a trabajar en redes neuronales, en el tiempo en el que Frank Rosenblatt desarrollo la regla de aprendizaje del perceptron. • En 1960 Widrow y su asesorado Marcian Hoff, presentaron la red ADALINE (Adaptive Linear Neuron), y una regla de aprendizaje la cual denominaron algoritmo LMS (least mean square).
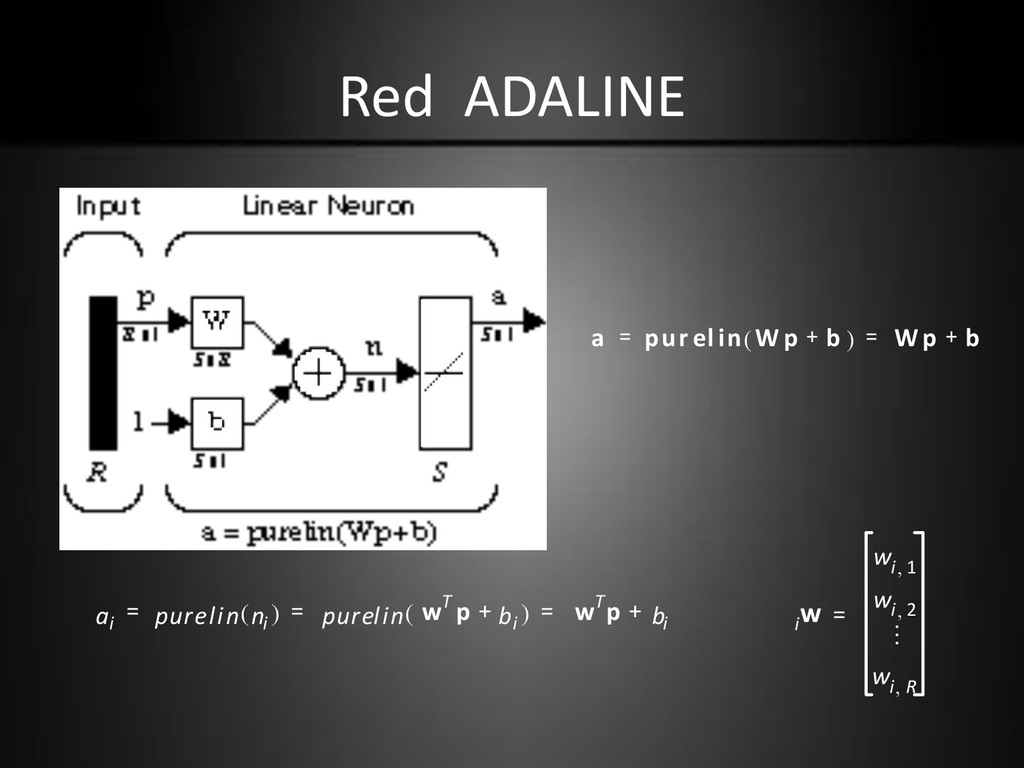
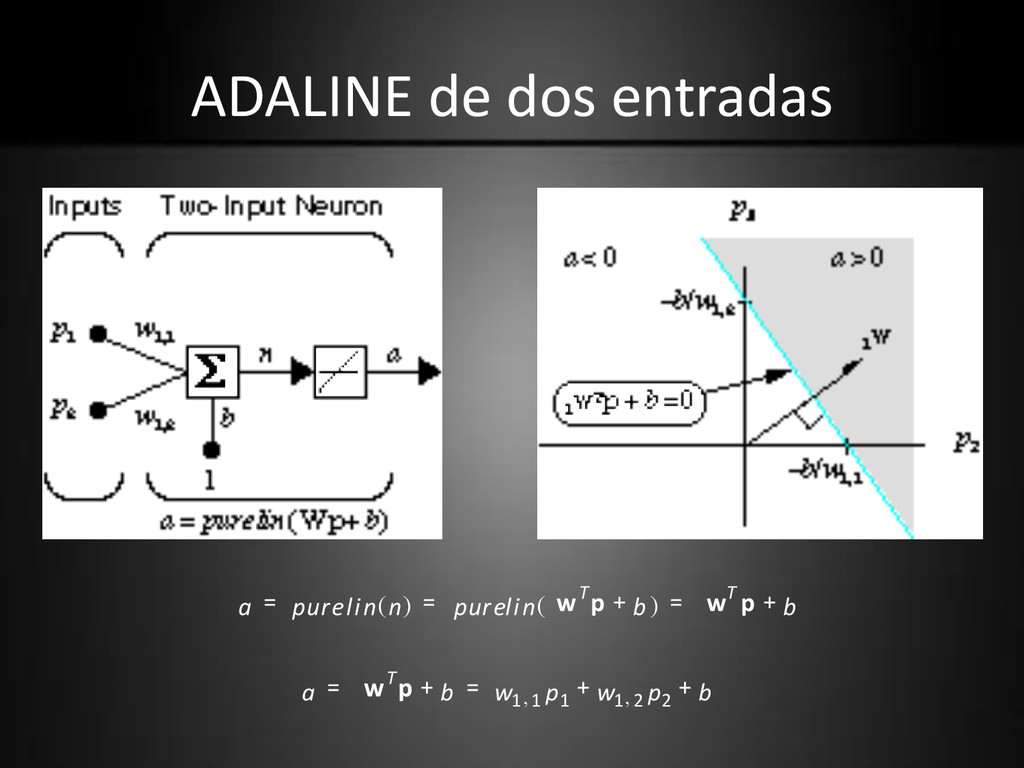
excepto que su función de transferencia es linear, en vez de escalón. • Tanto el ADALINE como el perceptron sufren de la misma limitación: solo pueden resolver problemas linealmente separables.
• El algoritmo LMS es más poderoso que la regla de aprendizaje del Perceptron. • El algoritmo LMS ha encontrado muchos más usos que la regla de aprendizaje del perceptron. En esencia en el área del procesamiento digital de señales.
PERCEPTRON ADALINE Función de Transferencia ESCALON LINEAL Resolución de problemas Linealmente Separables Linealmente Separables Comportamiento con respecto al RUIDO Sensible al Ruido Minimiza el Ruido Algoritmo de aprendizaje Regla de aprendizaje Del Perceptron LMS
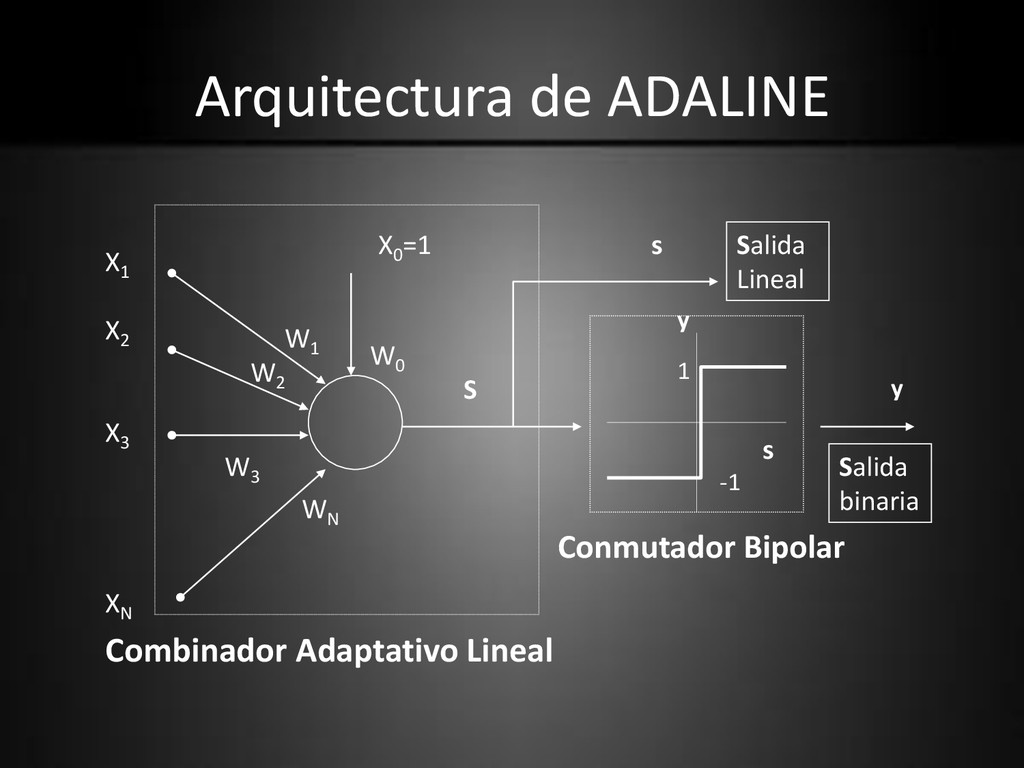
Adaptativo Lineal (ALC). • La salida lineal obtenida del ALC se aplica a un Conmutador Bipolar. • El Umbral de la F. de T. se representa a través de una conexión ficticia de peso Wo (b)
(LMS). LMS trata de minimizar una diferencia entre el valor obtenido y el deseado; como en el PERCEPTRON, sólo que ahora la salida considerada es la salida obtenida al aplicar una función de activación lineal.
adaptar los pesos a medida que se vayan presentando los patrones de entrenamiento y salidas deseadas para cada uno de ellos. Para cada combinación E/S se realiza un proceso automático de pequeños ajustes en los valores de los pesos hasta que se obtienen las salidas correctas.
Donde : l max: es el eigenvalor más grande de la matriz Hessiana R W k 1 + ( ) W k ( ) 2 a e k ( ) p T k ( ) + = b k 1 + ( ) b k ( ) 2 a e k ( ) + = R E p p T [ ] 1 2 - - - p 1 p 1 T 1 2 - - - p 2 p 2 T + = = a es la velocidad de aprendizaje determinada por 0 a 1 l m a x < <
de entrada P. 2. Se obtiene la salida del ALC y se calcula la diferencia con respecto a la deseada (error). 3. Se actualizan los pesos. 4. Se repiten pasos 1 a 3 con todos los vectores de entrada. 5. Si el Error es un valor aceptable, detenerse, si no repetir algoritmo.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}