: 1) we train a deep-learning model to learn a distance measure (i.e. similarity measure) between all pairs of shots by leveraging visual, audio, and textual features extracted from the video; 2) we then cluster contiguous groups of shots into scenes based on the full similarity matrix of shots.
Presented by Rik Heijdens at Demuxed 2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}