una neurona biológica del cerebro por Mc Culloch & Pitts – En principio las redes neuronales artificiales podrían computar cualquier función aritmética o lógica. – La red de McCulloch y Pitts no podían aprender. • 1949 Hebb propone una ley de aprendizaje que explicaba como una red de neuronas aprendía
en hardware para reconocimiento de caracteres – Rosenblatt diseño el perceptron con vista a explicar y modelar las habilidades de reconocimientos de patrones de los sistemas visuales biológicos • 1958 Rosenblatt se acredita con el algoritmo de aprendizaje del perceptron
• El famoso problema de la “XOR”. • 1974-1986 Diferentes personas resuelven los problemas del perceptron: • Algoritmos para entrenar perceptrones multicapa feedforward. • Back-propagation del error (Rumelhart et al 1986).
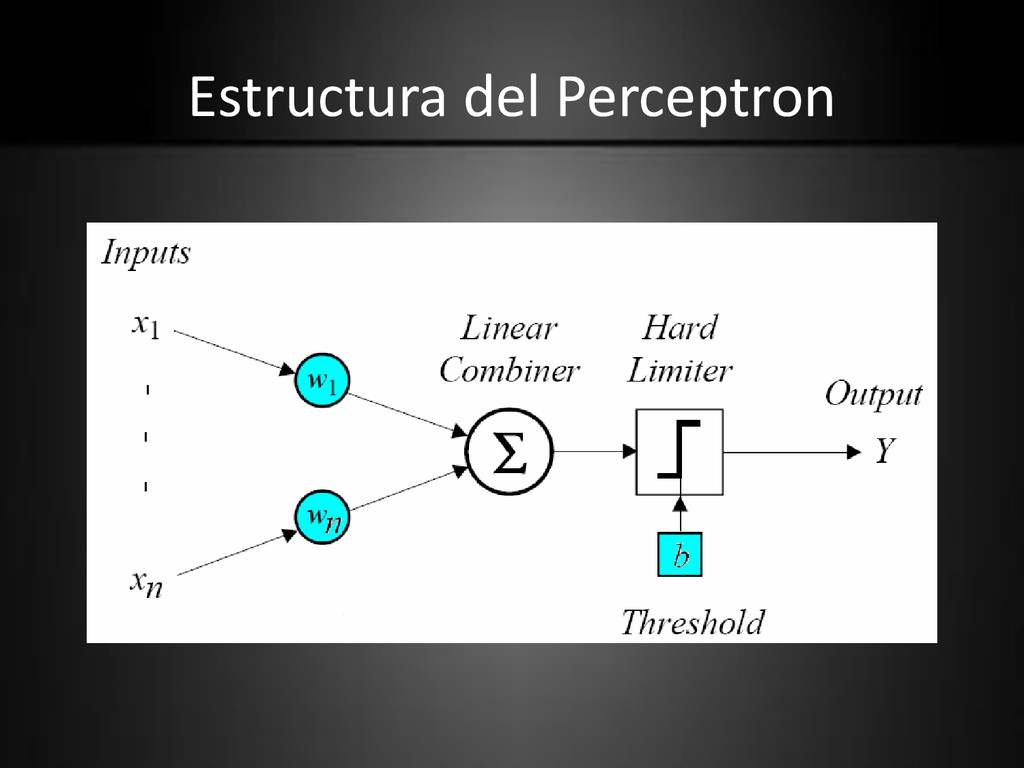
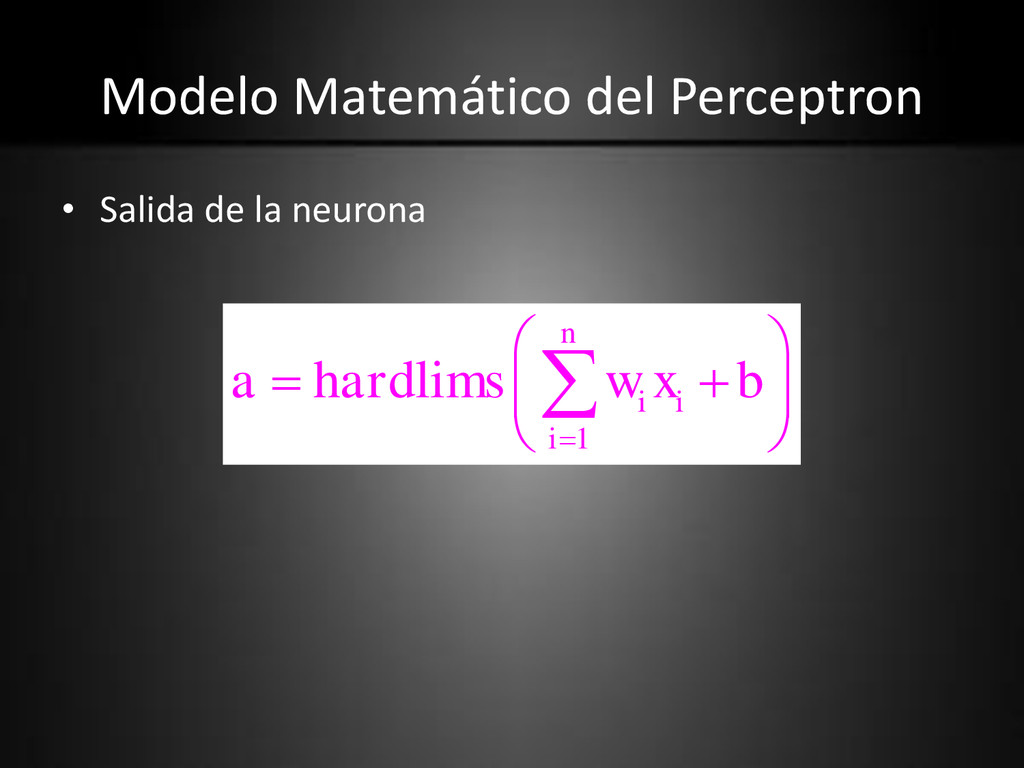
vector x. • wi es un peso modificable asociado con la señal de entrada xi . • La suma pesada de las entradas se aplica al hard limiter, con un valor umbral b.
se aplica al hard limiter, el cual produce una salida igual a • +1 si su entrada es positiva • -1 si es negativa. • El hard limiter es, entonces 0 x if 1 ) x ( step otherwise 1 0 x if 1 ) x sgn(
sgn(x): la funcion signo, o, hardlims(x) – step(x): la funcion paso, or, hardlim(x) otherwise 0 0 x if 1 ) x ( step otherwise 1 0 x if 1 ) x sgn(
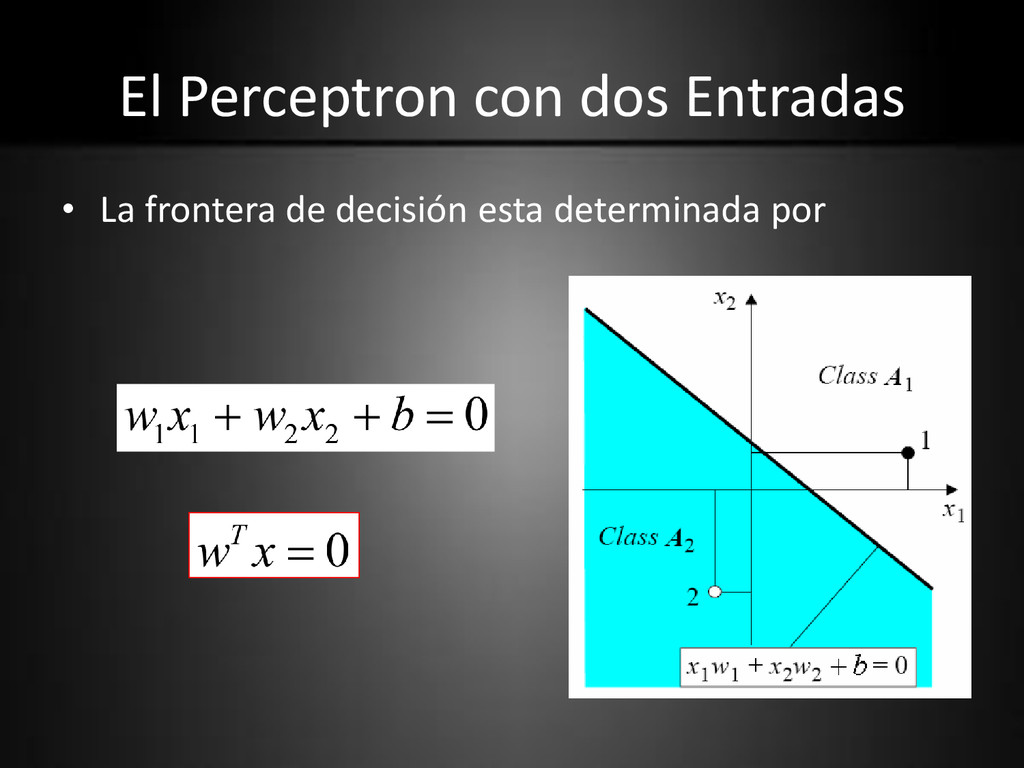
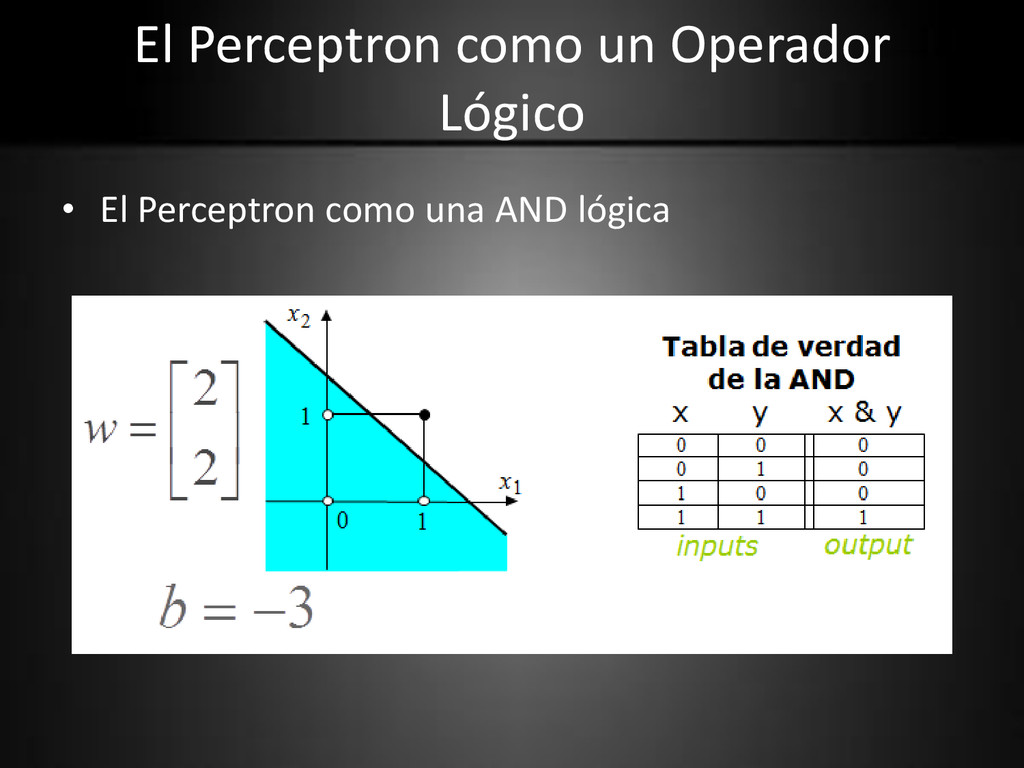
propósito del perceptron es clasificar las entradas, x1, x2, . . ., xn, en una de dos clases, digamos A1 y A2. • Los patrones de entrada pertenecen a una de dos clases. Esto solo puede suceder cuando ellos son linealmente separables
entendemos un procedimiento para modificar los pesos de una red. • El propósito de la regla de aprendizaje es entrenar la red para que ejecute una tarea. Este procedimiento se denomina también algoritmo de entrenamiento
se usa para ajustar los pesos de la red para mover las salidas de la red hacia las salidas correctas (targets). Wnew = Wold + ΔW Wnew: Pesos actualizados Wold: Pesos iniciales Los pesos se ajustan de acuerdo al error
– dk ).xk W(n+1) = wn + η(tn – dn).zn • w(n+1) es el vector de pesos que se usará para el siguiente patrón. • w(n) es el vector de pesos actual. • η es un escalar llamado razón de aprendizaje, el cual es un valor positivo entre cero y uno y se fija de antemano por uno. • t(n) es la salida esperada, o sea, si el patrón fue clasificado previamente como de la clase 0, t(n) sería 0. • d(n) es la salida dada por la Red, o sea, el 0 o 1 con el que clasificó al patrón. • z(n) es el vector del patrón aumentado, es decir, el vector del patrón con el elemento 1 del bias.
valores aleatorios. 2. Iterar por el conjunto de entrenamiento, comparando la salida de la red con la salida deseada para cada ejemplo. 3. Si todos los ejemplos son clasificados correctamente, PARAR. 4. Si no, actualizar los pesos para cada ejemplo incorrect: Si salida = -1, pero deberia ser 1 Si salida = 1 pero deberia ser -1 5. Volver al PASO 2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}