This talk was presented at the inaugural Elastic{ON} conference, http://elasticon.com
Session Abstract:
Sometimes we need to step back and take a look at the bigger picture - not just counting huge piles of individual log records, but reasoning about the behaviors of the people who are ultimately generating this firehose of data. While your DevOps folks care deeply about log records from a machine utlization perspective, marketing wants to know what these records tell us about the customers' needs.
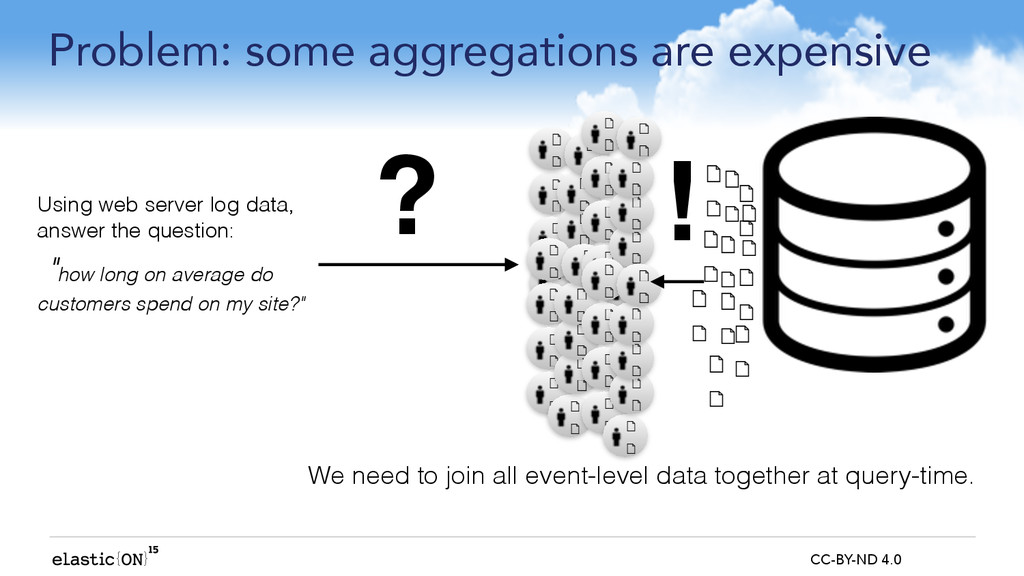
Elasticsearch Aggregations are a great feature but are not a panacea. We can happily use them to summarise complex things like the number of web requests per day broken down by geography and browser type on a busy website, but we would quickly run out of memory if we tried to calculate something as simple as a single number for the average duration of visitor web sessions when using the very same dataset.
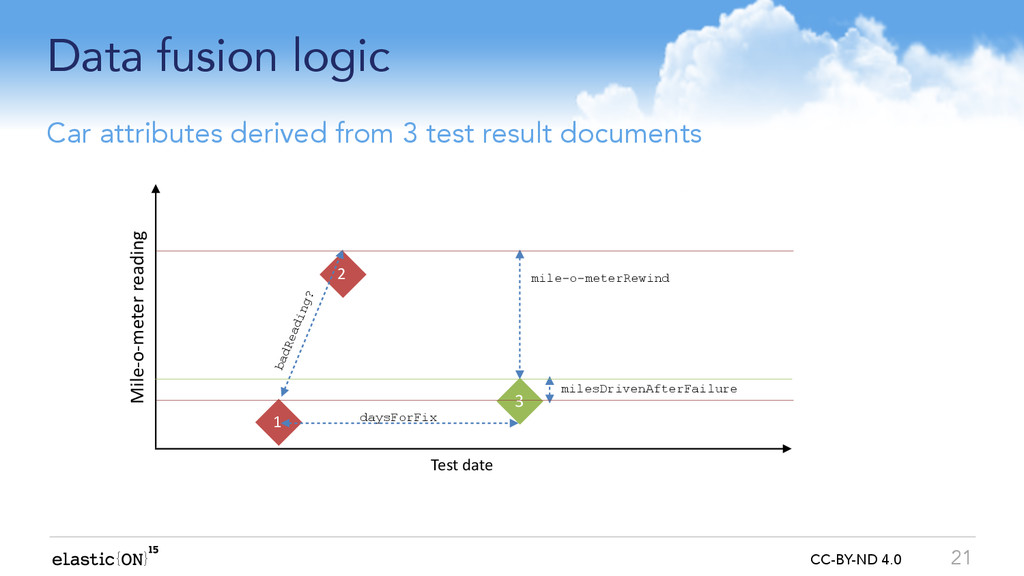
Why does this occur? A web session duration is an example of a behavioural attribute not held on any one log record; it has to be derived by finding the first and last records for each session in our weblogs, requiring some complex query expressions and a lot of memory to connect all the data points.
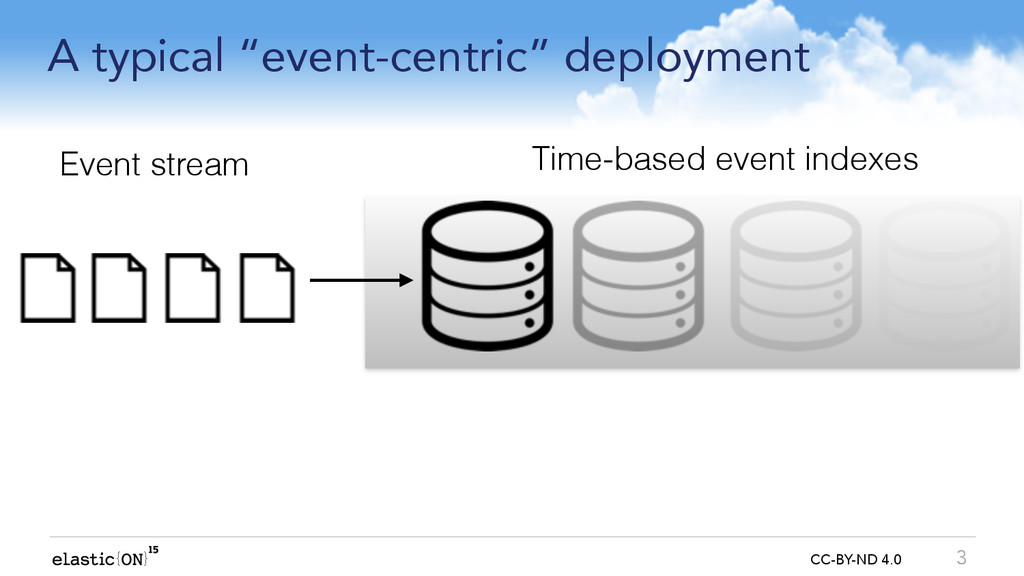
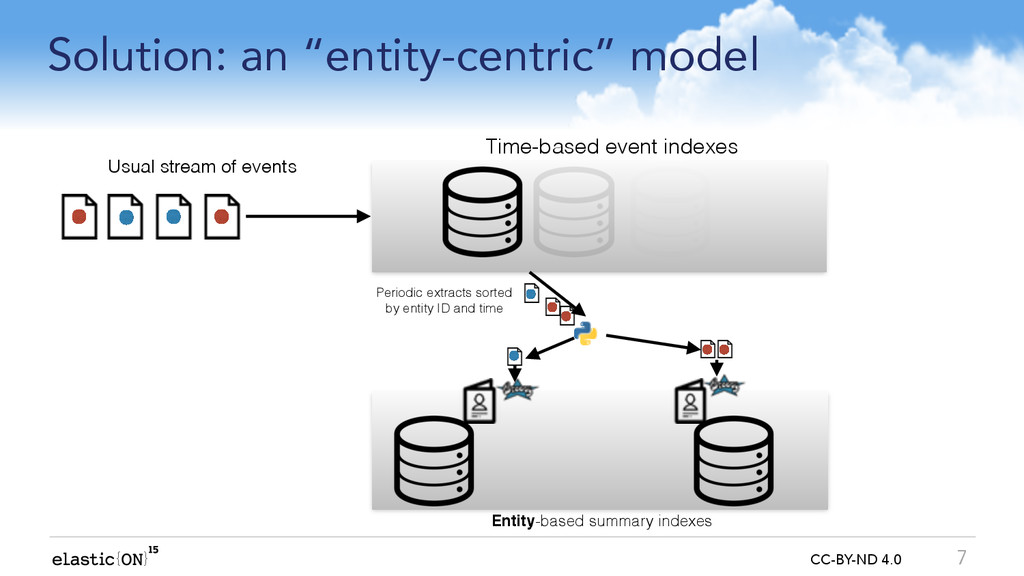
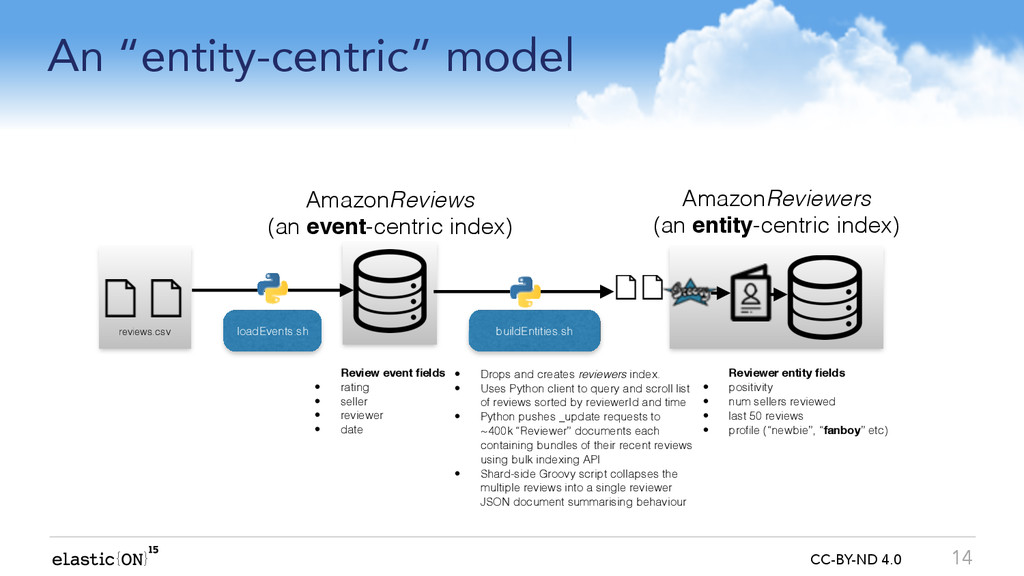
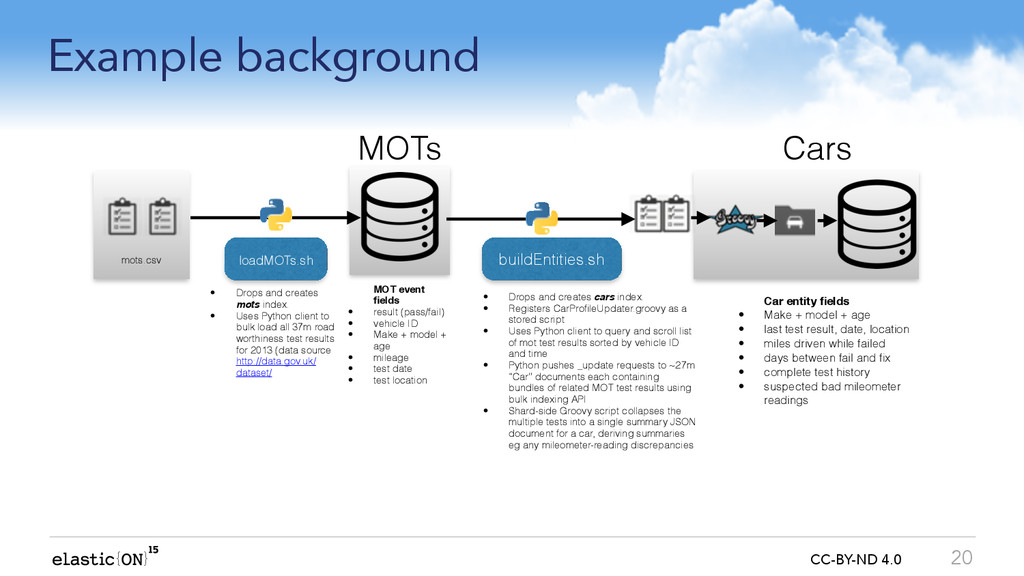
We can maintain a more useful joined-up-picture if we run an ongoing background process to fuse related events from one index into ?entity-centric? summaries in another index e.g:
Web log events summarised into ?web session? entities
Road-worthiness test results summarised into ?car? entities
Reviews in a marketplace summarised into a ?reviewer? entity
Using real data, this session will demonstrate how to incrementally build entity-centric indexes alongside event-centric indexes by using simple scripts to uncover interesting behaviours that accumulate over time. We'll explore:
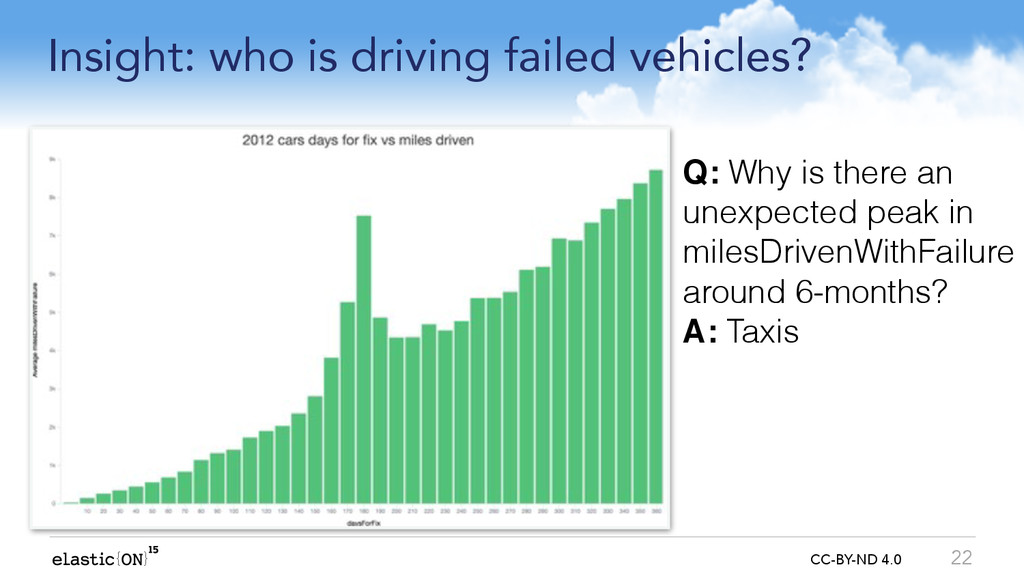
* Which cars are driven long distances after failing roadworthiness tests?
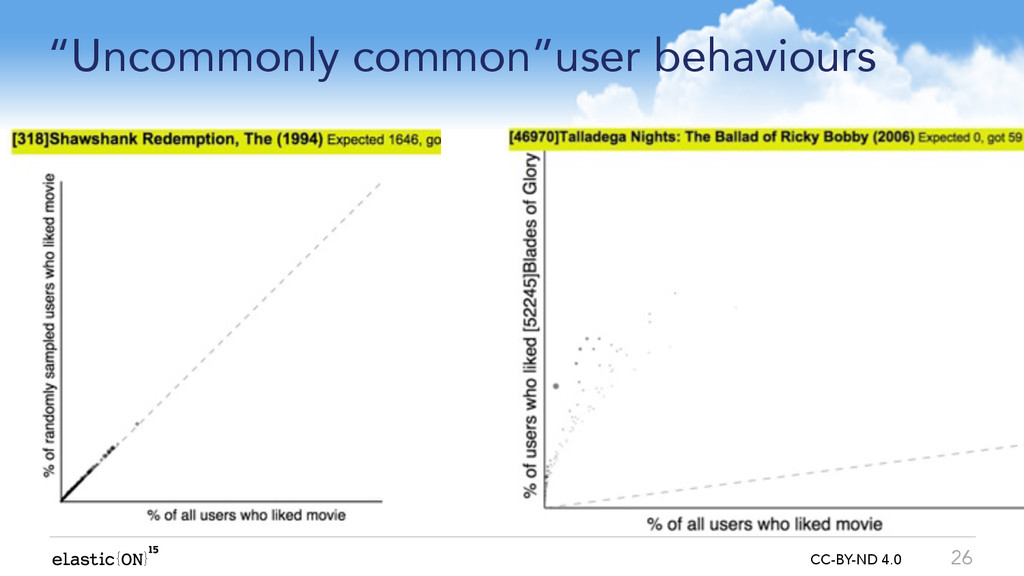
* Which website visitors look to be behaving like ?bots??
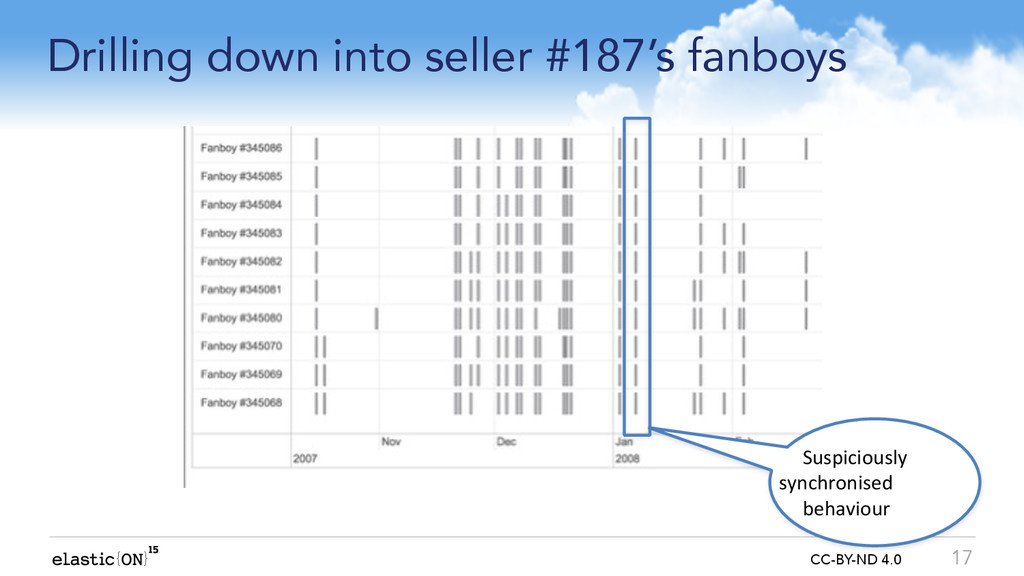
* Which seller in my marketplace has employed an army of ?shills? to boost his feedback rating?
Attendees will leave this session with all the tools required to begin building entity-centric indexes and using that data to derive richer business insights across every department in their organization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}