An exploration of FP in Ruby, going through some basic concepts and culminating in their application as Gary Bernhardt's "Functional Core, Imperative Shell".
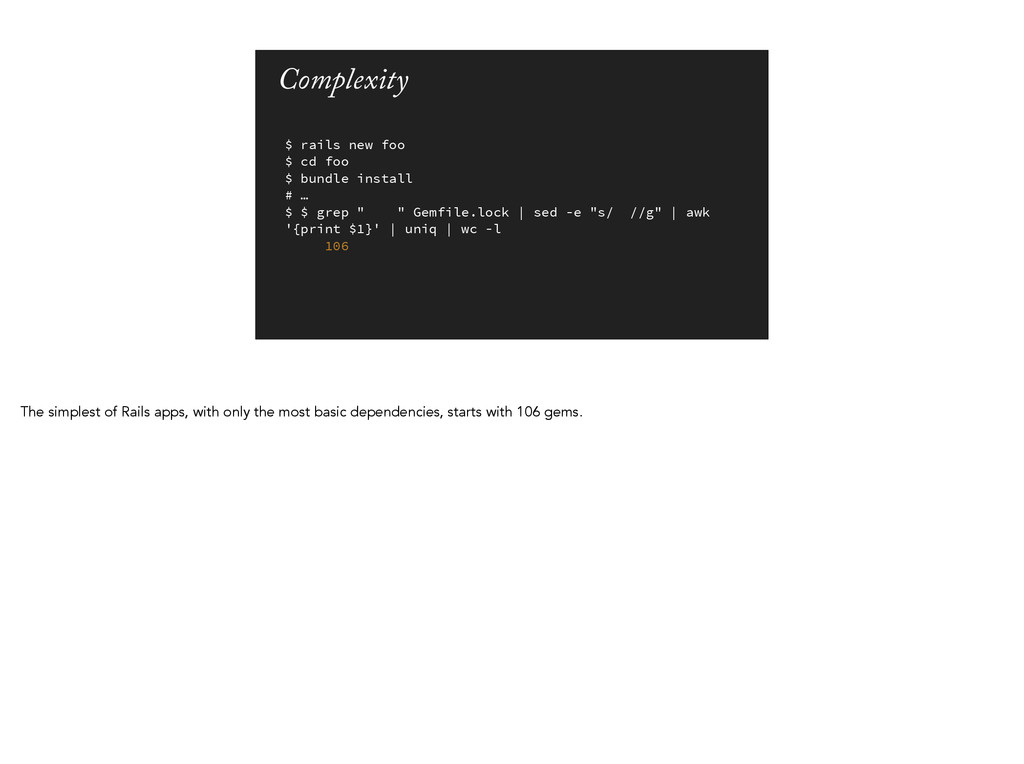
install # … $ $ grep " " Gemfile.lock | sed -e "s/ //g" | awk '{print $1}' | uniq | wc -l 106 The simplest of Rails apps, with only the most basic dependencies, starts with 106 gems.
can go wrong. It can go wrong in your code, or two layers deep, or even ten layers deep. It can go wrong in your network, it can go wrong in your disk. Considering how much CAN and DOES go wrong, maybe we should really think about our challenges and try new approaches. We’ve had OO as an industry-wide practice for a little over twenty years, and, frankly, things are not getting better — in fact, they’re very messed up right now.
way ahead. I remember reading about Futures in a paper about implementing them Haskell in 2004. That’s 10 years ago. 10 years ago, they were already over 20 years old. Only now Futures are sort of commonplace.
industry, it’s pretty clear we’re moving there. Haskell is getting industry use, Clojure and Scala are everywhere, Functional Reactive Programming is already a thing in JS-land (with Ember and friends).
.first(10) def fetch_friends(user) -> { FriendGraph.for(user) } end ! uwg = all_users.map { |user| [user, fetch_friends(user)] } ! # Need the graph of the first 3 uwg[0..2] .map { |_, graph| graph.() } Taking functions Producing functions and Not really there in Ruby. We take blocks in, but can’t return something indistinguishable from other calls. Also, procs vs blocks vs lambdas make for weird semantics (“is it return, next or break?”, “where am I exiting to?”).
= @group.map(&:age) .inject(0.0, :+) sum / @group.size end def average_age(group) return 0 if group.empty? ! sum = group.map(&:age) .inject(0.0, :+) sum / group.size end vs. Stateful Stateless
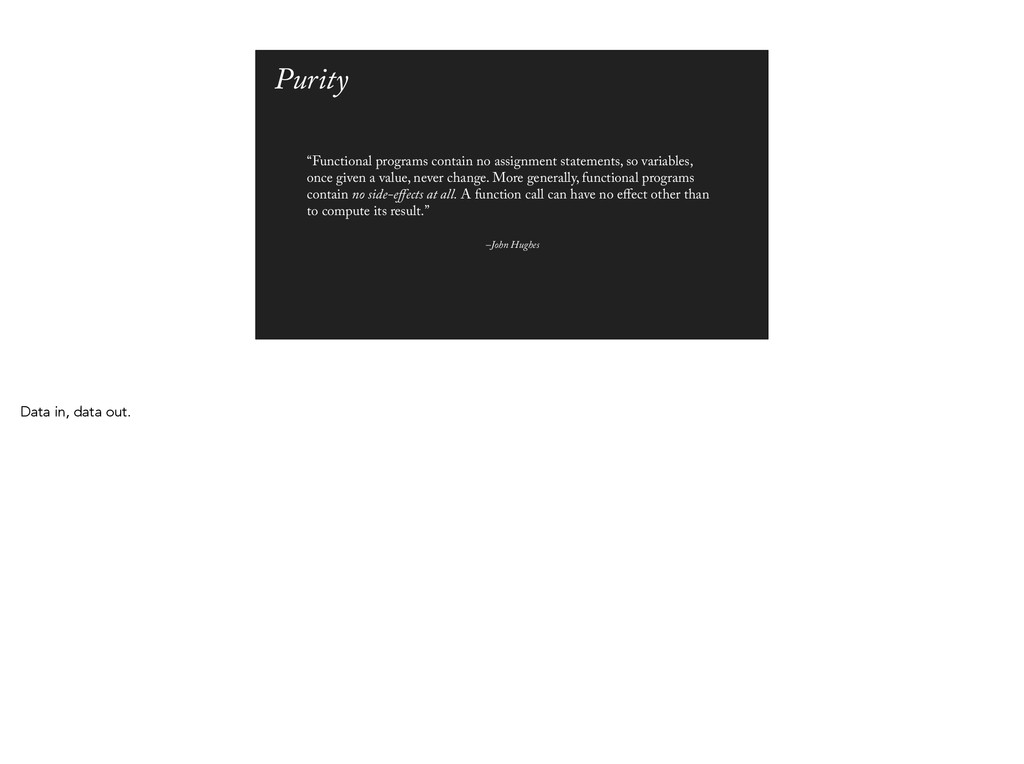
once given a value, never change. More generally, functional programs contain no side-effects at all. A function call can have no effect other than to compute its result.” Purity Data in, data out.
while i < list.size new_list[i] = list[i] + 3 i += 1 end ! new_list end def add_three(list, acc = []) if list.empty? acc else new_value = list[0] + 3 add_three(list[1..-1], acc + [new_value]) end end Imperative Recursive vs. If you don’t change state, you can’t loop. Loops rely on state changing to reach a terminal condition. A recursive function must also define its termination condition, but implements it using immutable values rather than a control variable. It calls itself again, always moving closer to its termination. FPs usually implement tail-recursion elimination, which avoids the creation of new stack frames, thus running the function in constant space. Ruby doesn’t, so deep recursive functions will result in a SystemStackError.
# => [1, 2, 3] list = [1, 2, 3, 4].immutable new_list = list.delete(4) new_list # => [1, 2, 3] list # => [1, 2, 3, 4] Mutable Immutable vs. The Ship of Theseus — how FP sidesteps the question of identity by not letting anything be changed. On the right, fake Ruby syntax to show the differences between a mutable and an immutable API.
send_email(from: user, to: f) end end end ! maybe_email_friends(user, FriendGraph.for(user)) def maybe_email_friends(user, lazy_friends) if user.ready? friends = lazy_friends.() friends.map { |f| send_email(from: user, to: f) } end end ! maybe_email_friends(user, -> { FriendGraph.for(user) }) Strict Lazy Consider the possibility of us needing to send email to a User’s friends, fetched with a very expensive call to an external service. If the email is only sent when the user is ready, we may have wasted a lot of time waiting for something we’ll never use. Laziness is a property of some languages (like Haskell) that takes care of only computing results when you actually need them.
do |shape| if shape.color == color with_color << color end end ! with_color end def filter_by_color(shapes, color) shapes.select { |shape| shape.color == color } end vs. FP is declarative in nature. Left, we tell what the computer needs to hear bit by bit so it can do what we want; right, we tell it what we want. This makes programs a lot clearer, and opens up a lot of space for compiler and runtime smarts.
= Person.find_by!(name: “Bob”) joe = Person.find_by!(name: “Joe”) ! transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) ! # => Transfer(12345) Not-so-happy path bob = Person.find_by!(name: “Bob”) joe = Person.find_by!(name: “Joe”) ! transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) ! # => StandardError: … vs. Monads are another more modern FP formulation. They're feared because they’re sold as this otherworldly, Math-y thing that requires a thousand different analogies and tutorials to grasp. As I understand them, they are in essence a way to safely sequence operations, allowing us to build sturdier programs. Let’s see how they can be useful. ! In this example, we have a bank transfer from Bob to Joe. In the happy path, all goes well; in the not-so-happy, fetching Joe from the database throws an exception. In these cases, we want to log what exactly went wrong, so having an exception blow up on our faces is not what we really should get.
Person.find_by(name: “Joe”) ! if bob && joe transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) end ! # => Transfer(12345) A B C D New requirements A B C D E F D1 D2 F1 F2 㱺 We resort then to using a non-exceptional find_by and if, logging which find_by failed. However, we’ve increased our complexity a little bit with branching. It all feels fine until we need to implement transfers between more accounts, themselves with their own nested operations and a bunch of stuff that would require a lot more branching and tracking. How can we both make the program easier to write and communicate problems better?
and def find_by_name(foo) p = Person.find_by(name: foo) p ? Some(p) : None end ! find_by_name(“Bob”).flat_map { |bob| find_by_name(“Joe”).map { |joe| transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) } } ! # => Some(Transfer(12345)) def find_by_name(foo) p = Person.find_by(name: foo) p ? Some(p) : None end ! find_by_name(“Bob”).flat_map { |bob| find_by_name(“Joe”).map { |joe| transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) } } ! # => None Maybe is a monad that can either hold a value (Just/Some(value)) or no value (Nothing/None). By formalizing these two possibilities and following monadic laws I’m glossing over here, we can use them for sequencing. Whenever a sequence finds a None, it returns that None. If it’s Some, things progress nicely. ! We change our program and make transfer take Option as inputs, and also make it return an Option with the Transfer or None if it never happened. The let you know if you actually have values or not.
|bob| find_by_name(“Joe”).map { |joe| find_by_name(“Sam”).map { |sam| transfer(from: bob, to: joe, amount: 10000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) transfer(from: joe, to: sam, amount: 5000) log(“Transferred 10000 from #{bob.name} to #{joe.name}”) } } } ! # => Some(Transfer(98765)) accounts = %w(Joe Sam Jack Jill Alice Lee) ! accounts.inject(find_by_name(“Bob”)) { |from, to_name| to_opt = find_by_name(to_name) from.flat_map { |f| to_opt.map { |t| transfer(from: f, to: t, amount: 10000) log(“Transferred 10000 from #{f.name} to #{t.name}”) } } ! to_opt } This makes adding a third account easy. You just add it to the sequence and use it in your computation. Actually, since Monads make sequencing easy, adding an arbitrary number of accounts is fine.
= do bob <- findByName(“Bob”) joe <- findByName(“Joe”) return transfer bob joe 10000 val transfer = for { bob <- findByName(“Bob”) joe <- findByName(“Joe”) } yield transfer(bob, joe, 10000) and It feels a little weird, though, to do all that nesting. You trade cyclomatic complexity for crappy readability. ! Haskell, Scala, F# and other languages provide a convenient syntax for chaining Monads. Ruby doesn't have that, which means…
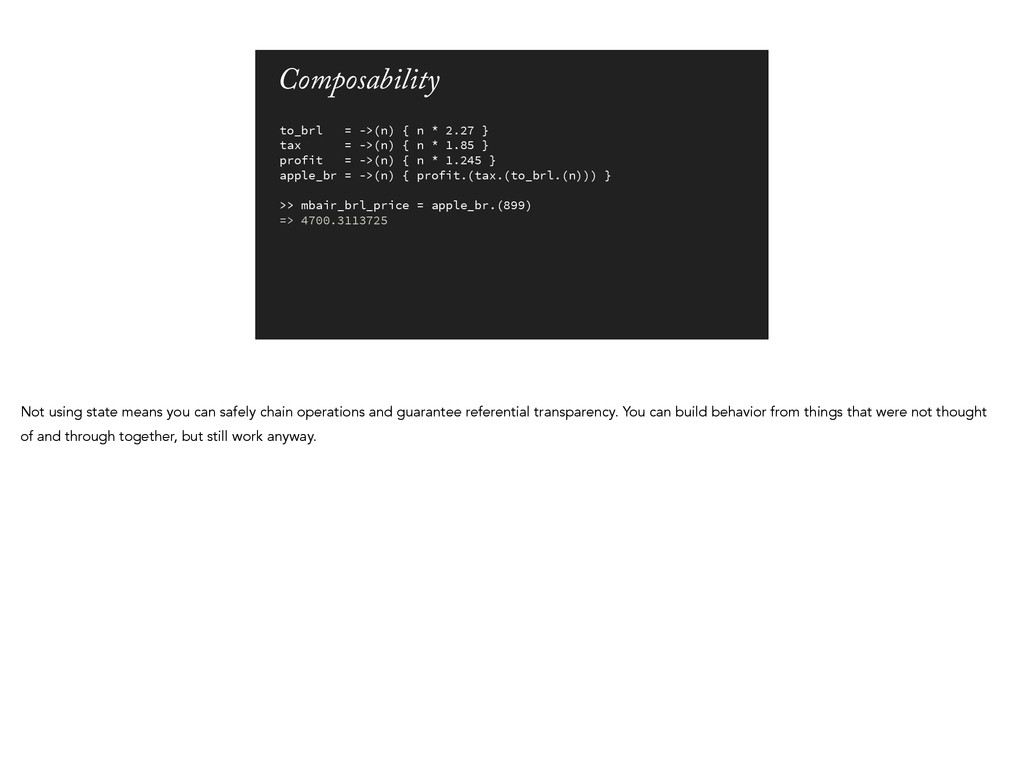
= ->(n) { n * 1.85 } profit = ->(n) { n * 1.245 } apple_br = ->(n) { profit.(tax.(to_brl.(n))) } ! >> mbair_brl_price = apple_br.(899) => 4700.3113725 Not using state means you can safely chain operations and guarantee referential transparency. You can build behavior from things that were not thought of and through together, but still work anyway.
do list += (0..999).map { |i| i * rand } end } ! threads.each(&:join) puts list.size ! # 3000, 6000, 4000 vs. Unsafe threads = 10.times.map { Thread.new { (0..999).map { |i| i * rand } } } ! list = threads.each(&:join) .map(&:value).flatten puts list.size ! # 10000 Safe Being immutable and declarative makes functional programs easily parallelizable. Using the imperative style on the left, we must lock list, lest we want to see different results at every run. On the right, it all works out beautifully.
user.start_dancing end end end end ! class User < ActiveRecord::Base def start_dancing update_attributes! dancing: true end end class Gym def jazzercise(users) users .select(:in_tights?) .map(:start_dancing) end end ! class User < Struct.new(:in_tights, :dancing) def start_dancing User.new(in_tights, true) end ! def in_tights?; in_tights; end end vs. Low High On the left: side effects (each, method dispatch, database access). On the right, new values, maps. Which is easier to test?
of lambdas and monads and whatnot would be very scary, unfamiliar, and you would revolt with hate for whomever used those things. You may even call them shitty programmers. ! Except, if you watch closely, you actually do work with codebases that have those properties all the time and don’t even blink.
words = %w(ace mace lace face) words .select { |w| w.end_with?(“ace”) } .select { |w| w =~ /\A(m|f)/ } .map(&:reverse) ! # => [“ecam”, “ecaf”] ! ages = { “Bob” => 10, “Jack” => 40 } oldies = ages.select { |_, v| v > 35 } ! # => { “Jack” => 40 } joe = Person.find_by(name: “Joe”) bob = Person.find_by(name: “Bob”) ! transfer = joe.try do |j| bob.try do |b| transfer(from: j, to: b, amount: 10000) end end ! transfer.try(:id) # => nil and Look at these examples, for instance. You can safely combine sequences of operations on Hash and Array without having your code blow up. If you look at their interfaces, you’ll even see map and flat_map! Isn’t that interesting? And don’t we actually use that stuff? ! And what about “try”? It’s part of our daily lives AND gives us some of the same benefits the Maybe monad does (albeit not in a composable manner). ! Considering we do adopt some FP concepts, even if unknowingly, is there more we can do?
SOLID (oh so punny)? Is it the right approach to solve problems? Isn’t OOP just a layer of abstractions over good old imperative programming? After all, we still program by dictating a sequence of steps.
class UserStats < Struct.new(:users) def above_average average = average_age users.select { |u| u.age > average } end ! def average_age return 0.0 if users.empty? ! sum_ages = users.map(&:age) .inject(0.0, :+) sum_ages / users.size end end
[] ! User.all.each do |user| report_rows << [user.name, average_time_on_site(user)] end ! report_rows end ! def average_time_on_site sessions = user.sessions sessions.map(&:length).sum / sessions.length end end ! class User < ActiveRecord::Base; has_many :sessions; end class Session < ActiveRecord::Base belongs_to :user def length; ended_at - started_at; end end ! describe UsageReport do let(:user1) { FactoryGirl.create(:user) } let(:user2) { FactoryGirl.create(:user) } ! subject { UsageReport.new } ! before do now = Time.now user1.sessions.create(started_at: now - 1.hour, ended_at: now) user2.sessions.create(started_at: now - 2.hours, ended_at: now - 90.minutes) user2.sessions.create(started_at: now - 2.hours, ended_at: now - 90.minutes) end ! it “has a row per User” do rows = UsageReport.build expect(rows).to have(2).items expect(rows.first.last).to eq(3600.0) expect(rows.last.last).to eq(2700.0) end end We have a class that builds a Report from User’s on the system and their Session lengths (the time they spend online). Its test requires a lot of setup to exercise the actual logic.
double(“user1”, sessions: [double(length: 3600.0)]) } let(:user2) { double(“user2”, sessions: [double(length: 3600.0), double(length: 1800.0)]) } let(:users) { [user1, user2] } ! subject { UsageReport.new(repository) } ! before do repository.should_receive(:all).and_return users end ! it “has a row per User” do rows = UsageReport.build expect(rows).to have(2).items expect(rows.first.last).to eq(3600.0) expect(rows.last.last).to eq(2700.0) end end class UsageReport def initialize(repository = User) @repository = repository end ! private :repository ! def build report_rows = [] ! repository.all.each do |user| report_rows << [user.name, average_time_on_site(user)] end ! report_rows end # … end ! # … and So we introduce our friend DI to separate the boundaries and add mocks. Awful mocks, nested mocks, that don’t make the test any clearer, but isolate us from the DB. The mocks must know the object structure and those magic numbers. WTF is 3600?
{ Time.new(2014, 6, 21, 10) } let(:sessions) { [Core::UserSession.new( ref_time - 2.hours, ref_time - 1.hour), Core::UserSession.new( ref_time - 1.hour, ref_time)] } ! describe “.average_time_on_site” do it do expect(subject.average_time_on_site(sessions)) .to eq (3600.0) end end end class Core::UserSession def initialize(started_at, ended_at) @started_at = started_at @ended_at = ended_at end ! def length @ended_at - @started_at end end ! module Core::SessionStats def self.average_time_on_site(sessions) sessions = sessions sessions.map(&:length).sum / sessions.length end end and So we’ll do what we must for our sanity: separate it into a Functional Core and an Imperative Shell. We’ll start by creating an immutable UserSession and moving the Stats logic to a module. The test doesn’t need any mocks, then. Values are values are values, and it’s all referentially transparent. And you’re always sure the methods you’re calling exist! No need for rspec-fire and the like.
Core::UsageReport do let(:ref_time) { Time.new(2014, 6, 21, 10) } let(:users_with_sessions) { [Core::User.new(“Joe”) .add_session(ref_time - 2.hours, ref_time - 1.hour) .add_session(ref_time - 30.minutes, ref_time), Core::User.new(“Jane”) .add_session(ref_time - 2.hours, ref_time - 1.hour)] } ! describe “.build” do it do rows = subject.build(users_with_sessions) expect(rows.first.last).to eq(2700.0) expect(rows.last.last).to eq(3600.0) end end end class Core::User def initialize(name, sessions = []) @name = name @sessions = sessions end ! attr_reader :name, :sessions ! def add_session(started_at, ended_at) User.new(name, sessions + [UserSession.new(started_at, ended_at)]) end end ! module Core::UsageReport def self.build(users_with_sessions) users_with_sessions.map { |user| [user.name, SessionStats.average_time_on_site(user.sessions)] } end end and We do the same for User and the UsageReport itself. Again, we can skip mocking. It’s interesting to notice how much the widespread use of DI in Ruby is about isolating boundaries for testing. In that sense, DHH has a point (although I disagree viscerally about the usefulness of TDD). It’s a useful tool for when your design may need customization or extension, but here we show that we can have fast tests and ted without resorting to DI or test doubles.
core_users = User.all.map { |user| core_user = Core::User.new(user.name) user.sessions.inject(core_user) { |uws, s| uws.add_session(s.started_at, ended_at) } } ! Core::UsageReport.build(core_users) end end and describe UsageReport do let!(:user) { FactoryGirl.create(:user, :with_session) } ! subject { UsageReport.new } ! it “has a row per User” do rows = subject.build expect(rows).to have(1).item end end And finally we get to the Imperative Shell. It fetches the Users from the DB and converts them into Core::Users, adding their sessions. It then just calls our purely functional Core::UsageReport. The test just verifies that it does fetch from the DB, but there’s no need to test WHAT it built (unless, of course, there’s something complex there).
and foremost, Ruby isn’t immutable. You have to write in that style, UNLESS you freeze everything you touch (you’ll forget to do it, and performance will suffer). Second, there’s an initial overhead for the team: the style must be explained and enforced. Nothing in Ruby proper will help you.
collections • Use Values (https://github.com/tcrayford/Values) for immutable objects • Use Virtus (https://github.com/solnic/virtus) for immutable objects • Use Rumonade (https://github.com/ms-ati/rumonade) if you want Monads • Use Enumerator::Lazy for lazy arrays and stream operations Here are some ways to alleviate those problems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Recursion def add_three(list) new_list = [] i = 0 !](https://files.speakerdeck.com/presentations/77fedf60ddbf0131b761266a7d836638/slide_25.jpg){kind=link}
![Immutability list = [1, 2, 3, 4] list.delete 4 list](https://files.speakerdeck.com/presentations/77fedf60ddbf0131b761266a7d836638/slide_26.jpg){kind=link}
{kind=link}
![Intent Imperative Declarative def filter_by_color(shapes, color) with_color = [] shapes.each](https://files.speakerdeck.com/presentations/77fedf60ddbf0131b761266a7d836638/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Parallelizability list = [] ! threads = 10.times.map { Thread.new](https://files.speakerdeck.com/presentations/77fedf60ddbf0131b761266a7d836638/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}