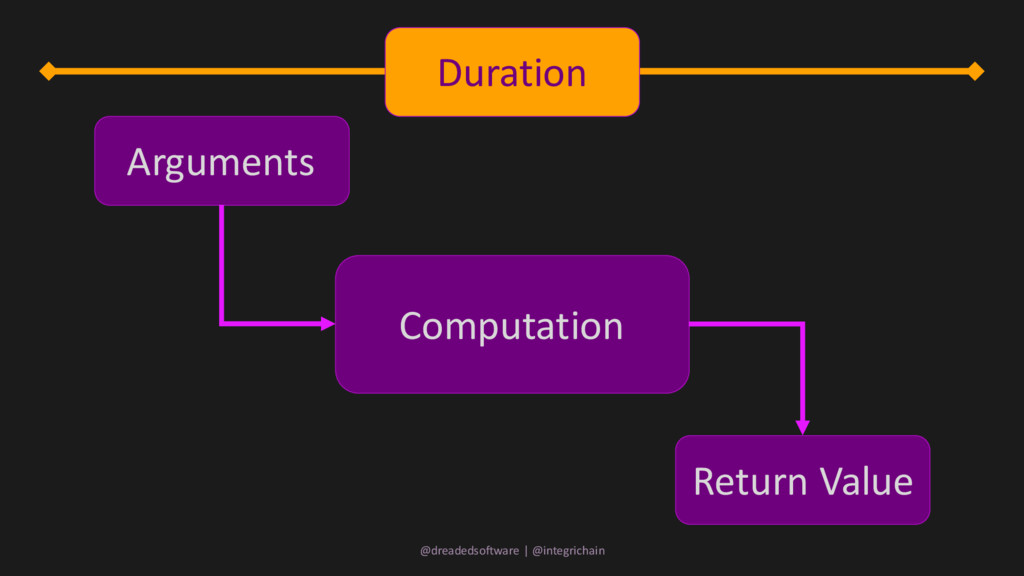
computation • performing multiple computations in the same duration • composing computations through adjacent durations • combining results without respect to duration @dreadedsoftware | @integrichain
ExecutionContext): Future[BigInt] = { Future{simple(n)} } All Future computations need one of these! The new Free Lunch @dreadedsoftware | @integrichain
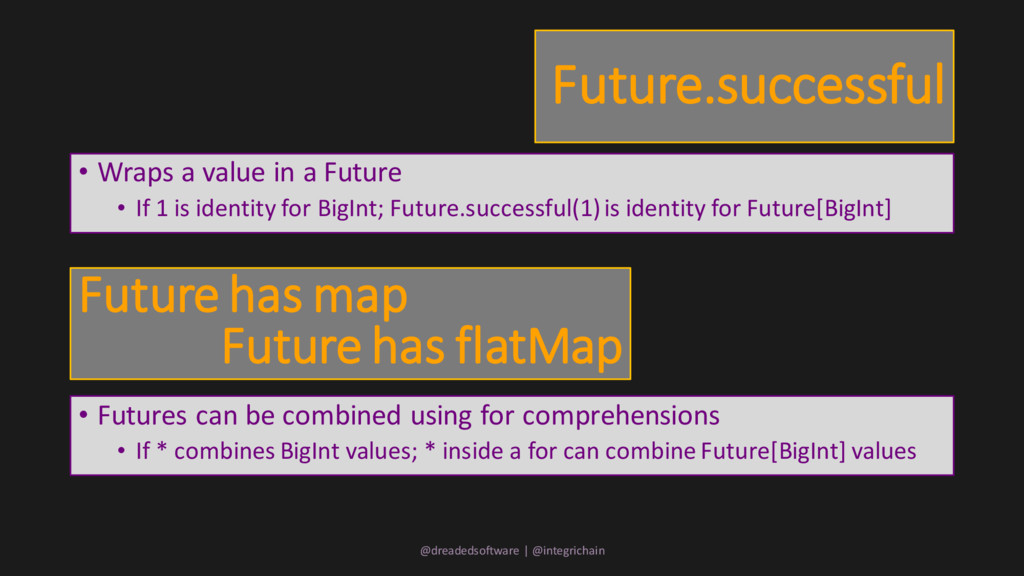
1 is identity for BigInt; Future.successful(1) is identity for Future[BigInt] Future has map Future has flatMap • Futures can be combined using for comprehensions • If * combines BigInt values; * inside a for can combine Future[BigInt] values @dreadedsoftware | @integrichain
Future[BigInt] = { val identityF = Future.successful(identity) val buckets: Seq[(Int, Int)] = getBuckets(n) buckets.foldLeft(identityF){(acc, n) => val next = Future{partialFactorial(n._1, n._2)} for{ a <- acc b <- next }yield{a * b} } } When we were synchronous we had: 1,000,000! ~ 110,000ms Now we have: 1,000,000! ~ 105,000ms Still Sequential! @dreadedsoftware | @integrichain
not just do right half and left half? def async( n: Int)( implicit ec: ExecutionContext): Future[BigInt] = { val start = System.currentTimeMillis val id = Future.successful(identity) val buckets: Seq[(Int, Int)] = getBuckets(n) val partials: Seq[Future[BigInt]] = buckets.map{ case (low, high) => Future{partialFactorial(low, high)} } bigFuture(partials) } Step1: Accumulate Futures @dreadedsoftware | @integrichain
hierarchically by design • No need for recursive inner function • Pass messages for communication; no direct access • Data protection • Unfortunately, typeless • Compiler can’t help us here • We can gain confidence through discipline @dreadedsoftware | @integrichain
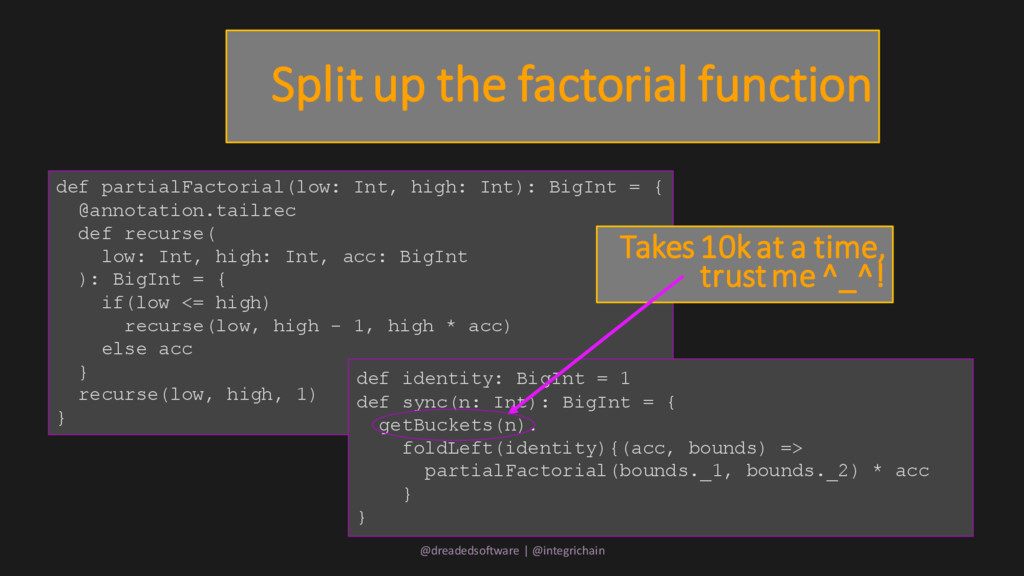
k!(n-k)! This is hierarchial: • 3 parts: a = n!, b = k!, c = (n-k)! • 2 level hierarchy: d = b * c, result = a / d Composed of factorials which we’ve already made async! @dreadedsoftware | @integrichain
• Left operand • Right operand case class Numerator(`n!`: BigInt) case class Denom(`k!(n-k)!`: BigInt) case class DenomLeft(`k!`: BigInt) case class DenomRight(`(n-k)!`: BigInt) @dreadedsoftware | @integrichain
override def receive: Receive = { case (n: Int, k: Int) => val sentBy = sender() val diff = n – k if(n < 1) nothingToDo(sentBy) else{ perform(n, k, sentBy) context.become(compute(sentBy)) } case message @ _ => //failure println(message) context.stop(self) } private def nothingToDo(sentBy: ActorRef) = sentBy ! (0: BigInt) … } For the Futures Input n and k The Trivial Case Let’s dive in here! Let it crash! (After logging of course) @dreadedsoftware | @integrichain
None private var denominator: Option[BigInt] = None private def compute(sentBy: ActorRef): Receive = { case Numerator(n) => denominator.fold{ numerator = Some(n)}{denominator => sentBy ! (n / denominator) context.stop(self) } case Denom(d) => numerator.fold{ denominator = Some(d)}{numerator => sentBy ! (numerator / d) context.stop(self) } case message @ _ => //failure println(message) context.stop(self) } } var is not my favorite way to do this; it works Will see another method later. No denominator, continue on. Have denominator, ready! Let it crash! No numerator, continue on. Have numerator, ready! @dreadedsoftware | @integrichain
Dispatches numerator computation to a Future • Dispatches denominator computation to a child Actor • Combines results of numerator and denominator before terminating @dreadedsoftware | @integrichain
= { case (k: Int, diff: Int) => val `n-k` = diff val sentBy = sender() context.actorOf(Props(new `k!`)) ! k context.actorOf(Props(new `(n-k)!`)) !`n-k` context.become(hasNone(sentBy)) case message @ _ => context.parent ! Message } … } Dispatch left part of computation Let it crash! Dispatch right part of computation Using become to change state @dreadedsoftware | @integrichain
Receive = { case DenomLeft(a) => context.become(hasLeft(a, ref)) case DenomRight(b) =>context.become(hasRight(b, ref)) case message @ _ => fail(message) } private def hasLeft( a: BigInt, sentBy: ActorRef): Receive = { case DenomRight(b) => ref ! Denom(a * b) case message @ _ =>fail(message) } private def hasRight( b: BigInt, ref: ActorRef): Receive = { case DenomLeft(a) => ref ! Denom(a * b) case message @ _ => fail(message) } private def fail(m: Message){ context.parent ! M context.stop(self) } } Current state determines next state. Each state can only receive messages that will put it into the next good state. Duplication of messages will trigger an error. No var! @dreadedsoftware | @integrichain
Especially in the linear case • The payoffs can be enormous • Actors are for larger concurrent problems • They help organize the problem into a hierarchy • Use discretion when deploying, not necessarily a good idea @dreadedsoftware | @integrichain
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Determining what you have @annotation.tailrecdef bigFuture( s: Seq[Future[BigInt]])( implicit ec:](https://files.speakerdeck.com/presentations/1583c491ff834f28aabfa67663229902/slide_18.jpg){kind=link}
![Splitting the pot def collapse( seq: Seq[Future[BigInt]])( implicit ec: ExecutionContext):](https://files.speakerdeck.com/presentations/1583c491ff834f28aabfa67663229902/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![class Combinations extends Actor{ … private var numerator: Option[BigInt] =](https://files.speakerdeck.com/presentations/1583c491ff834f28aabfa67663229902/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}