Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GPT_LangChain_LlamaIndexを活用しDB作業の生産性10倍を考える
Search
神谷築
June 12, 2023
Programming
0
190
GPT_LangChain_LlamaIndexを活用しDB作業の生産性10倍を考える
LangChainとLhamaIndexの簡易解説
ツールを利用しているpythonプログラムの解説
デモ(いい感じに完成していたら紹介します。。。w)
神谷築
June 12, 2023
Tweet
Share
More Decks by 神谷築
See All by 神谷築
Backlogで開発プロセスを可視化した話
eg_kamiya
0
170
GPTを使って行ったプレスリリースまでのプロセス
eg_kamiya
0
130
Other Decks in Programming
See All in Programming
CS教育のDX AIによる育成の効率化
niftycorp
PRO
0
150
米国のサイバーセキュリティタイムラインと見る Goの暗号パッケージの進化
tomtwinkle
2
630
車輪の再発明をしよう!PHP で実装して学ぶ、Web サーバーの仕組みと HTTP の正体
h1r0
2
230
エンジニアの「手元の自動化」を加速するn8n 2026.02.27
symy2co
0
170
maplibre-gl-layers - 地図に移動体たくさん表示したい
kekyo
PRO
0
320
Codexに役割を持たせる 他のAIエージェントと組み合わせる実務Tips
o8n
4
1.4k
Feature Toggle は捨てやすく使おう
gennei
0
190
Cyrius ーLinux非依存にコンテナをネイティブ実行する専用OSー
n4mlz
0
230
SourceGeneratorのマーカー属性問題について
htkym
0
210
守る「だけ」の優しいEMを抜けて、 事業とチームを両方見る視点を身につけた話
maroon8021
3
1.2k
どんと来い、データベース信頼性エンジニアリング / Introduction to DBRE
nnaka2992
1
310
今からFlash開発できるわけないじゃん、ムリムリ! (※ムリじゃなかった!?)
arkw
0
130
Featured
See All Featured
Music & Morning Musume
bryan
47
7.1k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.5k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.8k
Faster Mobile Websites
deanohume
310
31k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.2k
The browser strikes back
jonoalderson
0
810
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
My Coaching Mixtape
mlcsv
0
82
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
250
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
230
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
210
Designing for Timeless Needs
cassininazir
0
170
Transcript
GPT/LangChain/LlamaIndexを活用しDB 作業の生産性10倍を考える GPT Okinawa
自己紹介 • 〜2011:飲食業 • 2012年:株式会社プロトソリューション • 2018年:株式会社EC-GAIN • 2020年:CTO就任 •
現在 :開発組織構築奮闘中 神谷 築(カミヤ キズク) 1991年:31歳 4人の子持ち お酒/ラーメン大好き
GPT Okinawa Mission GPTを使って開発生産性を10倍にしたい
Slack
今日の流れ - LangChain/LhamaIndex解説 - LT - ディスカッション
GPT の課題 最新情報や独自の情報を持っていない
GPT の課題に対するアプローチ - Fine -tuning - In-Context Learning
Fine-tuning モデル自体にデータを与えて再学習させる方法
In-Context Learning 情報を先に与えておいて、GPTにアプローチする方法
今回の話 In-Context Learning
使うツール LangChain LhamaIndex
LangChainとは LangChainは、GPT-3のような大規模言語モデル( Large Language Model: LLM)を利用してサービスの開発 をしたいときに便利に使えるライブラリです。 例えば、ChatGPT のような AI
とチャットできるサービスを開発する場合を考えます。 OpenAI が提供する GPT-3 の API だけでも非常にシンプルで使いやすいので、 GPT-3 のみを使用した AI チャットサービスを開発 するには LangChain は不要かもしれません。 しかし、例えば、開発したいチャットアプリの要件に、「最新の検 索結果の内容も踏まえて AIに返答をさせたい」といった条件が追加された場合には LangChain が有効です。 LangChain には、「検索エンジンでの検索結果を API で返してくれるサービス」である SerpApi と LLM を組み 合わせる機能があります。 この機能を使うことで、よくある「最新の検索結果の内容も踏まえて AI に返答をさせ たい」という要望を数行のコードで実装できます。 このように、LangChain は LLM を使ってサービスを開発したいときのよくある機能をまとめて提供してくれてい るライブラリです。 引用:https://book.st-hakky.com/docs/langcain-intro/
LangChain要約 GPTを簡単に扱えるようにする 便利なやつ
LhamaIndexとは GPTのようなLLMにプライベートなデータを補強するために、in-context learningという 枠組みがあり、これを行うには データの取り込み インデックス化が必要 ということです。そこで、このデータの取り込み、インデックス化、またそのインデックスを 利用して質問(クエリ)に回答するところまでの機能を一気通貫で提供してくれるのが LlamaIndex、となります。 引用:https://dev.classmethod.jp/articles/llamaindex-overview/
LhamaIndex要約 in-context learning を簡単にできるやつ
プログラムのステップ - テキストを分割 - embeddingとretrieverの作成 - gptの実行
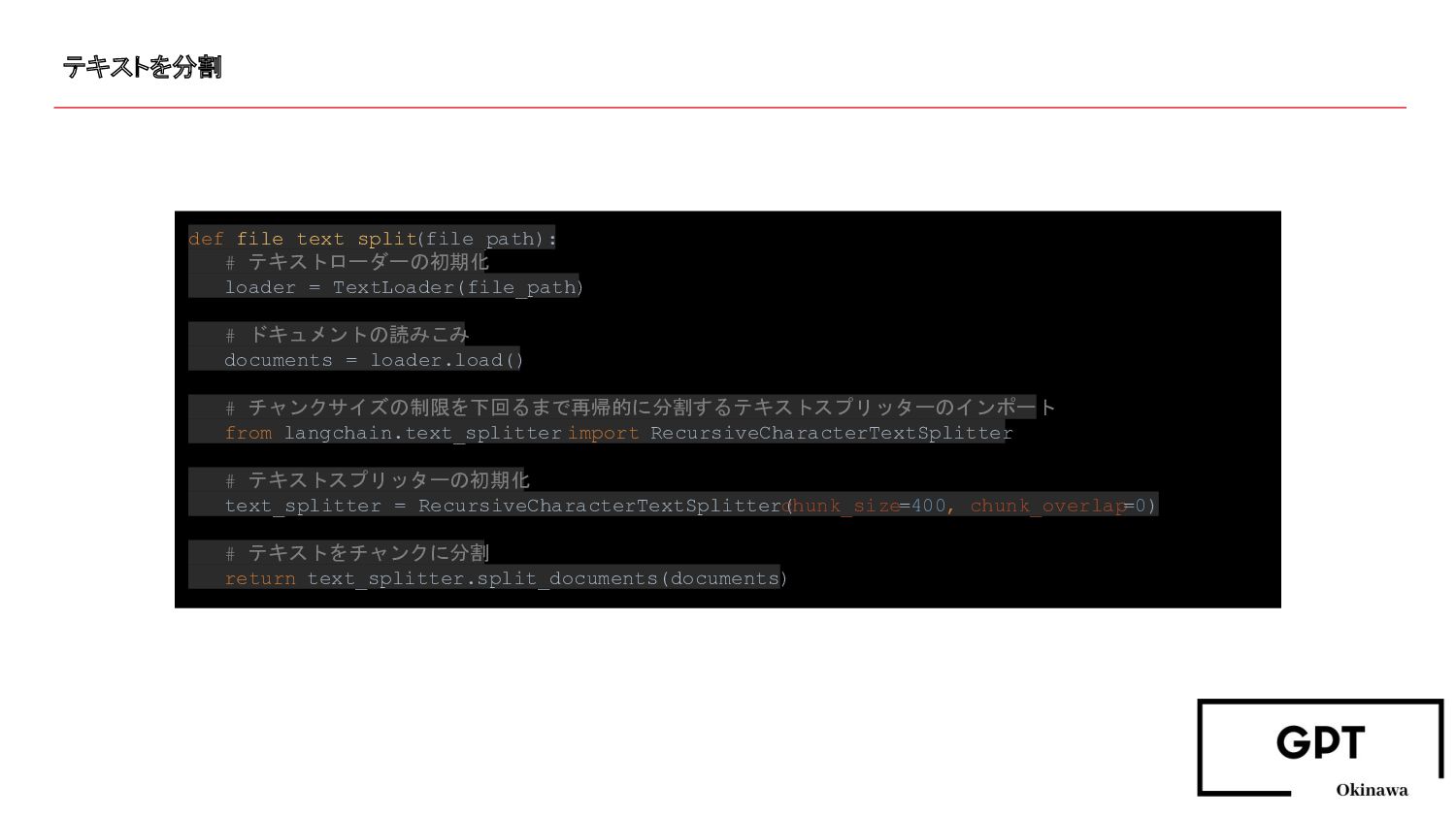
テキストを分割 def file_text_split (file_path): # テキストローダーの初期化 loader = TextLoader(file_path) #
ドキュメントの読みこみ documents = loader.load() # チャンクサイズの制限を下回るまで再帰的に分割するテキストスプリッターのインポート from langchain.text_splitter import RecursiveCharacterTextSplitter # テキストスプリッターの初期化 text_splitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=0) # テキストをチャンクに分割 return text_splitter.split_documents(documents)
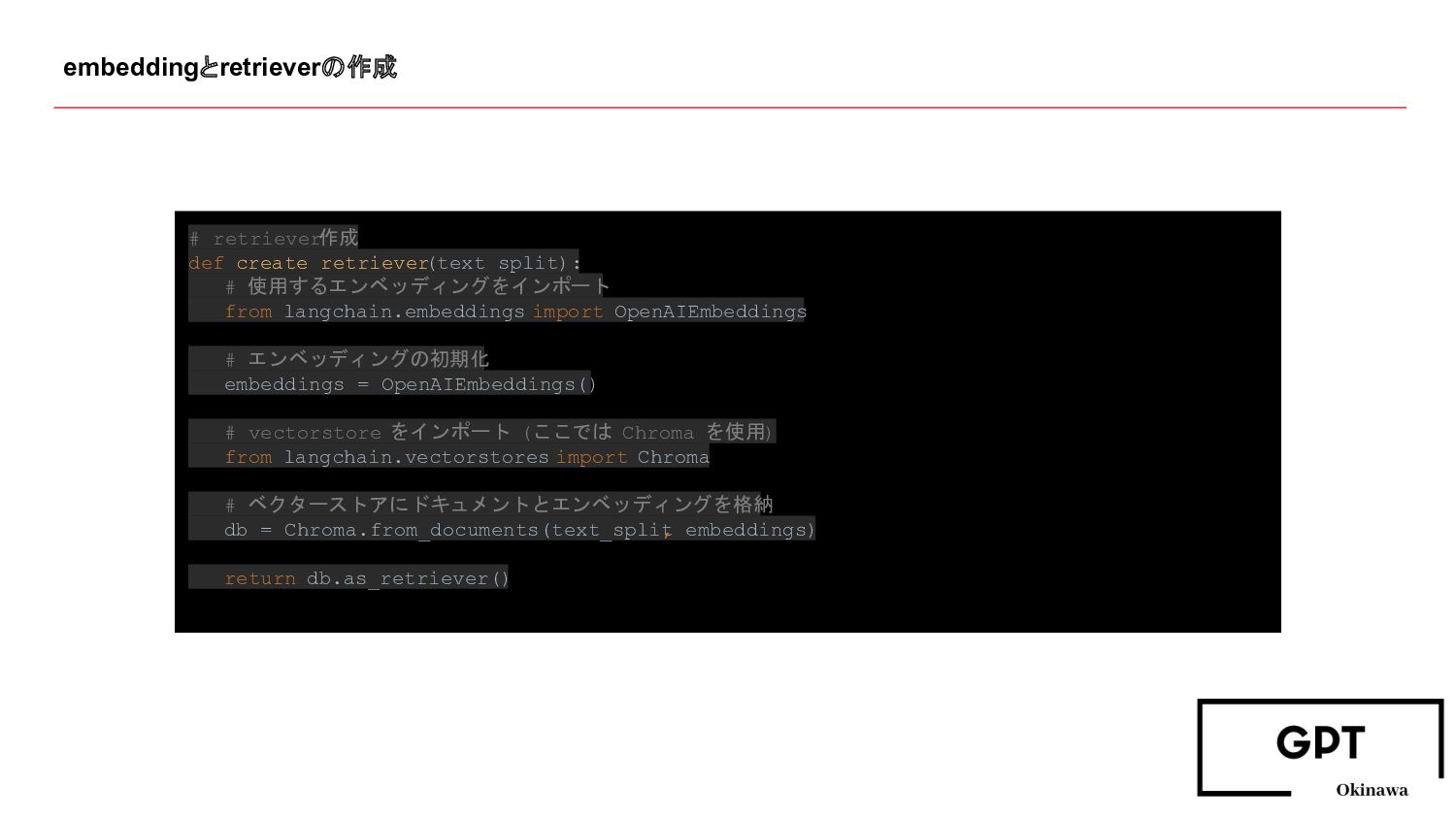
embeddingとretrieverの作成 # retriever作成 def create_retriever (text_split): # 使用するエンベッディングをインポート from langchain.embeddings
import OpenAIEmbeddings # エンベッディングの初期化 embeddings = OpenAIEmbeddings() # vectorstore をインポート (ここでは Chroma を使用) from langchain.vectorstores import Chroma # ベクターストアにドキュメントとエンベッディングを格納 db = Chroma.from_documents(text_split , embeddings) return db.as_retriever()
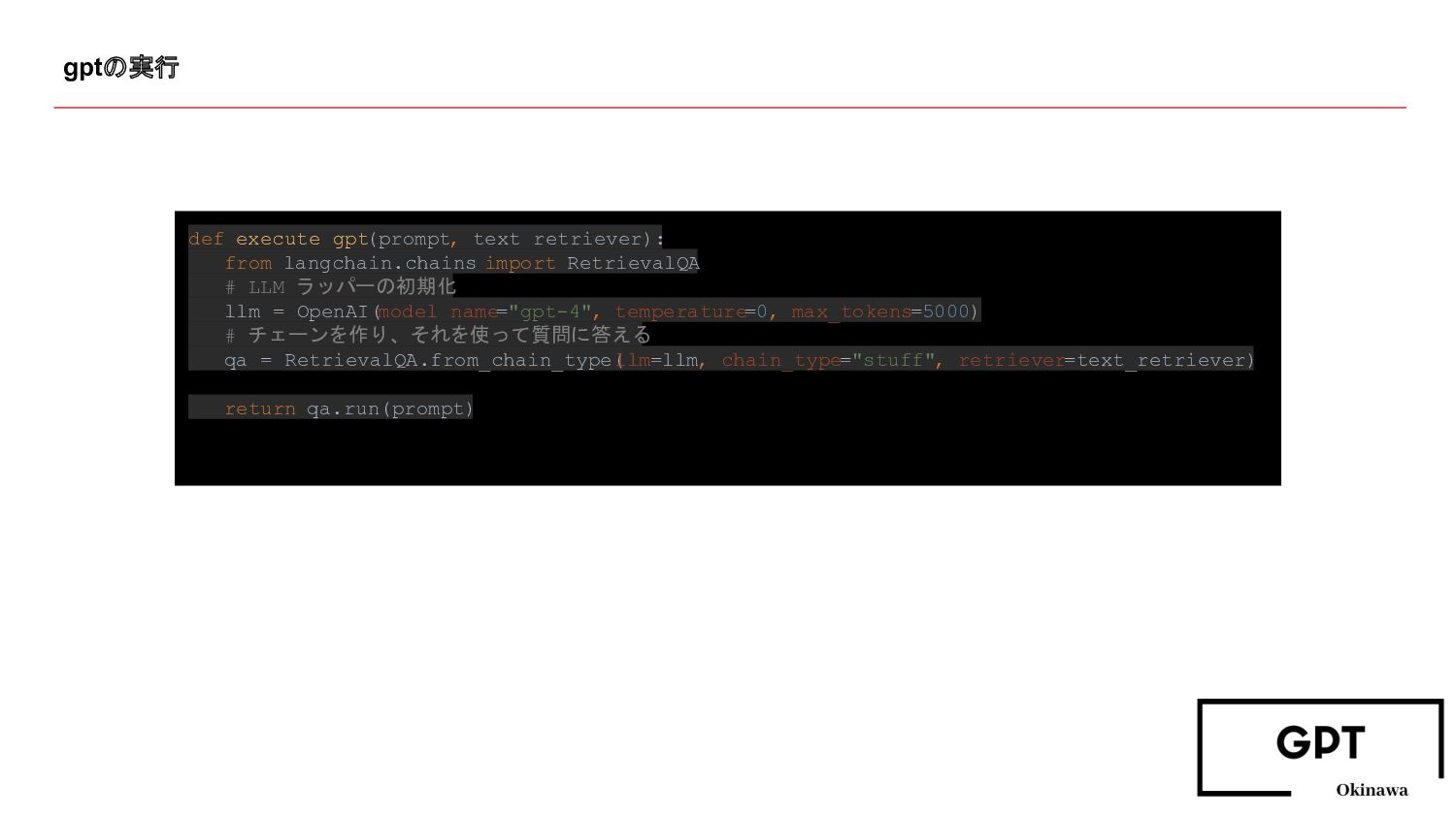
gptの実行 def execute_gpt(prompt, text_retriever): from langchain.chains import RetrievalQA # LLM
ラッパーの初期化 llm = OpenAI(model_name="gpt-4", temperature=0, max_tokens=5000) # チェーンを作り、それを使って質問に答える qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=text_retriever) return qa.run(prompt)
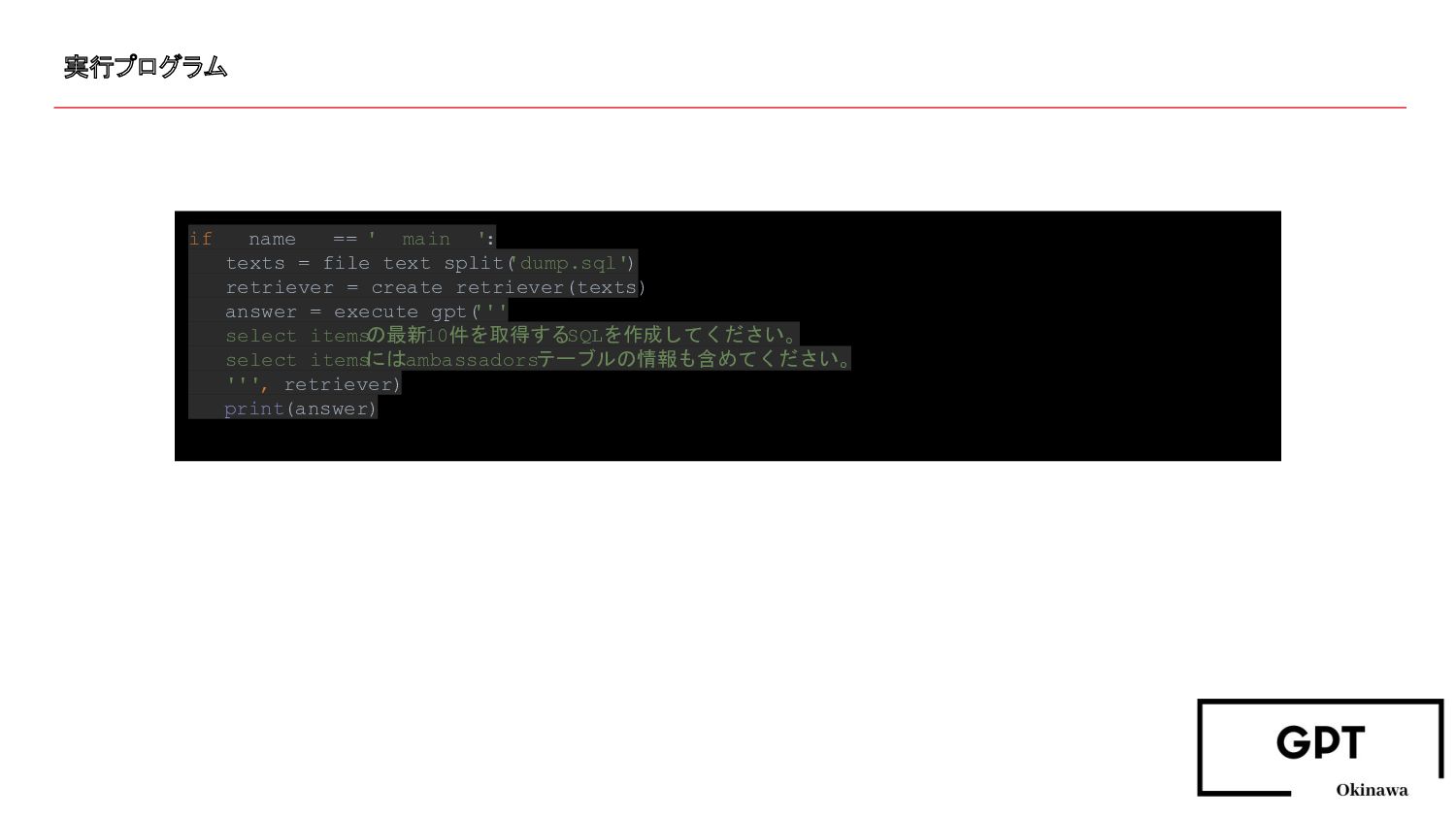
実行プログラム if __name__ == '__main__': texts = file_text_split( 'dump.sql') retriever
= create_retriever(texts) answer = execute_gpt( ''' select_items の最新10件を取得するSQLを作成してください。 select_items にはambassadorsテーブルの情報も含めてください。 ''', retriever) print(answer)
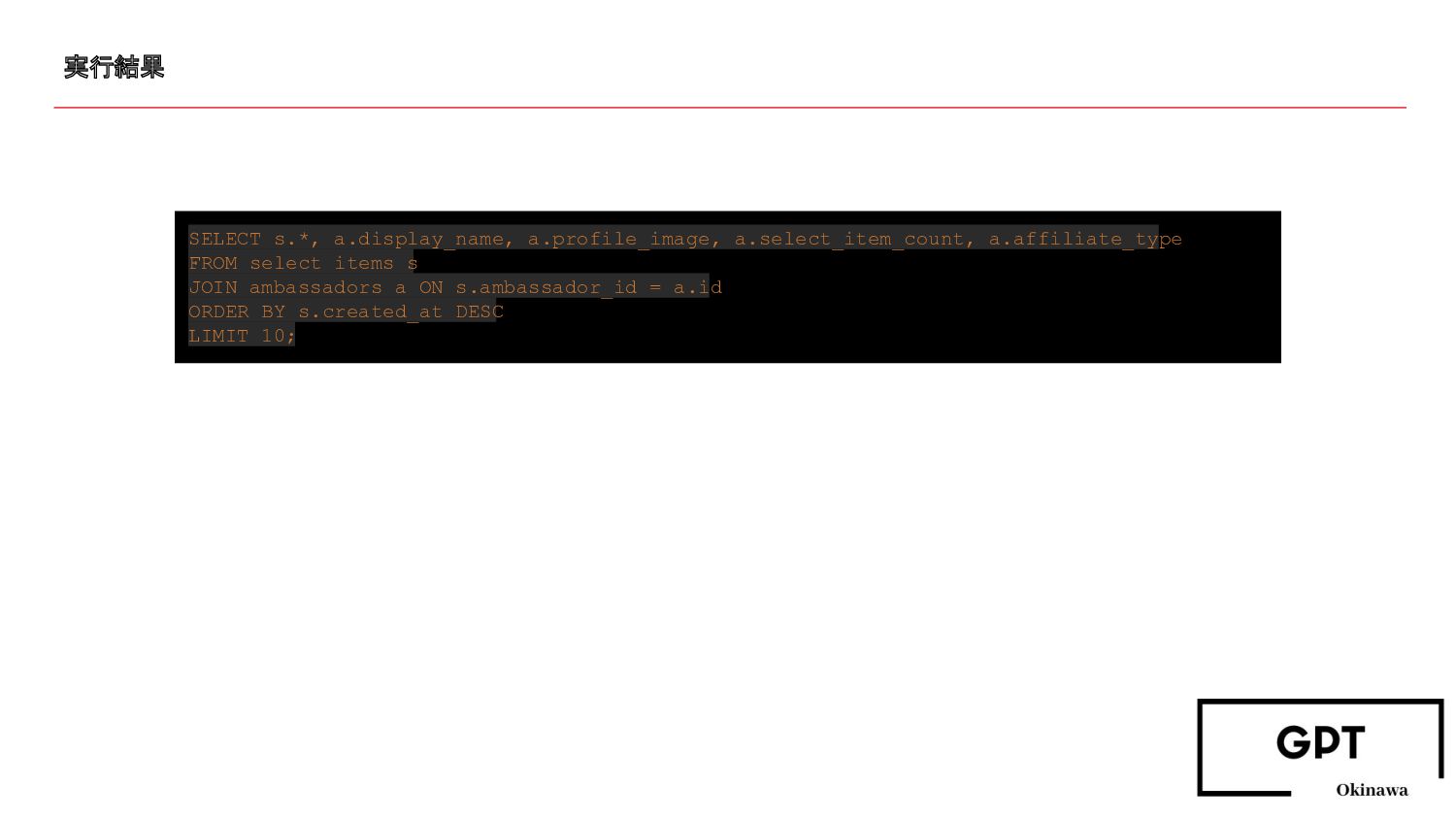
実行結果 SELECT s.*, a.display_name, a.profile_image, a.select_item_count, a.affiliate_type FROM select_items s
JOIN ambassadors a ON s.ambassador_id = a.id ORDER BY s.created_at DESC LIMIT 10;
感想 おおお!
読み込ませたdump.sql データベースのdumpデータを食わせた。 185,426文字のデータ
テキスト分割について 全てのテキストを一回で処理する事が制限されておりできない。 意味のある単位で、テキストをある程度分割する必要がある。 今回は適当に分割してみた。
embeddingとretrieverについて embeddingとは文字をベクトル表現に変換すること 雑に言うと文字が下記のようにマシンが処理しやすい形で管理されるようになる [0.002369190799072385, -0.004423773847520351] retrieverとは、情報を検索して言語モデルに情報を渡せるやつ。 今回だと、GPTの言語モデルにsql dumpのデータを検索して渡している。 正直、内部の詳細はわかっていない。
まとめ - In-Context Learningの実装は難しくない(テキストデータが必要) - ChatGPTには投げられない量のデータを扱える
最後に でかい独自のテキストデータと GPTを簡単に組み合わせる事ができる 色々な活用方法がありますよね!
以上!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![embeddingとretrieverについて embeddingとは文字をベクトル表現に変換すること 雑に言うと文字が下記のようにマシンが処理しやすい形で管理されるようになる [0.002369190799072385, -0.004423773847520351] retrieverとは、情報を検索して言語モデルに情報を渡せるやつ。 今回だと、GPTの言語モデルにsql dumpのデータを検索して渡している。 正直、内部の詳細はわかっていない。](https://files.speakerdeck.com/presentations/9841af2e07fa407dbc6b1e12a1c5c61b/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}