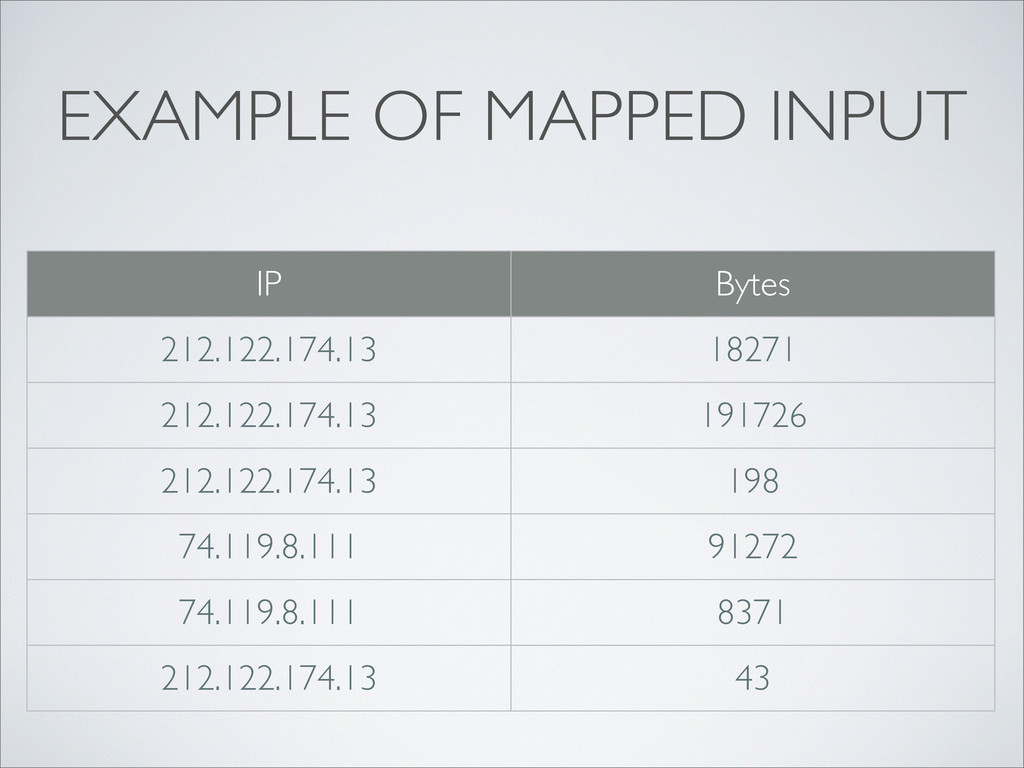
<key, value> pairs • Example: Apache access.log • Each line is a record • Extract client IP address and number of bytes transferred • Emit IP address as key, number of bytes as value • For hourly rotating logs, the job can be split across 24 nodes* * In pratice, it’s a lot smarter than that
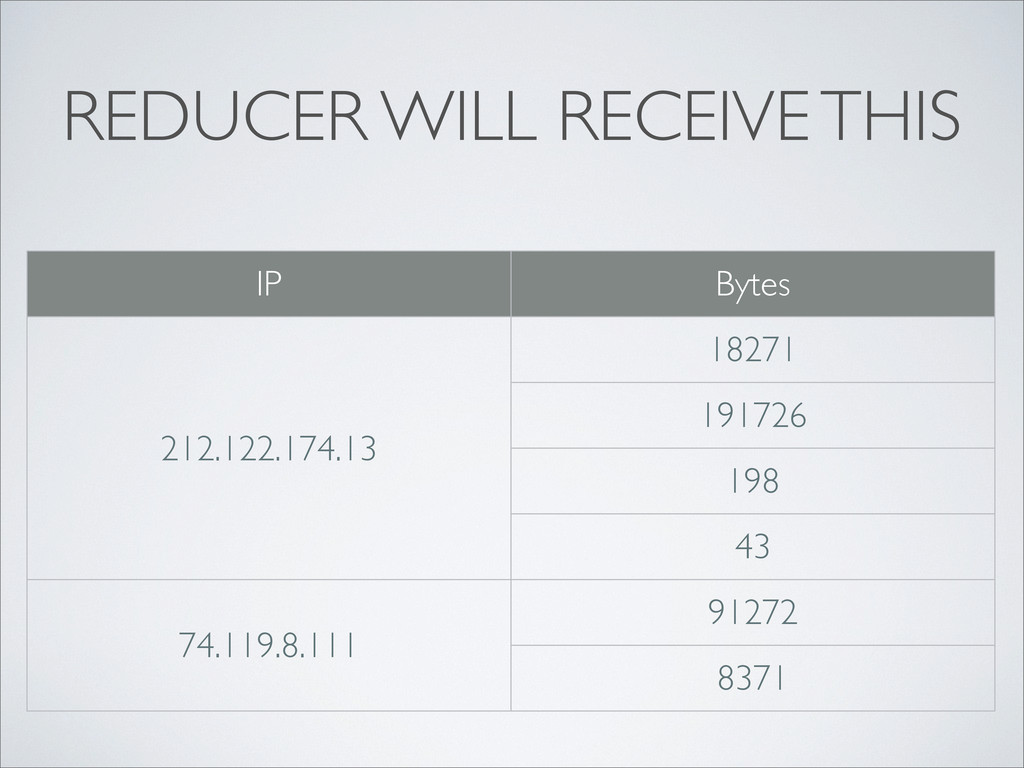
and all values for this specific key • Even if there are many Mappers on many computers; the results are aggregated before they are handed to Reducers • Example: Apache access.log • The Reducer is called once for each client IP (that’s our key), with a list of values (transferred bytes) • We simply sum up the bytes to get the total traffic per IP!
(~95%) • 4800 cores with 12 TB of storage per node • Per day: • 4 TB of new data (compressed) • 135 TB of data scanned (compressed) • 7500+ Hive jobs per day, ~80k compute hours http://www.slideshare.net/cloudera/hw09-rethinking-the-data-warehouse-with-hadoop-and-hive
http://www.cloudera.com/hadoop-training has useful resources • Send me an E-Mail: [email protected] • Follow @dzuelke on Twitter • Slides will be on SlideShare
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PSEUDOCODE function map($line_number, $line_text) { $parts = parse_apache_log($linetext); emit($parts['ip'], $parts['bytes']);](https://files.speakerdeck.com/presentations/d70ec6f031c30130e5b5123139181106/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}