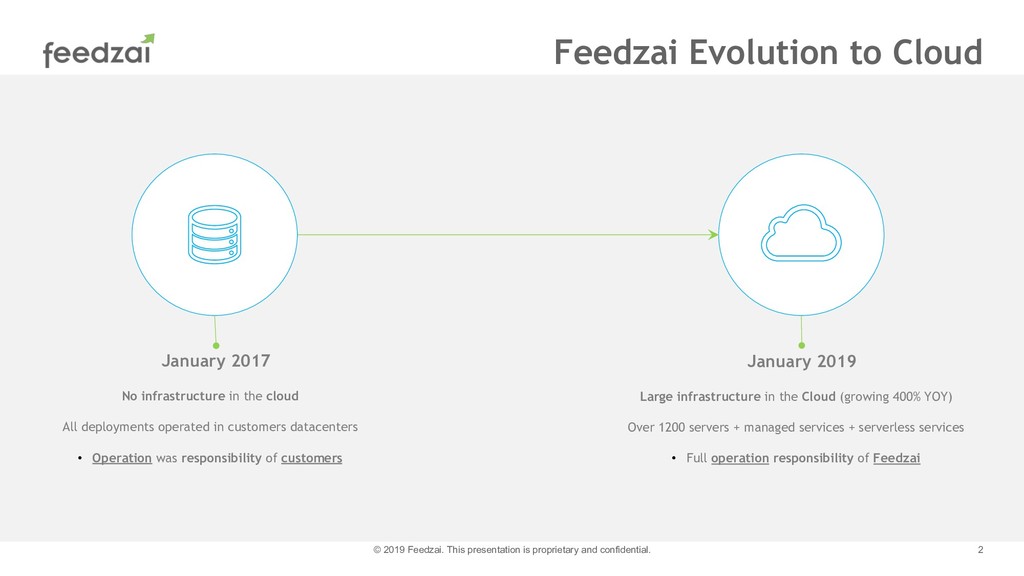
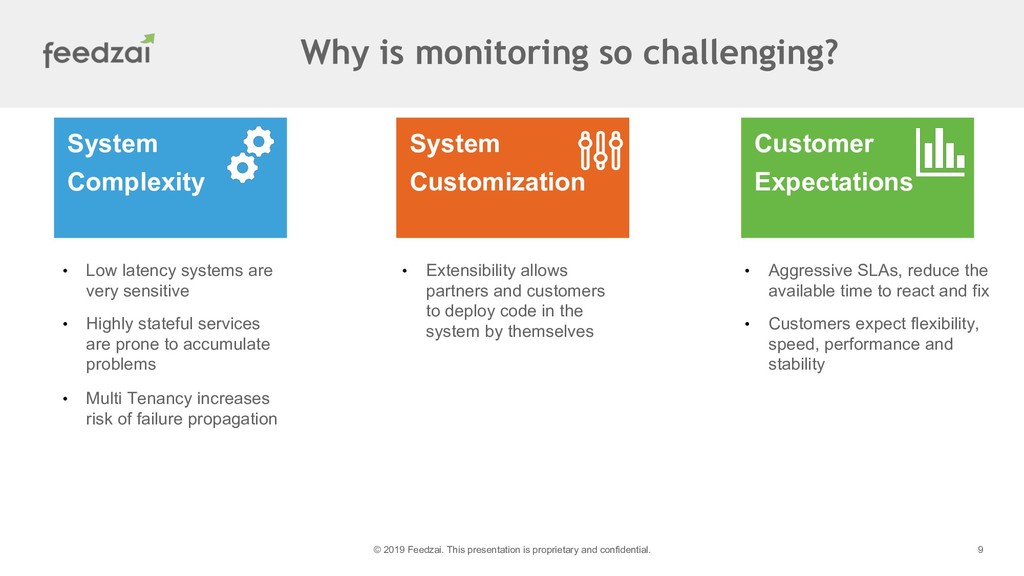
At Feedzai we have been making a transition to a devops mindset. During 2018 our cloud footprint grew 400% being a significant part of Feedzai's business. In this talk I will cover the effort put on monitoring and alerting of our systems and how our cloud operation changed the way we address monitoring from planning to the alerts that reach engineers phones.
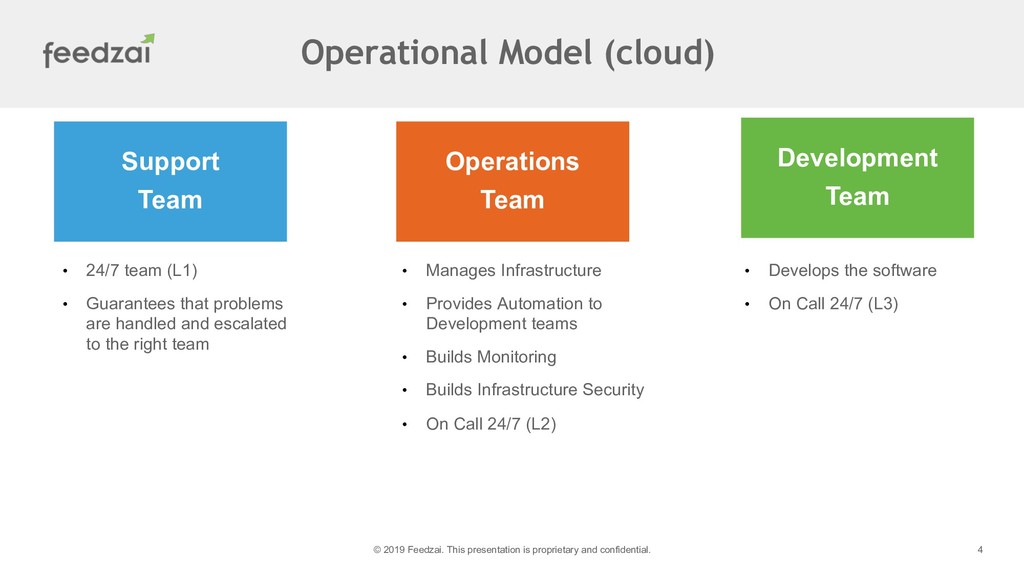
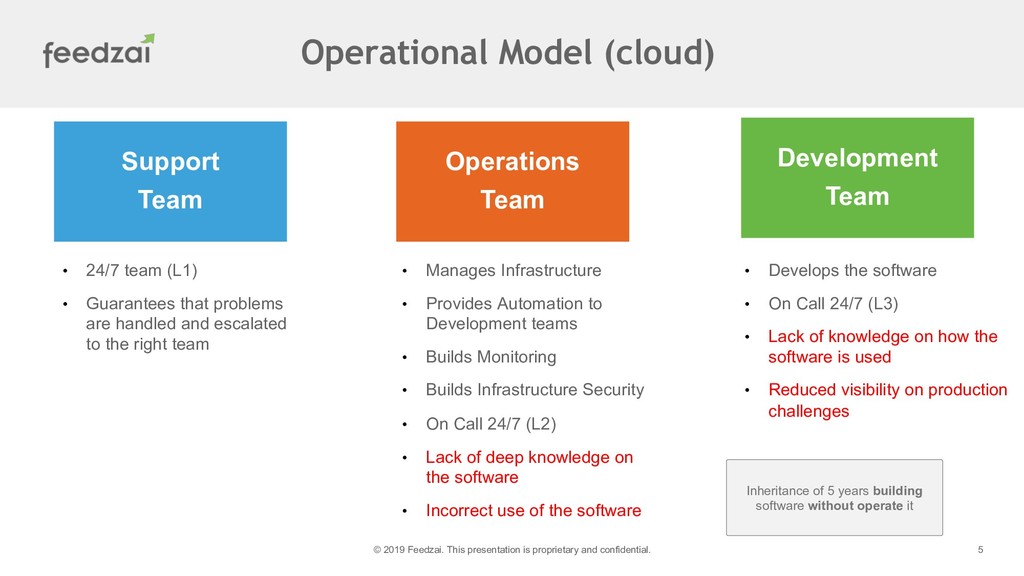
I'll go into details of the transformation process and the differences between our legacy monitoring platform and the current state as well the impact on the quality of our service.
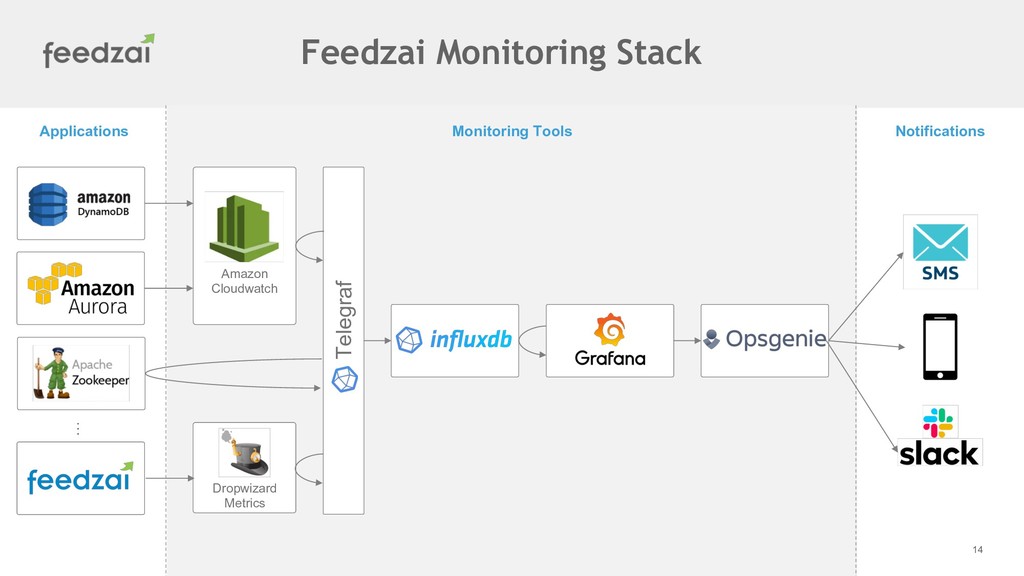
Feedzai monitoring stack is built on top of TIG (Telegraf, InfluxDB and Grafana) and covers mostly open source technologies such as Cassandra, Postgres, RabbitMQ, Hadoop (Spark and Yarn) as well as AWS native services.
Diogo Guerra is VP of Engineering at Feedzai leading the development of Feedzai's Real Time Fraud Detection system. He specializes in distributed systems, high performance, and low latency real-time platforms.
Leading teams to design and build systems that can process high volumes of data and leverage the power of Machine Learning, Diogo works on a daily basis with top financial institutions across the world to fight fraud.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}