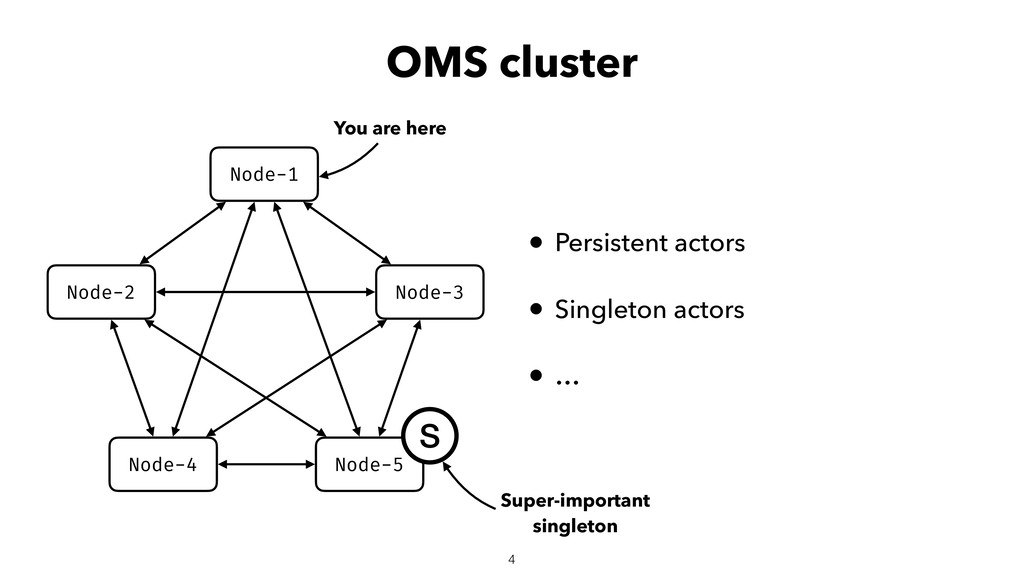
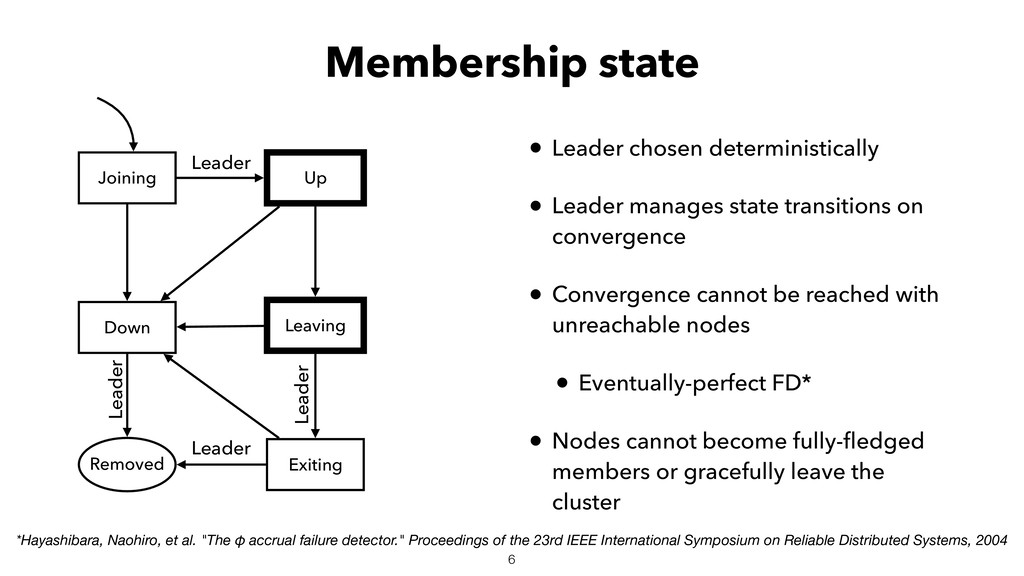
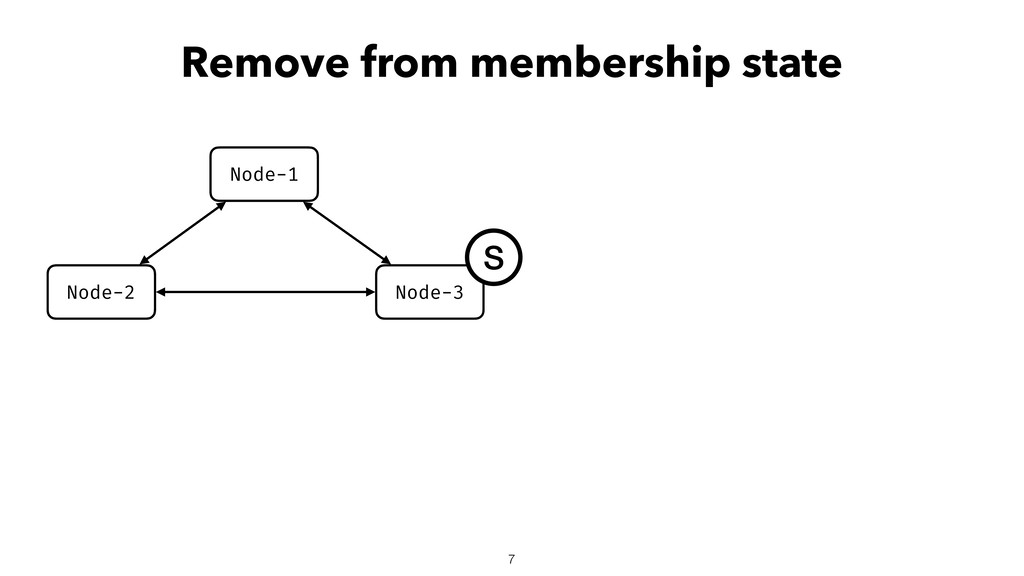
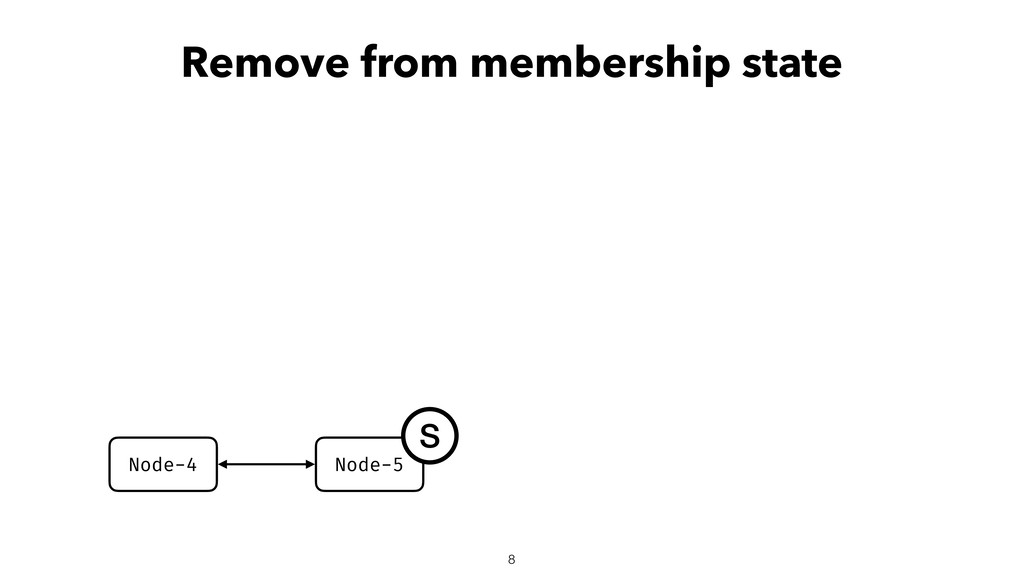
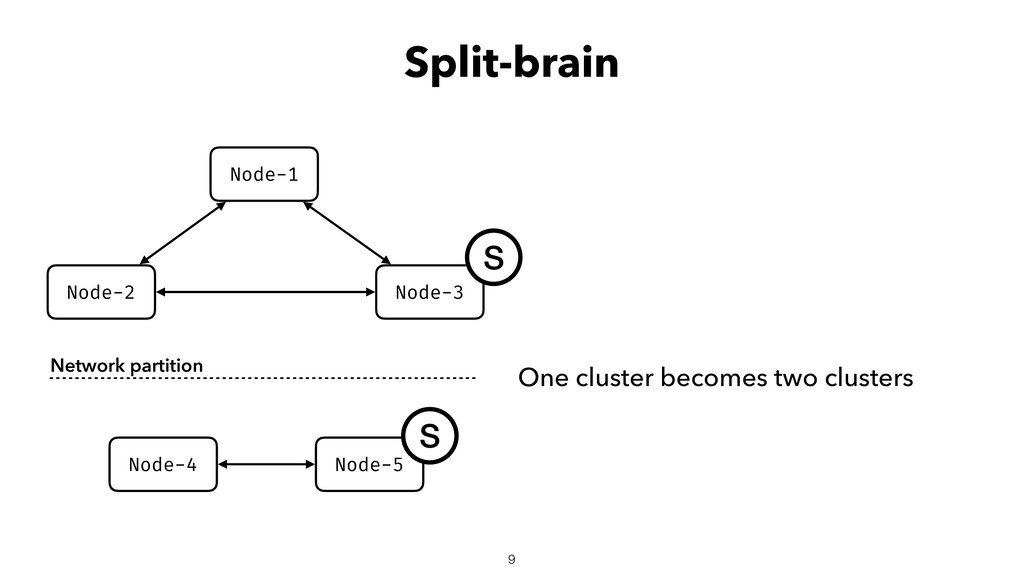
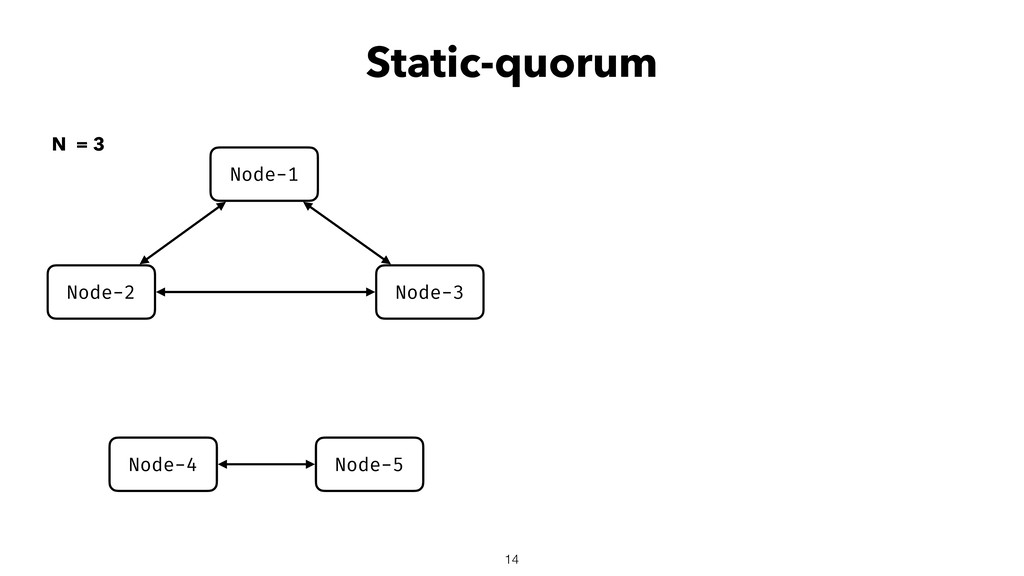
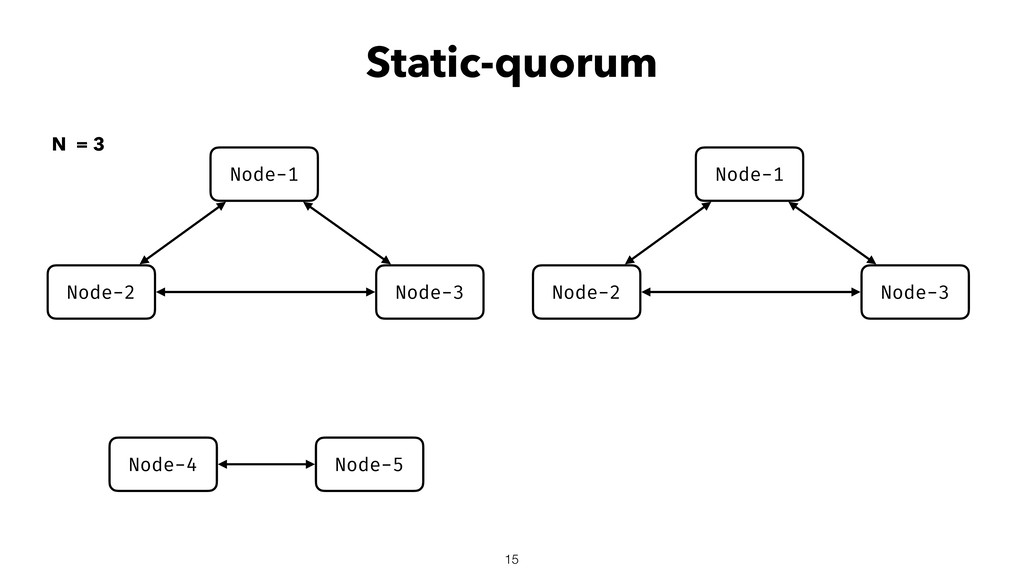
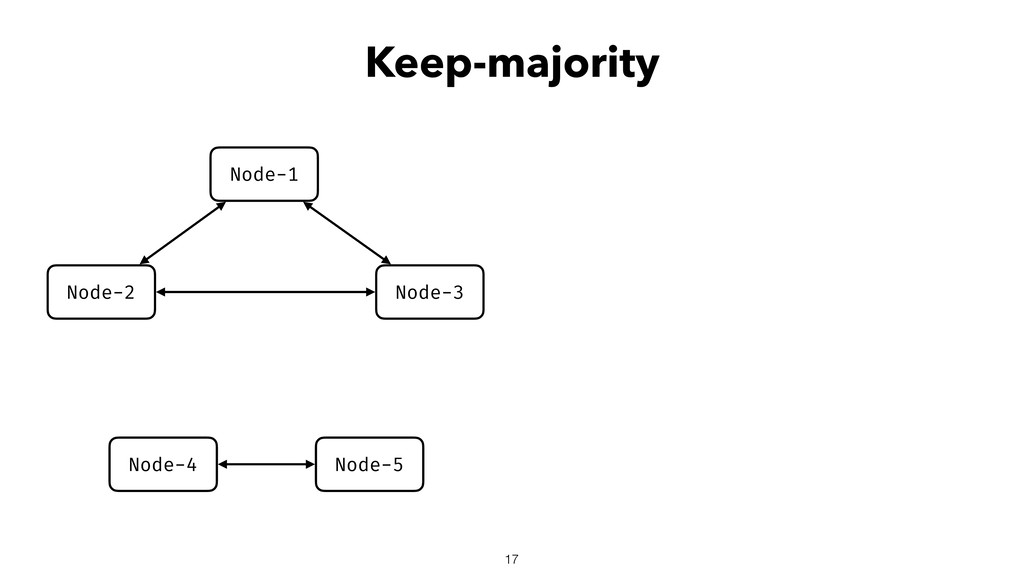
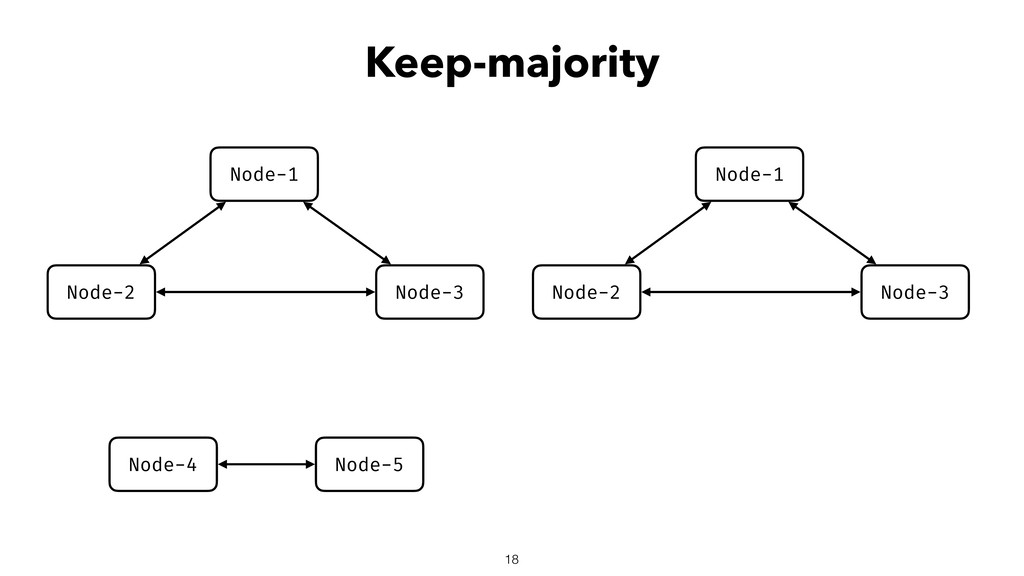
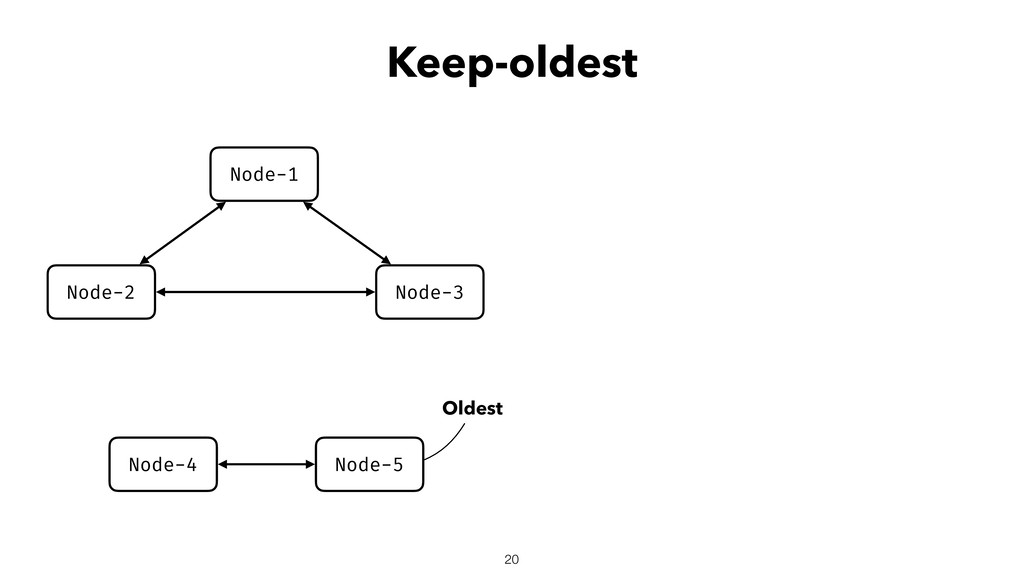
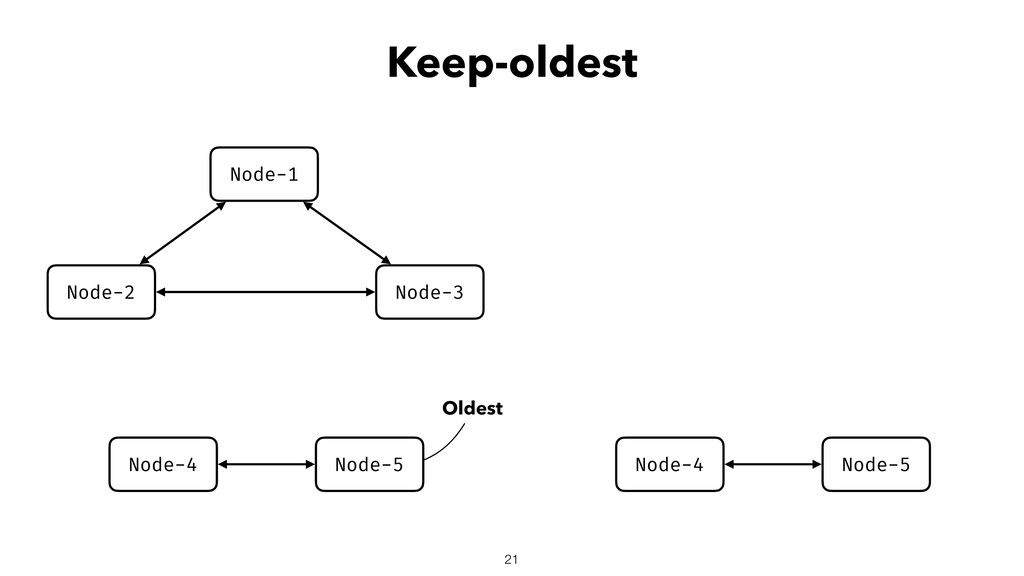
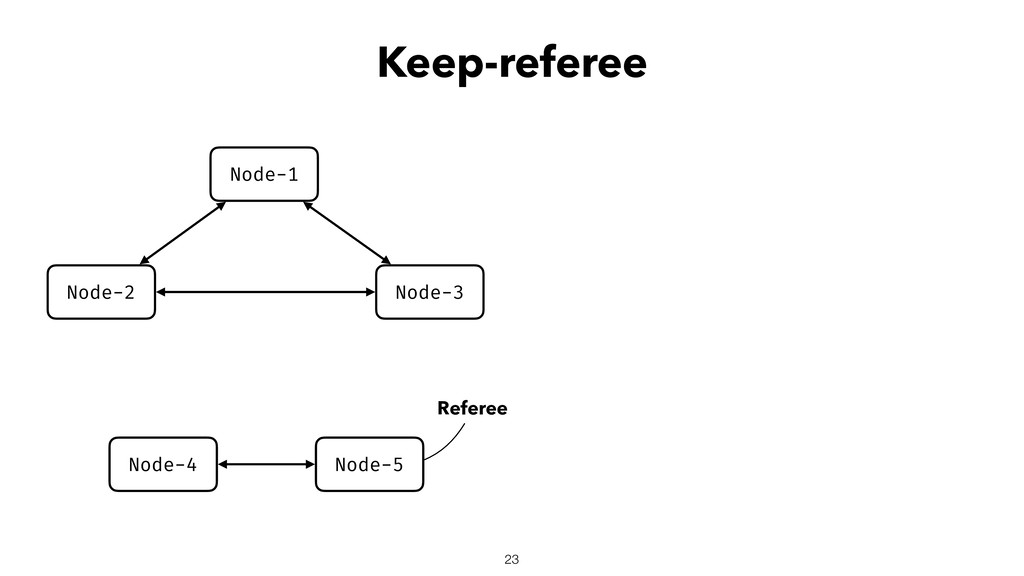
When using Akka-Cluster, when some nodes become unreachable, no one can join or even leave the cluster anymore. To bring back the cluster to a fully working state, the unreachable nodes must be downed. However, because there is no way of knowing if a node has crashed or is victim of a network partition, if done incorrectly the downing could lead to data corruption, a split-brain, and a headache fixing it.
In order to automatically and correctly recover from unreachable nodes, Lightbend provides a resolver through it’s subscription. For individuals and companies that cannot afford the subscription, some open-source solutions exist but do not come near it in terms of features and correctness. To fix that gap, I developed an open-source split-brain resolver called Lithium as part of my EPFL master project.
In this talk I will introduce Lithium, explain how it works helps with recovering the cluster from unreachable nodes, its internals, and everything to know to set it up.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
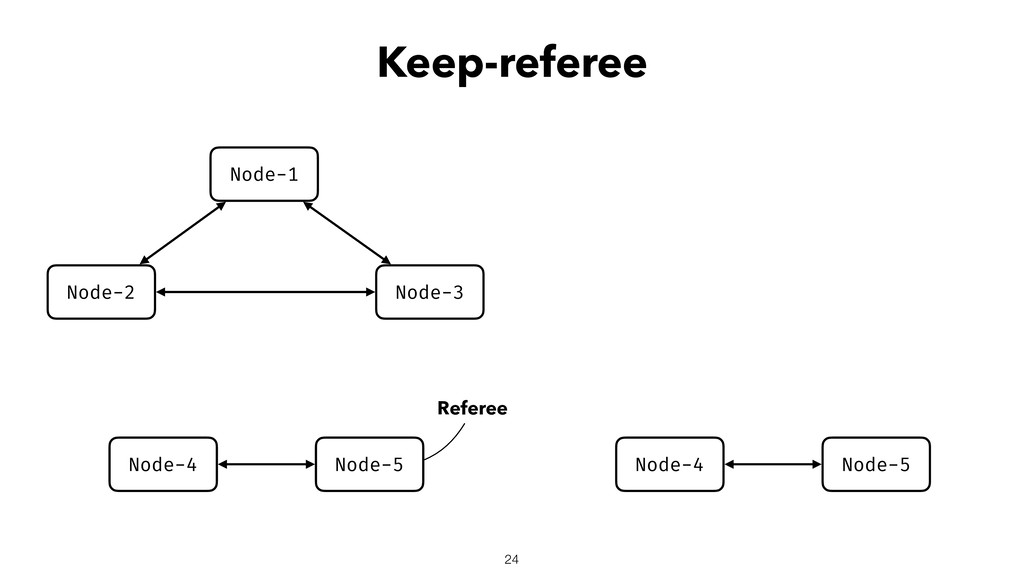{kind=link}
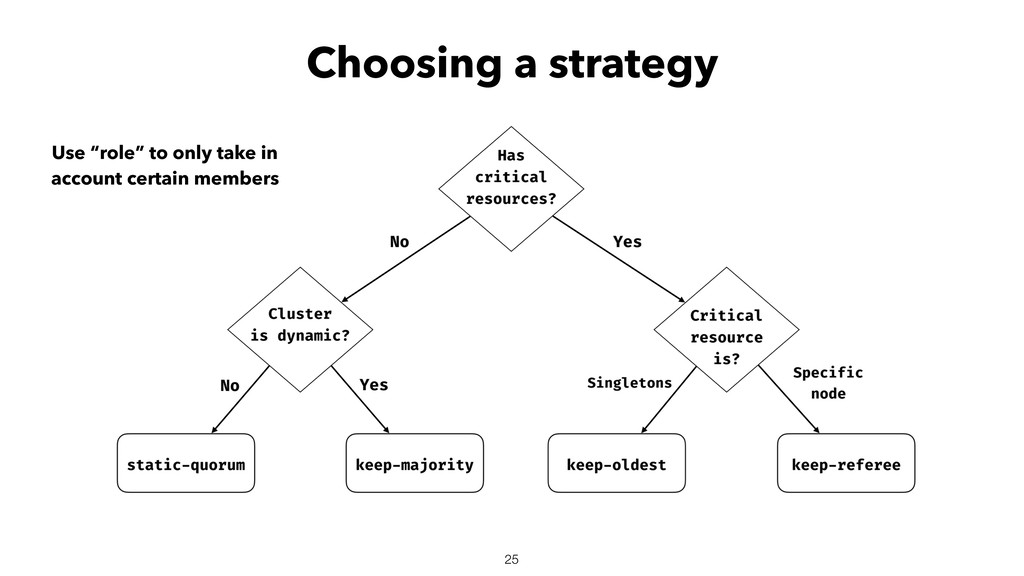{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
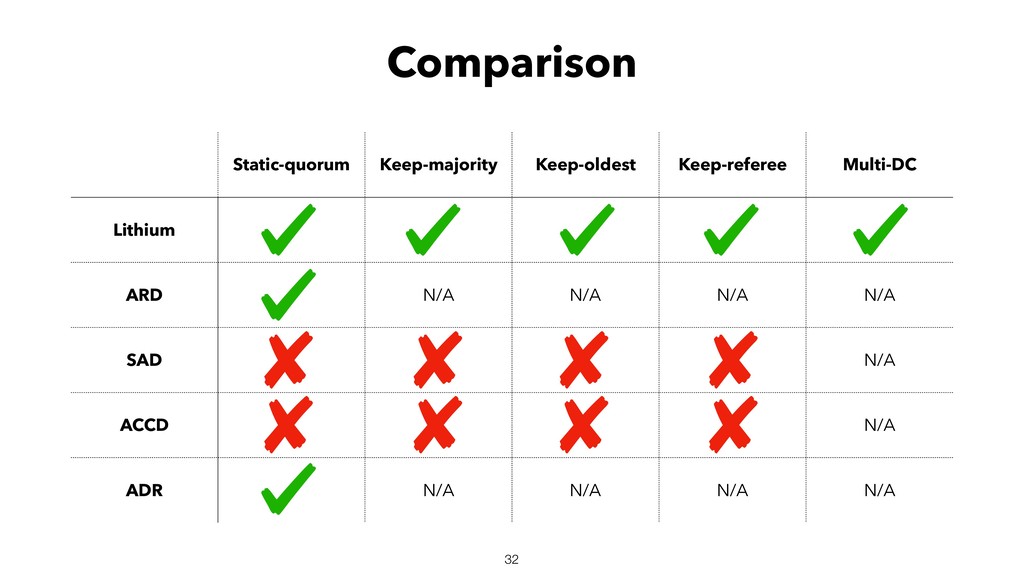{kind=link}
{kind=link}