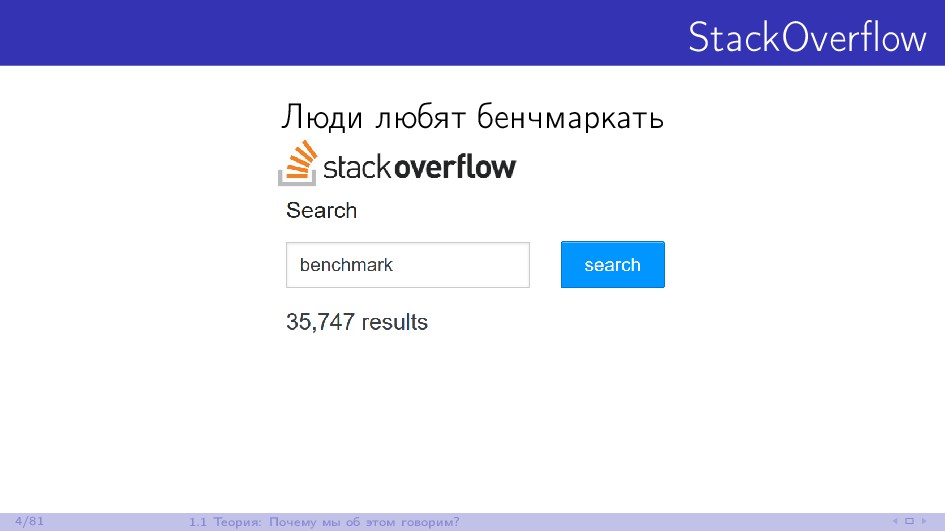
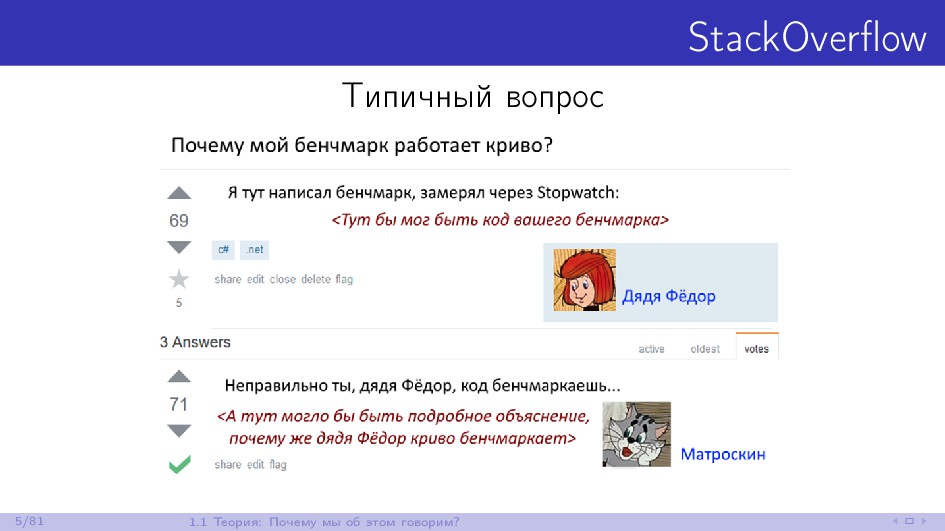
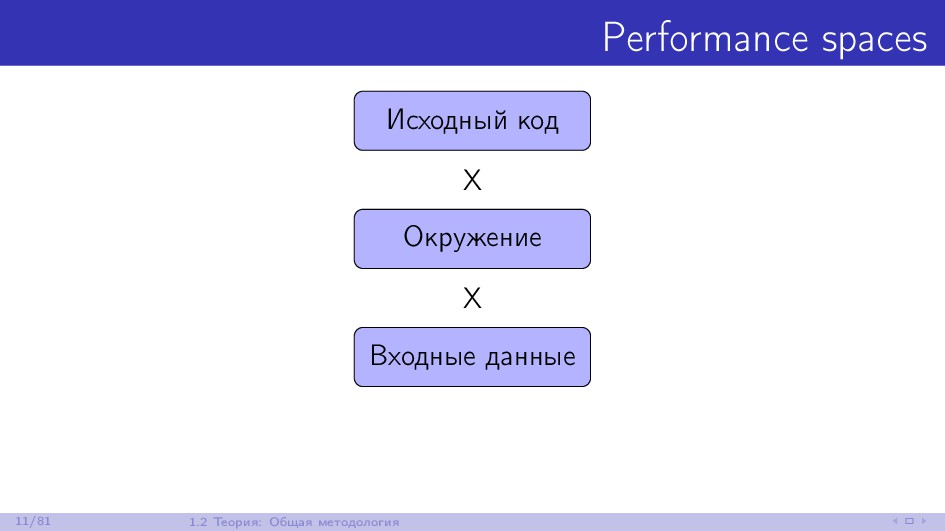
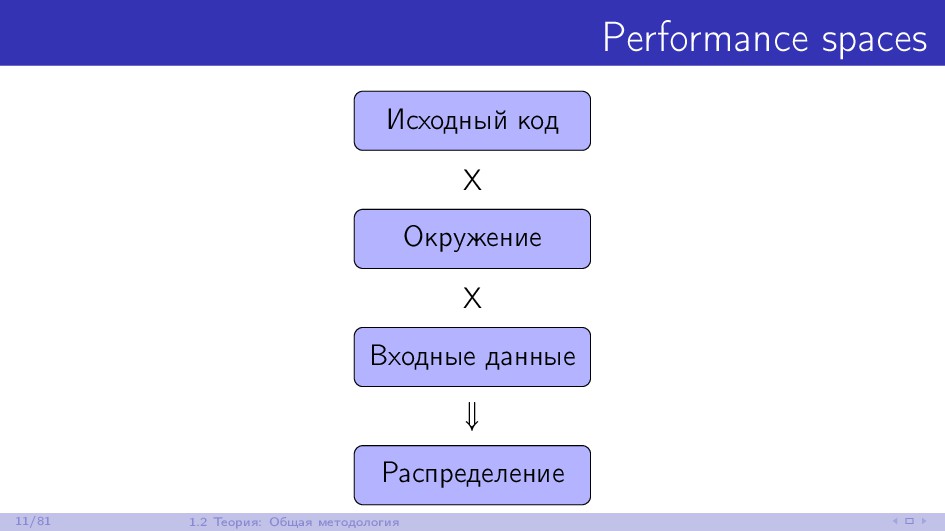
Изо дня в день многие .NET-разработчики сталкиваются с проблемами производительности в своих проектах. Для их решения необходимо уметь корректно замерять время, чтобы иметь возможность сравнить эффективность разных подходов. Если речь идёт о минутах или часах, то такие замеры можно выполнять "на глаз". Если речь идёт о секундах, то с задачей хорошо справится ваш любимый профайлер. Но если речь идёт о миллисекундах, микросекундах или даже наносекундах, то у вас могут возникнуть проблемы. Замеры коротких промежутков времени - очень сложная задача, многие программисты не умеют решать её корректно. Доклад будет состоять из двух частей. В первой мы поговорим про теорию бенчмаркинга. Как это делать правильно, на что нужно обращать внимание и как не обмануть себя при анализе результатов. Во второй части посмотрим на практические примеры, в которых истинное положение дел с производительностью совсем не очевидно до проведения замеров. Разбор подобных ситуаций помогает понять сколько граблей раскидано повсюду для начинающих любителей побенчмаркать и почему сложно делать микрозамеры времени на современном железе.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
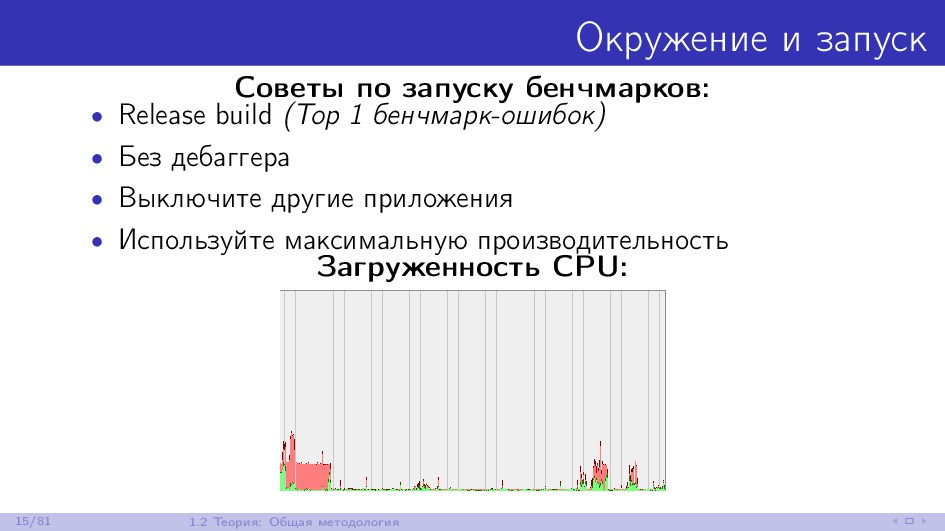{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
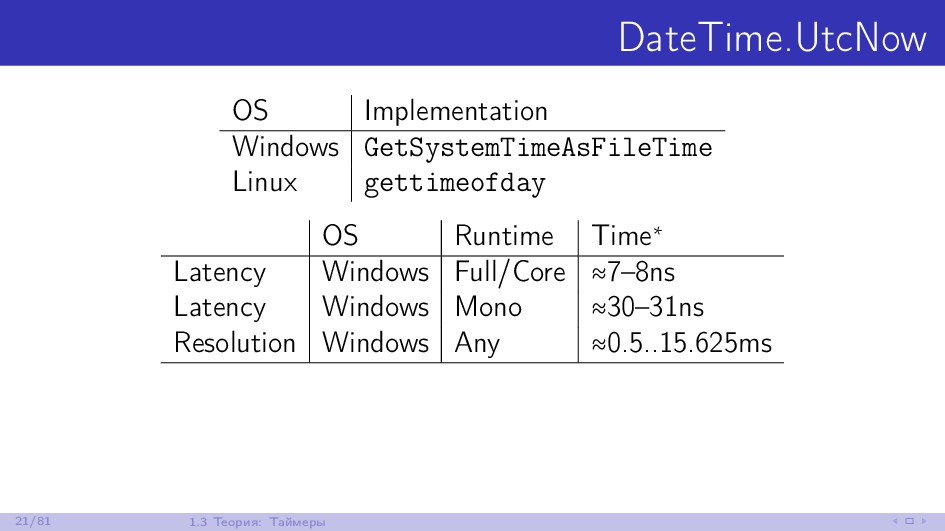{kind=link}
{kind=link}
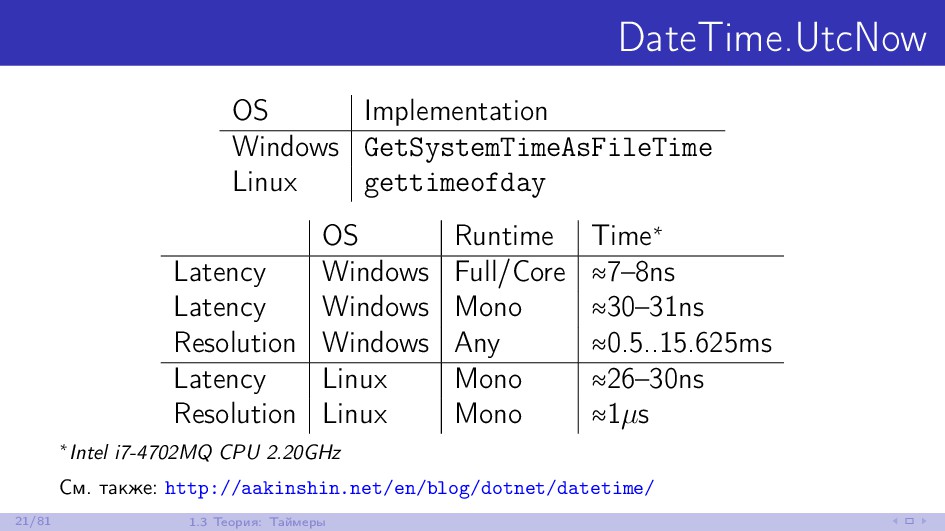{kind=link}
{kind=link}
{kind=link}
{kind=link}
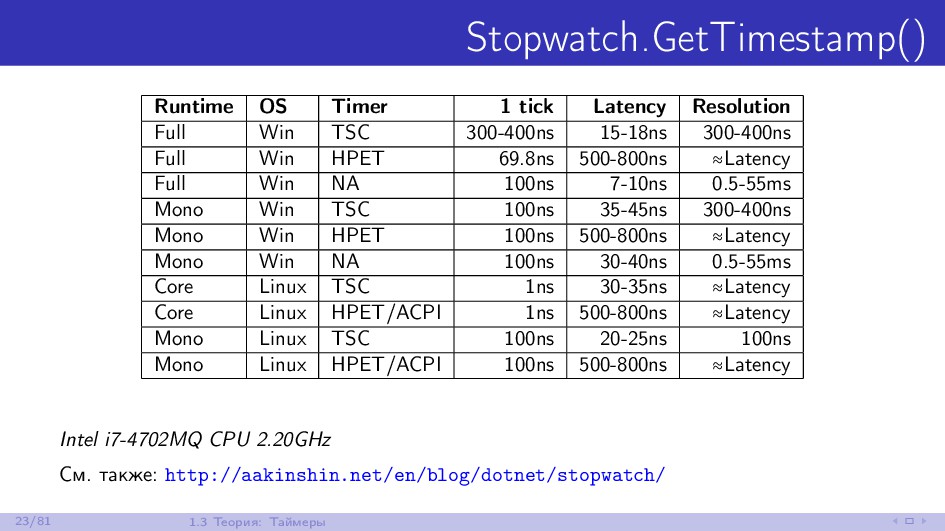{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
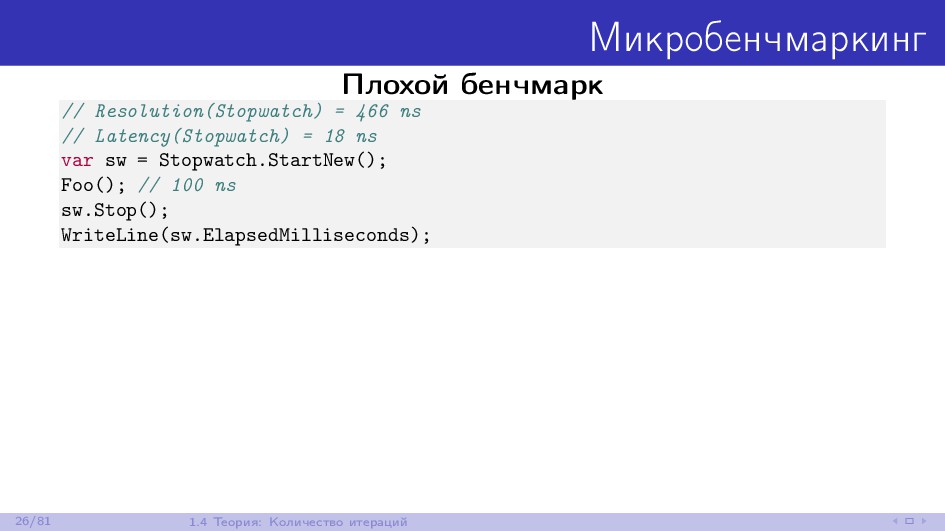{kind=link}
{kind=link}
![Прогрев Запустим бенчмарк несколько раз: int[] x = new int[128](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_82.jpg){kind=link}
![Прогрев Запустим бенчмарк несколько раз: int[] x = new int[128](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_83.jpg){kind=link}
{kind=link}
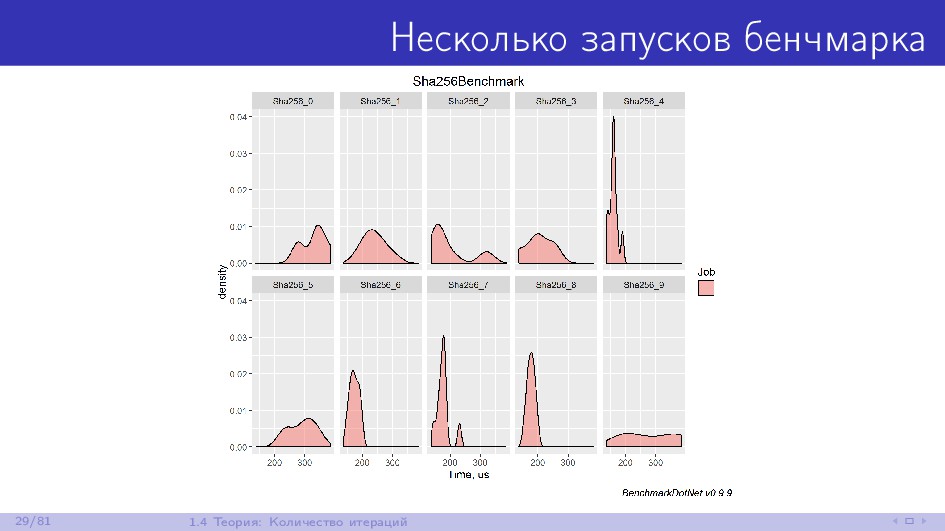{kind=link}
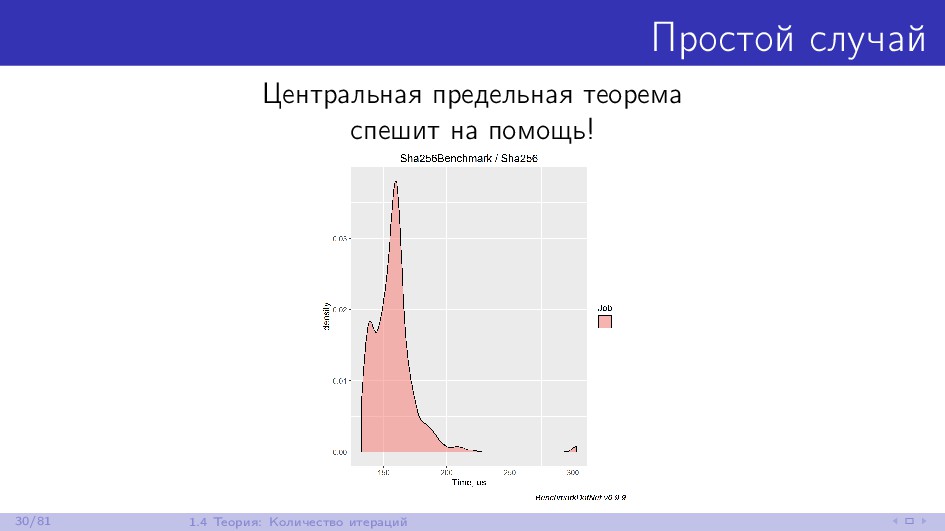{kind=link}
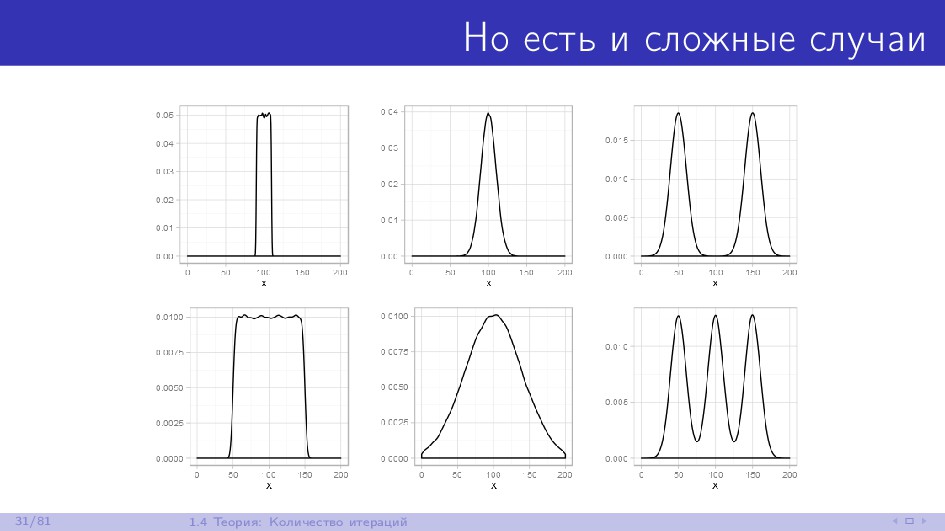{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
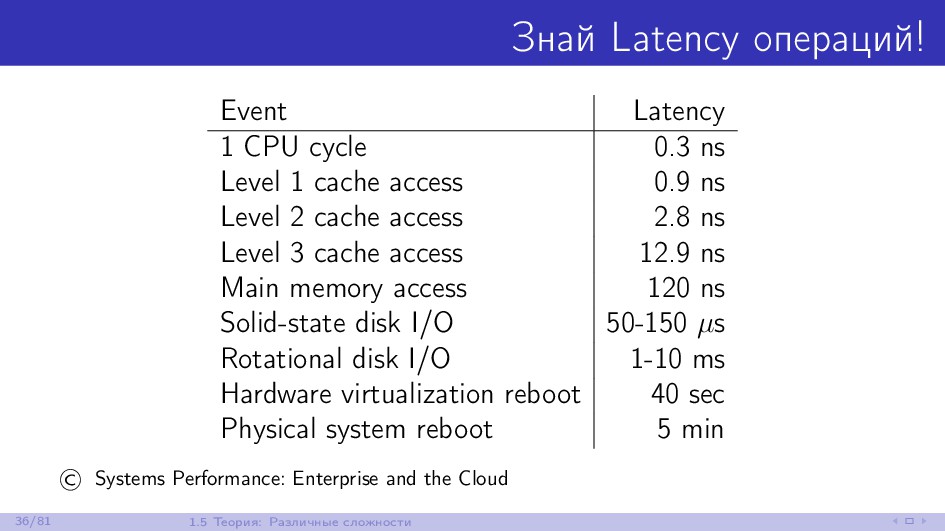{kind=link}
{kind=link}
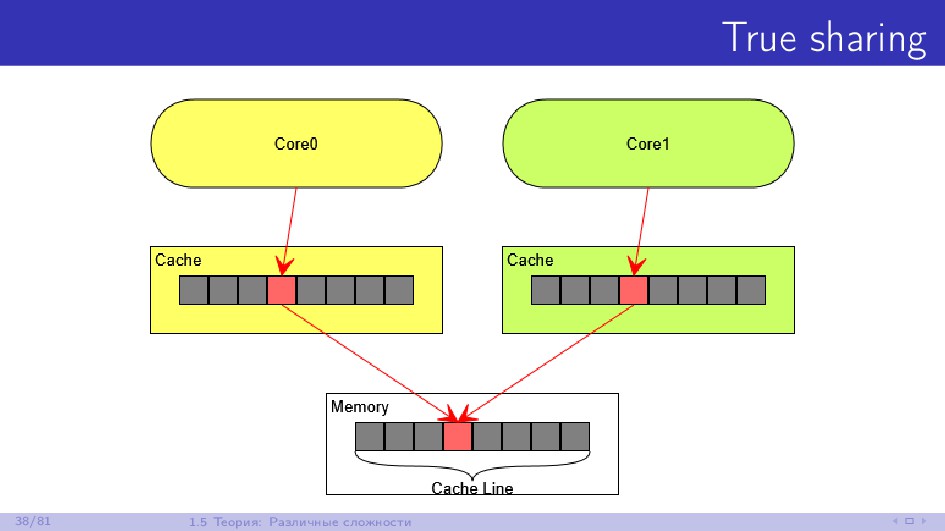{kind=link}
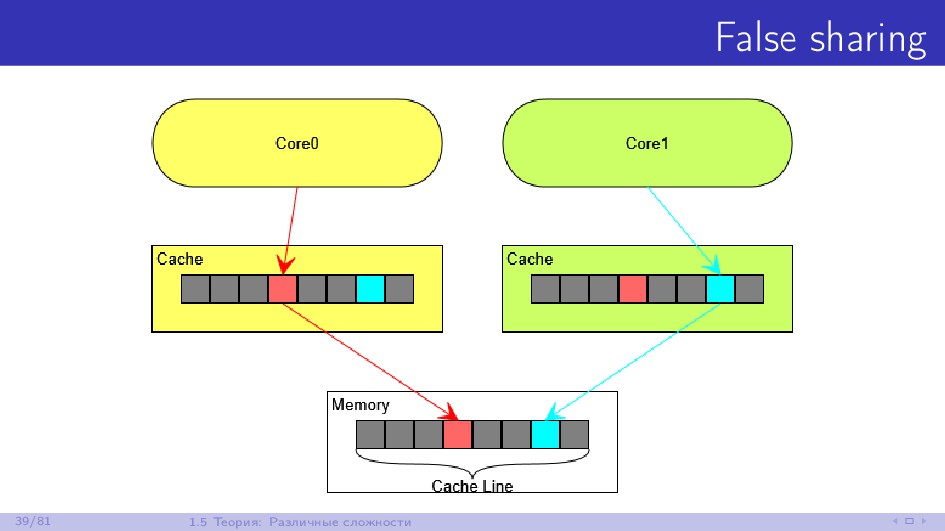{kind=link}
![False sharing в действии private static int[] x = new](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_97.jpg){kind=link}
![False sharing в действии private static int[] x = new](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_98.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
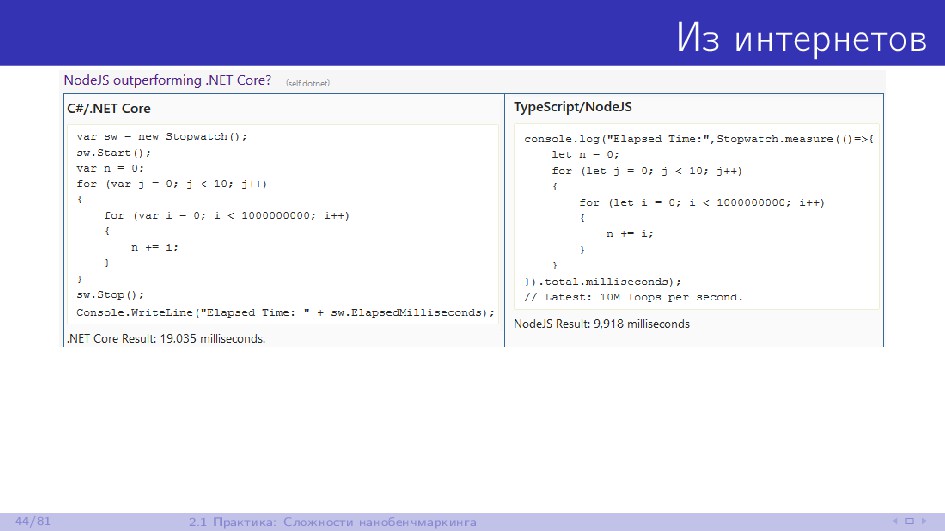{kind=link}
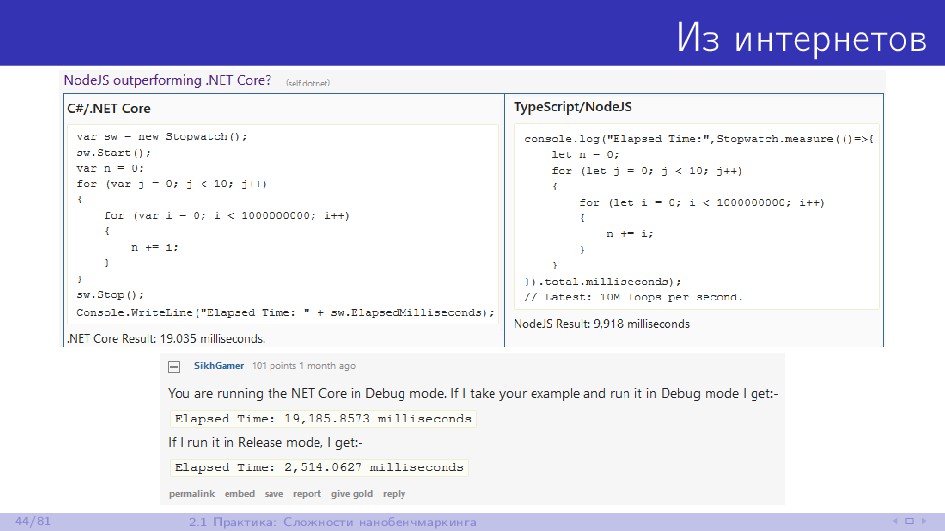{kind=link}
![Задача Какой из методов работает быстрее? [MethodImpl(MethodImplOptions.NoInlining)] public void Empty0()](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_105.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
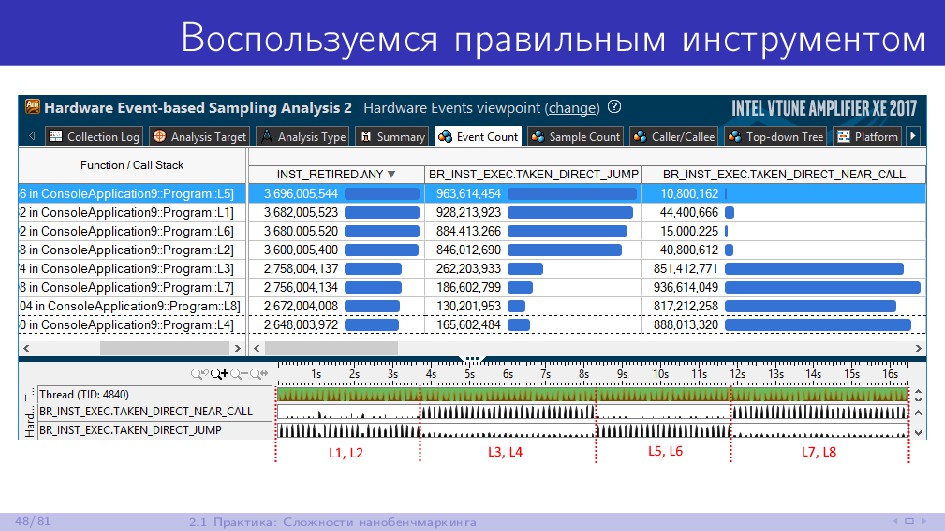{kind=link}
{kind=link}
{kind=link}
![Сумма элементов массива const int N = 1024; int[,] a](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_114.jpg){kind=link}
![Сумма элементов массива const int N = 1024; int[,] a](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_115.jpg){kind=link}
{kind=link}
![Branch prediction const int N = 32767; int[] sorted, unsorted;](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_117.jpg){kind=link}
![Branch prediction const int N = 32767; int[] sorted, unsorted;](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_118.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Проведём опыт [Benchmark] int Calc() => WithoutStarg(0x11) + WithStarg(0x12); int](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_125.jpg){kind=link}
![Проведём опыт [Benchmark] int Calc() => WithoutStarg(0x11) + WithStarg(0x12); int](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_126.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
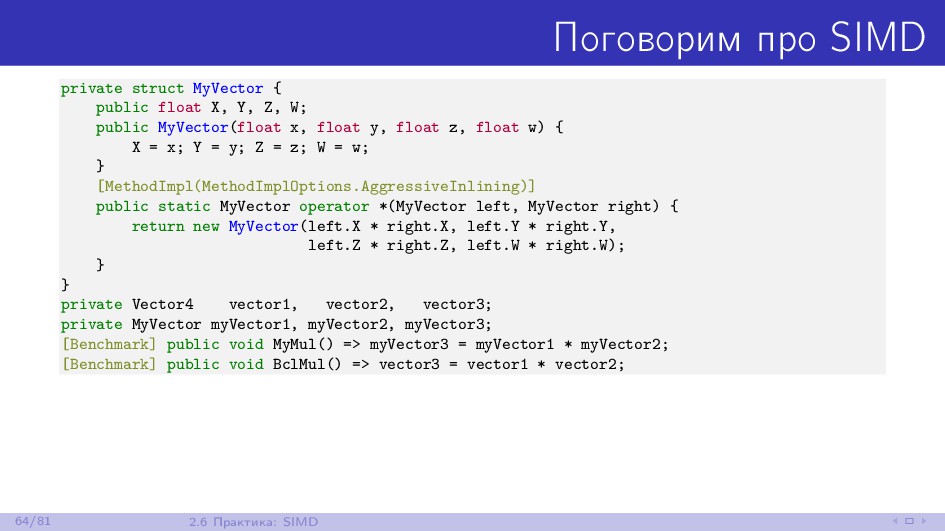{kind=link}
{kind=link}
{kind=link}
{kind=link}
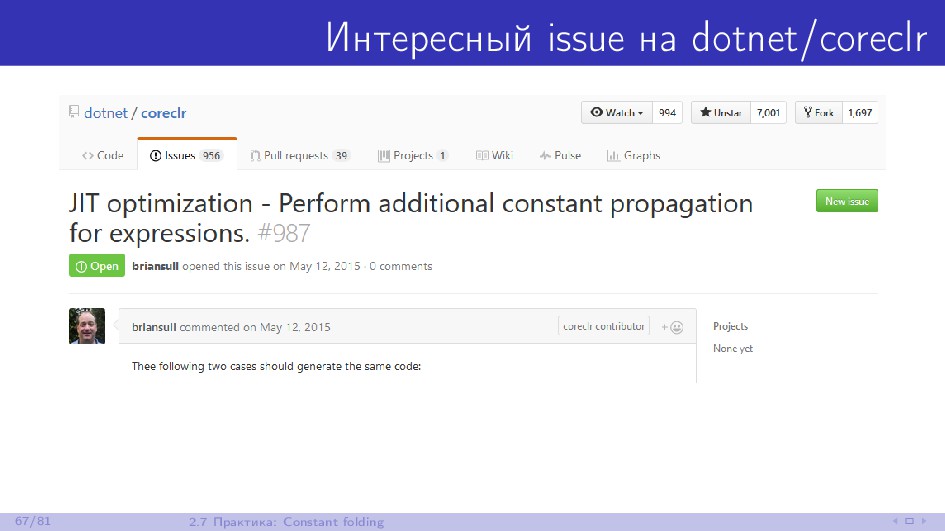{kind=link}
{kind=link}
{kind=link}
![Как же так? RyuJIT-x64, Sqrt13 vsqrtsd xmm0,xmm0,mmword ptr [7FF94F9E4D28h] vsqrtsd](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_139.jpg){kind=link}
![Как же так? RyuJIT-x64, Sqrt14 vmovsd xmm0,qword ptr [7FF94F9C4C80h] ret](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_140.jpg){kind=link}
{kind=link}
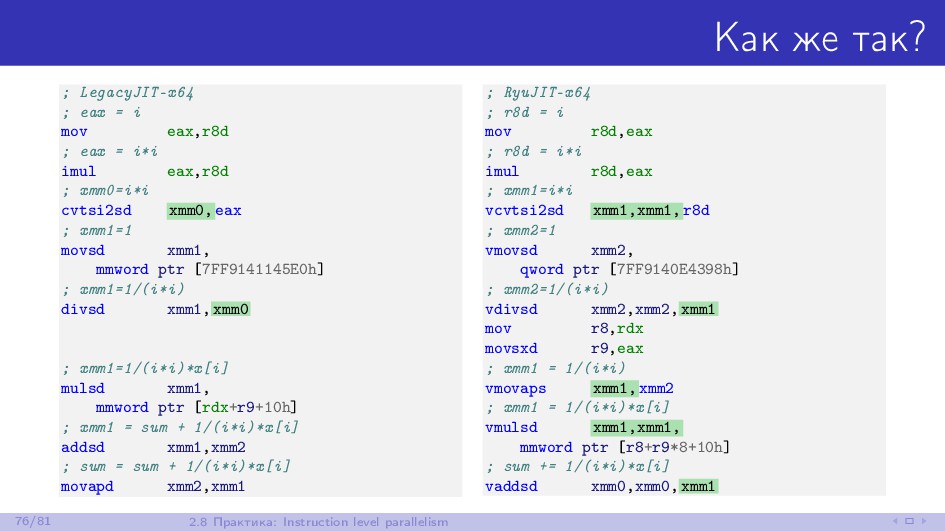
![Как же так? Constant folding в действии N001 [000001] dconst](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_142.jpg){kind=link}
{kind=link}
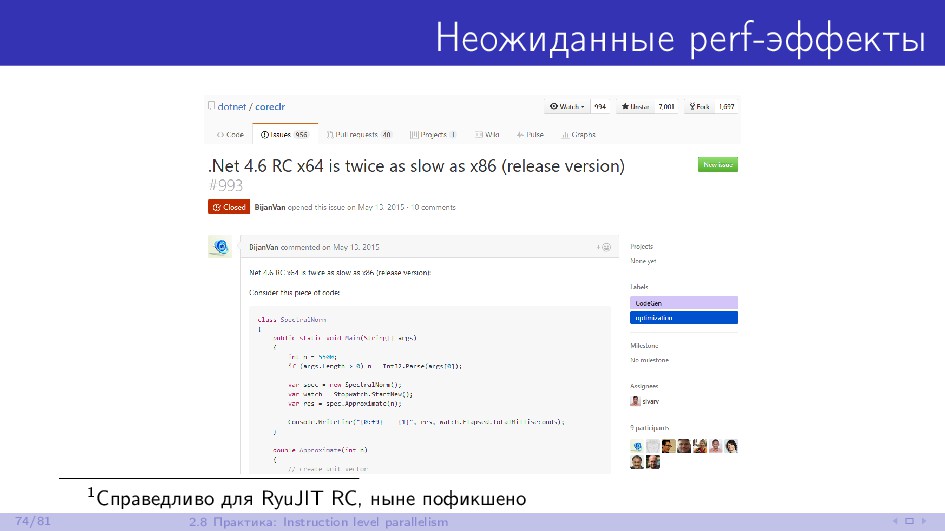{kind=link}
![Задачка private double[] x = new double[11]; [Benchmark] public double](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_145.jpg){kind=link}
![Задачка private double[] x = new double[11]; [Benchmark] public double](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_146.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы? Андрей Акиньшин http://aakinshin.net https://github.com/AndreyAkinshin https://twitter.com/andrey_akinshin [email protected] 81/81 3. Заключение](https://files.speakerdeck.com/presentations/09a28a6250f04924b297312fea7af1f1/slide_152.jpg){kind=link}