http://www.meetup.com/Chicago-Elastic-Fantastics/events/231694268/
Acquisition of social media data with the Elastic Stack at a greater scale.
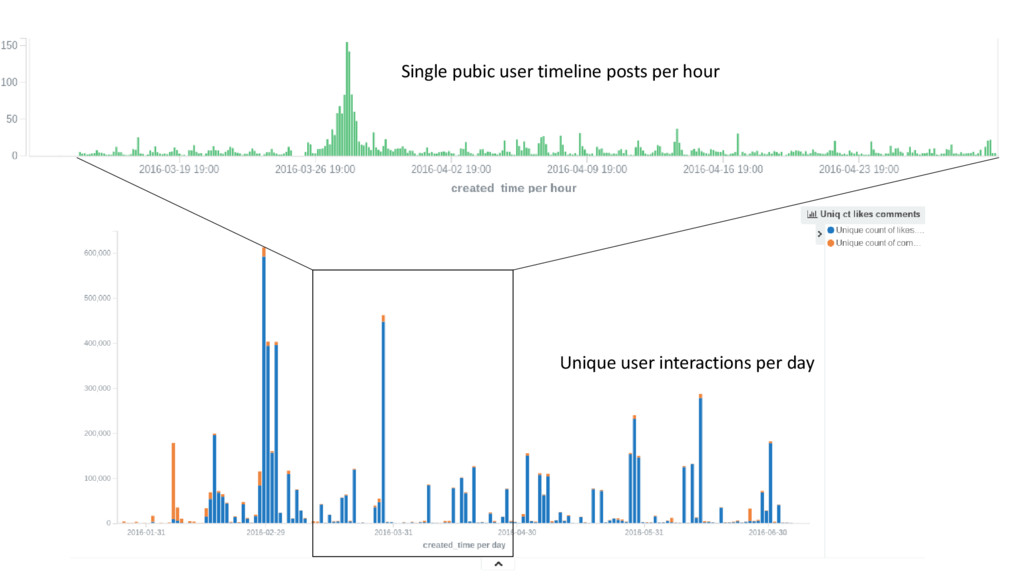
You don't truly understand some technology unless you are able to break it and fix it. In this talk I will share my experience in breaking elasticsearch while indexing massive amounts of social media data from Facebook and Twitter. We will discuss the main challenges faced and lessons learned along the way of my journey with the Elastic Stack while staying on the edge of the hardware limits.
Miroslav Mihaylov is an experimental physicist turned full stack developer with 2 years of experience in elasticsearch. I have been extensively using the Elastic Stack in the past year as a part of an ongoing research effort in the field of Social Network Analysis and Text Data Mining.
{kind=link}
{kind=link}
{kind=link}
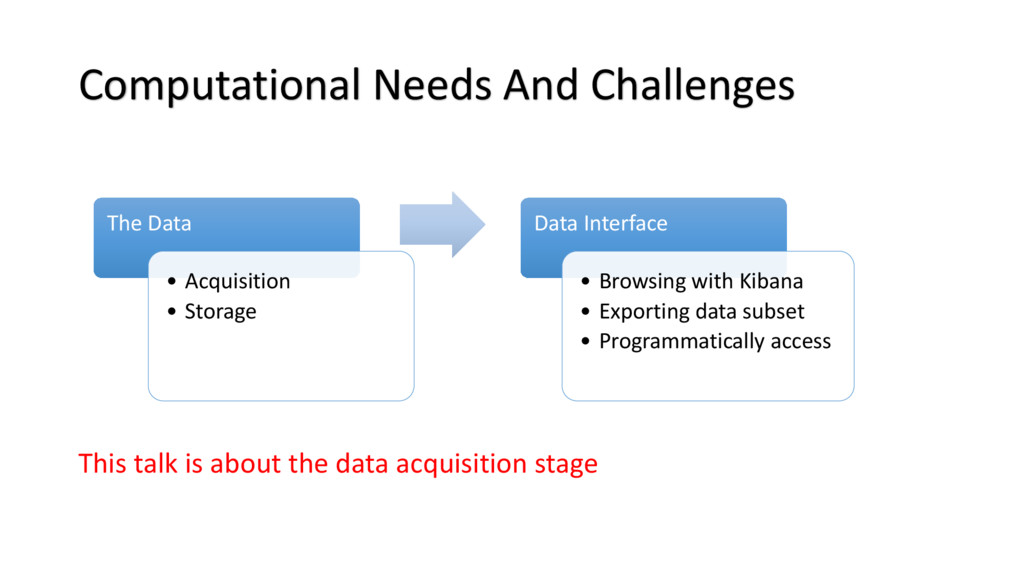{kind=link}
{kind=link}
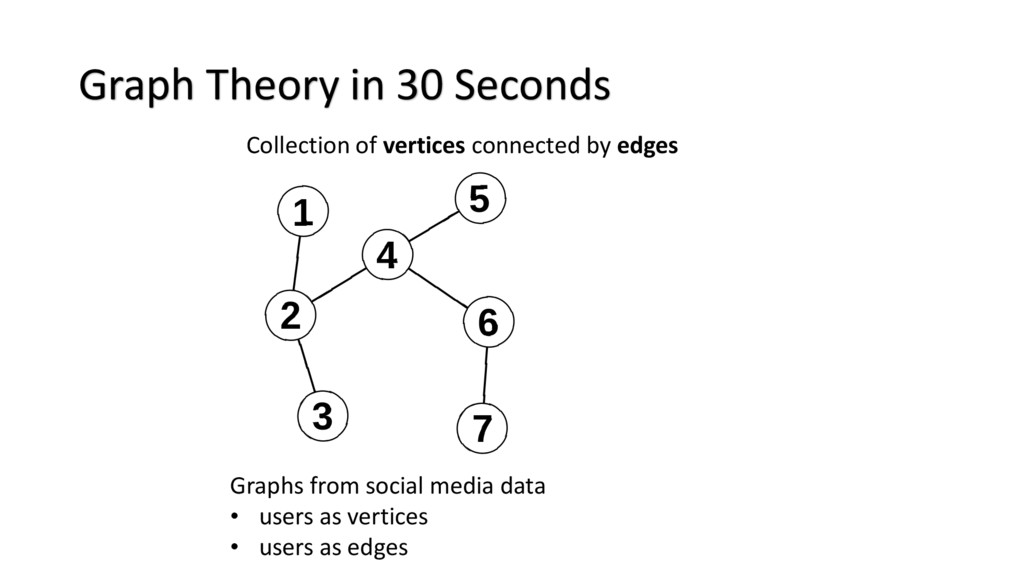{kind=link}
{kind=link}
{kind=link}
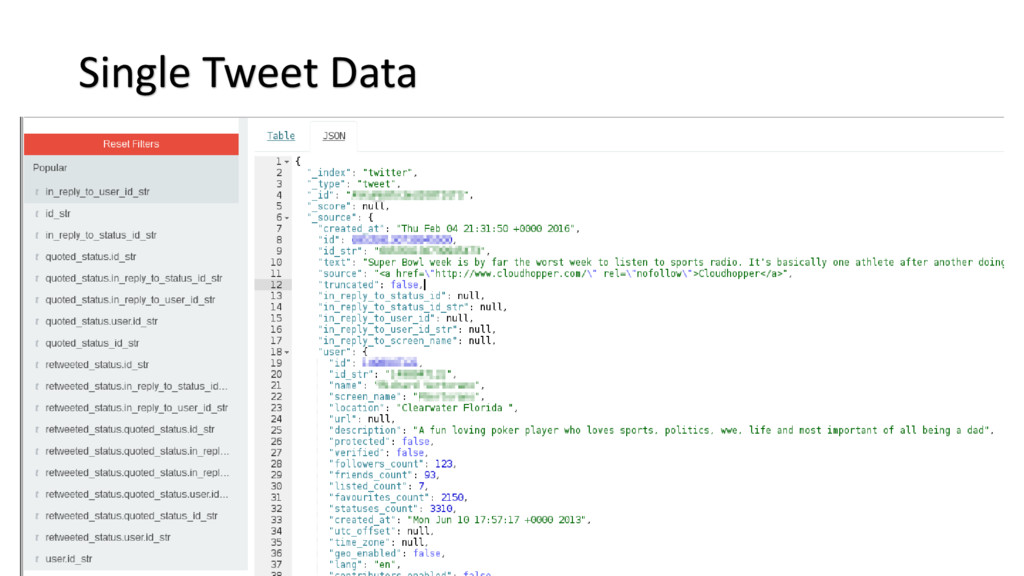{kind=link}
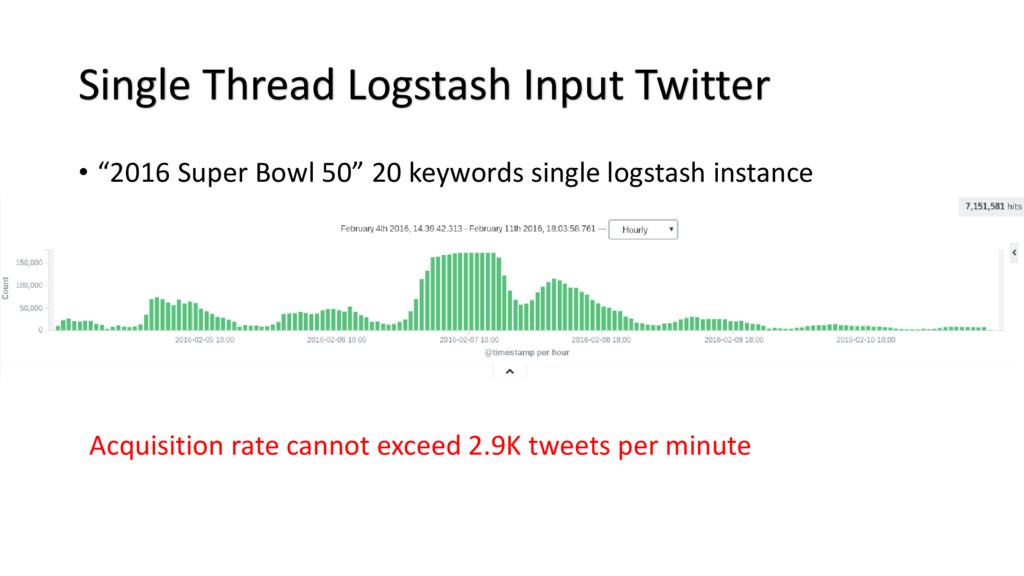{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}