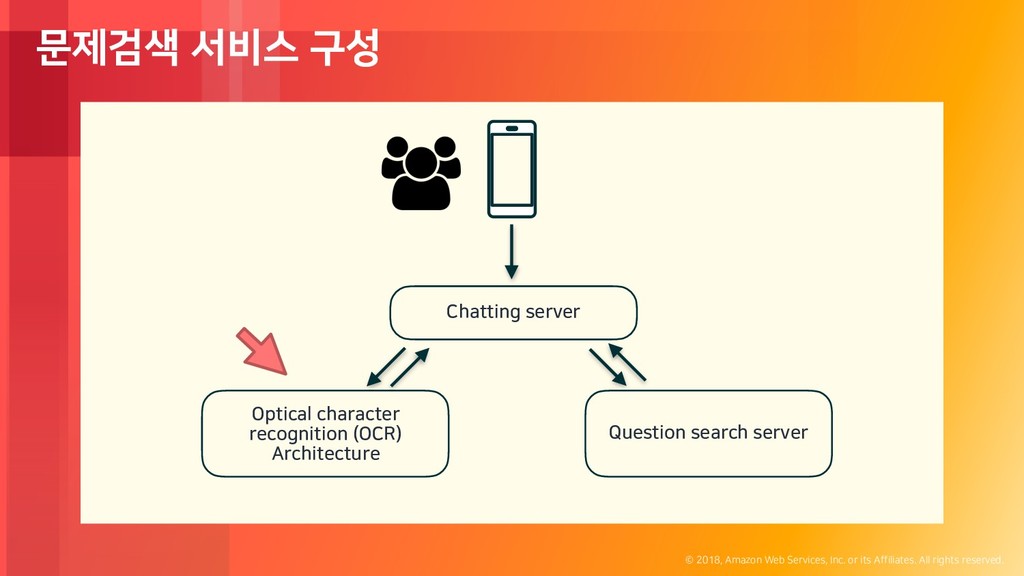
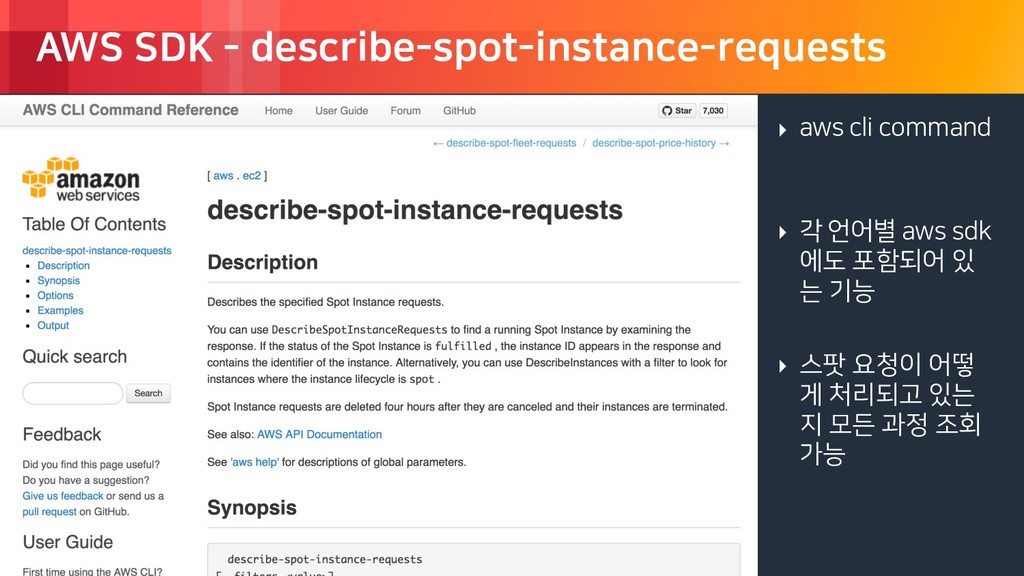
rights reserved. Contents 문제검색 서비스 아키텍쳐 Docker 기반 worker 운영 및 모니터링 - Nvidia-Docker AMI - Count proper number of worker in Instance - Lambda - Health Checker GPU spot 안전하고 효율적으로 쓰기 - Spot Instance - 최적화 배경 - spot to on-demand - Lambda - Availability checker - 효과
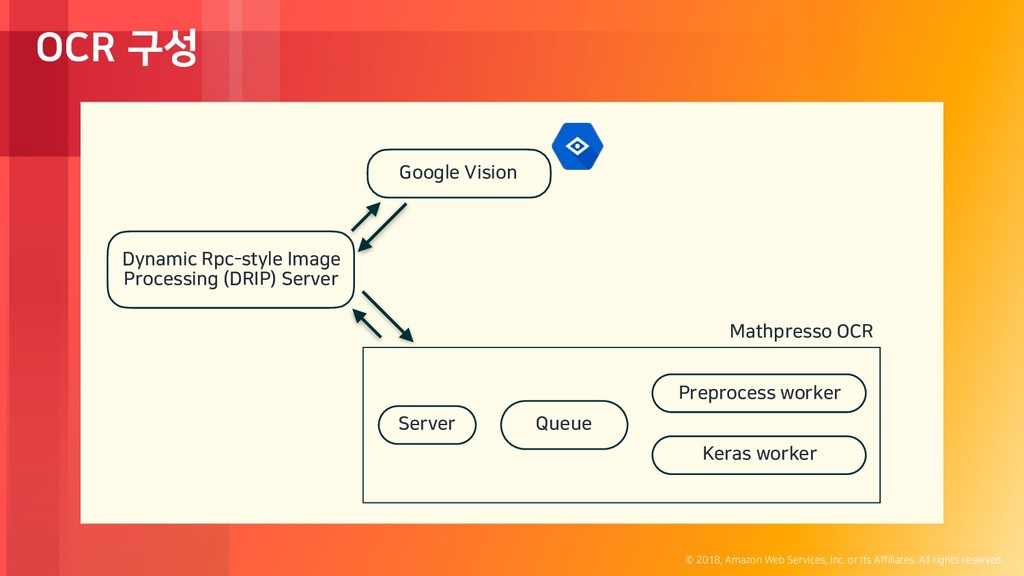
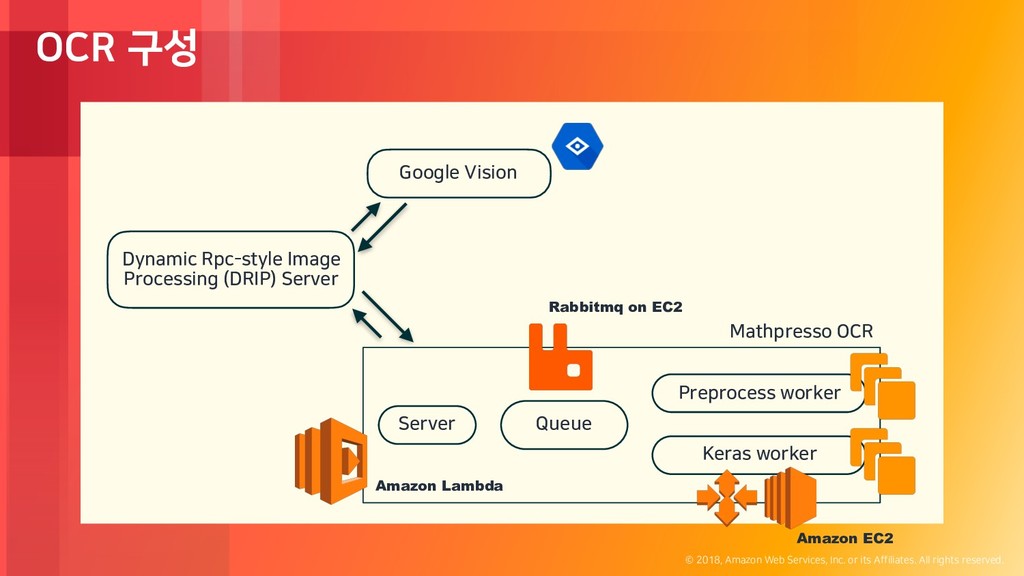
rights reserved. OCR 구성 Dynamic Rpc-style Image Processing (DRIP) Server Google Vision Server Queue Keras worker Preprocess worker Mathpresso OCR Amazon EC2 Rabbitmq on EC2 Amazon Lambda
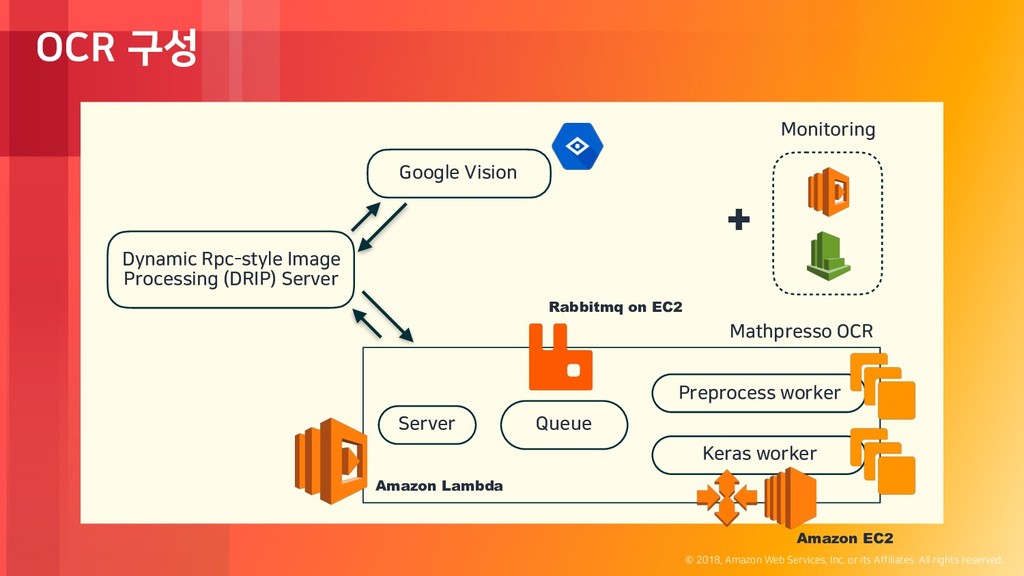
rights reserved. OCR 구성 Dynamic Rpc-style Image Processing (DRIP) Server Google Vision Server Queue Keras worker Preprocess worker Mathpresso OCR Amazon EC2 Rabbitmq on EC2 Amazon Lambda + Monitoring
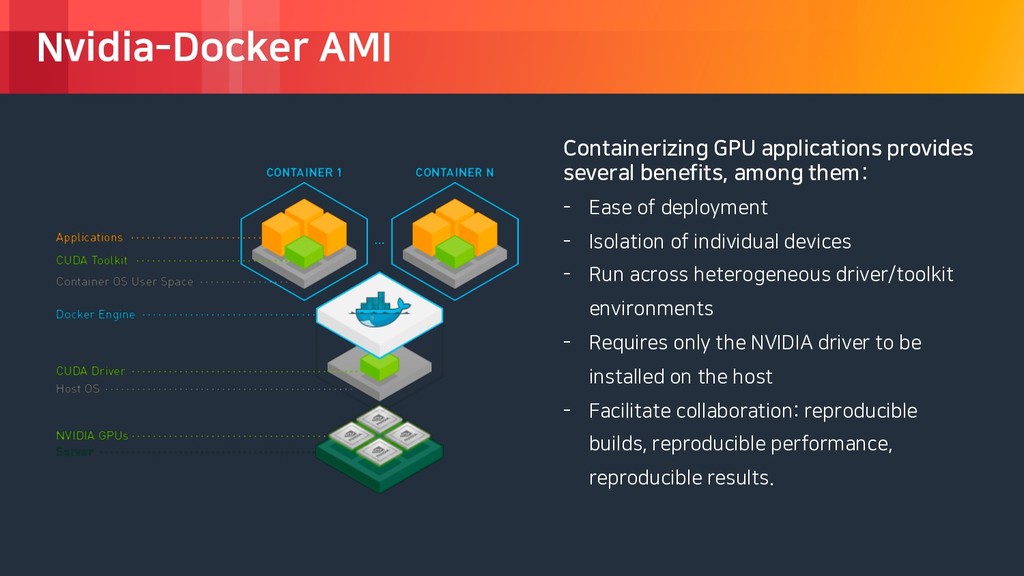
rights reserved. Nvidia-Docker AMI Containerizing GPU applications provides several benefits, among them: - Ease of deployment - Isolation of individual devices - Run across heterogeneous driver/toolkit environments - Requires only the NVIDIA driver to be installed on the host - Facilitate collaboration: reproducible builds, reproducible performance, reproducible results.
rights reserved. Nvidia-Docker AMI ‣ 필요한 딥러닝 패키지들(cuda, tensorrt, opencv...)과 서비스 준비된 프로덕션 코드로 Docker 이미지 생성 ‣ Private Dockerhub ( AWS ECR )에 태그를 달아 업로드 ‣ Nvidia-docker가 설치된 p3 인스턴스로 해당 Docker 이미지 를 받아 실행시키는 AWS AMI 생성 ‣ Auto Scaling - 트래픽에 따라 인스턴스 수 제어
rights reserved. Nvidia-Docker AMI ‣ 필요한 딥러닝 패키지들(cuda, tensorrt, opencv...)과 서비스 준비된 프로덕션 코드로 Docker 이미지 생성 ‣ Private Dockerhub ( AWS ECR )에 태그를 달아 업로드 ‣ Nvidia-docker가 설치된 p3 인스턴스로 해당 Docker 이미지 를 받아 실행시키는 AWS AMI 생성 ‣ Auto Scaling - 트래픽에 따라 인스턴스 수 제어 CloudWatch? 어떤 기준으로?
rights reserved. Count proper number of worker in Instance ‣ GPU Utilization / Search log - 인스턴스 기준 스케일링? - 인스턴스는 동작하는 상태이지만 내부의 worker는 동작하지 않을 수도 있다. (worker 코 드를 수정한 개발자의 실수, 라이브러리 오류, 시스템 오류 등 가능성 존재) - 사내 서버도 완전히 믿을 수는 없음 - 최초의 시행착오 - 사내/ AWS 서버에서 동작하는 worker 개별의 상태를 알 수 있는 지표 필요
rights reserved. Monitoring GPU Utilization with Amazon Cloudwatch https://aws.amazon.com/ko/blogs/machine-learning/monitoring-gpu-utilization-with-amazon-cloudwatch/
rights reserved. Count proper number of worker in Instance ‣ GPU Utilization / Search log - 사내/ AWS 서버에서 동작하는 worker 개별의 상태를 알 수 있는 지표 필요 - GPU Util * EC2 기본 지원 X, 데이터 수집 및 전송하는 agent에 대한 개발이 추가적으로 필요 - Search log * 이미 수집하고 있던 데이터, 추가적인 작업 없이 활용 가능 - Search log로 사내/ AWS 서버의 worker cluster load rates를 계산하는 알고리즘을 개발 ( = GPU load rates) - AWS Lamba에 해당 알고리즘 탑재, 주기적으로 Monitoring & Scaling 수행
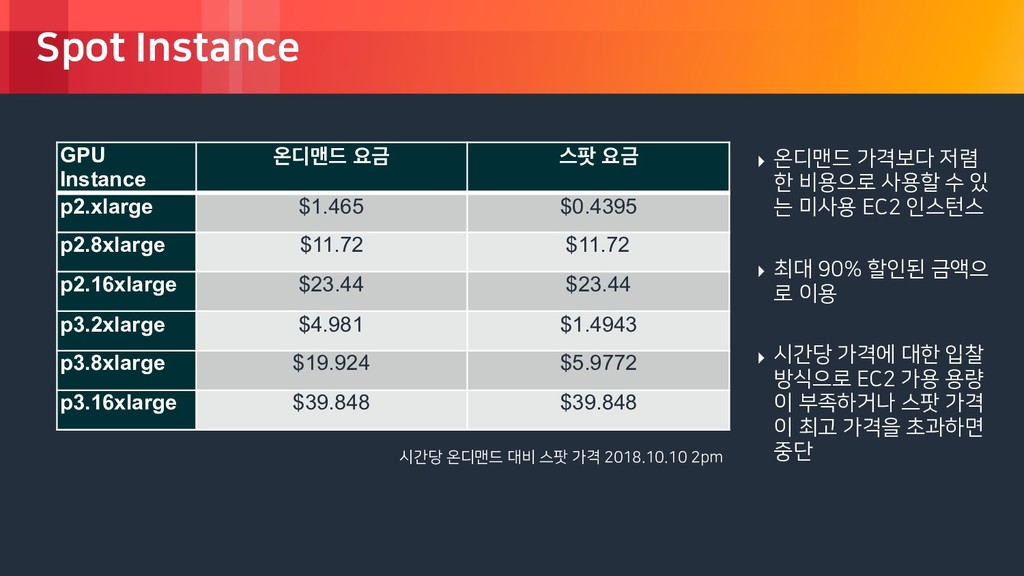
rights reserved. Spot Instance 시간당 온디맨드 대비 스팟 가격 2018.10.10 2pm ‣ 온디맨드 가격보다 저렴 한 비용으로 사용할 수 있 는 미사용 EC2 인스턴스 ‣ 최대 90% 할인된 금액으 로 이용 ‣ 시간당 가격에 대한 입찰 방식으로 EC2 가용 용량 이 부족하거나 스팟 가격 이 최고 가격을 초과하면 중단 GPU Instance ৡ٣ݔ٘ ਃӘ झ౽ ਃӘ p2.xlarge $1.465 $0.4395 p2.8xlarge $11.72 $11.72 p2.16xlarge $23.44 $23.44 p3.2xlarge $4.981 $1.4943 p3.8xlarge $19.924 $5.9772 p3.16xlarge $39.848 $39.848
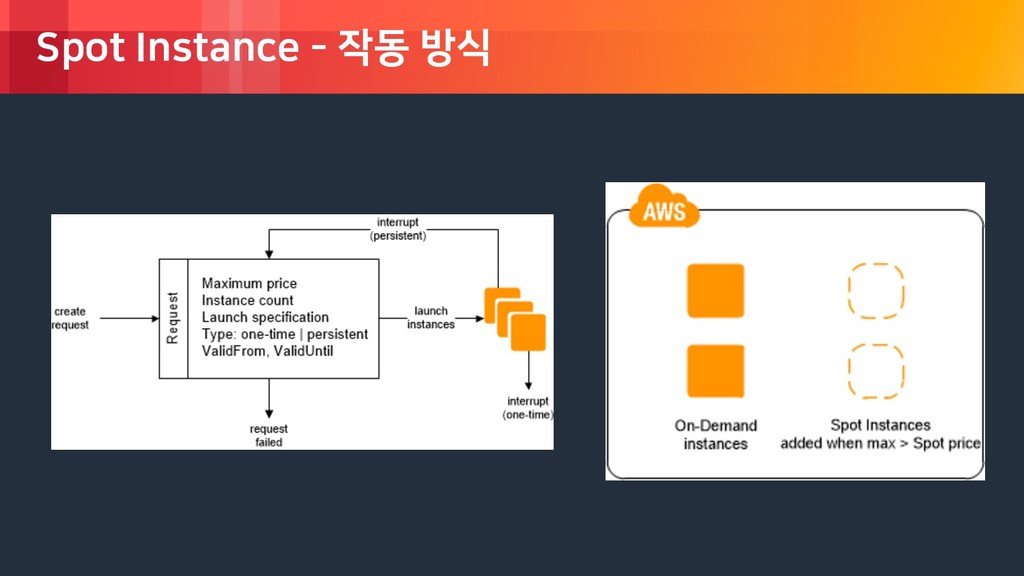
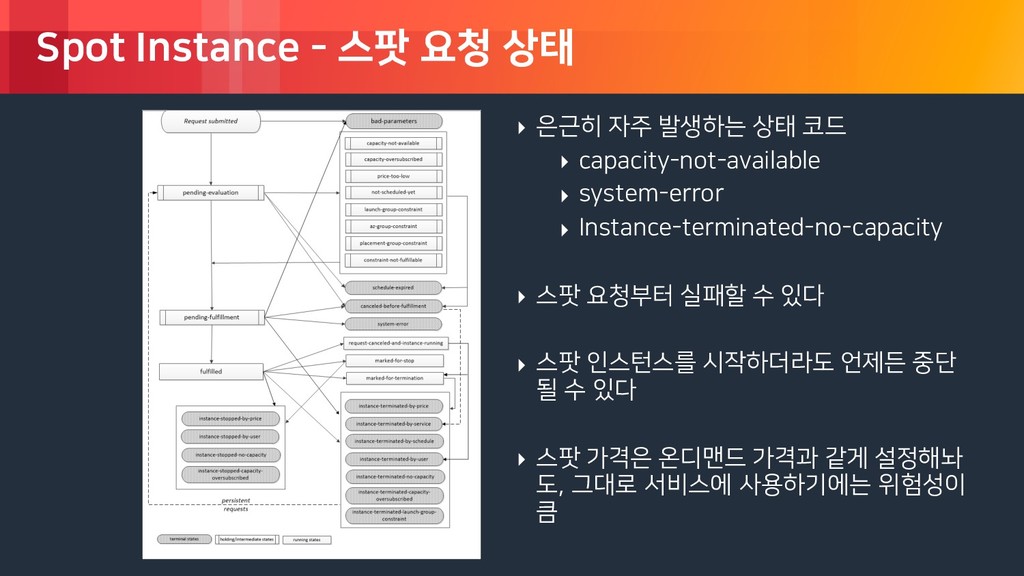
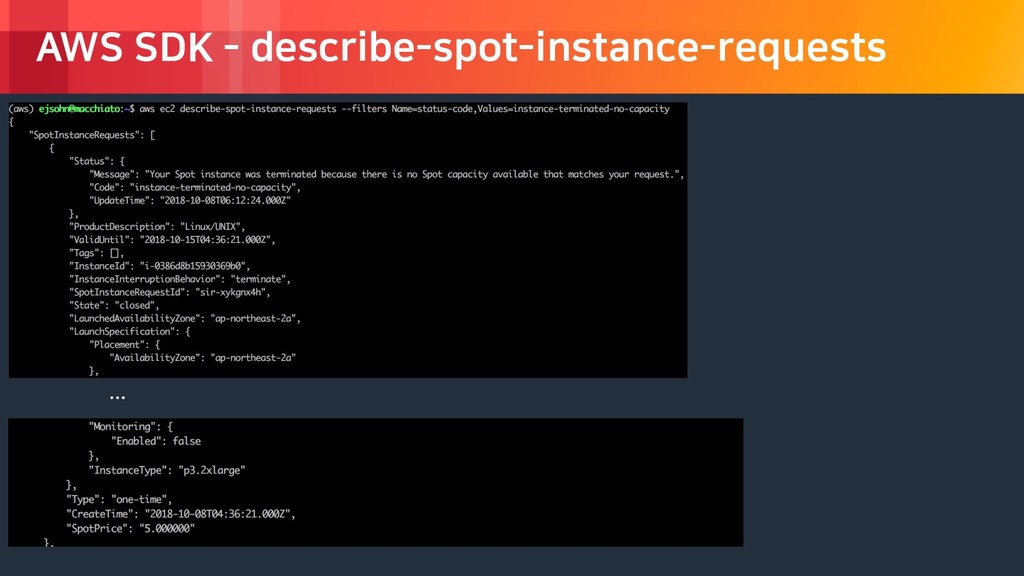
rights reserved. Spot Instance - 스팟 요청 상태 ‣ 은근히 자주 발생하는 상태 코드 ‣ capacity-not-available ‣ system-error ‣ Instance-terminated-no-capacity ‣ 스팟 요청부터 실패할 수 있다 ‣ 스팟 인스턴스를 시작하더라도 언제든 중단 될 수 있다 ‣ 스팟 가격은 온디맨드 가격과 같게 설정해놔 도, 그대로 서비스에 사용하기에는 위험성이 큼
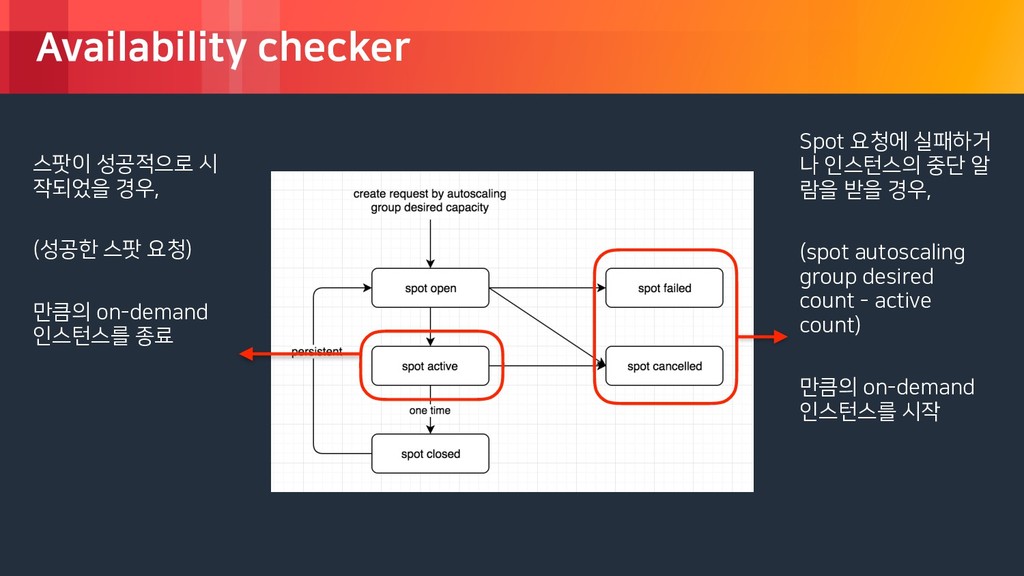
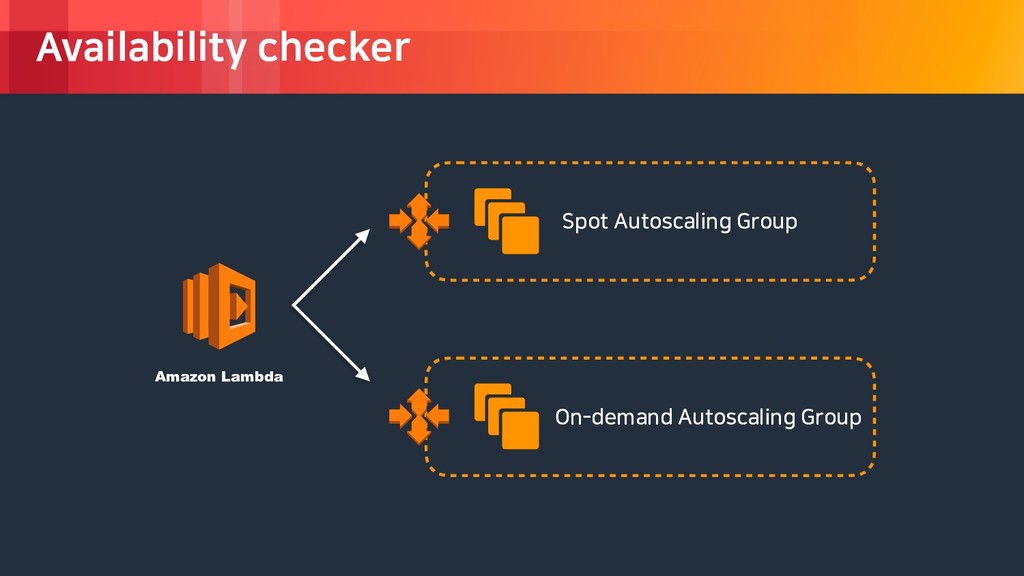
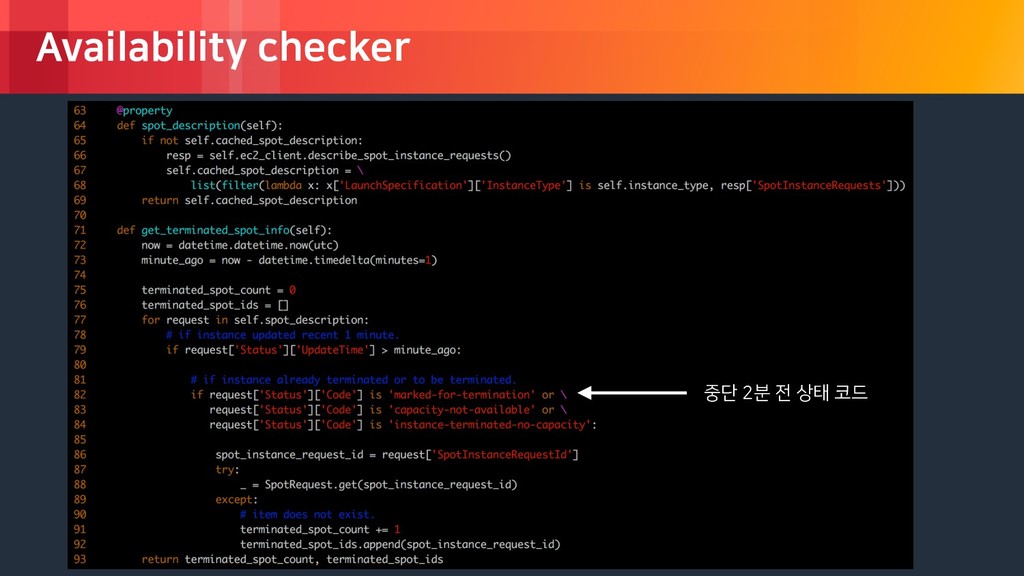
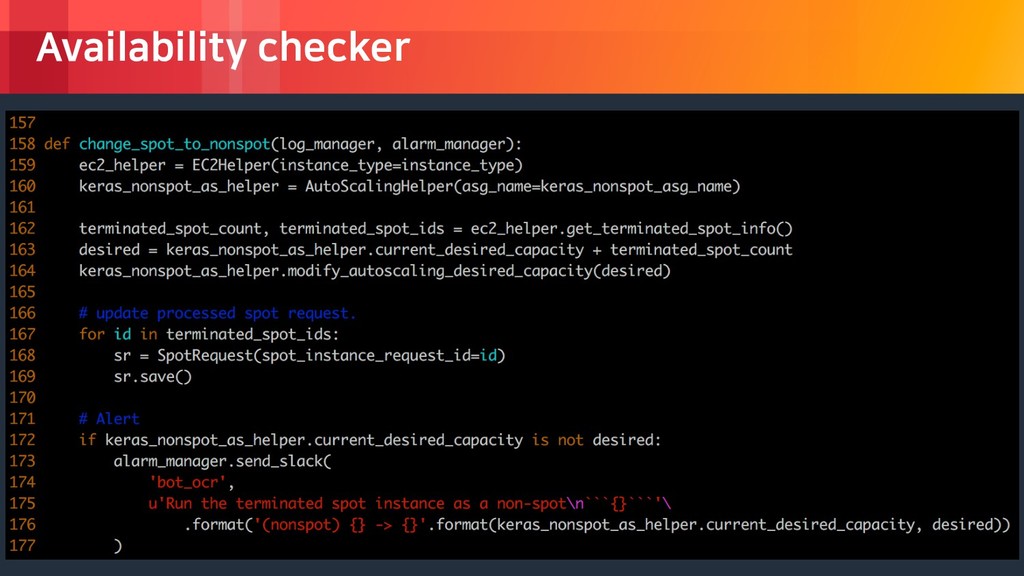
rights reserved. Availability checker Spot 요청에 실패하거 나 인스턴스의 중단 알 람을 받을 경우, (spot autoscaling group desired count - active count) 만큼의 on-demand 인스턴스를 시작 스팟이 성공적으로 시 작되었을 경우, (성공한 스팟 요청) 만큼의 on-demand 인스턴스를 종료
rights reserved. 효과 ‣ GPU 비용 1/10 ‣ 사내/ AWS GPU 서버 내의 서비스 방식 통일 ‣ 기존의 인스턴스 기반 스케일링을 worker 기반 스케일링으로 전환 ‣ 분단위로 필요한 만큼의 스팟을 생성/종료 ‣ 스팟 사용에 문제가 있을 경우 온디맨드 인스턴스를 사용 후 전환
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}