Presented at Papers We Love, Too (SF). https://youtu.be/FXuHxVIMIhw?t=15m00s
Apart from being a fantastic primer on designing portable concurrent data structures, this well-sourced paper provides a number of captivating ideas on thinking about, modeling, and solving concurrency and contention problems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
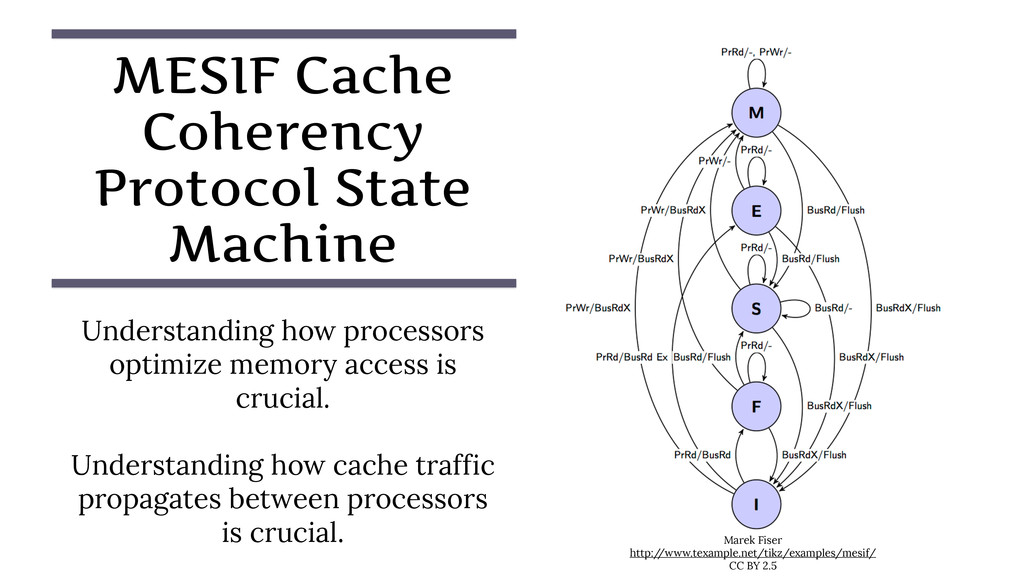{kind=link}
![“[T]he cache line is the granularity at which coherency is](https://files.speakerdeck.com/presentations/f5d51751a2794e97b62e04bf1798a71b/slide_9.jpg){kind=link}
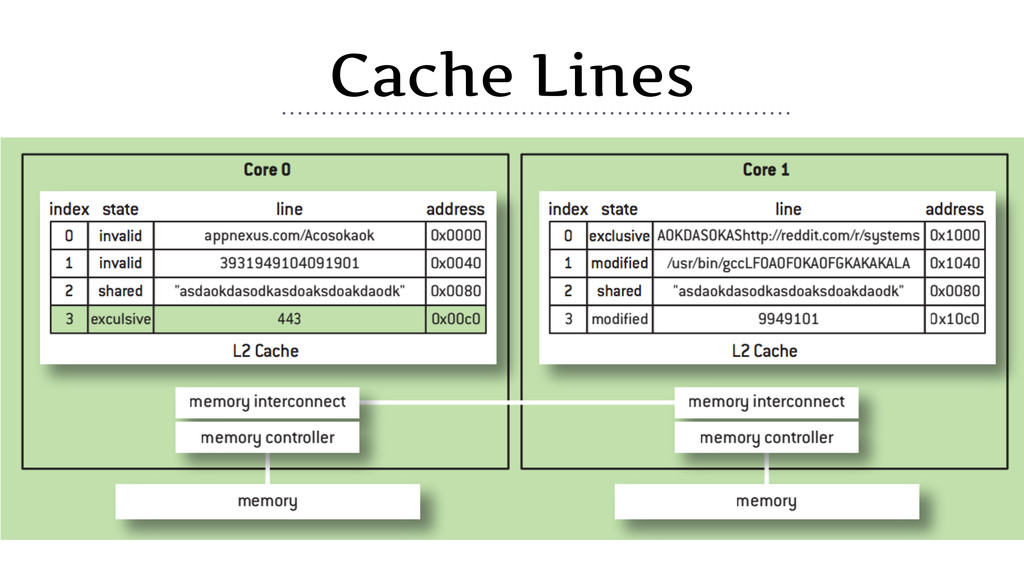{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
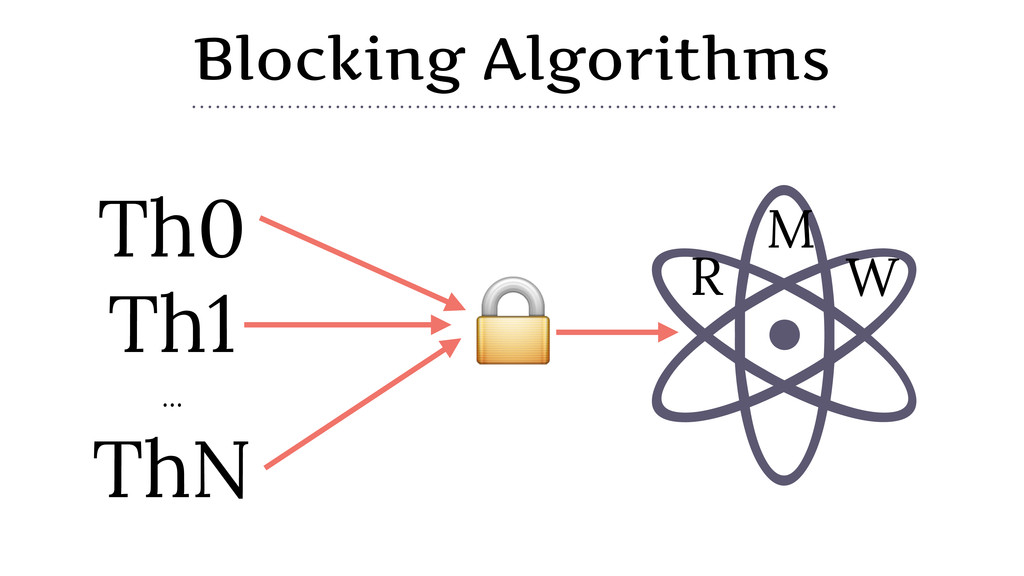{kind=link}
{kind=link}
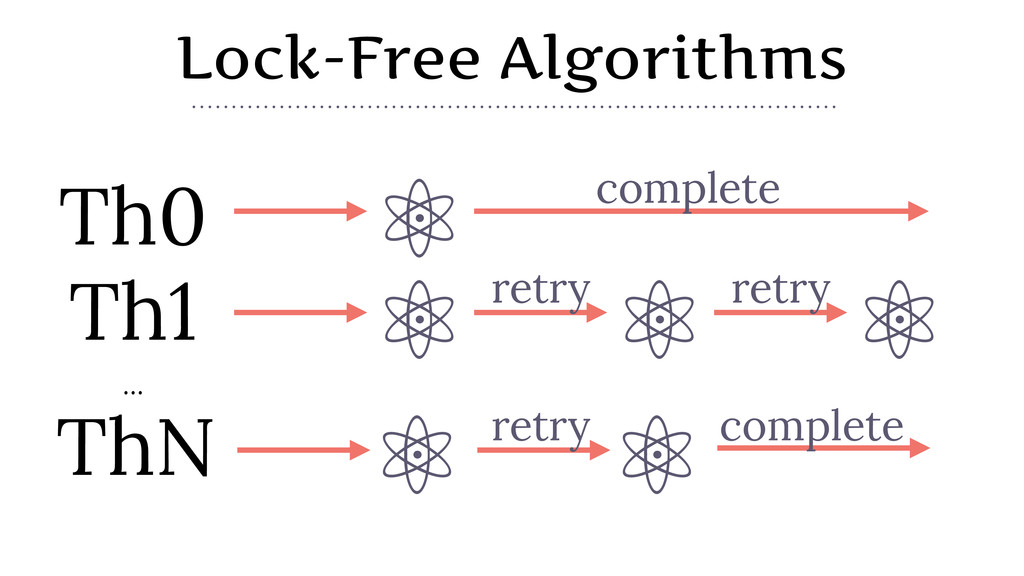{kind=link}
{kind=link}
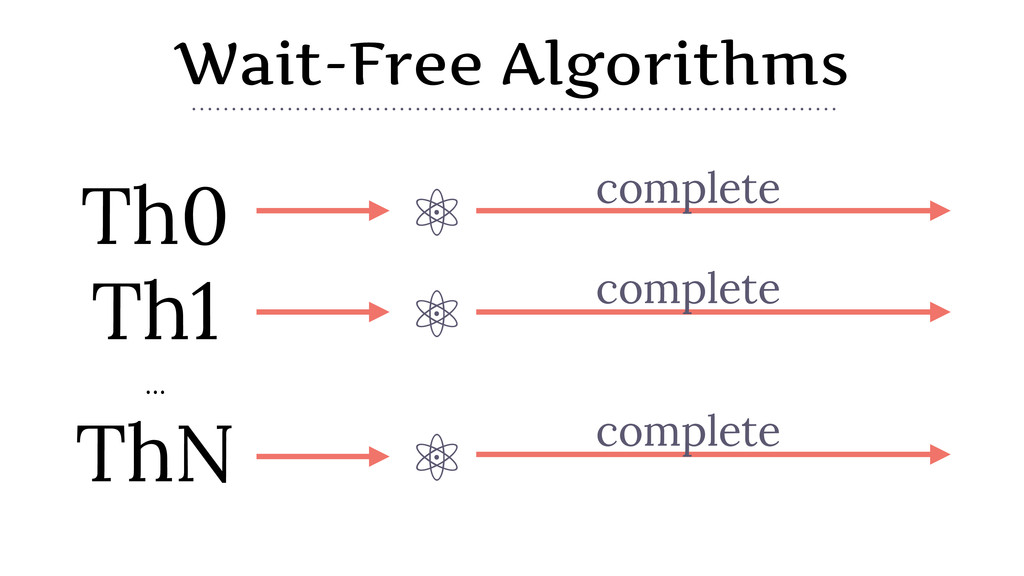{kind=link}
{kind=link}
![“Contention [is] a product of the effective arrival rate of](https://files.speakerdeck.com/presentations/f5d51751a2794e97b62e04bf1798a71b/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
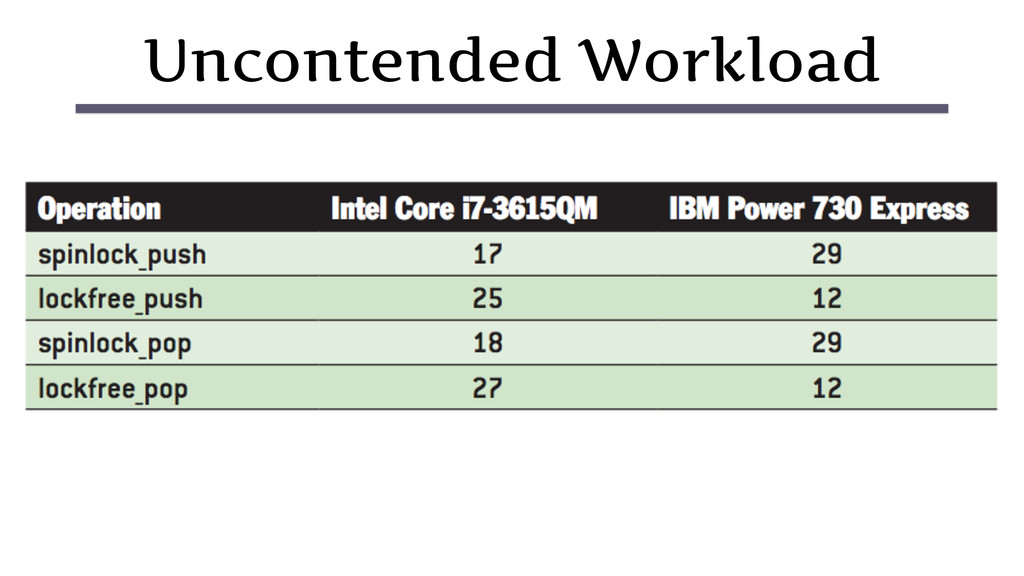{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}