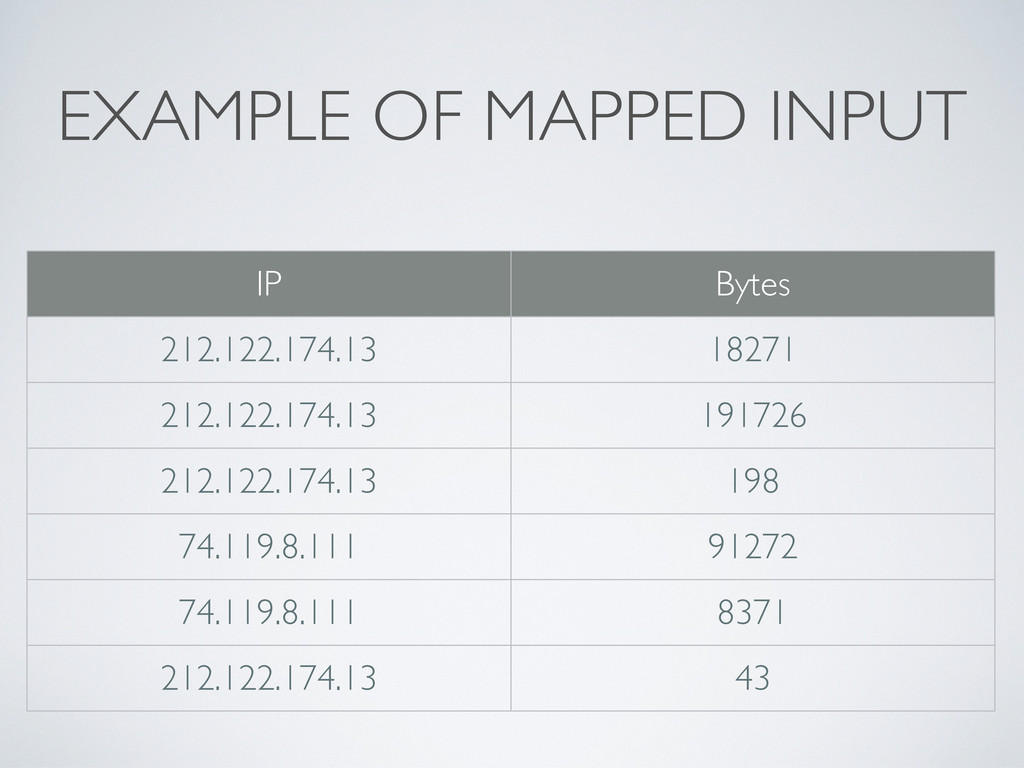
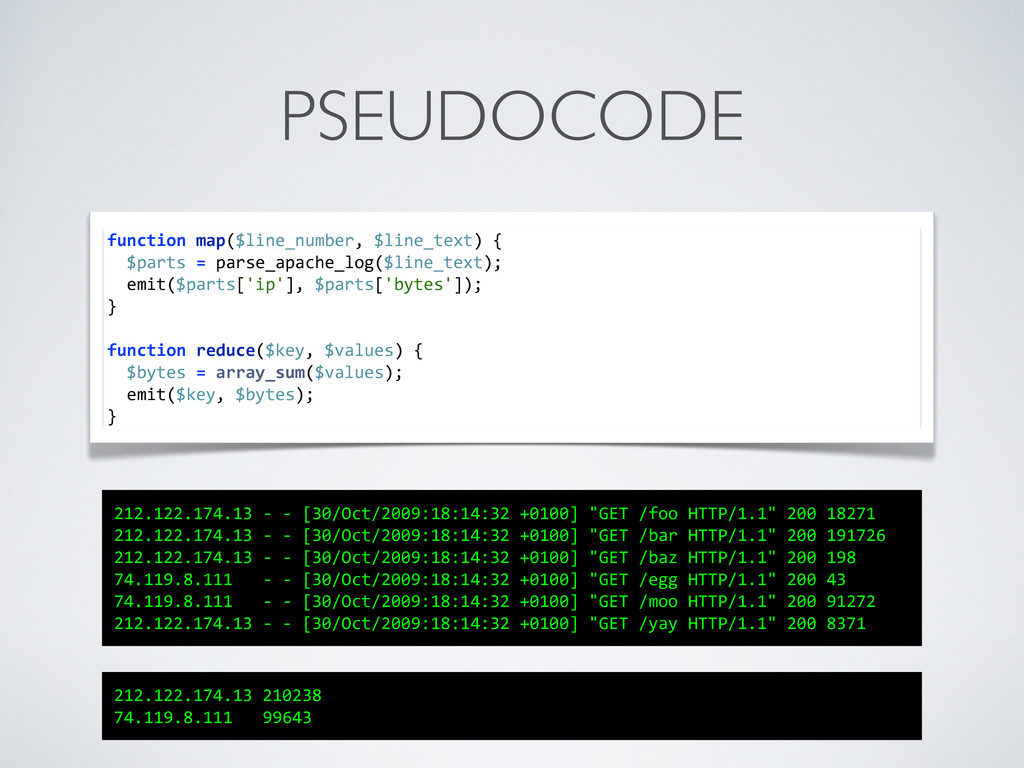
<key, value> pairs • Example: Apache access.log • Each line is a record • Extract client IP address and number of bytes transferred • Emit IP address as key, number of bytes as value • For hourly rotating logs, the job can be split across 24 nodes* * In pratice, it’s a lot smarter than that
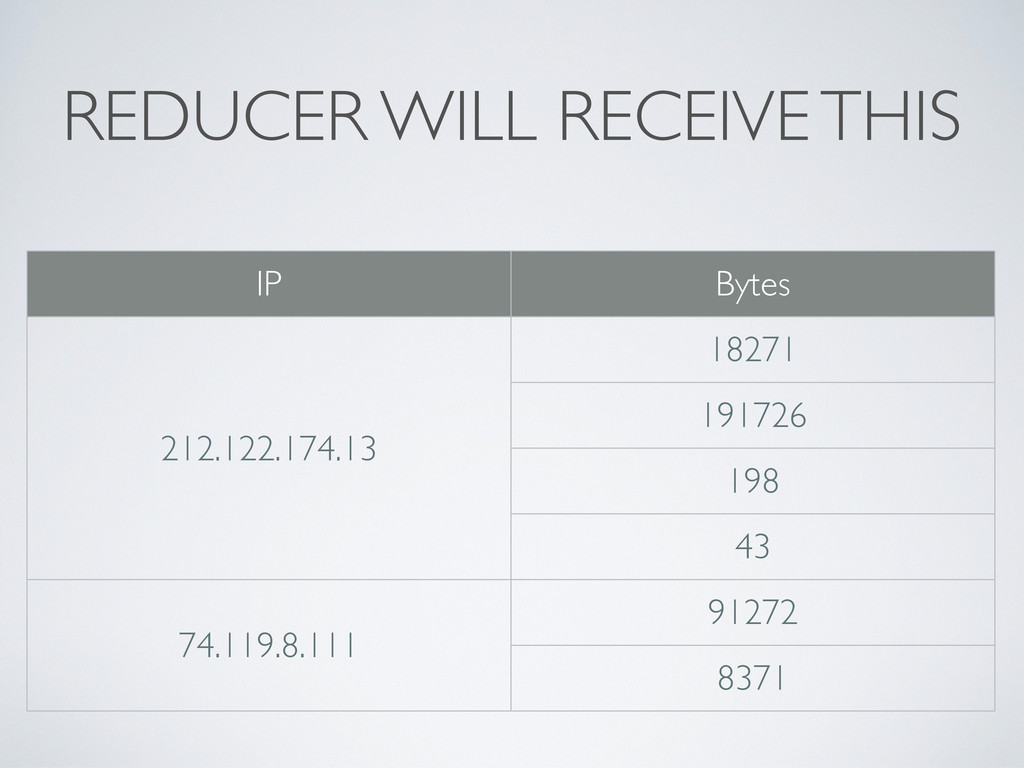
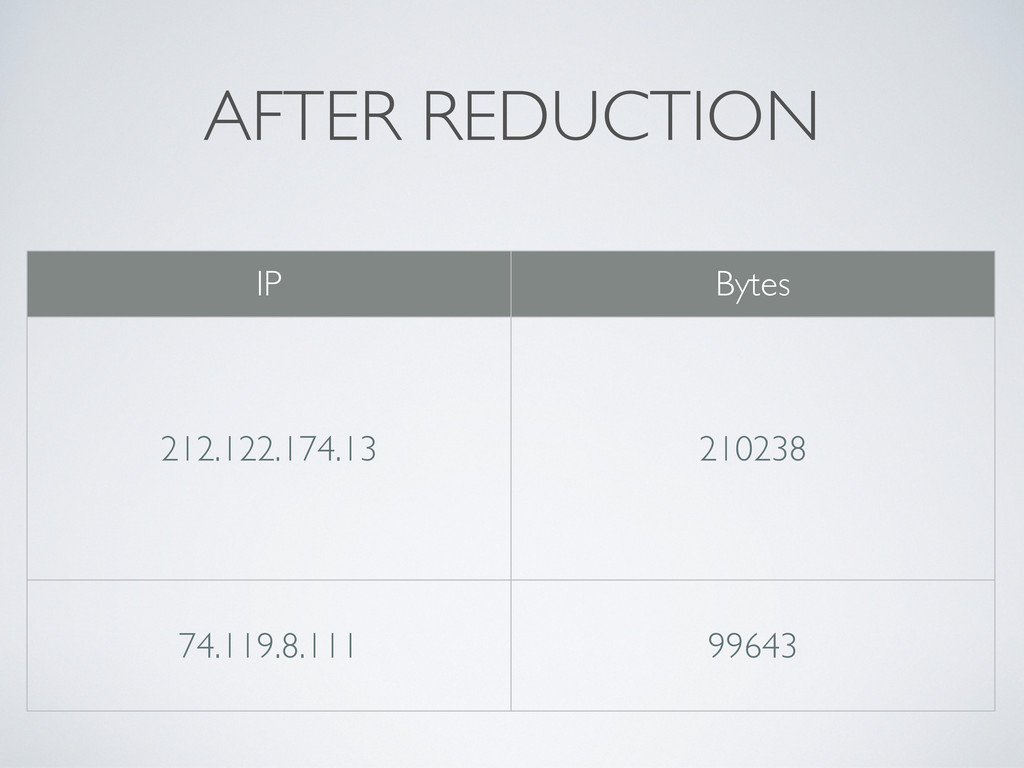
and all values for this specific key • Even if there are many Mappers on many computers; the results are aggregated before they are handed to Reducers • Example: Apache access.log • The Reducer is called once for each client IP (that’s our key), with a list of values (transferred bytes) • We simply sum up the bytes to get the total traffic per IP!
Hive (~95%) • 8400 cores with ~12.5 PB of total storage • 8 cores, 12 TB storage and 32 GB RAM per node • 1x Gigabit Ethernet for each server in a rack • 4x Gigabit Ethernet from rack switch to core http://www.slideshare.net/royans/facebooks-petabyte-scale-data-warehouse-using-hive-and-hadoop Hadoop is aware of racks and locality of nodes
of Pig) • Rackspace (log analysis; data pumped into Lucene/Solr) • LinkedIn (friend suggestions) • Last.fm (charts, log analysis, A/B testing) • The New York Times (converted 4 TB of scans using EC2)
MB) • Designed for very large data sets • Designed for streaming rather than random reads • Write-once, read-many (although appending is possible) • Capable of compression and other cool things
throughput • Blocks are stored redundantly (3 replicas as default) • Aware of infrastructure characteristics (nodes, racks, ...) • Datanodes hold blocks • Namenode holds the metadata Critical component for an HDFS cluster (HA, SPOF)
data into single records • You can optimize using combiners to reduce locally on a node • Only possible in some cases, e.g. for max(), but not avg() • You can control partitioning of map output yourself • Rarely useful, the default partitioner (key hash) is enough • And a million other things that really don’t matter right now ;)
relatively easy to spell and pronounce, meaningless and not used elsewhere: those are my naming criteria. Kids are good at generating such. Googol is a kid’s term. Doug Cutting
jobs in PHP • Takes care of input splitting, can do basic decoding et cetera • Automatically detects and handles Hadoop settings such as key length or field separators • Packages jobs as one .phar archive to ease deployment • Also creates a ready-to-rock shell script to invoke the job
O’Reilly, 2009 • http://www.cloudera.com/hadoop/ • Cloudera Distribution for Hadoop is easy to install and has all the stuff included: Hadoop, Hive, Flume, Sqoop, Oozie, …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}