If you've ever worked on concurrent or parallel systems, race conditions have invariably plagued your existence. They are difficult to identify, debug, and nearly impossible to test repeatably. While race conditions intuitively seem bad, it turns out there are cases in which we can use them to our advantage! In this talk, we'll discuss a number of ways that race conditions -- and correctly detecting them -- are used in improving throughput and reducing latency in high-performance systems.
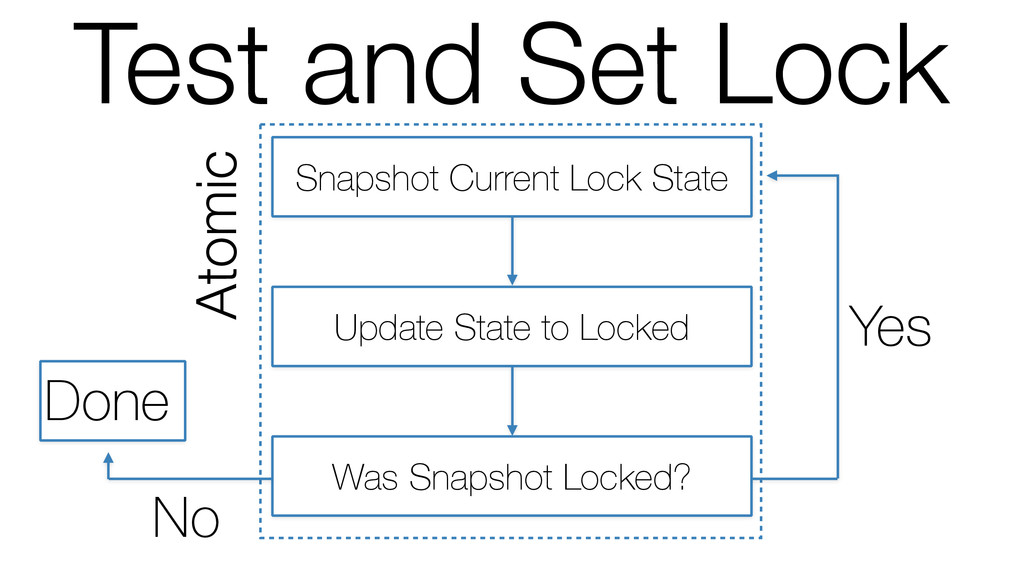
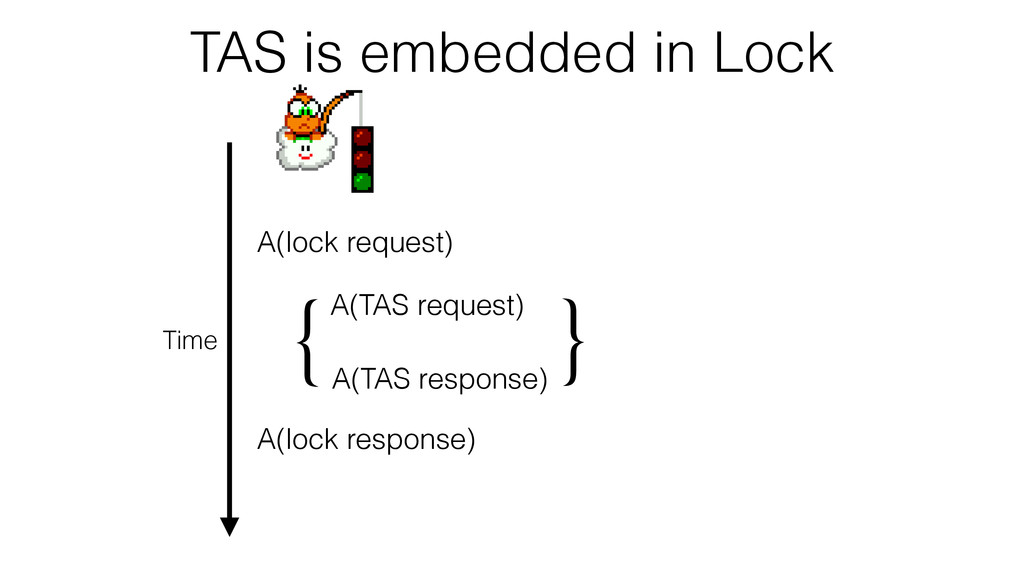
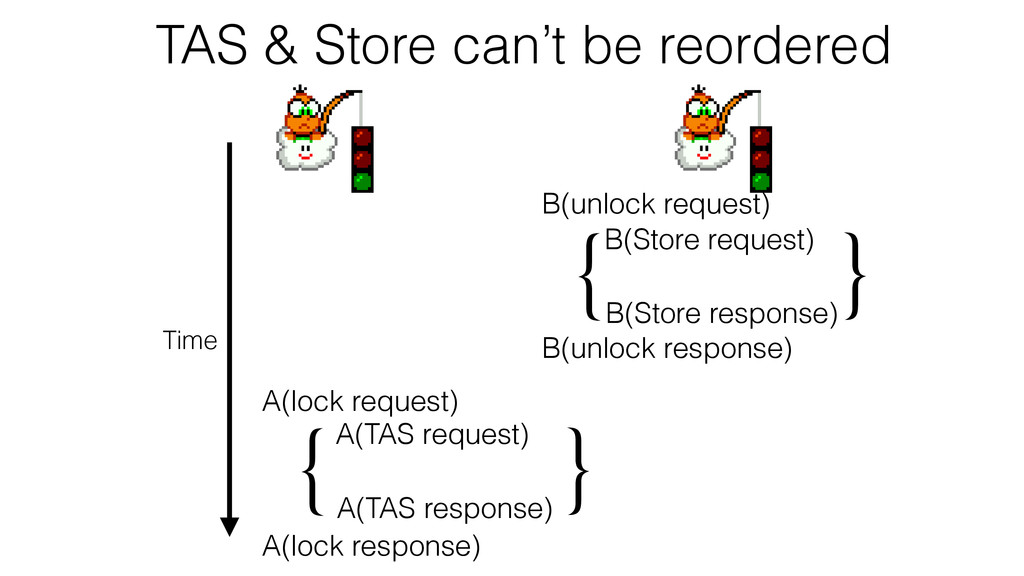
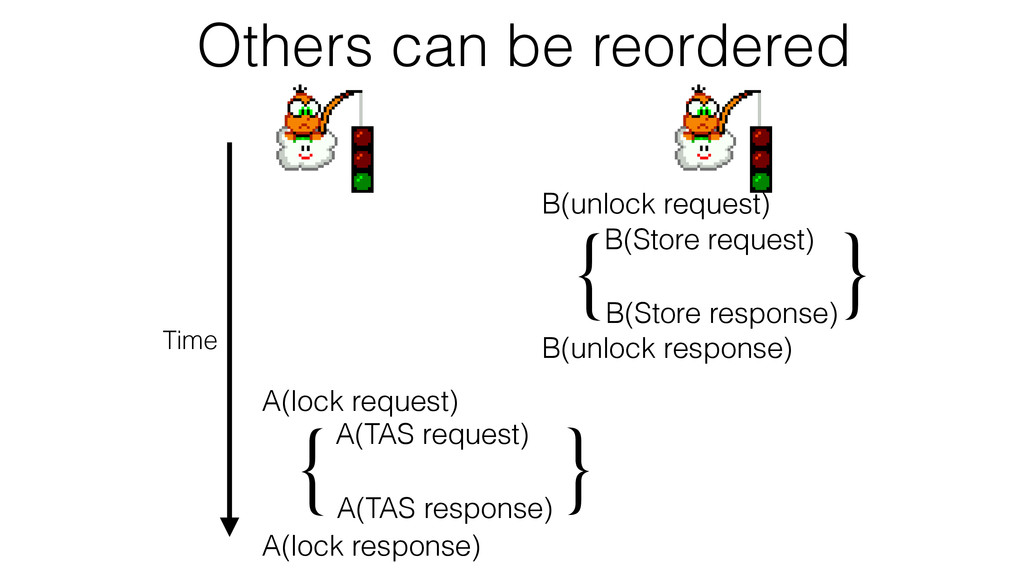
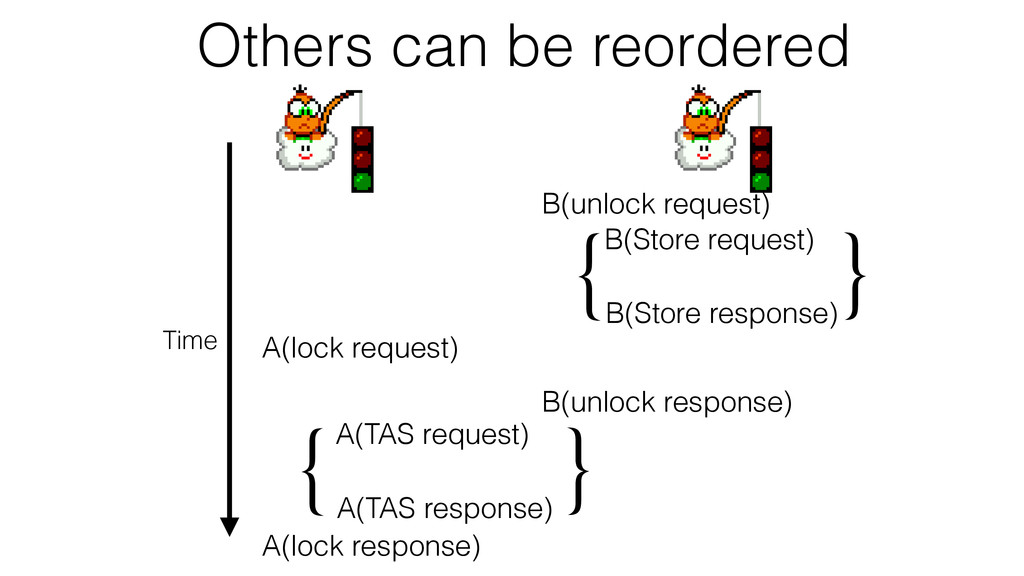
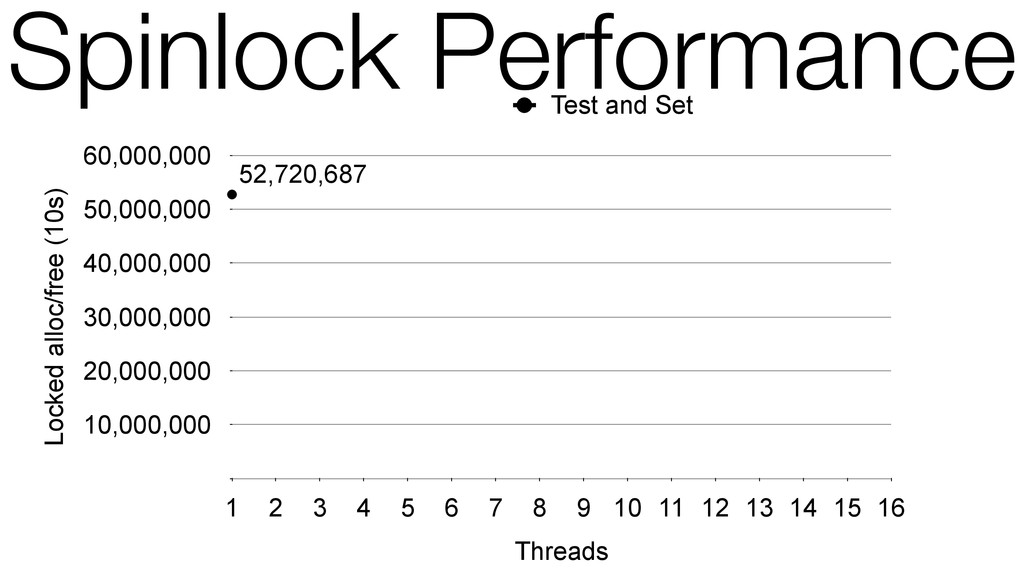
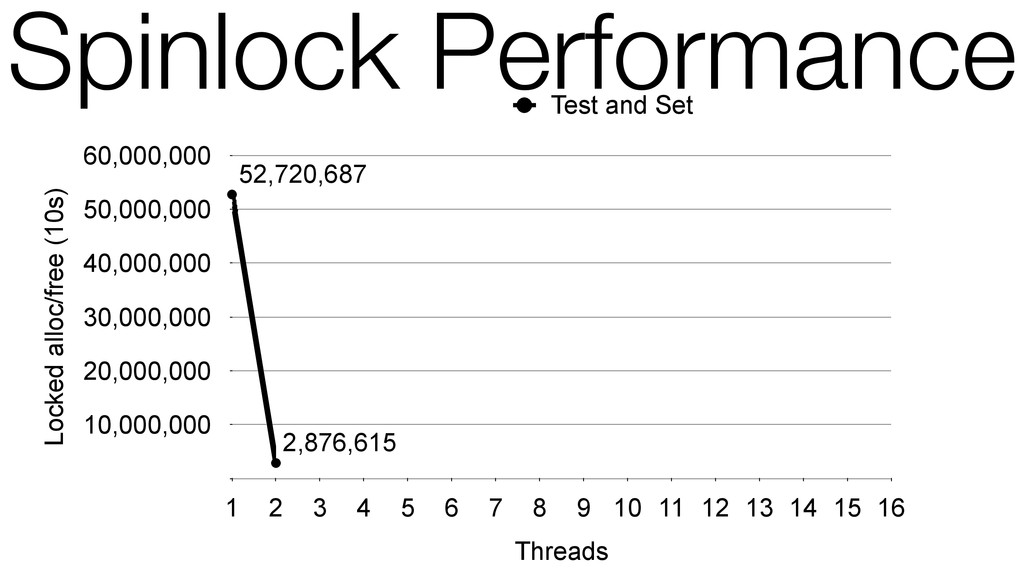
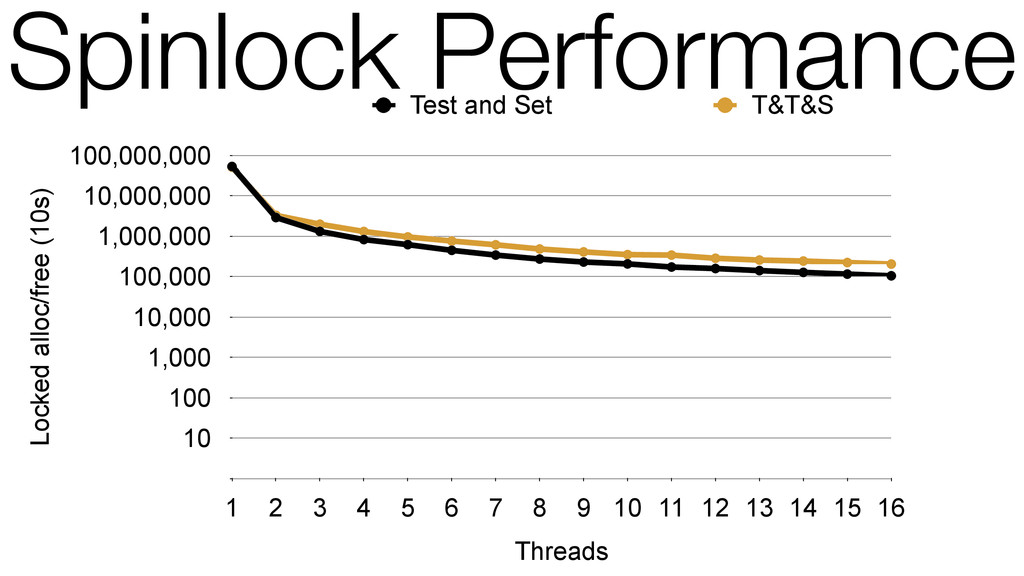
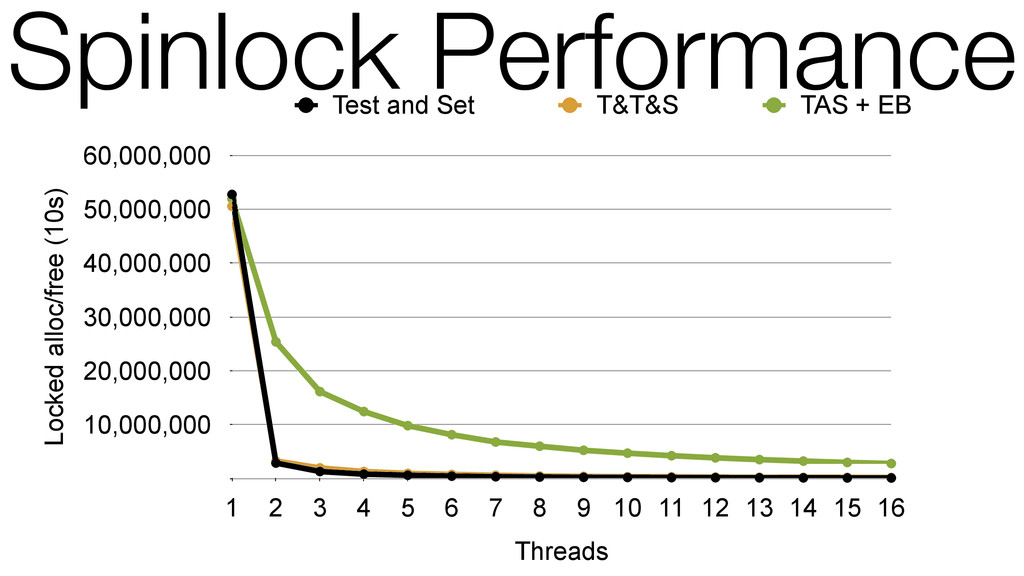
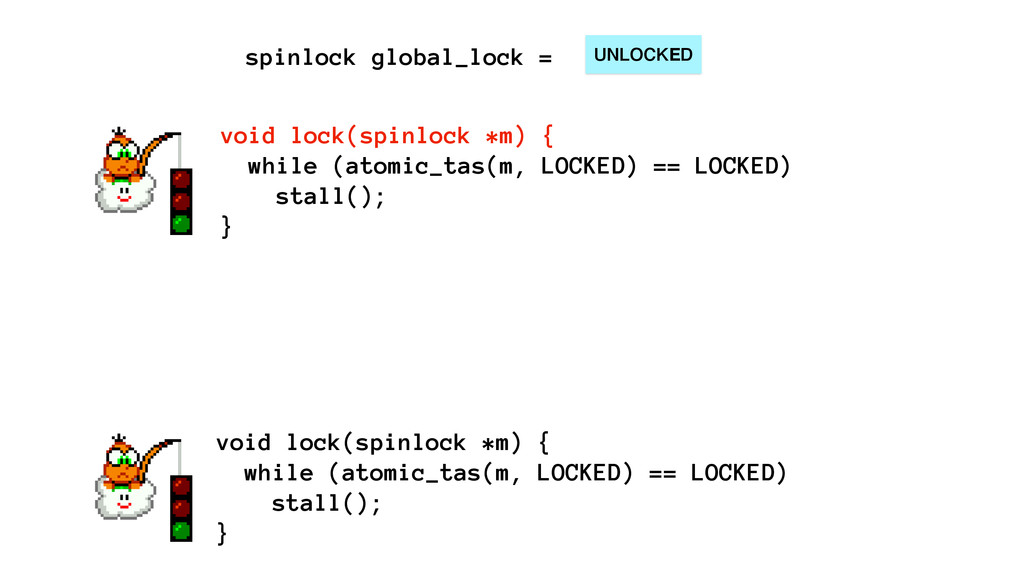
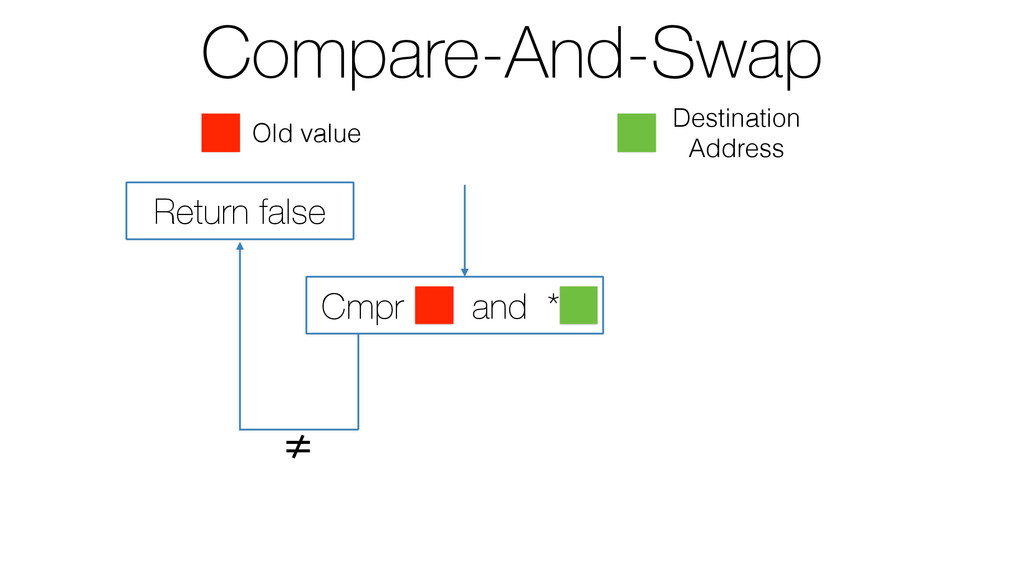
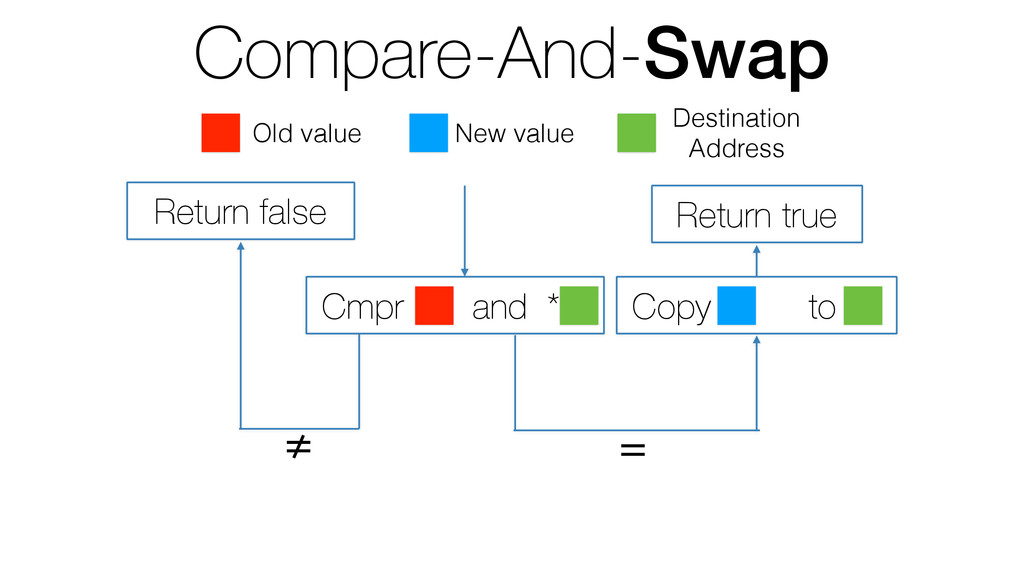
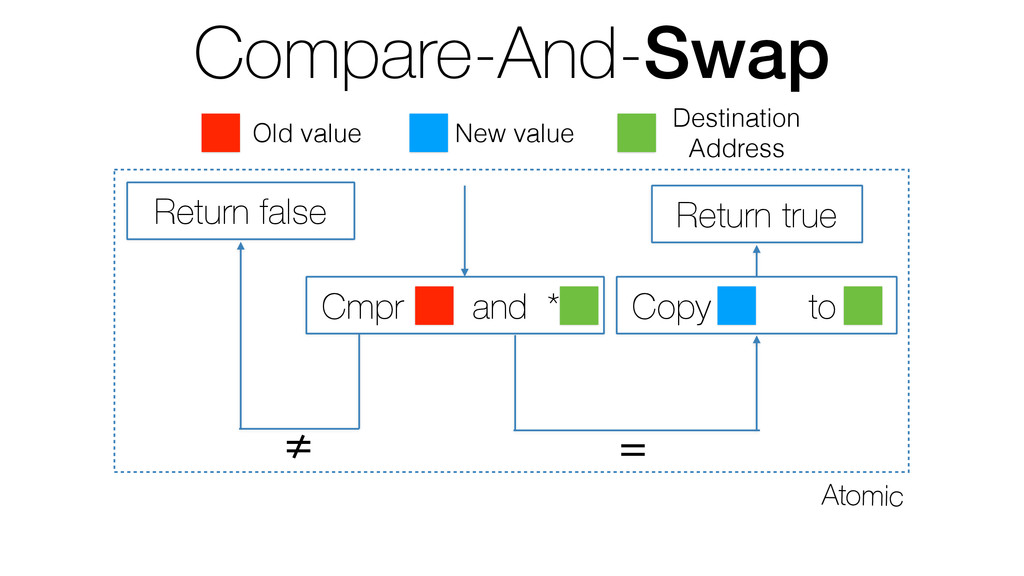
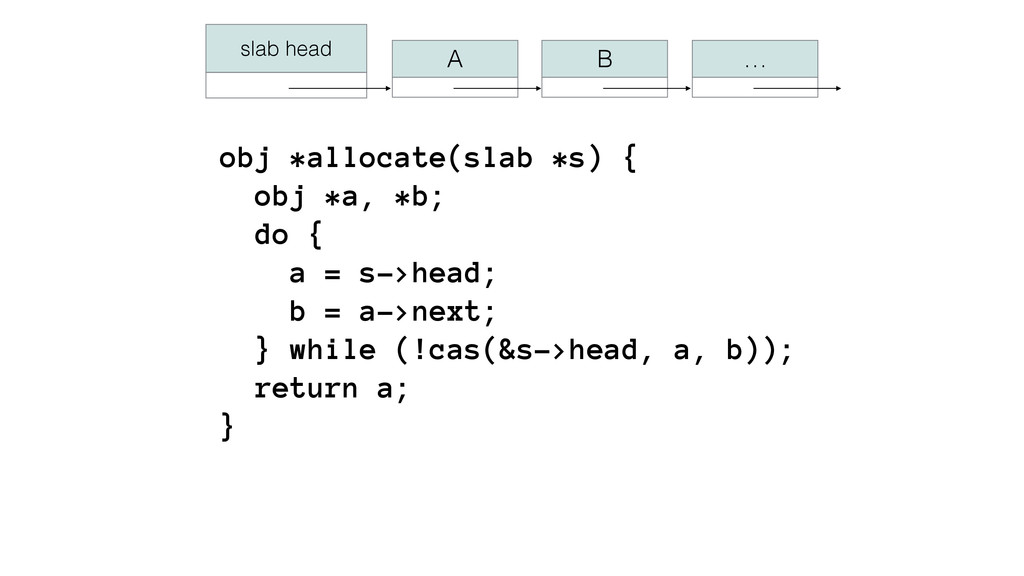
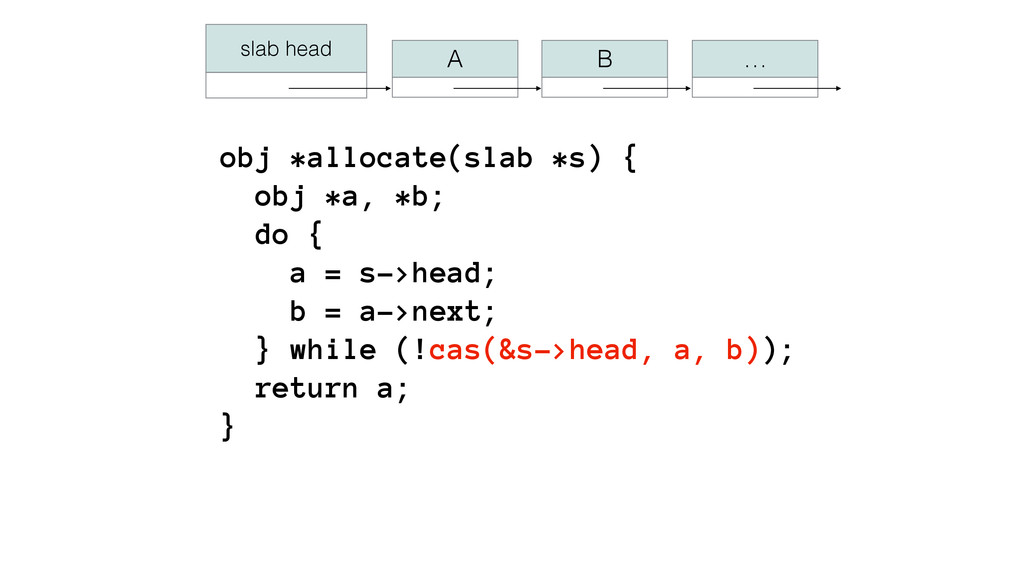
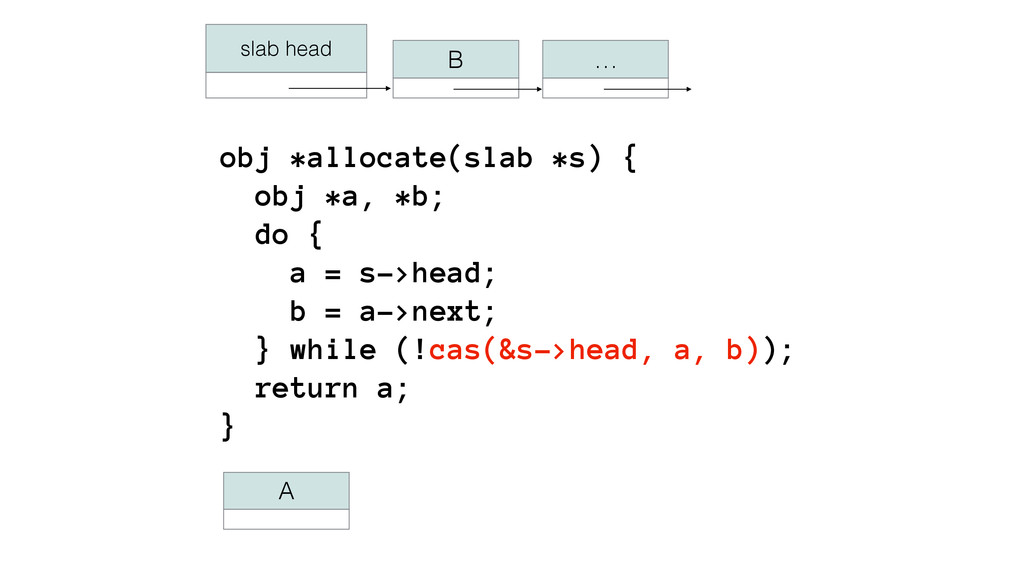
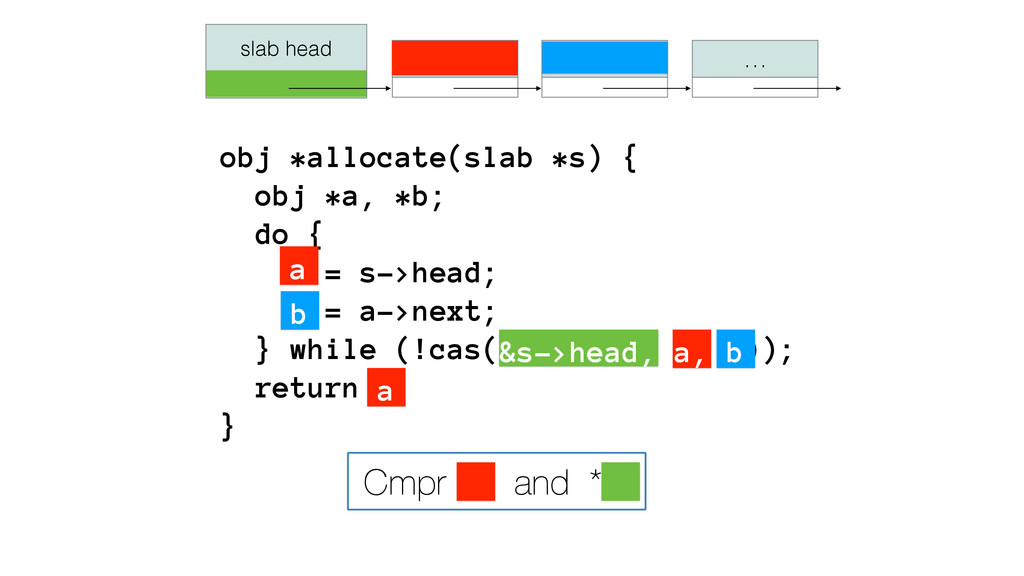
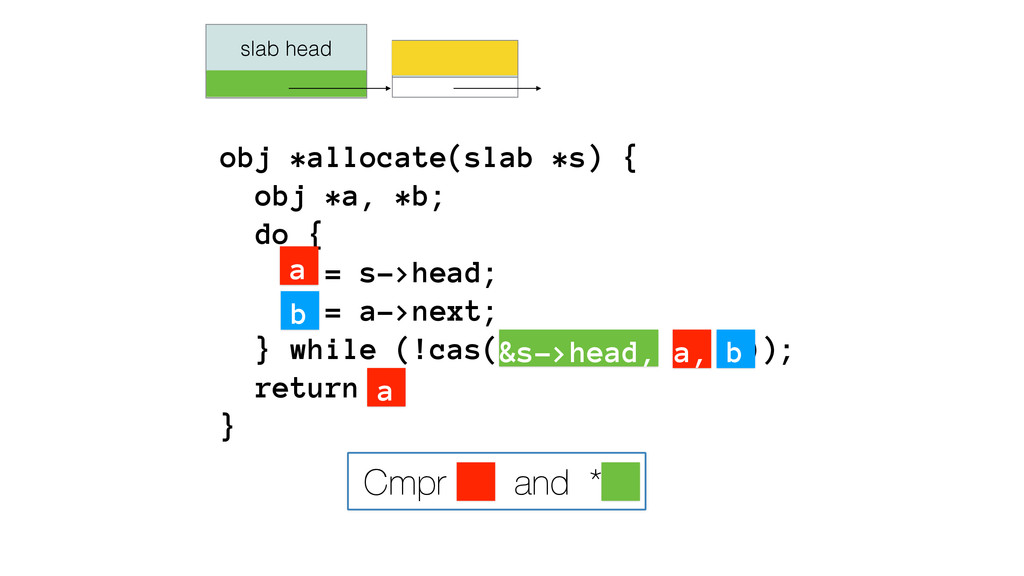
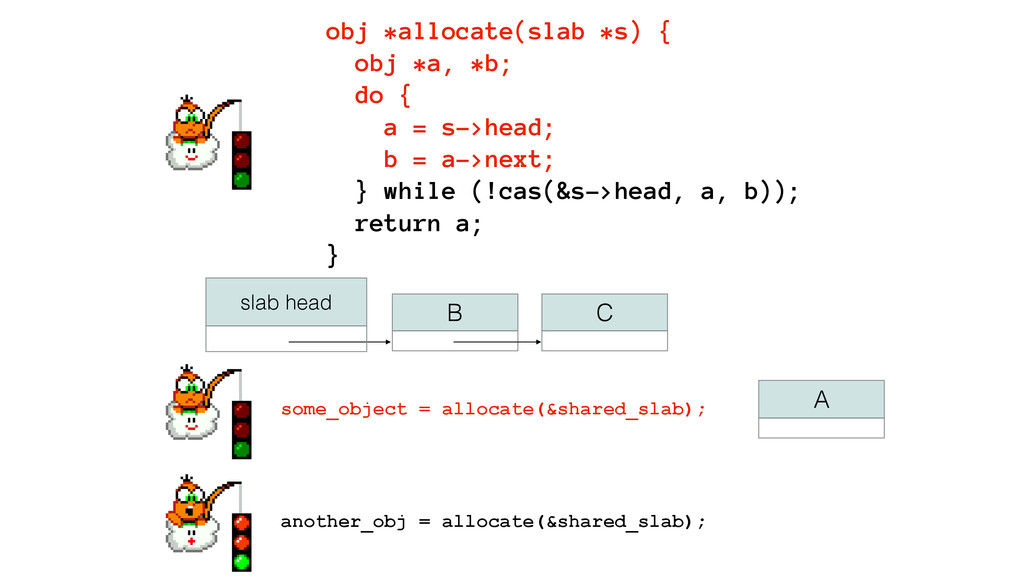
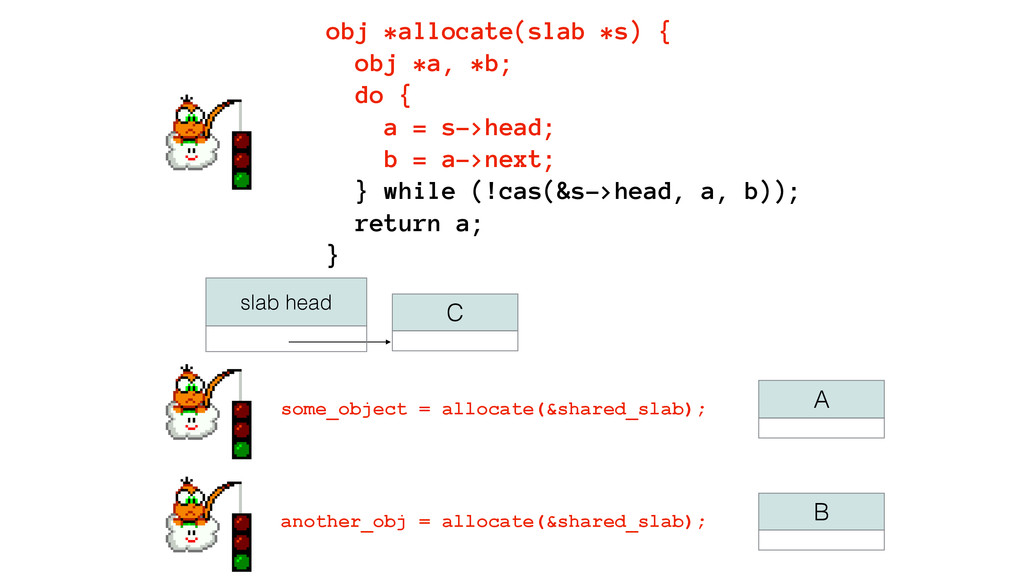
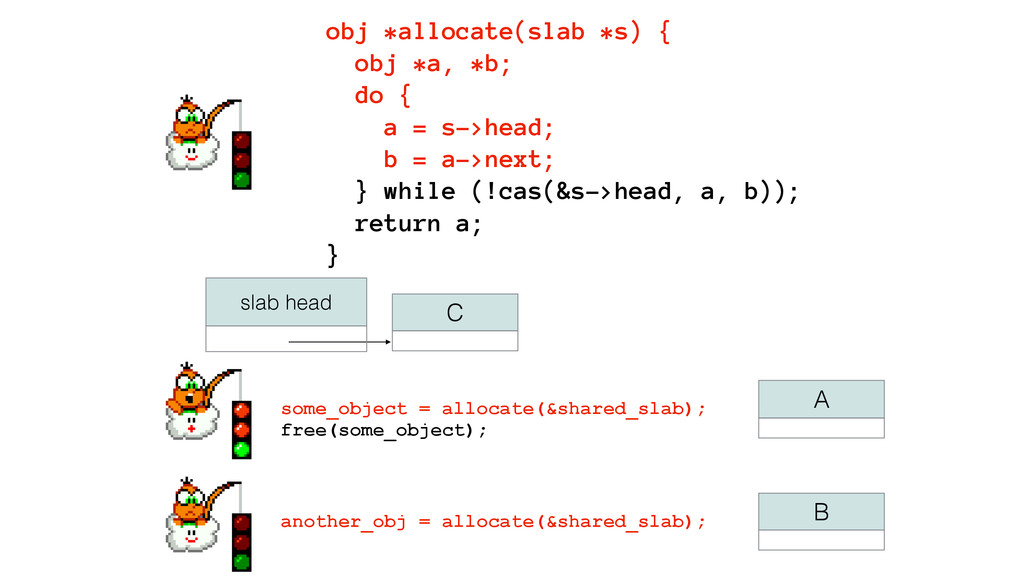
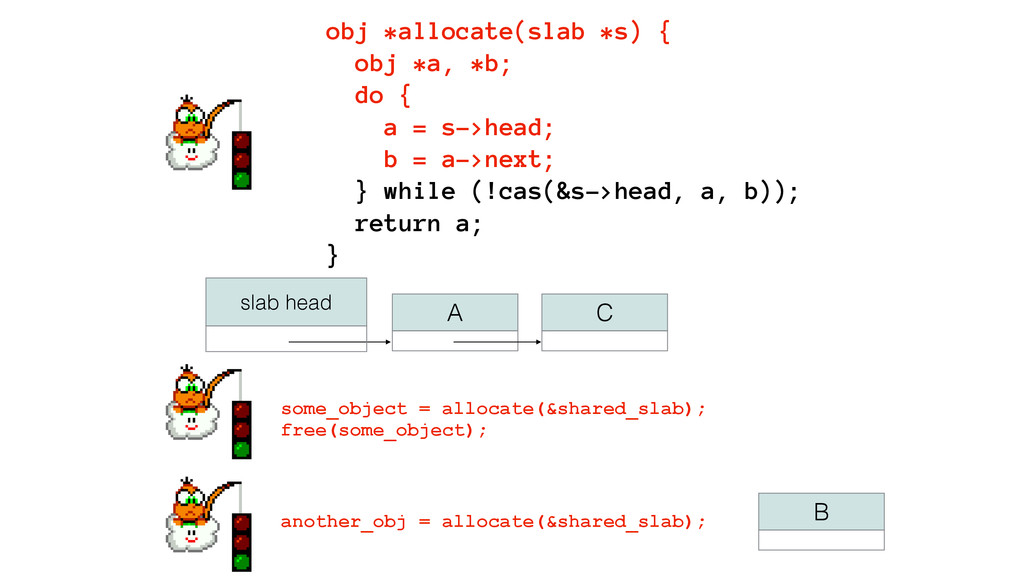
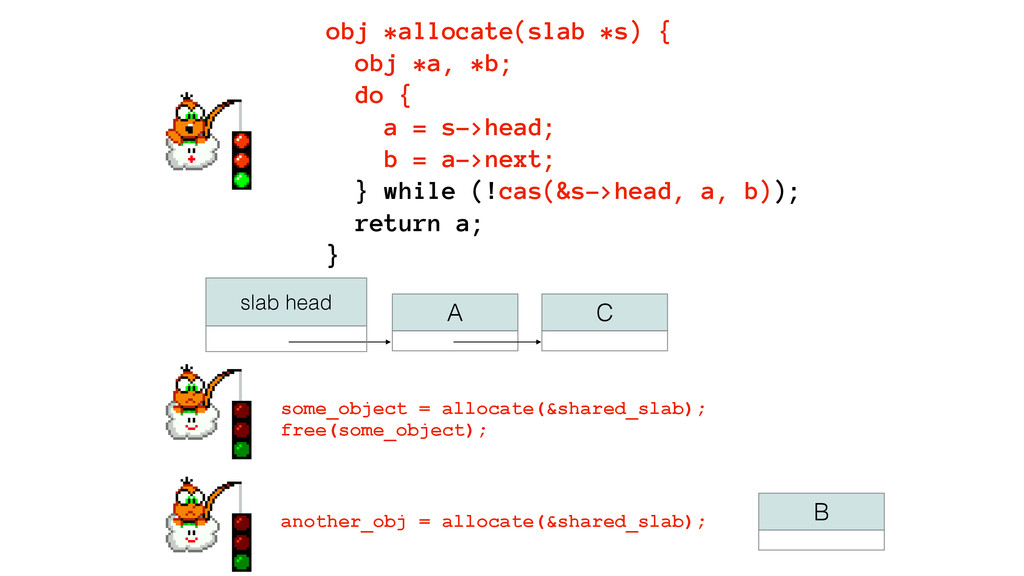
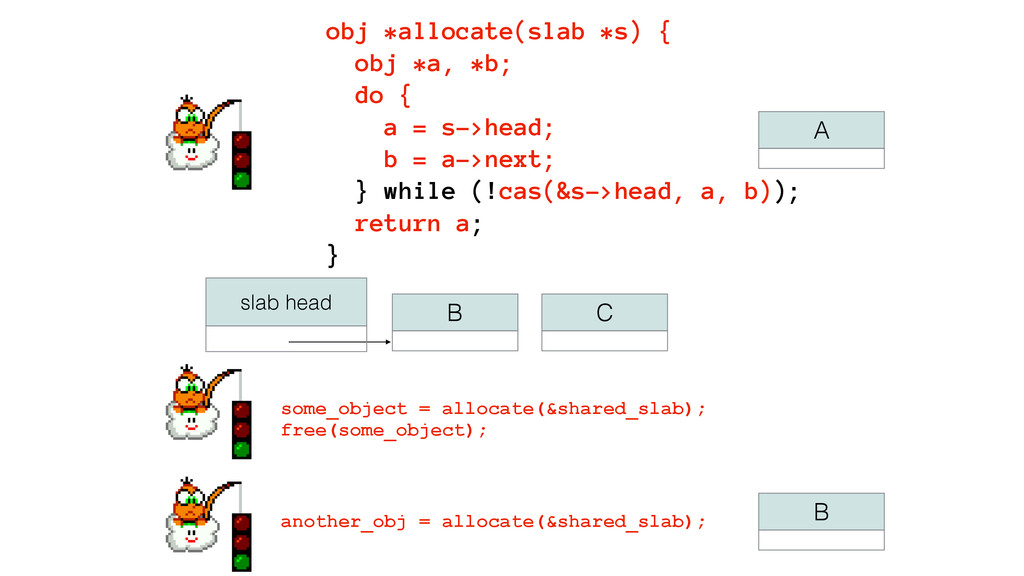
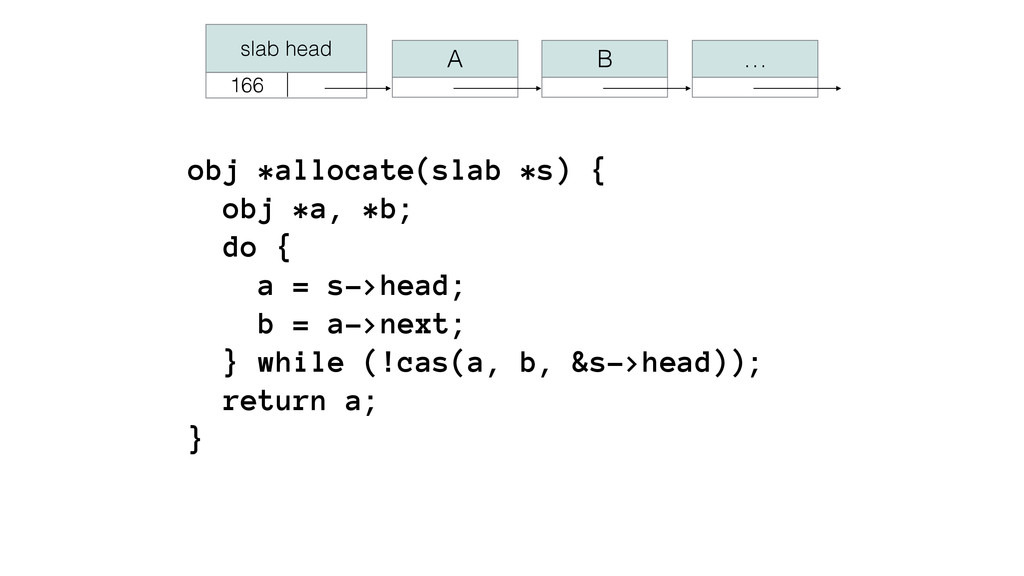
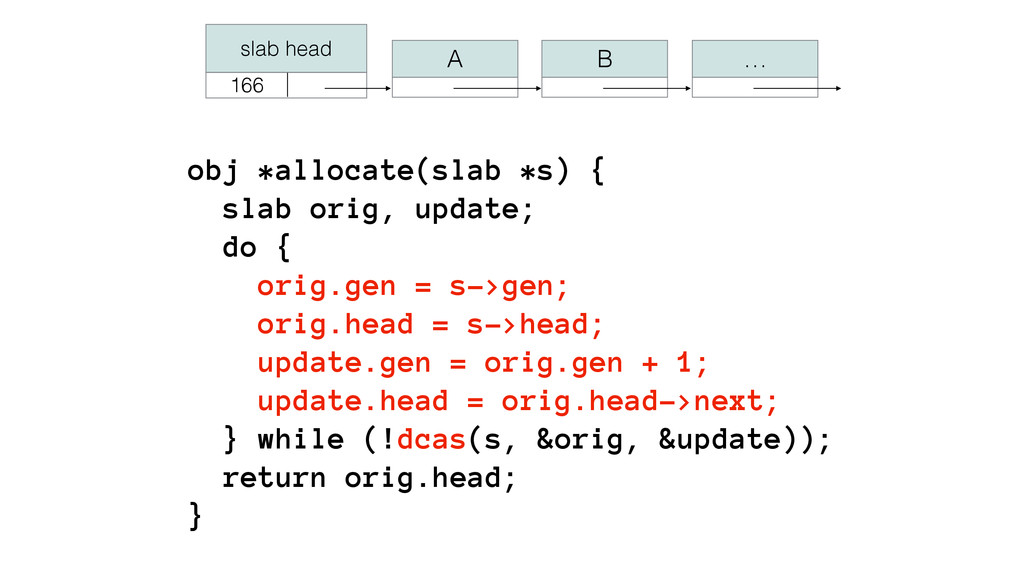
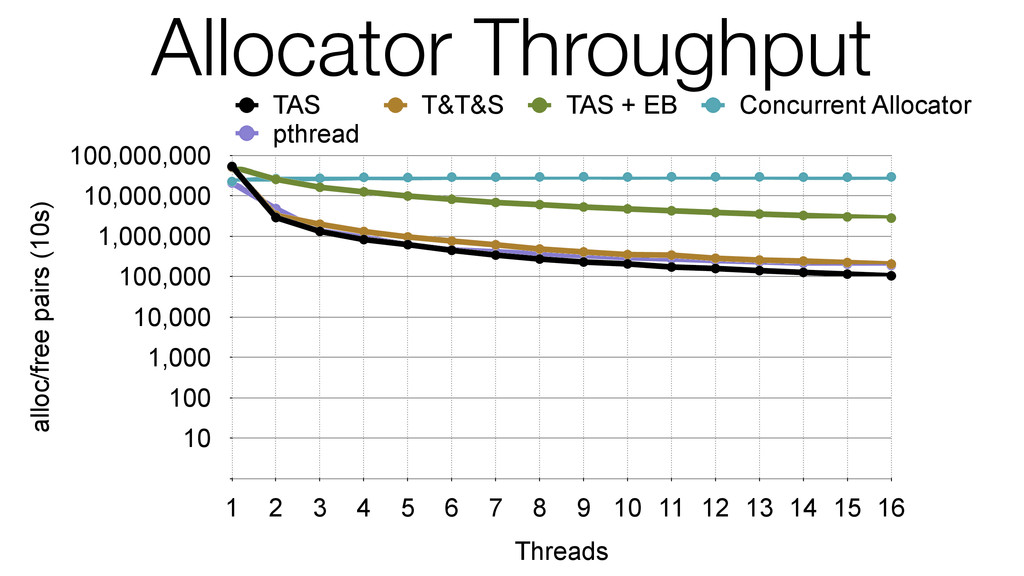
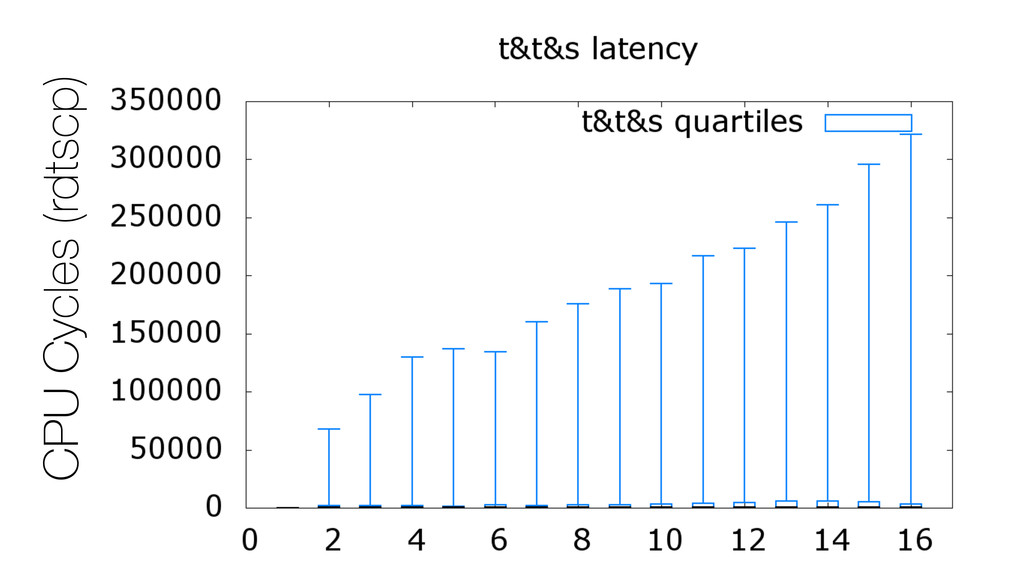
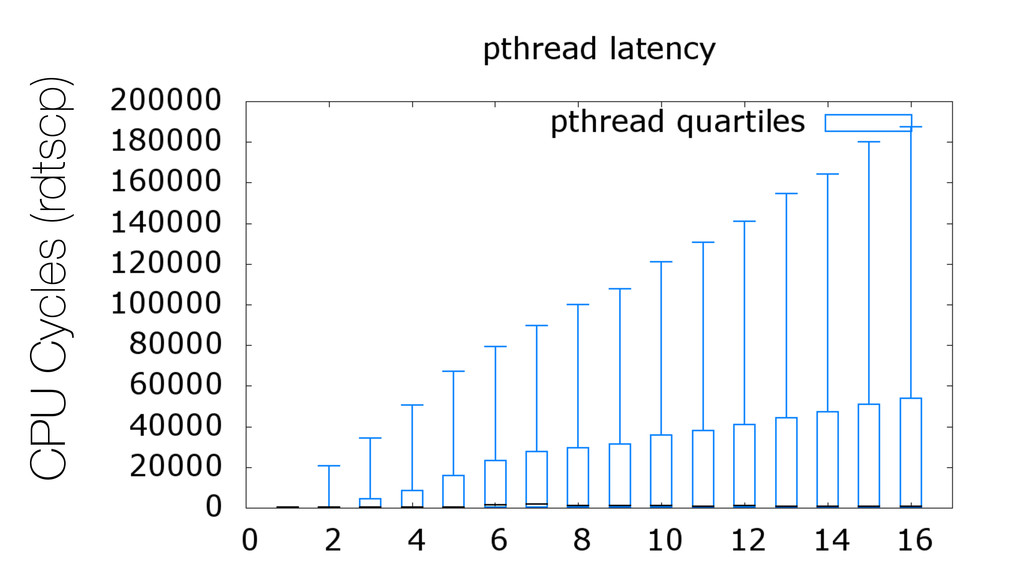
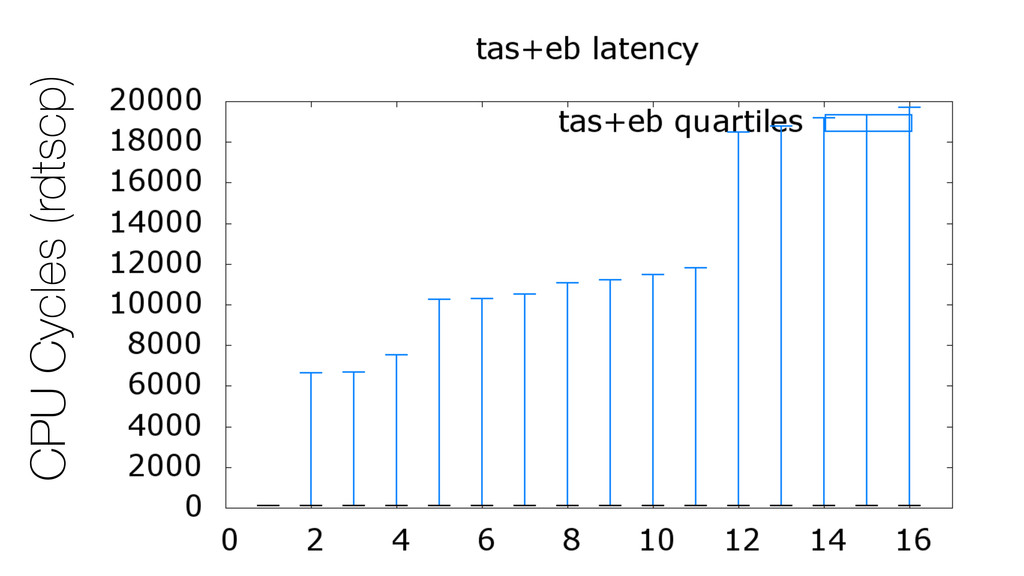
We begin this exploration with a brief discussion of the various types of locks, non-blocking algorithms, and the benefits thereof. We'll look at a naive test-and-set spinlock and show how introducing a race condition on reads significantly improves lock acquisition throughput. From here, we'll investigate non-blocking algorithms and how they incorporate detection of race events to ensure correct, deterministic, and bounded behavior by analyzing a durable, lock-free memory allocator written in C using the Concurrency Kit library.
Videos of this talk are available at:
* Strangeloop 2015 https://www.youtube.com/watch?v=3LcNHxBJw2Q
* OSCon EU 2015 https://www.youtube.com/watch?v=jmSiMCENcVY
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
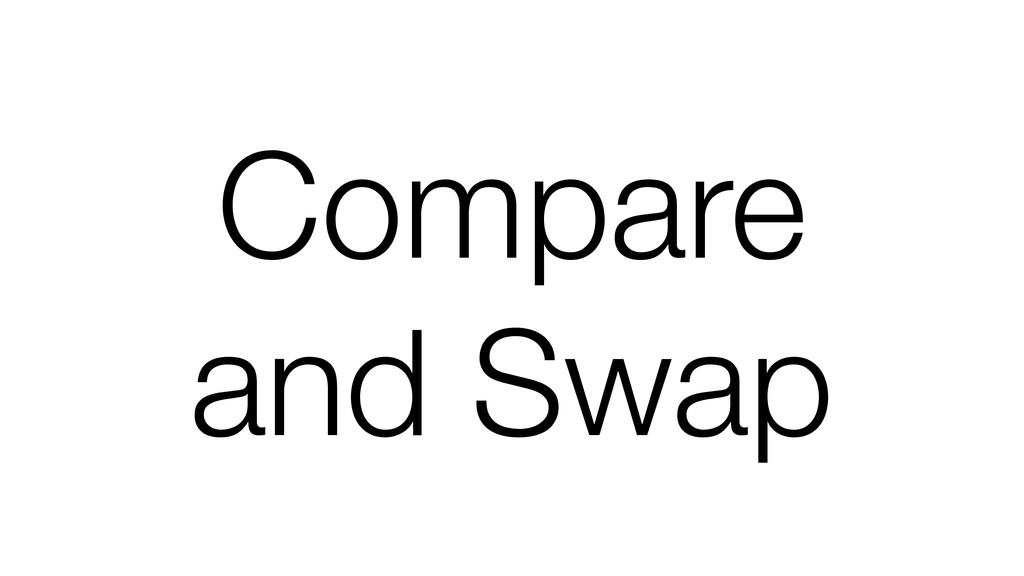{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
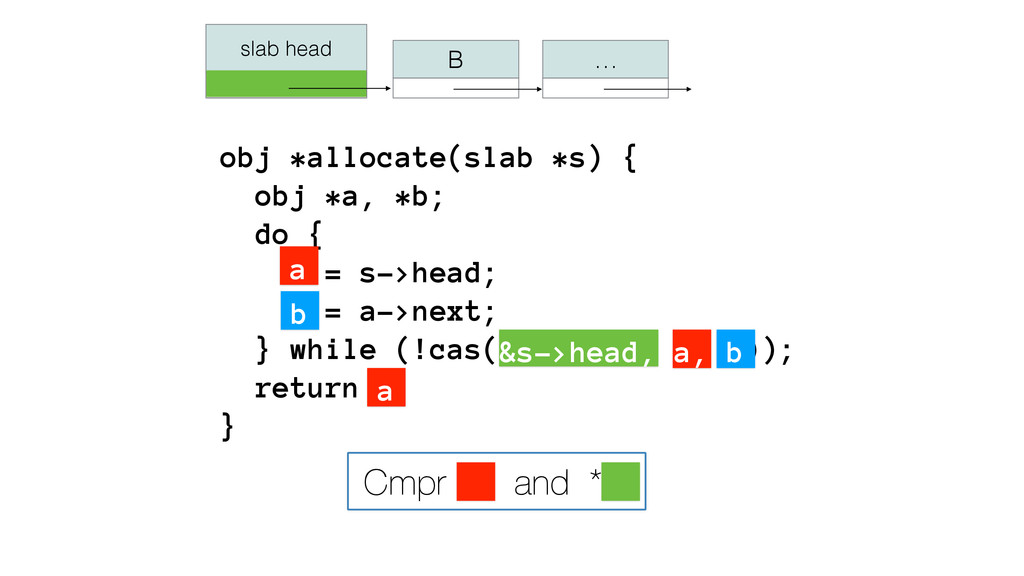{kind=link}
{kind=link}
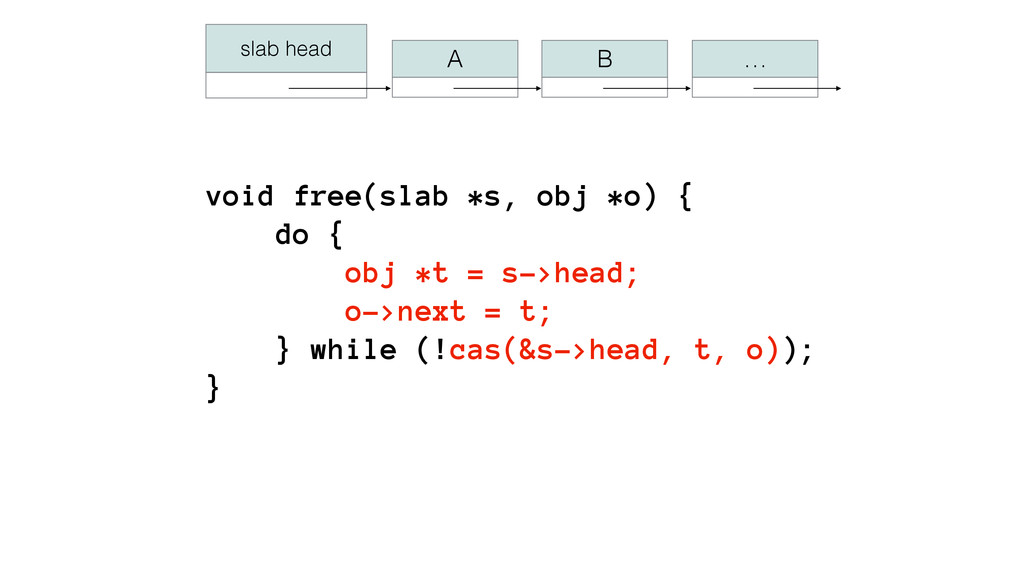{kind=link}
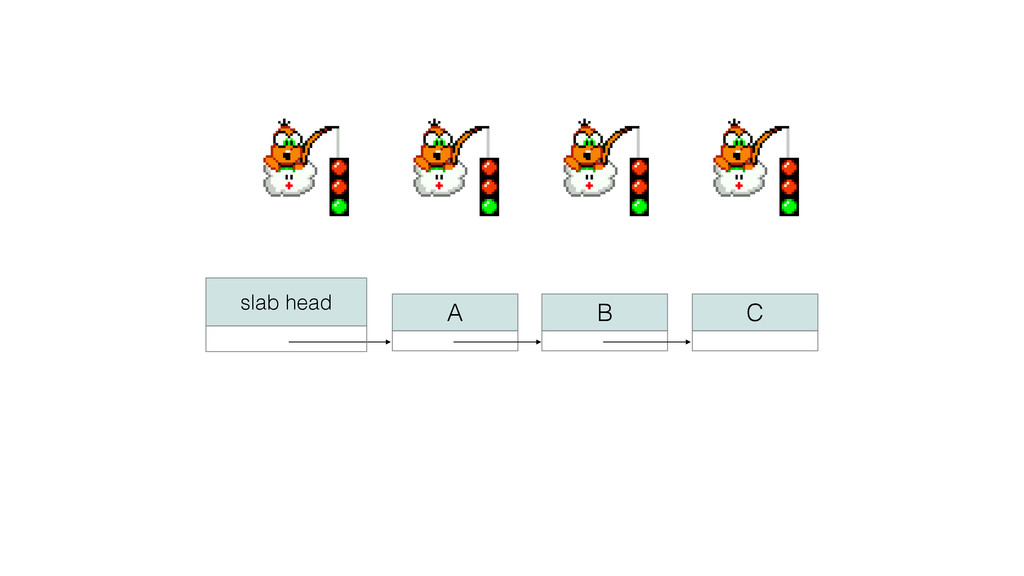{kind=link}
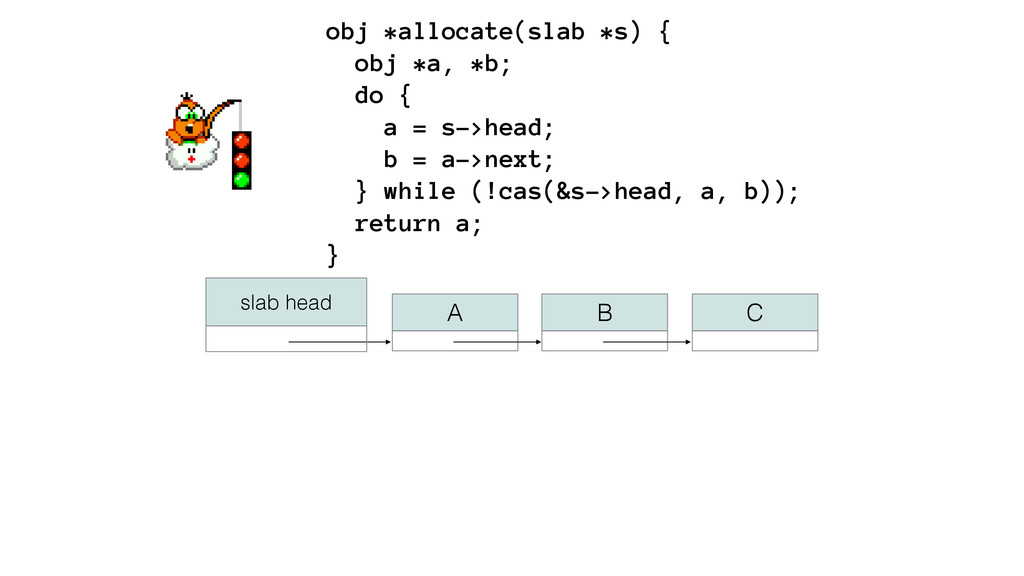{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}