fields • Automatic optimizations for range searches • Massive aggregations with partitioning • Faster geo-distance sorting • Faster geo-ip lookups and for logs and for numbers and for geo and ... ^
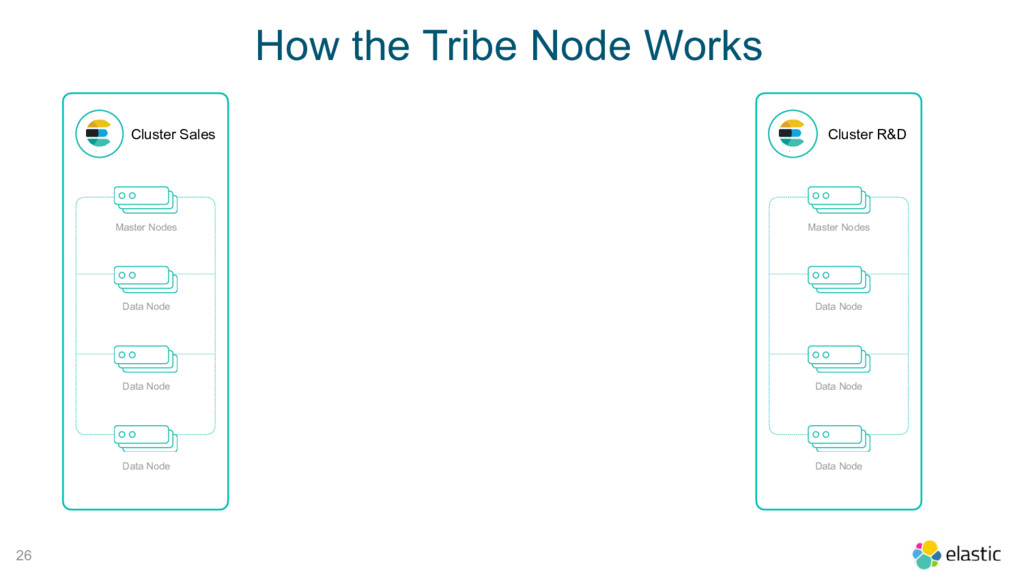
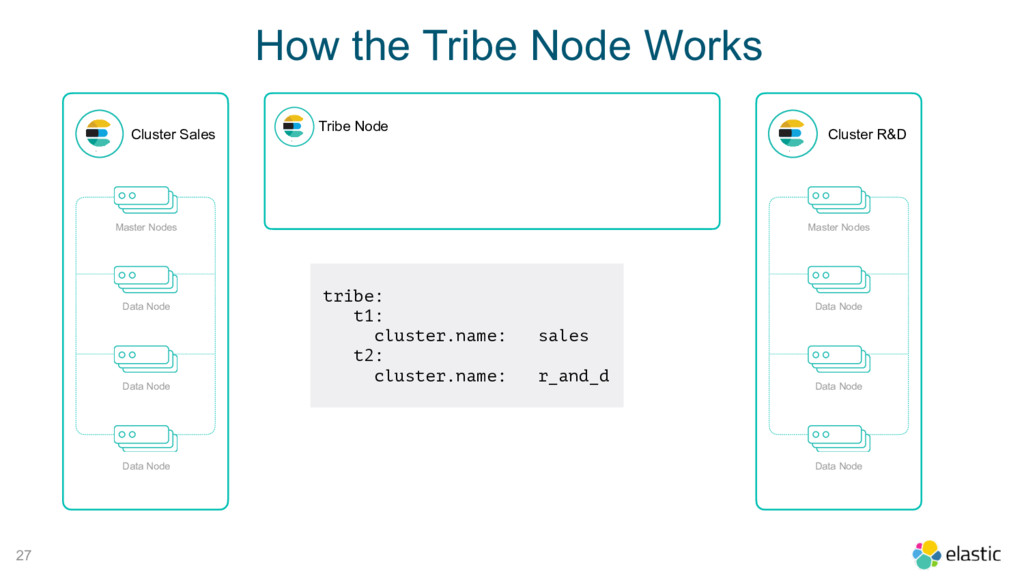
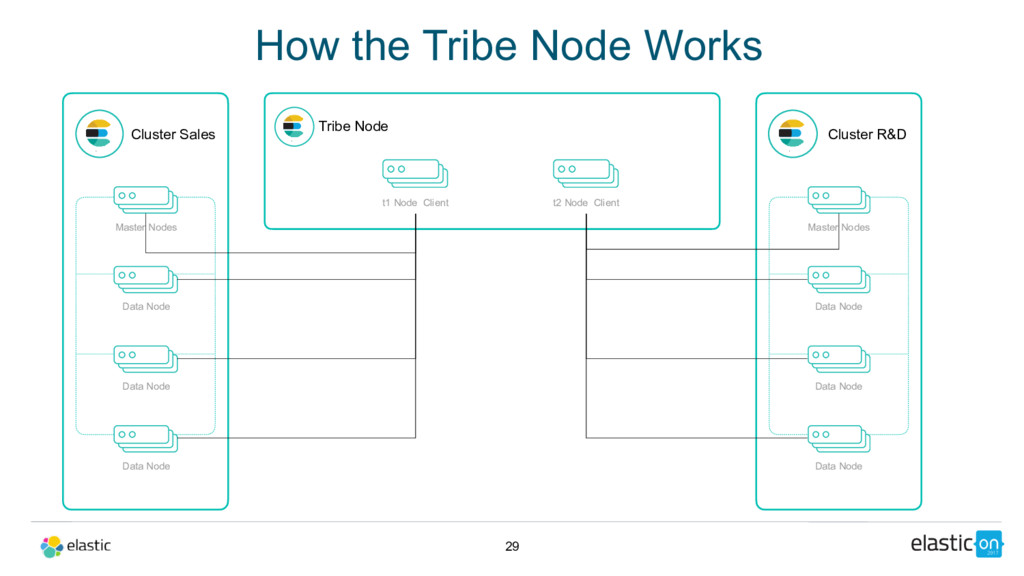
Node Tribe Node Cluster R&D Master Nodes Data Node Data Node Data Node tribe: t1: cluster.name: sales t2: cluster.name: r_and_d How the Tribe Node Works
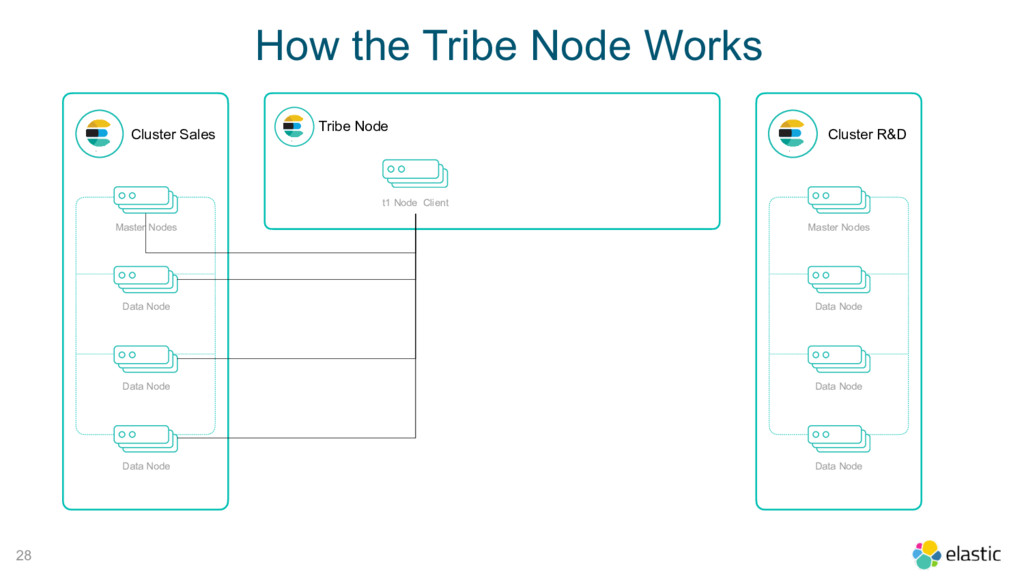
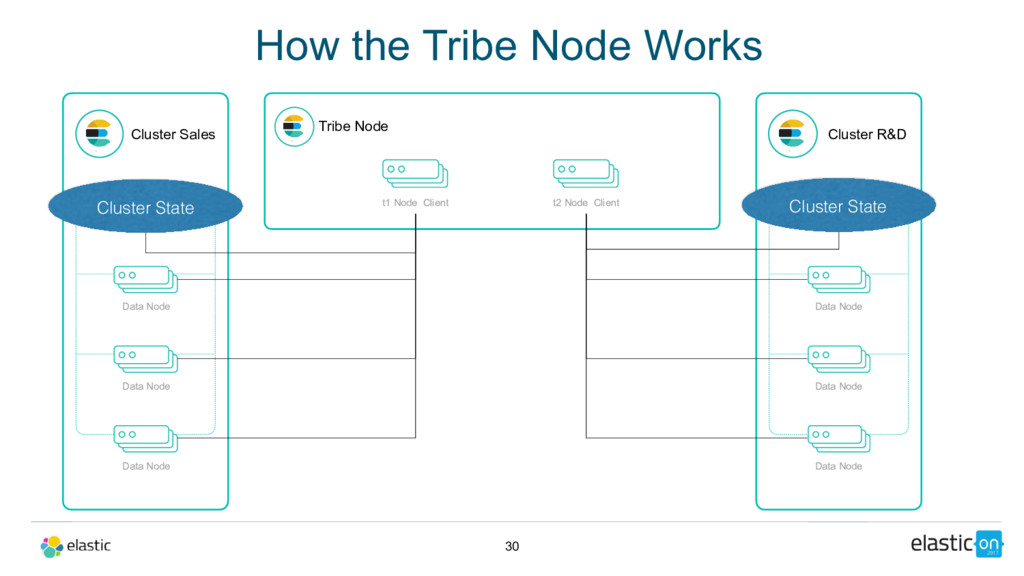
Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client 30 Cluster State Cluster State How the Tribe Node Works
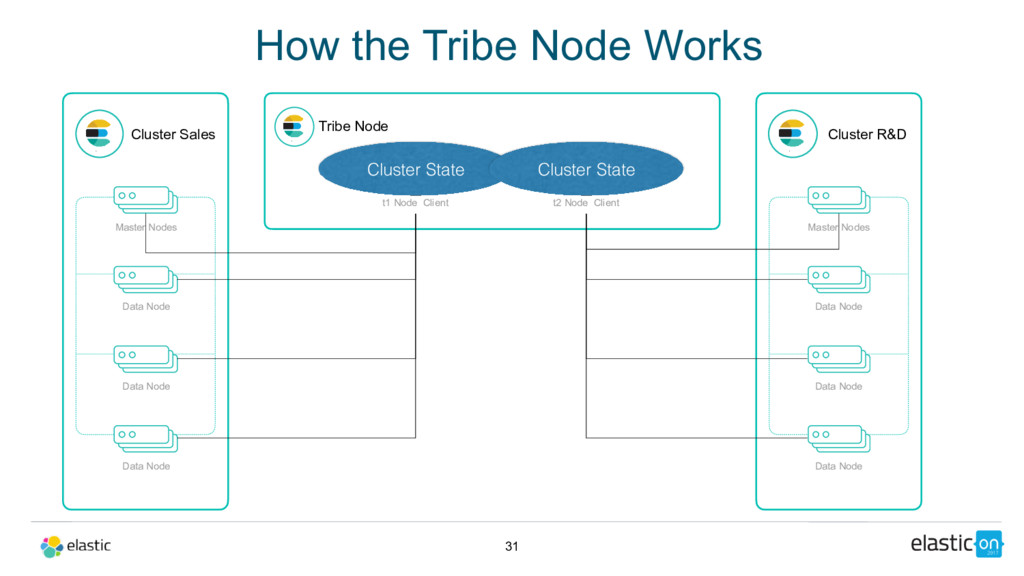
Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client 31 Cluster State Cluster State How the Tribe Node Works
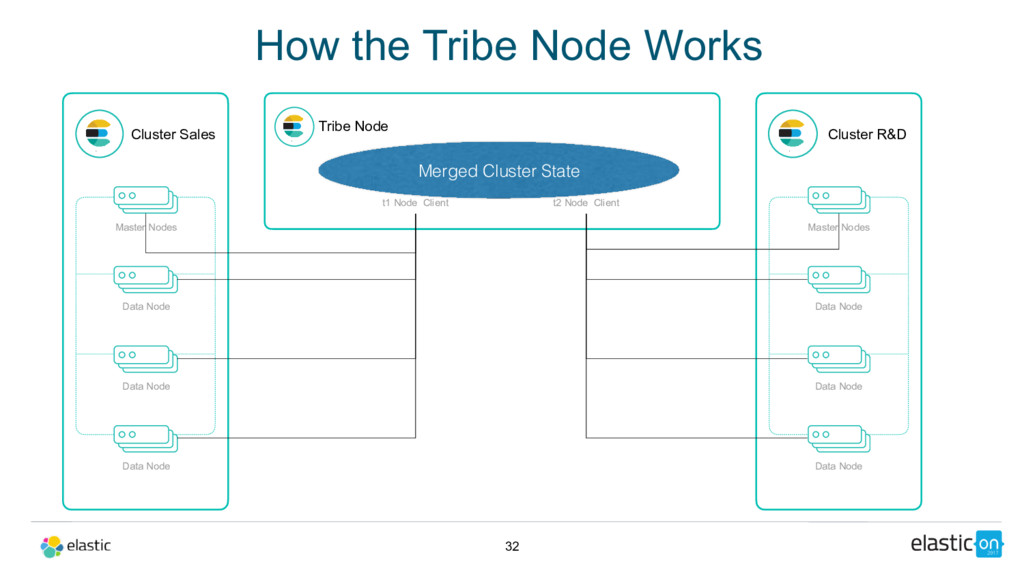
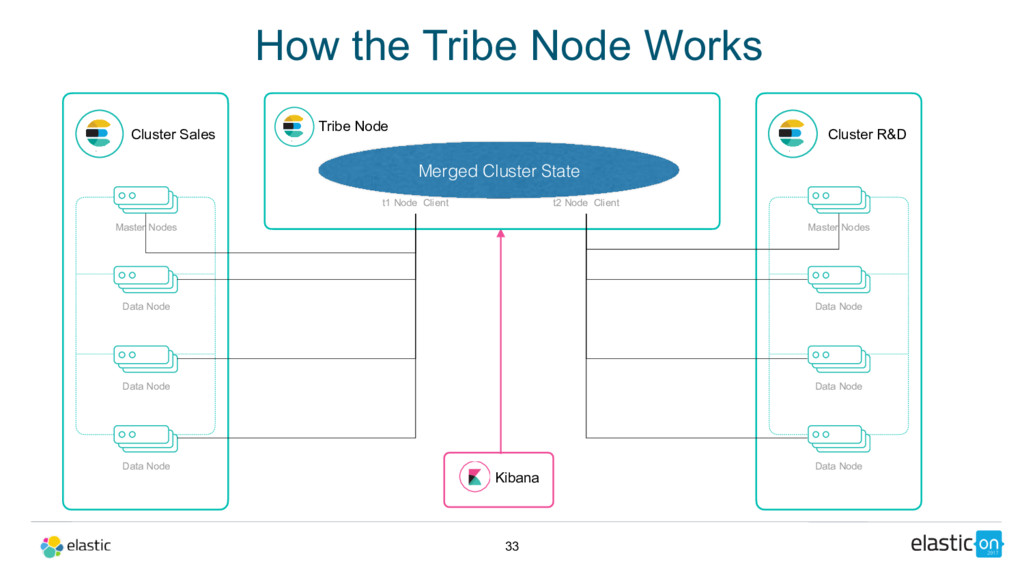
Data Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Merged Cluster State How the Tribe Node Works
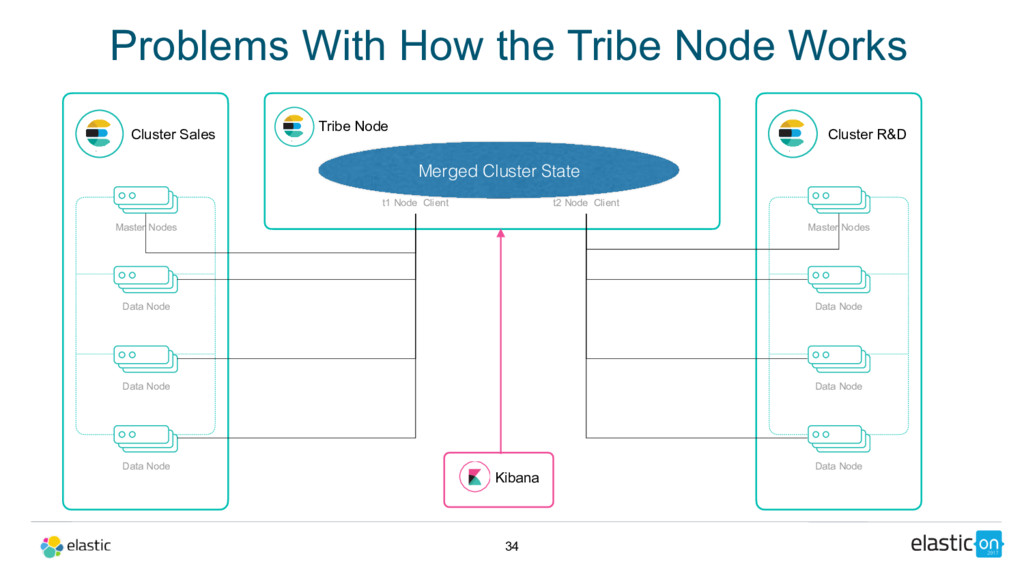
Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client 34 Problems With How the Tribe Node Works Merged Cluster State Kibana
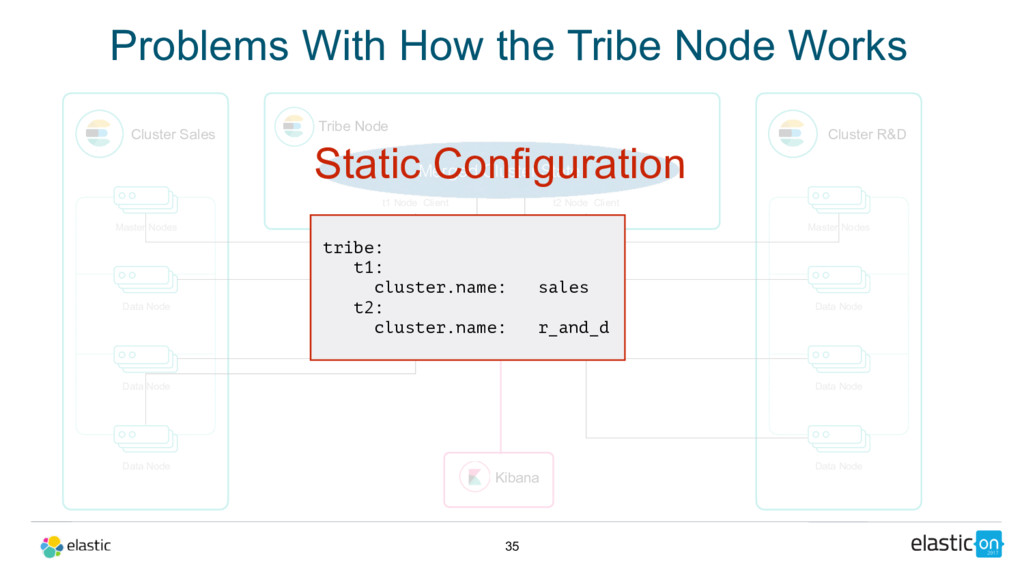
Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Merged Cluster State Kibana Static Configuration tribe: t1: cluster.name: sales t2: cluster.name: r_and_d Problems With How the Tribe Node Works
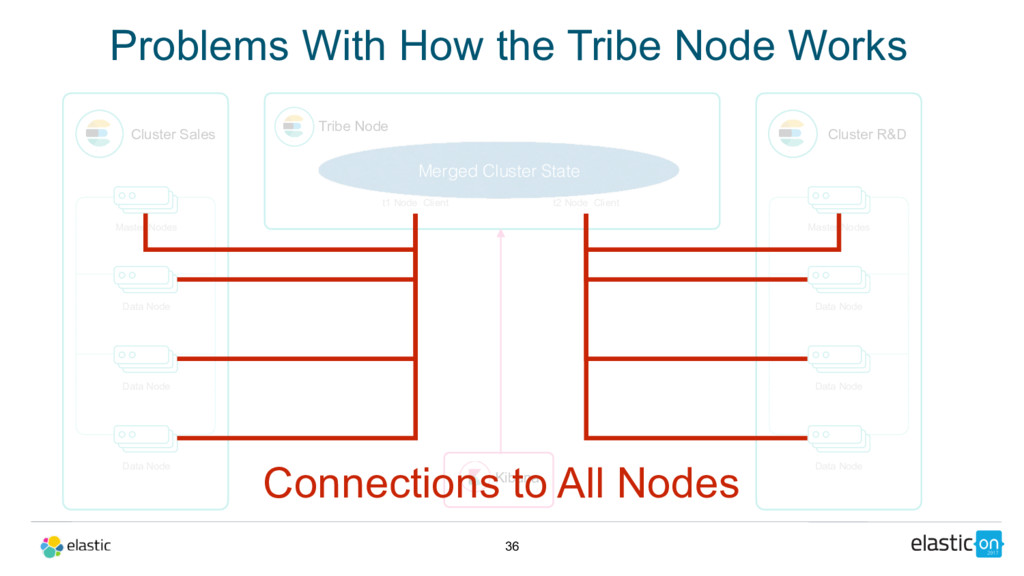
Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Kibana Merged Cluster State Connections to All Nodes Problems With How the Tribe Node Works
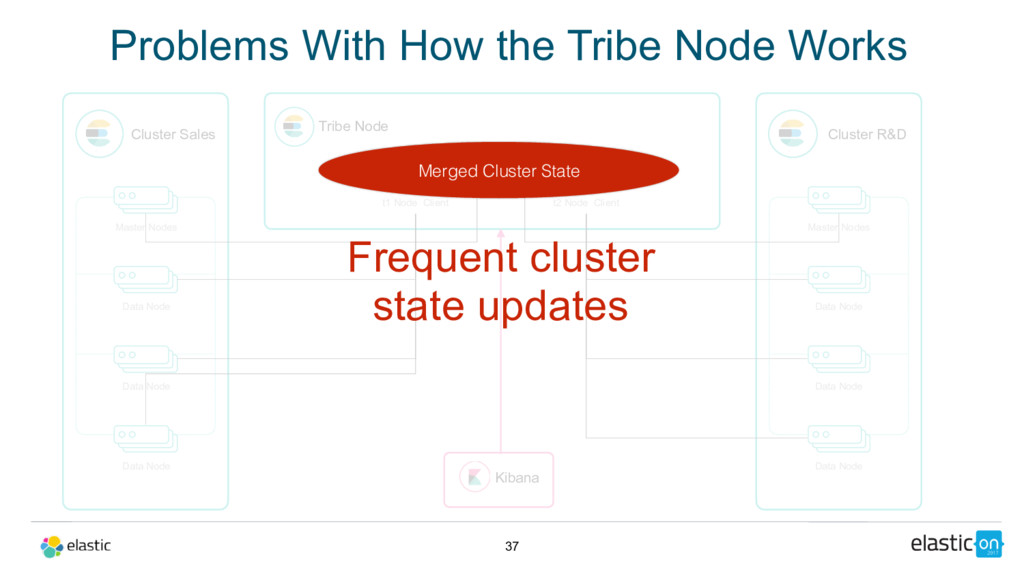
Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Kibana Merged Cluster State Frequent cluster state updates Problems With How the Tribe Node Works
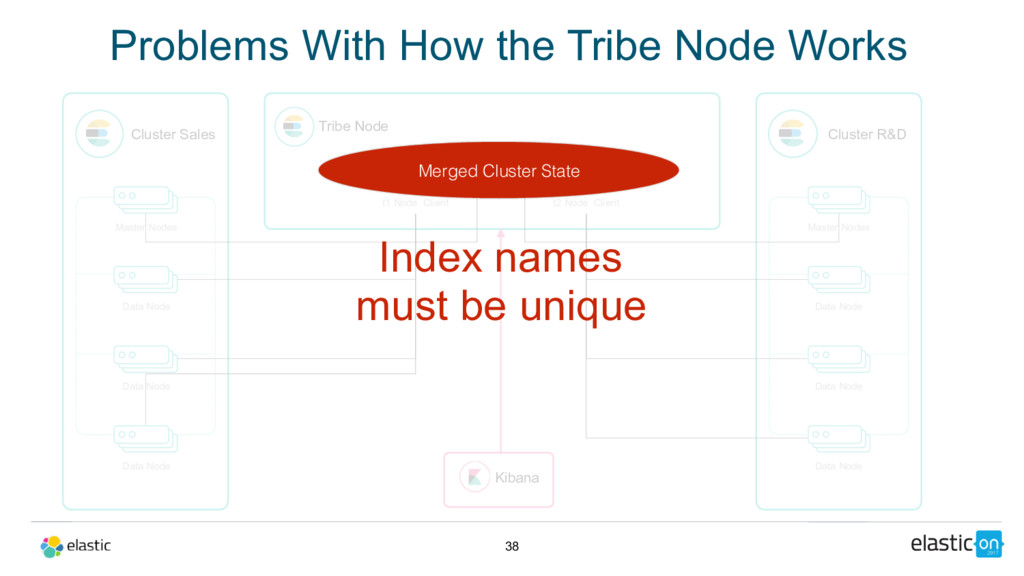
Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Kibana Merged Cluster State Index names must be unique Problems With How the Tribe Node Works
Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Merged Cluster State Tribe Node Kibana No master node No index creation Problems With How the Tribe Node Works
Node Tribe Node t1 Node Client Cluster R&D Master Nodes Data Node Data Node Data Node t2 Node Client Merged Cluster State Kibana Reduce results from many shards Problems With How the Tribe Node Works
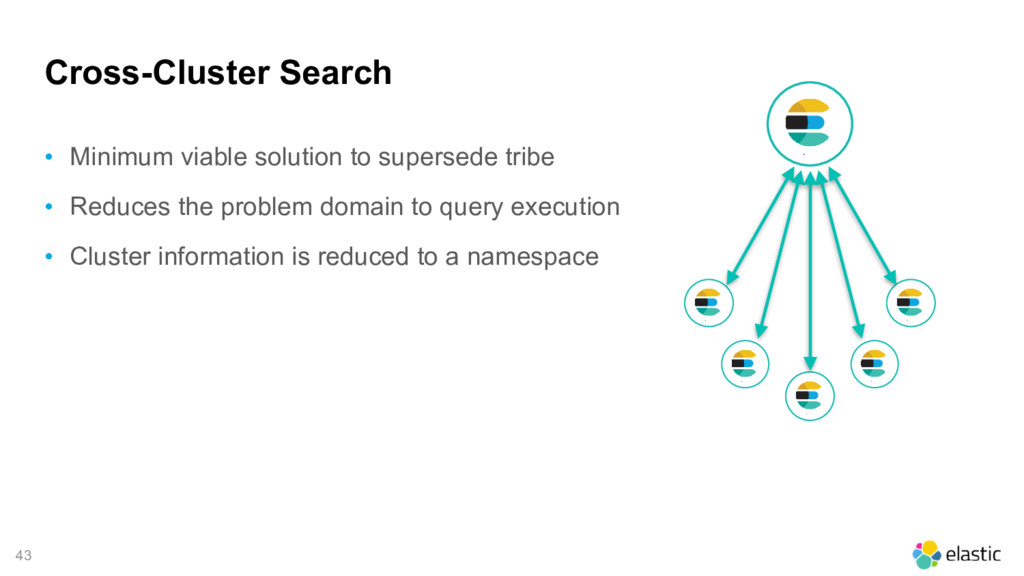
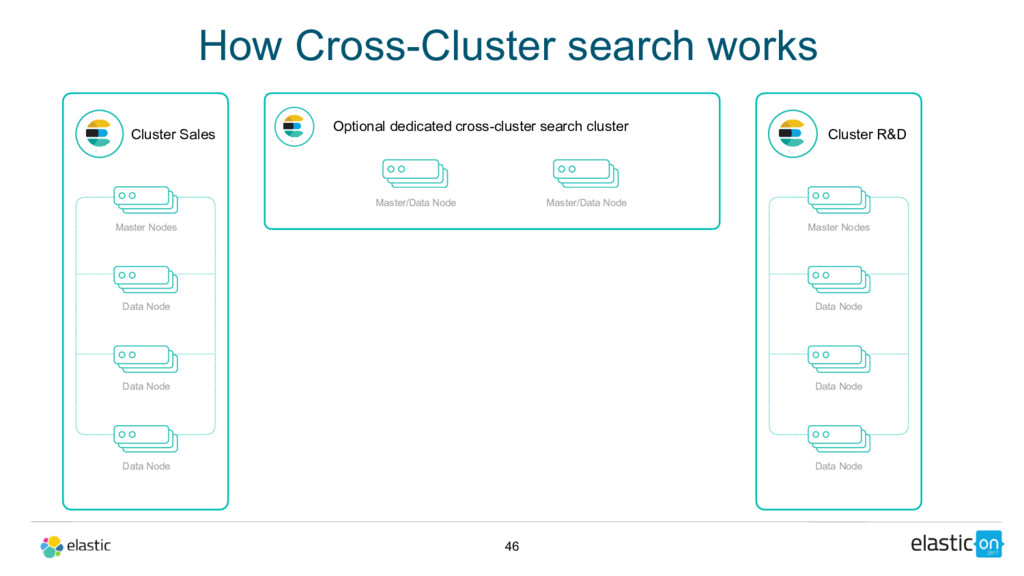
Node Data Node Data Node Optional dedicated cross-cluster search cluster Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node No cluster state updates Optional dedicated cross-cluster search cluster
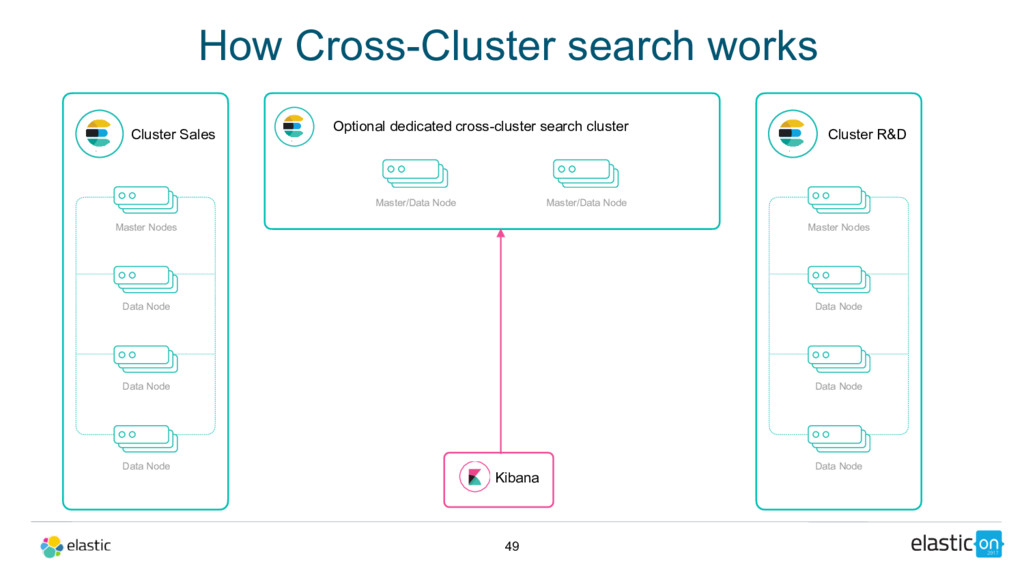
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana Optional dedicated cross-cluster search cluster
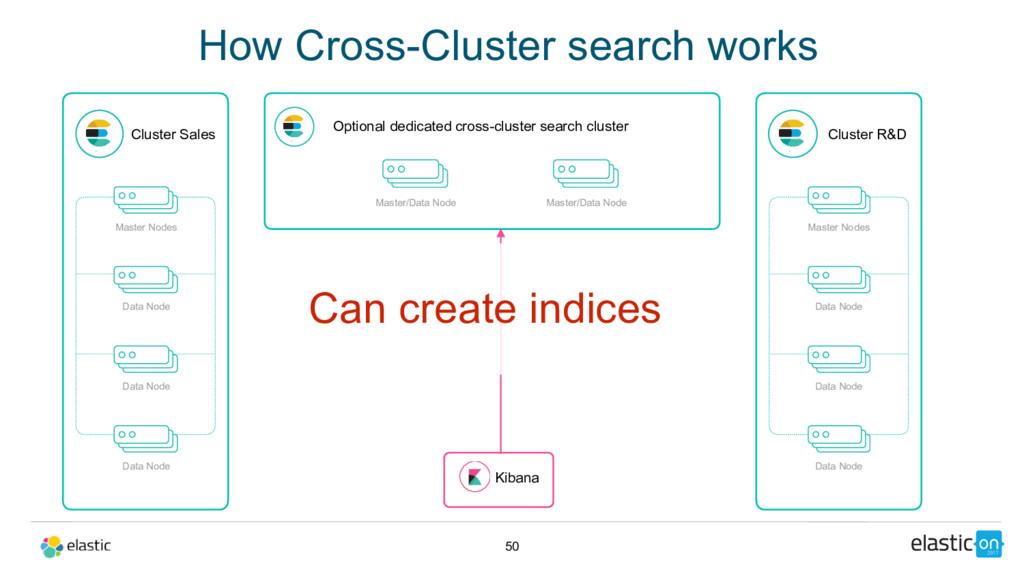
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana Can create indices Optional dedicated cross-cluster search cluster
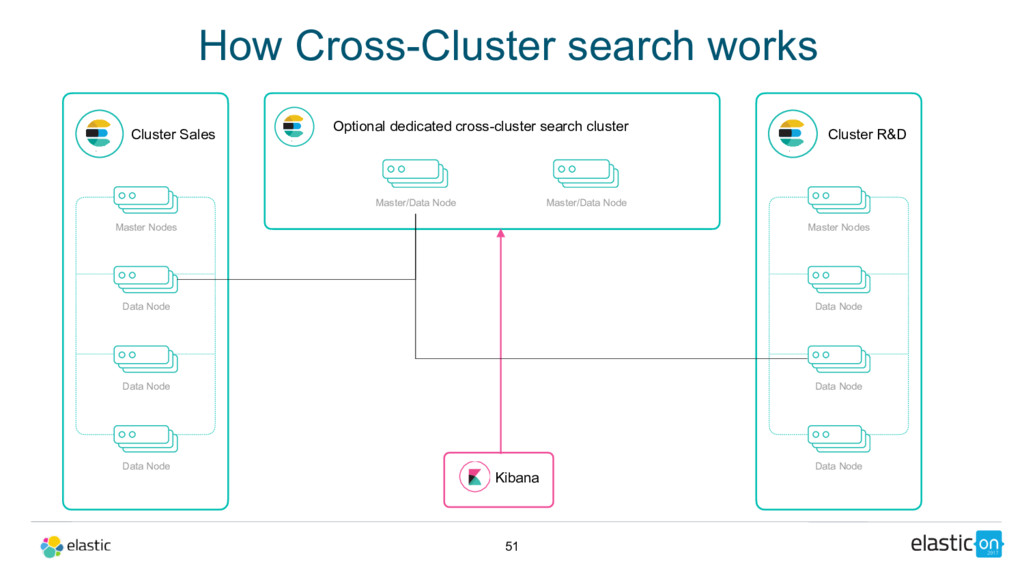
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana Optional dedicated cross-cluster search cluster
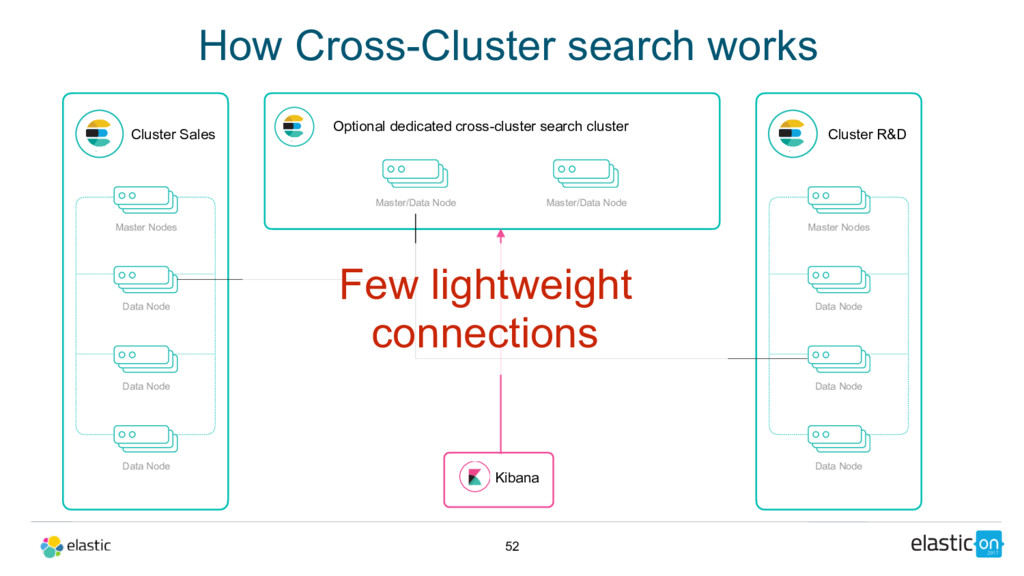
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana Few lightweight connections Optional dedicated cross-cluster search cluster
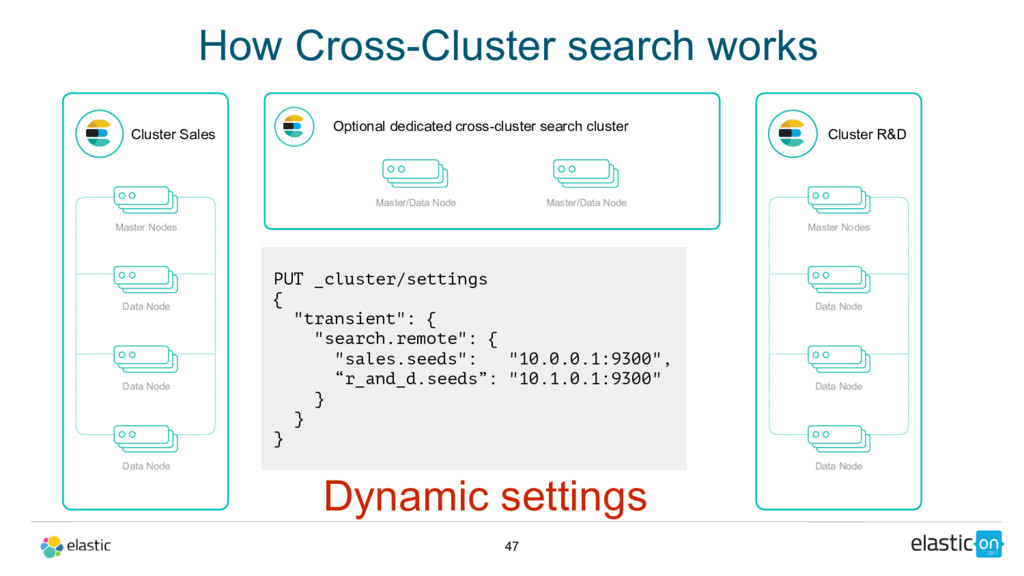
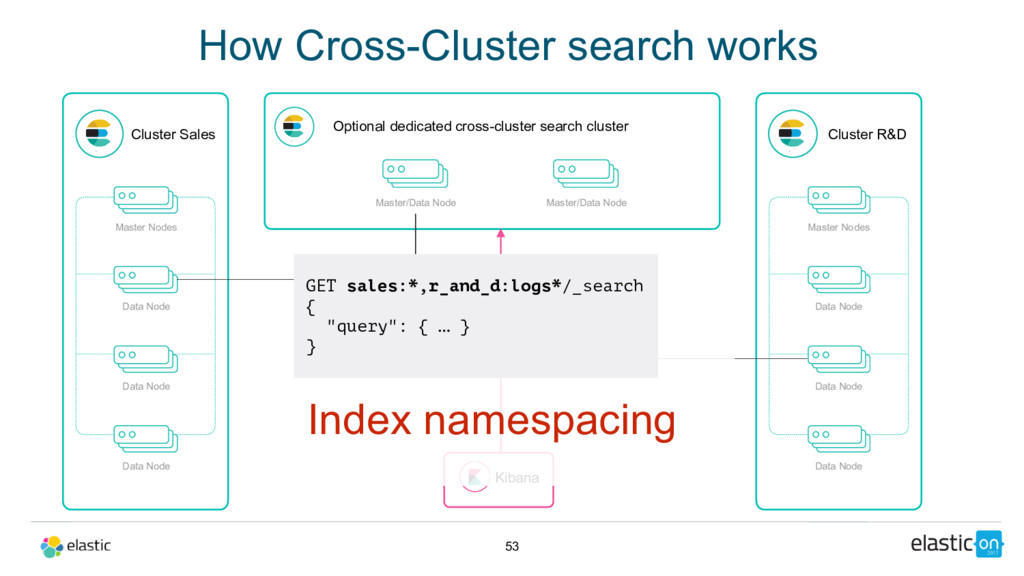
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana Index namespacing GET sales:*,r_and_d:logs*/_search { "query": { … } } Optional dedicated cross-cluster search cluster
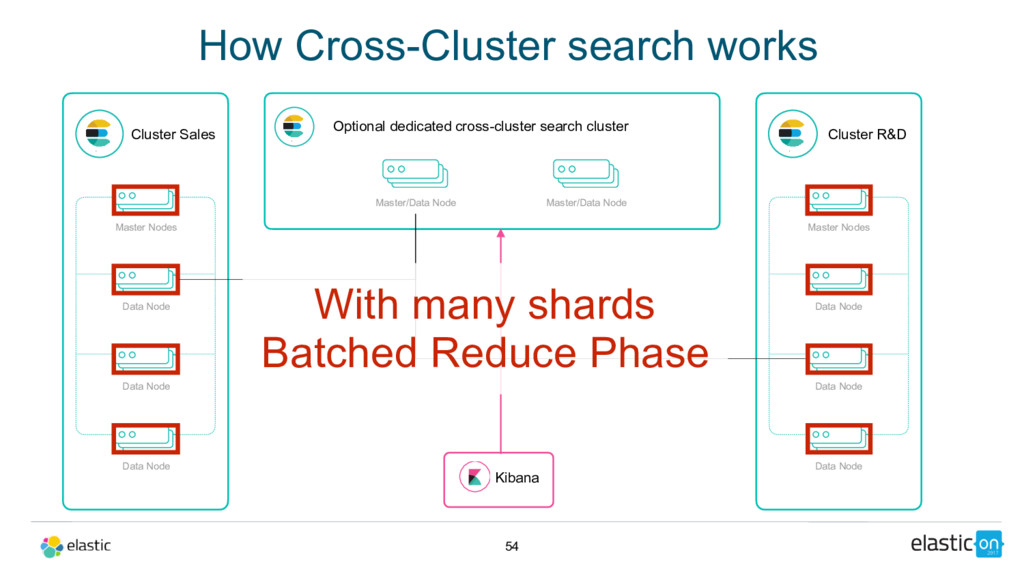
Node Data Node Data Node Master/Data Node Cluster R&D Master Nodes Data Node Data Node Data Node Master/Data Node Kibana With many shards Batched Reduce Phase Optional dedicated cross-cluster search cluster
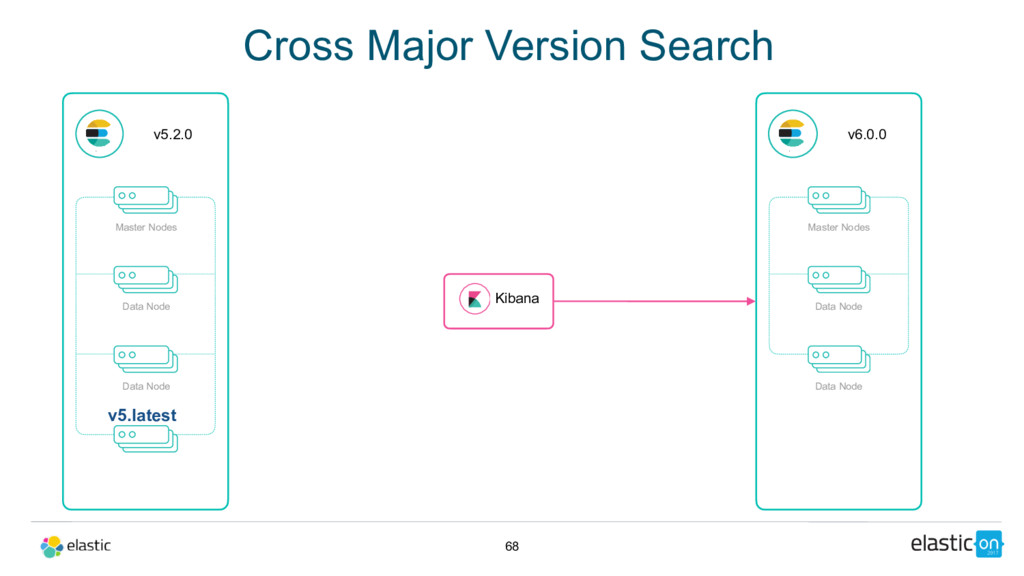
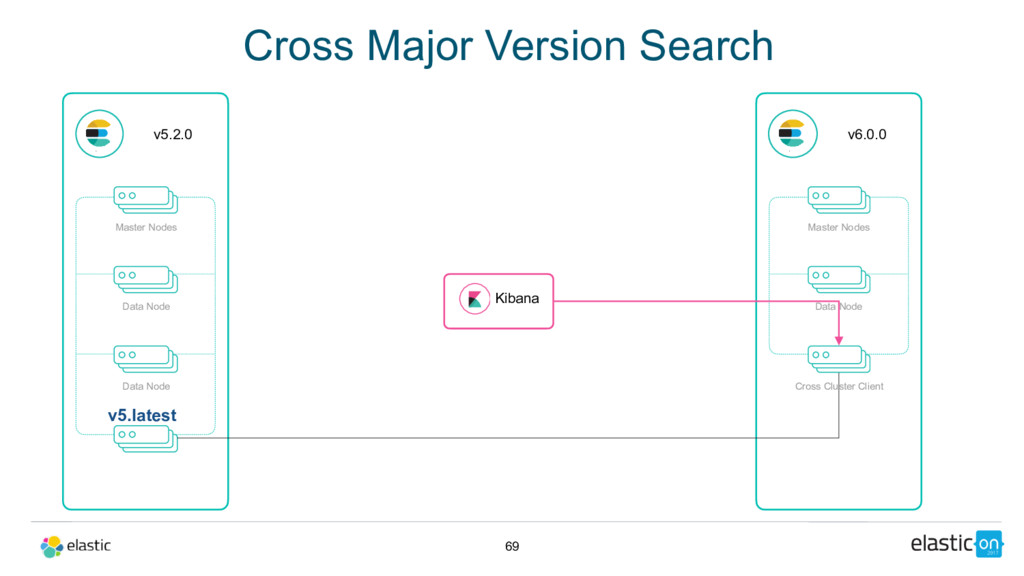
full cluster restart • 5.latest is the latest GA release of 5.x when 6.0.0 goes GA • All 6.x releases will allow upgrading from that 5.x release, unless there is a new 5.x release
TLS enabled • Reserve the right to require full cluster restart in the future, but only if absolutely necessary • All nodes must be upgraded to 5.latest before upgrading • Indices created in 2.x still need to be reindexed before upgrading to 6.x
version upgrade • IDE friendly • Similar API to Transport Client - easy migration • Based on low-level REST client • Supports CRUD & Search • Currently targeted for release in 5.6 • Depends on elasticsearch-core
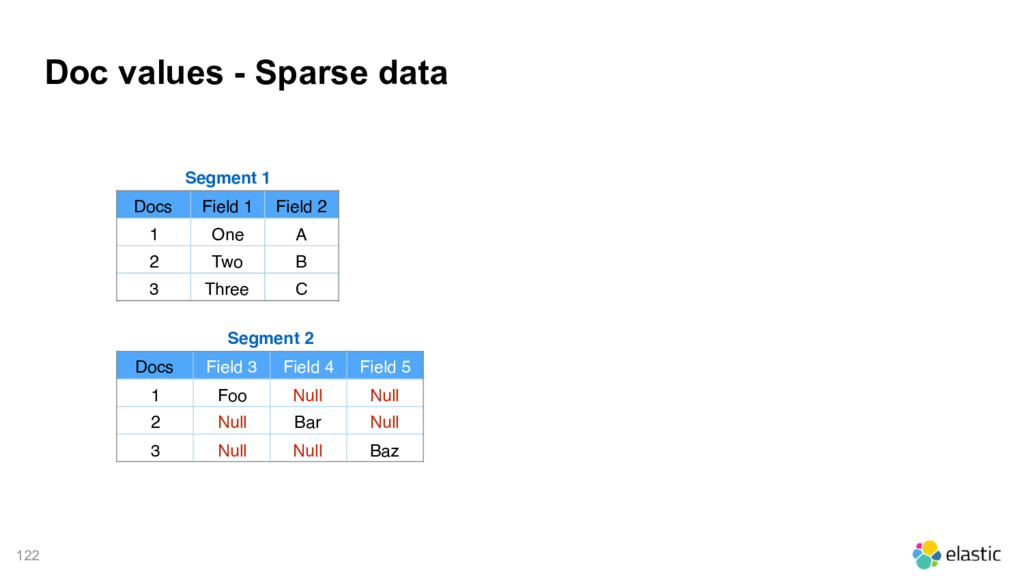
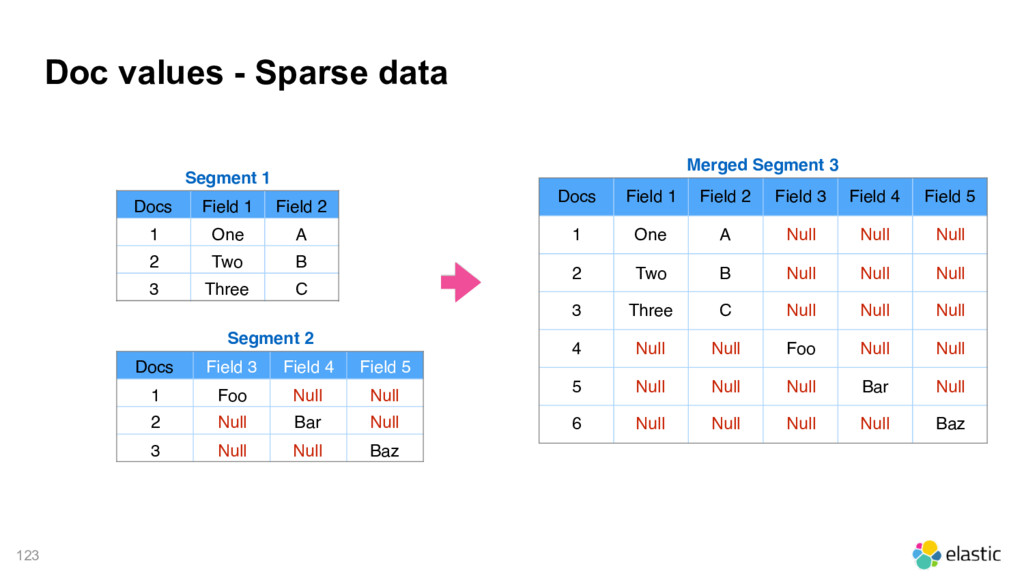
1 Field 2 1 One A 2 Two B 3 Three C Segment 2 Docs Field 3 Field 4 Field 5 1 Foo Null Null 2 Null Bar Null 3 Null Null Baz Merged Segment 3 Docs Field 1 Field 2 Field 3 Field 4 Field 5 1 One A Null Null Null 2 Two B Null Null Null 3 Three C Null Null Null 4 Null Null Foo Null Null 5 Null Null Null Bar Null 6 Null Null Null Null Baz
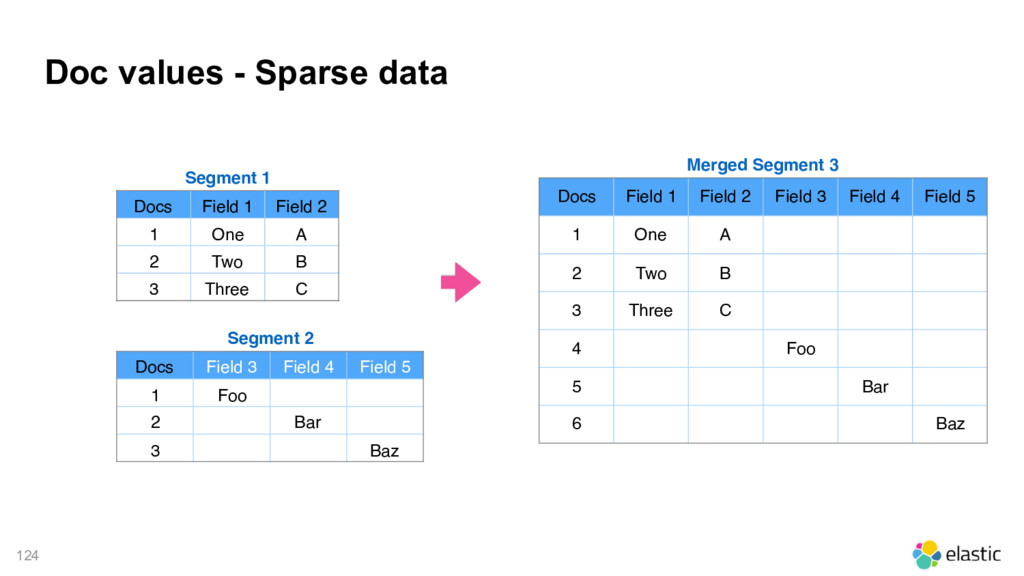
1 Field 2 1 One A 2 Two B 3 Three C Segment 2 Docs Field 3 Field 4 Field 5 1 Foo 2 Bar 3 Baz Merged Segment 3 Docs Field 1 Field 2 Field 3 Field 4 Field 5 1 One A 2 Two B 3 Three C 4 Foo 5 Bar 6 Baz
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
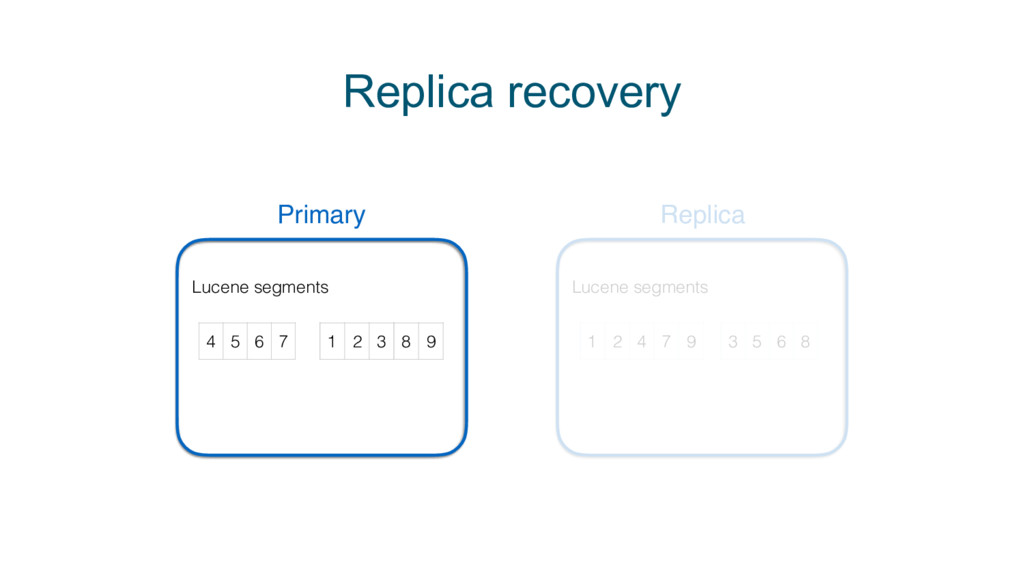{kind=link}
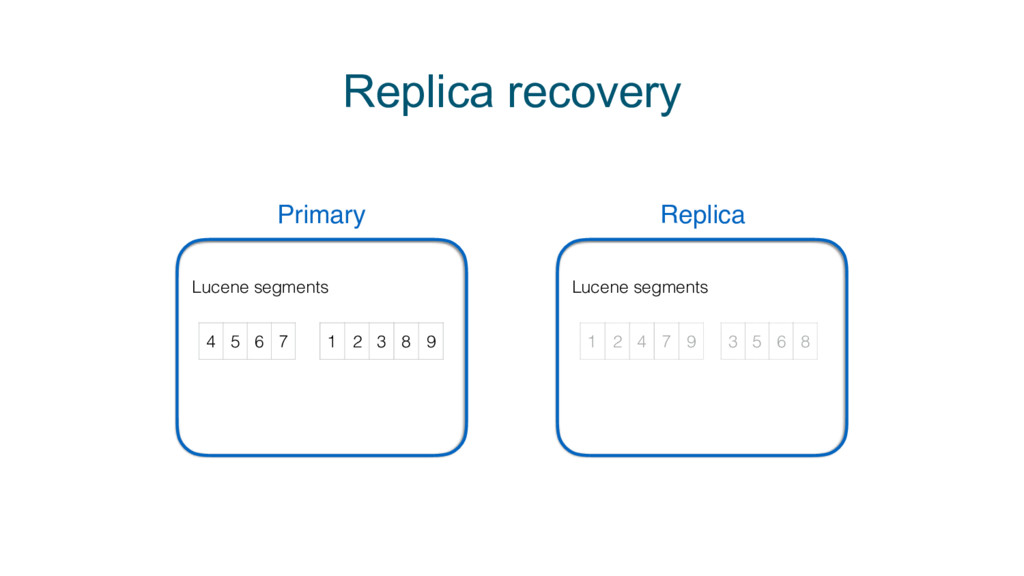{kind=link}
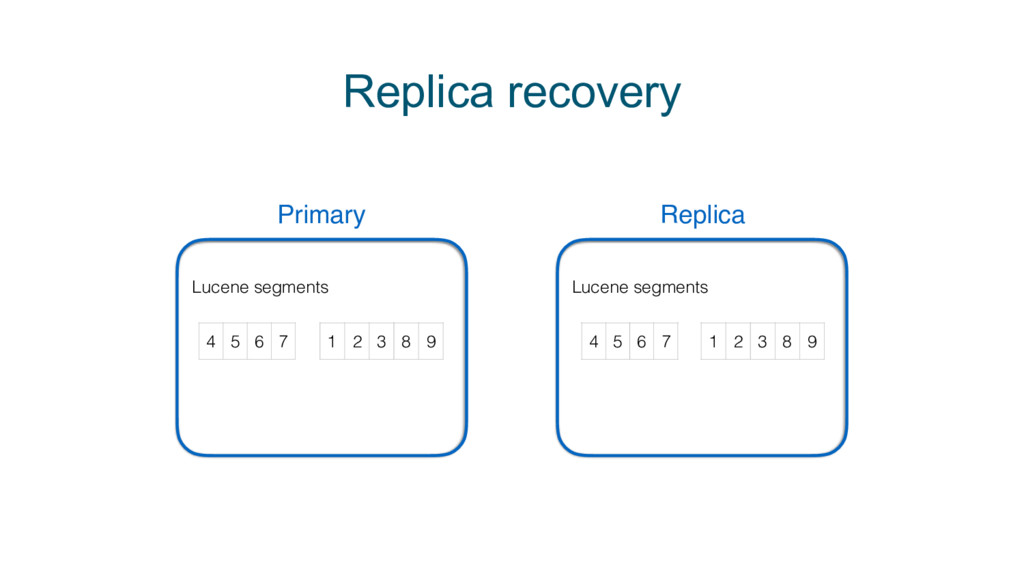{kind=link}
{kind=link}
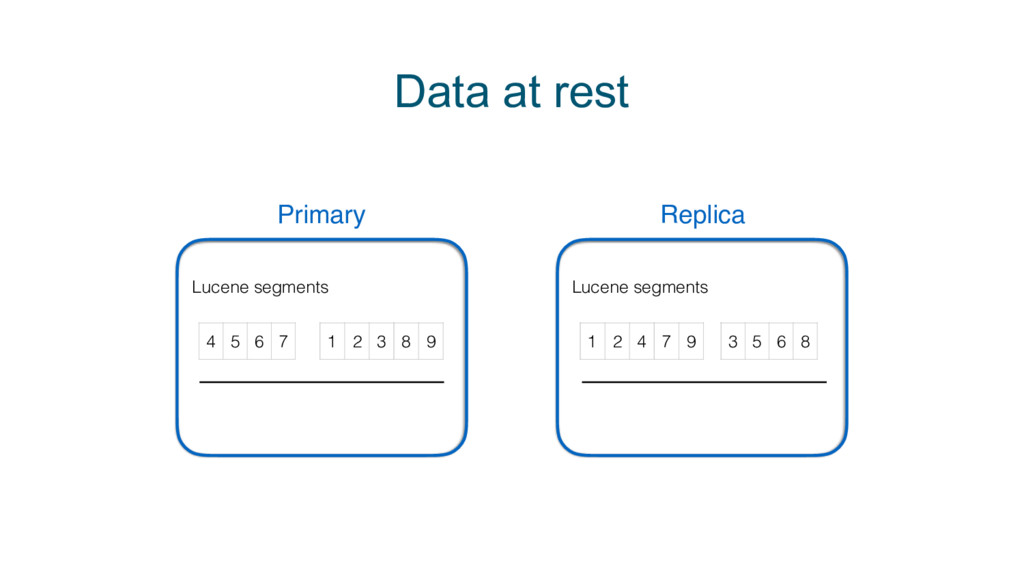{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}