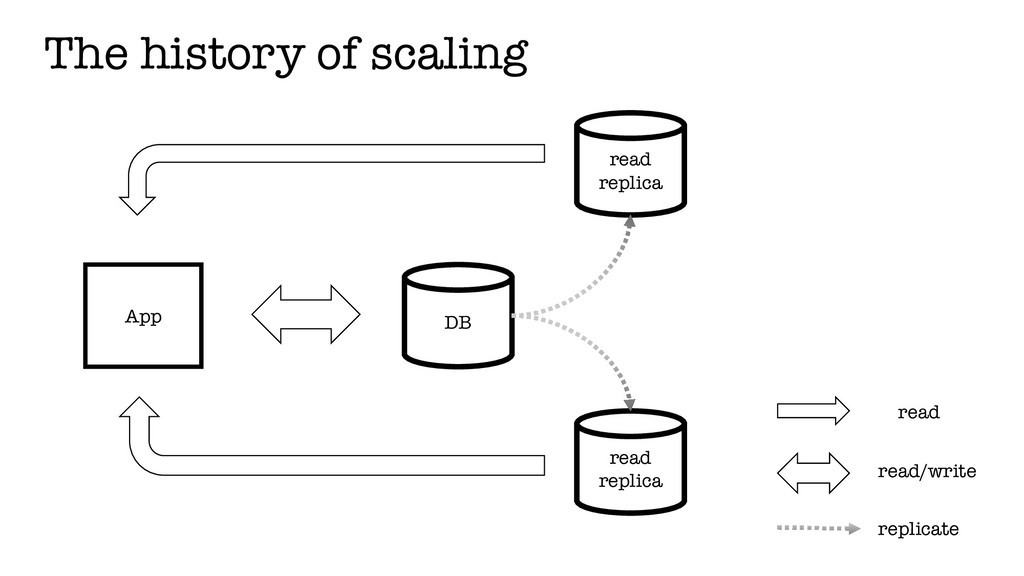
During the last decade, Internet companies have achieved unprecedented growth. As a result of this, their systems needed to cope with workloads they had never experienced before. The existing data storage technologies were not capable of supporting these workloads, because of inherent limitations, such as single point of failures, vertical scaling etc.
In an effort to solve these problems, companies started re-evaluating the architecture of existing systems and started building a new generation of systems, focused on a more distributed, scalable and highly available architecture. Of course, this came with a whole new set of technical challenges that they needed to address.
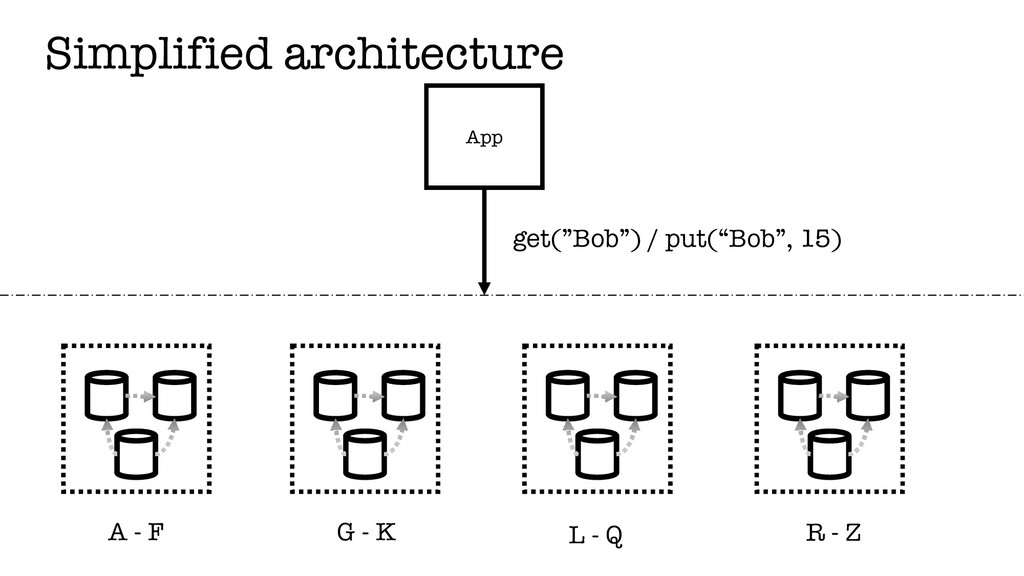
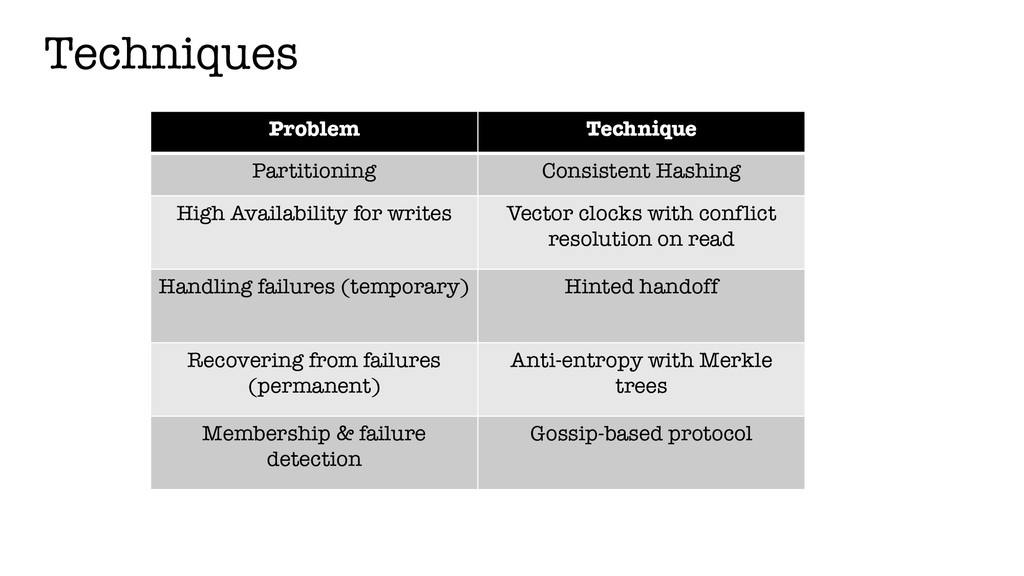
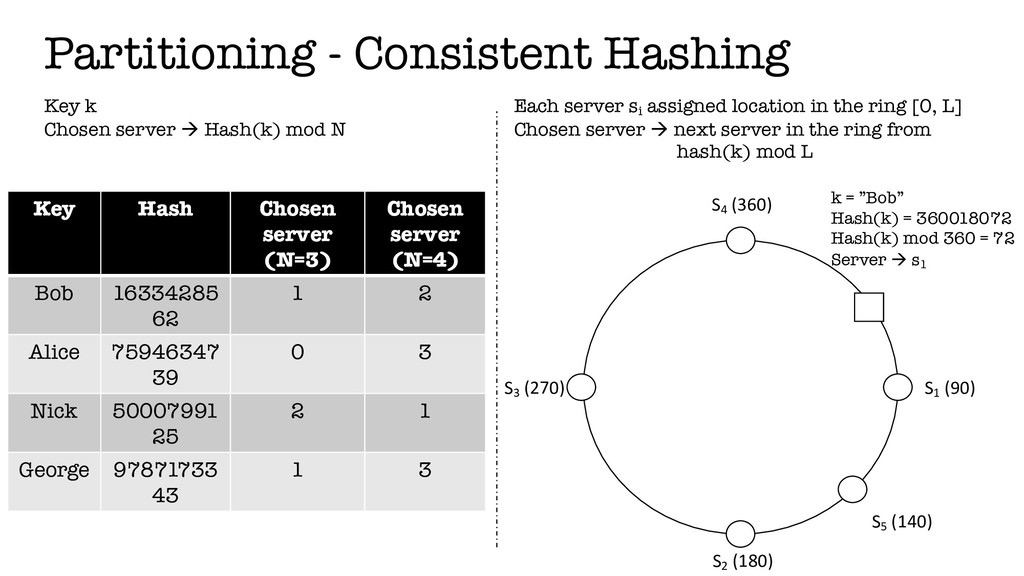
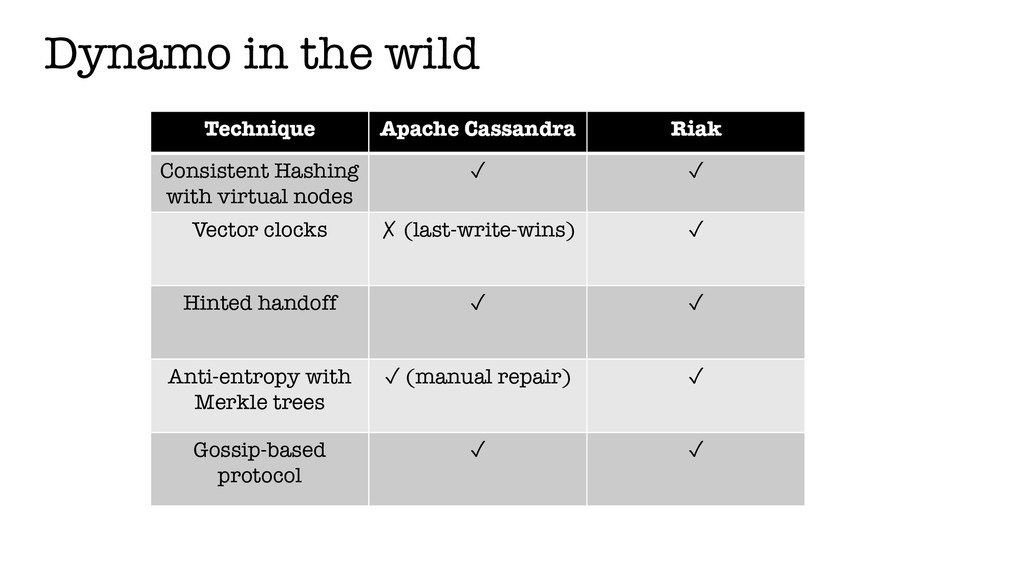
In this talk, we will be looking at a set of core techniques Amazon used to build their key-value store, referred to as Dynamo in the related paper. We will explain what are the problems they had to address and how these techniques helped them.
Given that this was amongst the seminal papers in the space of distributed systems, we will also visit some examples of open-source systems that leveraged some of these techniques.
![Dynamo: Amazon’s Highly Available Key-value store Dimos Raptis @dimor7 [email protected]](https://files.speakerdeck.com/presentations/d68d27b9bbf34ba09037f97169d8aadb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Dimos Raptis @dimor7 [email protected] Papers We Love (London)](https://files.speakerdeck.com/presentations/d68d27b9bbf34ba09037f97169d8aadb/slide_11.jpg){kind=link}