Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20250614_LT_走れメロスの個人情報マスク処理をMacStudio 512GBメモリマ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
NobuakiOshiro
PRO
June 13, 2025
Technology
39
1
Share
20250614_LT_走れメロスの個人情報マスク処理をMacStudio 512GBメモリマシンで試してみた
https://agifukuoka.connpass.com/event/352826/
NobuakiOshiro
PRO
June 13, 2025
More Decks by NobuakiOshiro
See All by NobuakiOshiro
20260601_中東情勢1週間差分update
doradora09
PRO
0
15
20260602_中東情勢と物流_3か月振り返り_10枚圧縮版_最新版
doradora09
PRO
0
19
伊藤さん_発表スライド_全業種x各国_20260602
doradora09
PRO
0
8
20260528_生成AIを専属DSに_Howの次にすべきことを考える
doradora09
PRO
0
260
20260527_準悲観シナリオ_v2_価格高騰見込み
doradora09
PRO
0
49
20260527_ホルムズ制約長期化シナリオ(準悲観シナリオ)
doradora09
PRO
0
52
20260527_先週差分_今後調査予定_サマリ
doradora09
PRO
0
43
20260519_NOBDATA_企業決算から読む中東情勢
doradora09
PRO
0
58
20260519_NOBDATA_中東情勢ウィークリーモニタリング
doradora09
PRO
0
33
Other Decks in Technology
See All in Technology
はじめてのDatadog
kairim0
0
220
OpenClawとHermesAgentでAI新入社員を作った話
takanoriyanada
0
140
Amazon CloudFrontにおけるAIボットアクセス制御のポイント
kizawa2020
5
310
速さだけじゃない! VoidZero ツールが移行先に選ばれる理由
mizdra
PRO
6
680
AI フレンドリーなエラー監視を TypeScript で実現する
shinyaigeek
2
190
Platform engineering for developers, architects & the rest of us (AI agents)
danielbryantuk
0
140
最低限これだけ押さえれ大丈夫_Claude Enterprise/Team企業展開ガバナンス入門
tkikuchi
1
540
ITエンジニアを取り巻く環境とキャリアパス / A career path for Japanese IT engineers
takatama
4
1.8k
JJUG CCC 2026 Spring AI時代の開発こそ標準化を武器に! ― 方式・プロセス・プラットフォームの標準化
s27watanabe
2
620
A Harness for Behaviour: how to get AI to generate code that does what we intend, or "TDD in the age of AI"
xpmatteo
1
510
サプライチェーンセキュリティの空白地帯 - 信頼できる”依存性”の未来を考える
rung
PRO
1
460
Strands Agents超入門
kintotechdev
1
140
Featured
See All Featured
HDC tutorial
michielstock
2
680
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
180
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
70
39k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.5k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
140
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
460
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
122
22k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
270
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
The Pragmatic Product Professional
lauravandoore
37
7.3k
Transcript
LT : 「⾛れメロス」の 個⼈情報マスク処理を Mac Studio 512GBメモリ マシンで試してみた 2025/6/14 @doradora09
Mac Studio 512GBメモリマシン • メモリ512GBまでマ シましにできるポー タブルPC(4kg) • LLMの⼤きいモデル が動くので今回実験
利⽤
Mac Studio 512GBメモリマシン • ちなみにスペック増 し増しにすると200万 を超えます・・ • ( 3台買ったらカード
を⽌められたのは良 い?思い出・・ )
閑話休題:⾛れメロス • ⻘空⽂庫で全⽂公開されてます • https://www.aozora.gr.jp/cards/000035/files/1567_14913.html • ローカルLLMで「メロス」や「セリヌンティウス」などの名称をマス クしたい -> これができれば、社内でいろんなデータをLLMに⾷わせて処理できる
-> また、マスク後データを外部のさらに性能の良いAPIに投げて分析させるとか もできて良さげ • 現時点での結論 • Mac Studio 512GBならいけそう • 128GBメモリのMac Boop Proだと厳しいかも?
原⽂ • だいたい1万⽂ 字くらいの物語
LM StudioでLlama-4を動かす • Mavericのモデルは230GBくらい容量あるのでダウンロードの 帯域とか注意( スマホテザリングではやらない⽅が吉・・ ) • メモリ使⽤量はこんな感じ
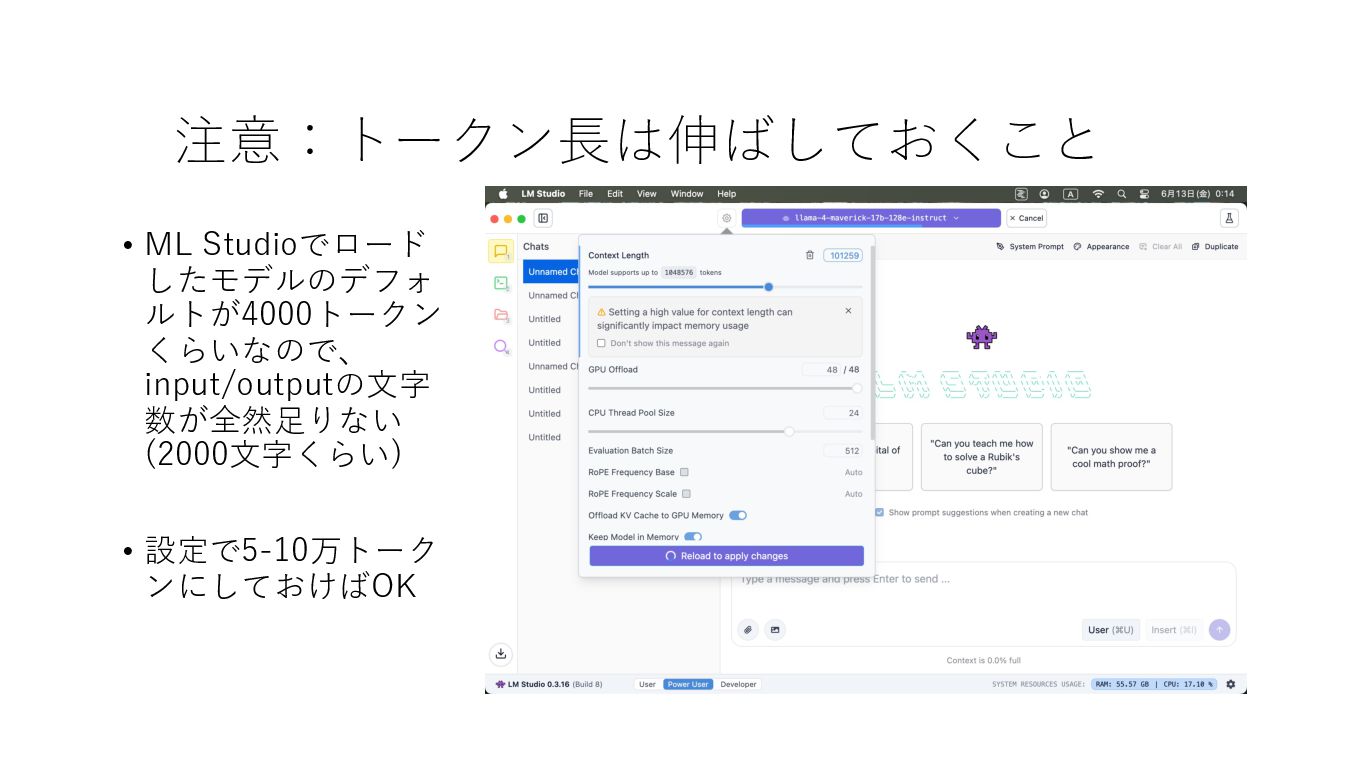
注意:トークン⻑は伸ばしておくこと • ML Studioでロード したモデルのデフォ ルトが4000トークン くらいなので、 input/outputの⽂字 数が全然⾜りない (2000⽂字くらい)
• 設定で5-10万トーク ンにしておけばOK
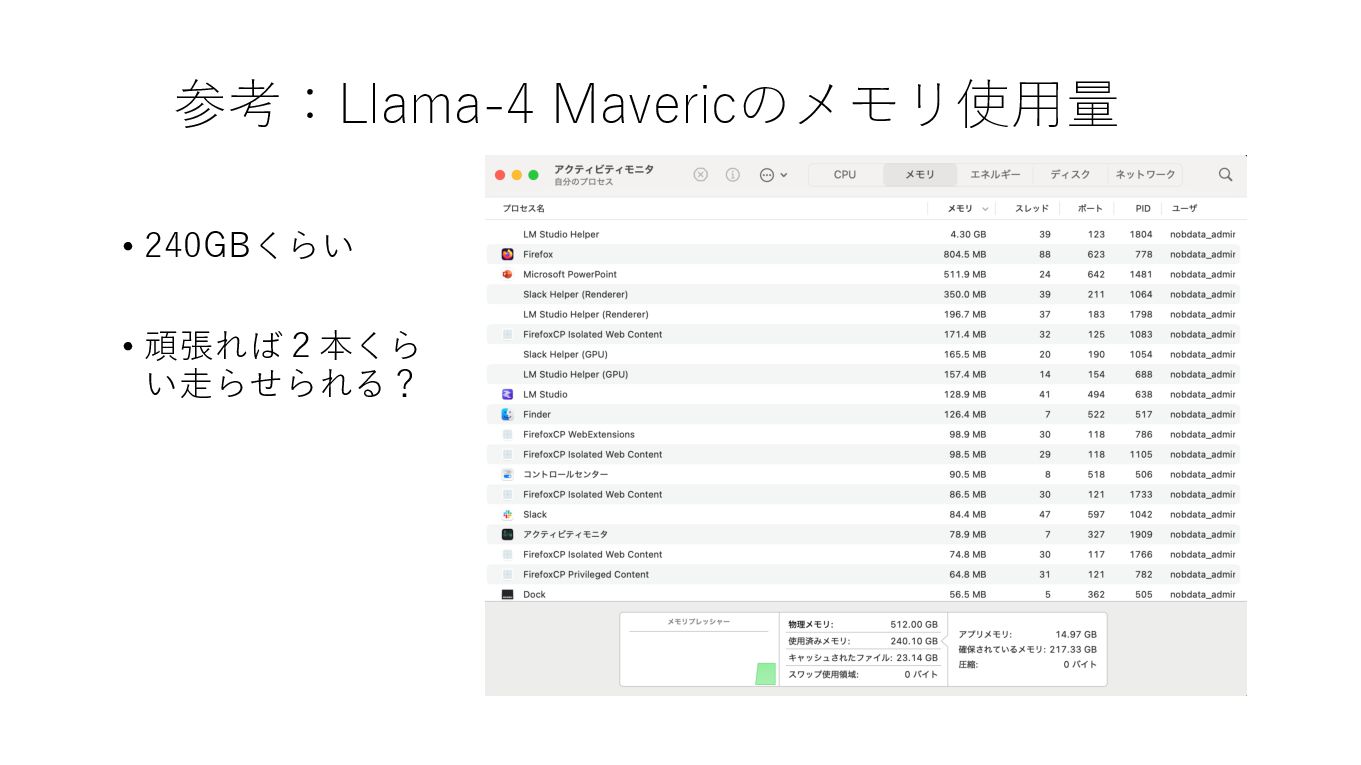
参考:Llama-4 Mavericのメモリ使⽤量 • 240GBくらい • 頑張れば2本くら い⾛らせられる?
今回⽤いたプロンプト ・指⽰ 以下の原⽂に対して、個⼈が特定できないように⽒名のマスクを お願いします。また後で復元できるように対応表を作成し、最初と 最後に提⽰してください。【⼈物1】のようなイメージでお願いし ます。 ・原⽂ ⾛れメロス 太宰治 メロスは激怒した。必ず、かの邪智暴虐の王を除かなければなら
ぬと決意した。メロスには政治がわからぬ。・・・(以下、最後ま で記載)
実⾏結果① ( Llama-4 Maveric ) • とても良い感じです • 動作中のメモリ使⽤量は 266GBくらい
• 15token/sec、くらいのス ピードは出てそうです
実⾏結果② ( Llama-4 scout-17b-16e ) • やや、いい感じです ( アレキスが⾜りない )
• 動作中のメモリ使⽤量は 116GBくらい • 15token/sec、くらいのス ピードは出てそうです
実⾏結果③ ( Llama-3.3-70b ) • 少し間違えているものの、概ねOK ( 太宰治を⼈物2、とかたまに間 違えている )
• 動作中のメモリ使⽤量は87GBくら い • 5token/sec、くらいのスピードな のでやや遅めですが許容範囲
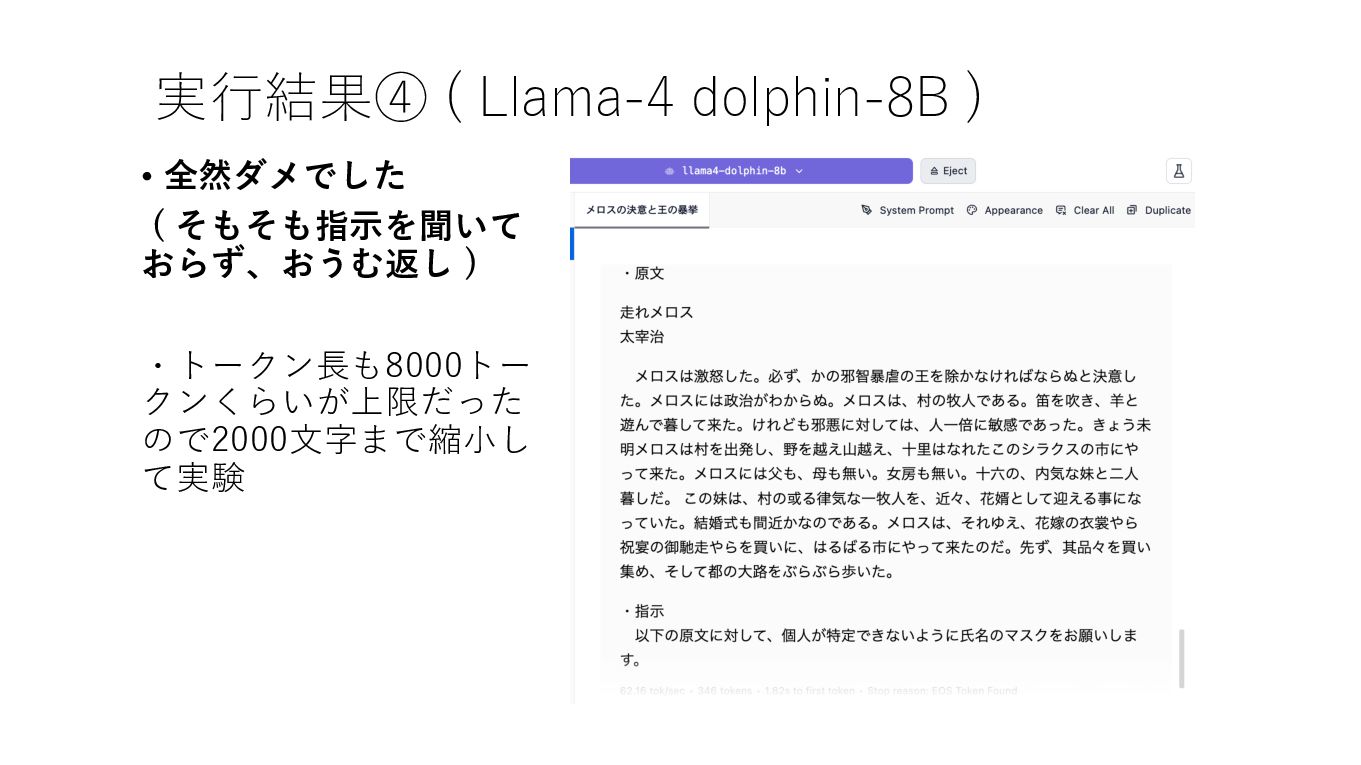
実⾏結果④ ( Llama-4 dolphin-8B ) • 全然ダメでした ( そもそも指⽰を聞いて おらず、おうむ返し
) ・トークン⻑も8000トー クンくらいが上限だった ので2000⽂字まで縮⼩し て実験
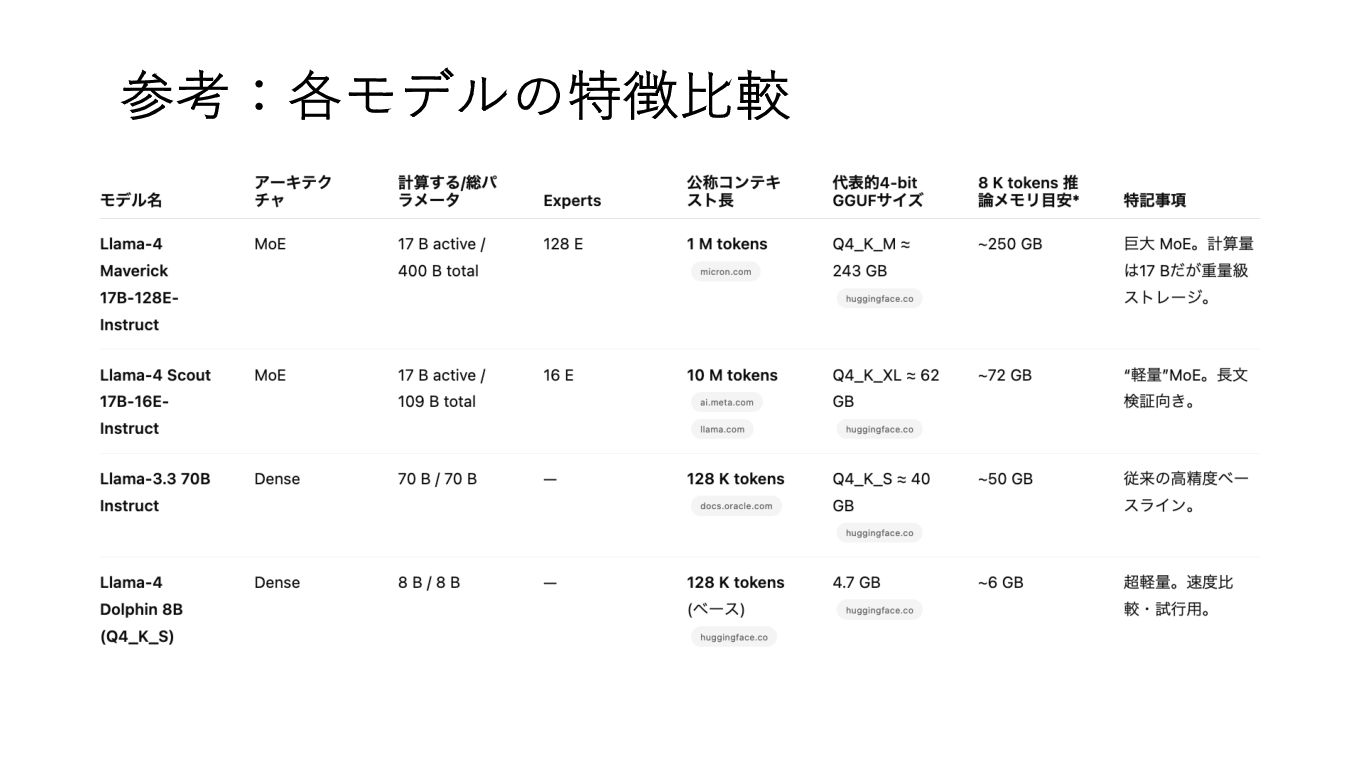
参考:各モデルの特徴⽐較
その他所感等 • Llama-4 mavericでようやく及第点。ただ、⼗分ではない ( ChatGPT-4と4oの中間くらいの感覚 ) • 個⼈情報マスクは⼗分だが、バイブコーディングで分析させる にはまだ弱い印象(
複雑な分析は失敗する ) • ⼀⽅で「どんなデータでもローカルで安全に扱える」という点 はやはりデカい • ローカルLLM活⽤も引き続き⾊々検証していきたいと思います
Enjoy..!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}