rights reserved. Situación Contar con una plataforma resiliente y de alta disponibilidad para proveer la mejor experiencia a la demanda de usuarios global. Ejemplos: plataformas de servicios (SaaS, streaming), sitios de comercio electrónico, noticias, microservicios, etc.
rights reserved. Retos • Escoger la mejor solución tecnológica • Manejo de fallos a escala • Cercanía a los usuarios en distintas geografías • Leyes y regulaciones
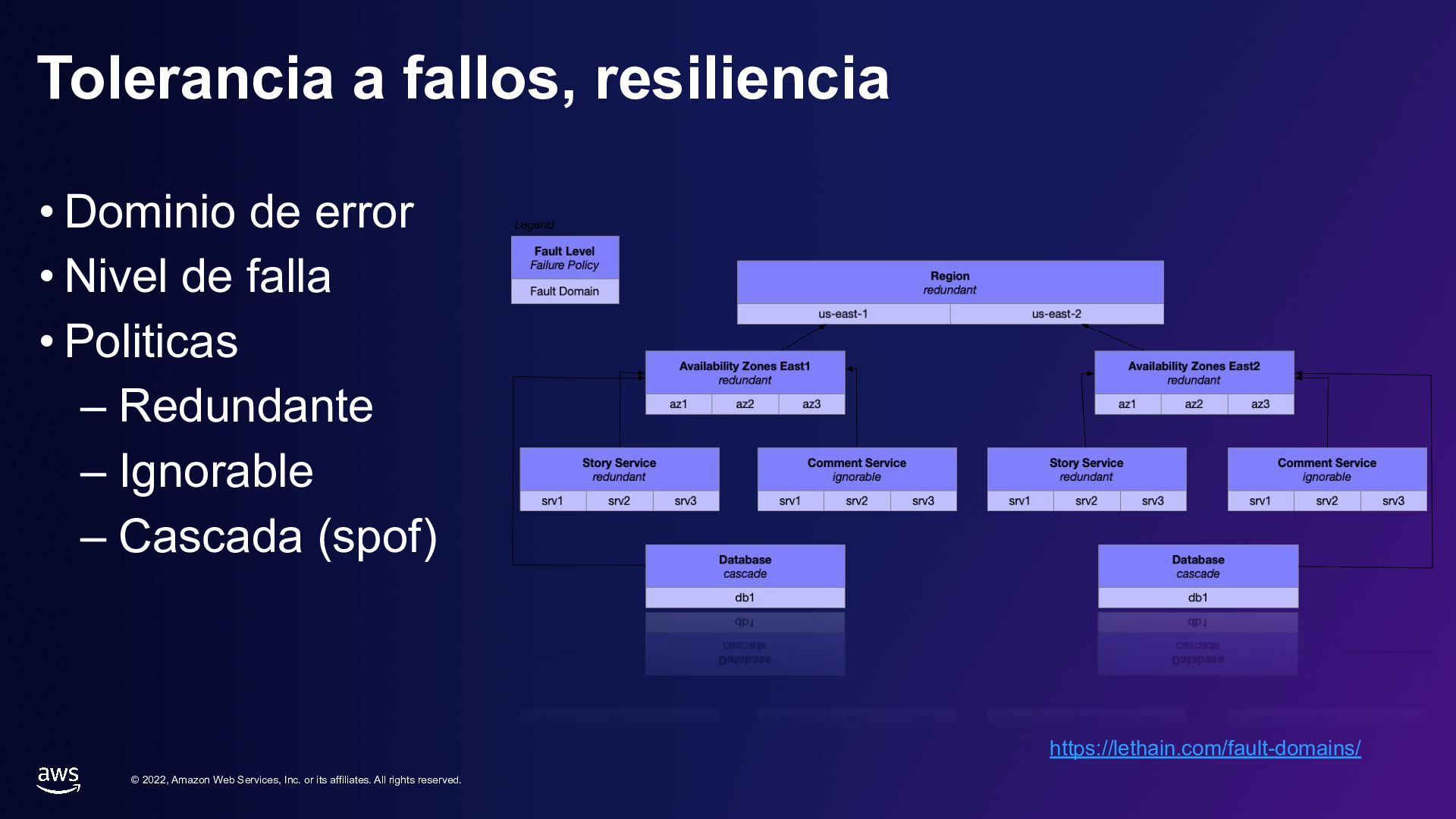
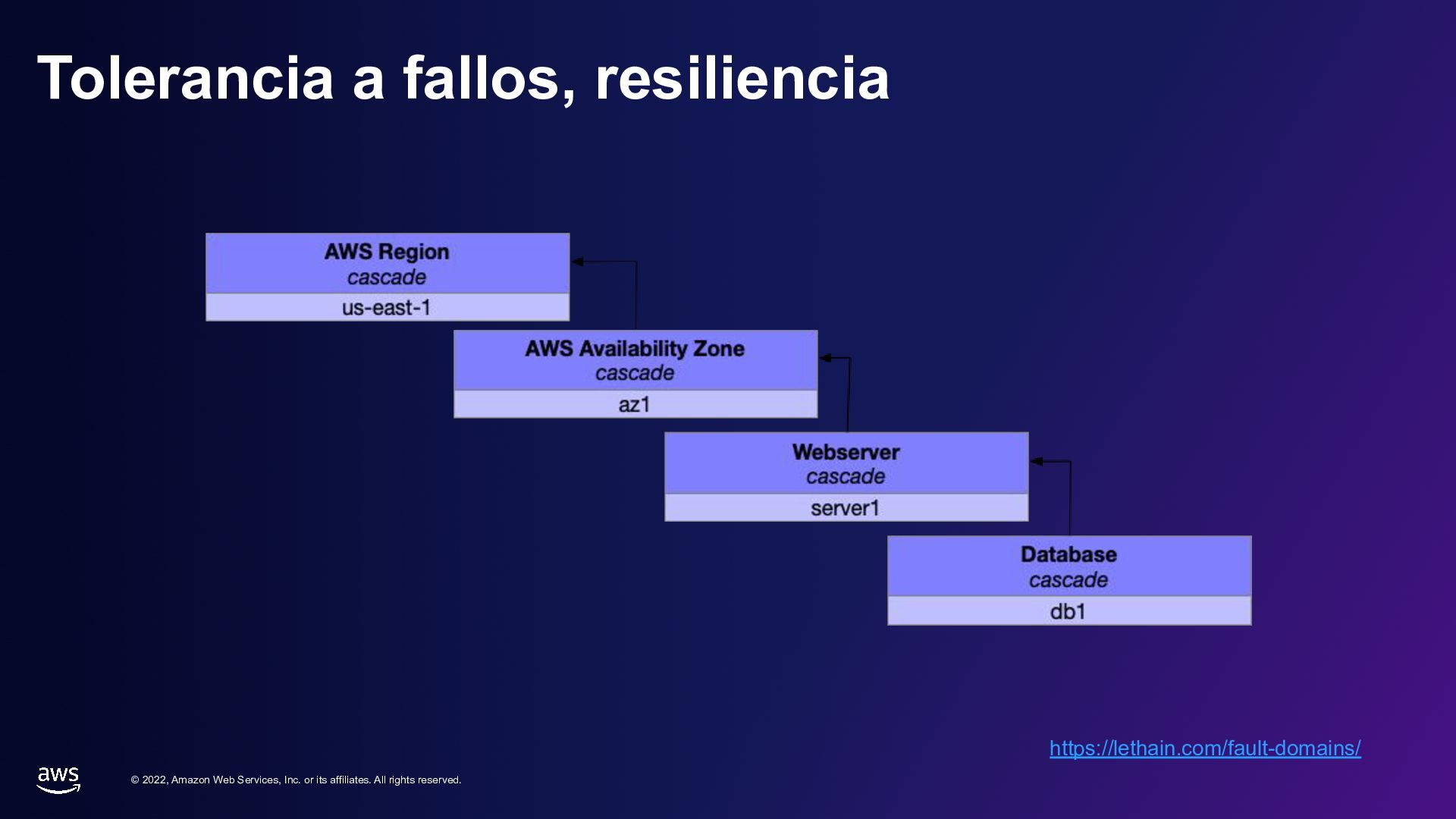
rights reserved. Tolerancia a fallos, resiliencia • Dominio de error • Nivel de falla • Politicas – Redundante – Ignorable – Cascada (spof) https://lethain.com/fault-domains/
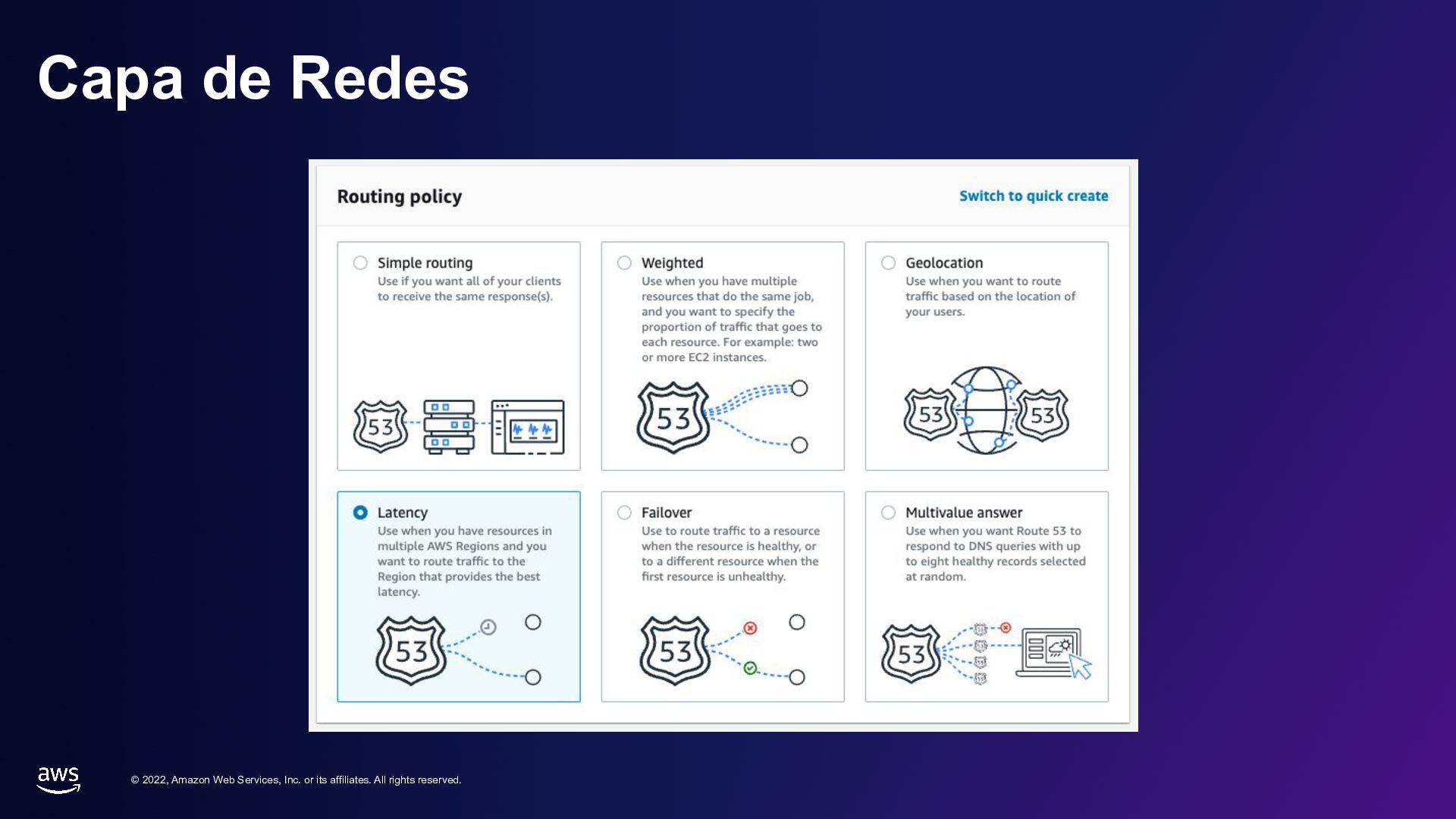
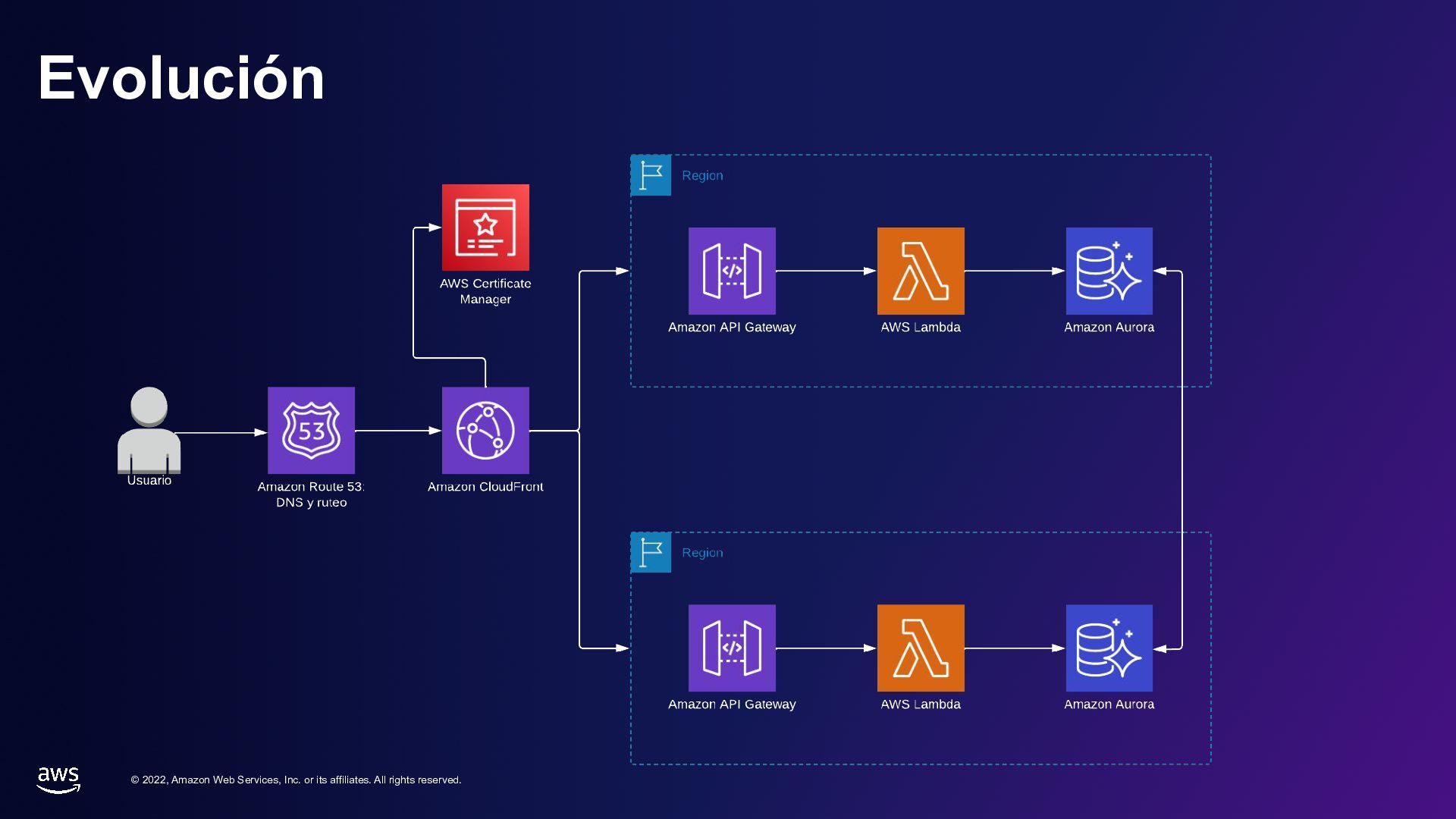
rights reserved. Capa de Redes • CDN: Entrega de contenido global con acceso seguro y rápido. • DNS: Acceso desde el internet a nuestra infraestructura ▪ Ruteo basado en reglas/escenarios – Latencia, failover, geografia, etc – Nombres de dominio • Redes internas: ▪ Interconectadas, regionales
rights reserved. Capa de Cómputo • Servicios ▪ Modulares ▪ Organizados en base a necesidades de negocio ▪ Escalables bajo demanda • Lambda, EC2, ECS, K8s ▪ Elección de acuerdo al caso de uso
rights reserved. Capa de datos • Identificar patrones de acceso y sus métricas ▪ Identificar tipo de acceso a datos (bloque, archivo, objeto) ▪ Costo • Cercanía y ubicación del usuario – Filtrado y/o particionado – Ruteo global o por región
rights reserved. Capa de datos • Servicios en AWS compatibles con la replicación entre regiones: ▪ DynamoDB ▪ RDS Aurora ▪ RDS ▪ S3 ▪ ElastiCache ▪ DocumentDB
rights reserved. Capa de seguridad, identidad y acceso • IAM ▪ Global: usuarios, roles, cuentas, grupos • KMS ▪ Creación con capacidad Multi-región • Secrets Manager ▪ Puede replicar secretos en regiones secundarias
rights reserved. Instrumentación y monitoreo • Una estrategia de monitoreo e instrumentación requiere varias iteraciones • Nuevos servicios como Amazon DevOps Guru ayudan a: ▪ Identificar comportamientos anómalos o inesperados ▪ Sugerir mejoras de configuración ▪ Alertar sobre fallos críticos
rights reserved. Pruebas y automatización • Llevar a cabo un proceso de pruebas y automatización minucioso para garantizar la funcionalidad de cada región • Tip ▪ Nuevas regiones se pueden utilizar para – Validar nuevas funcionalidades – Simulación de desastres
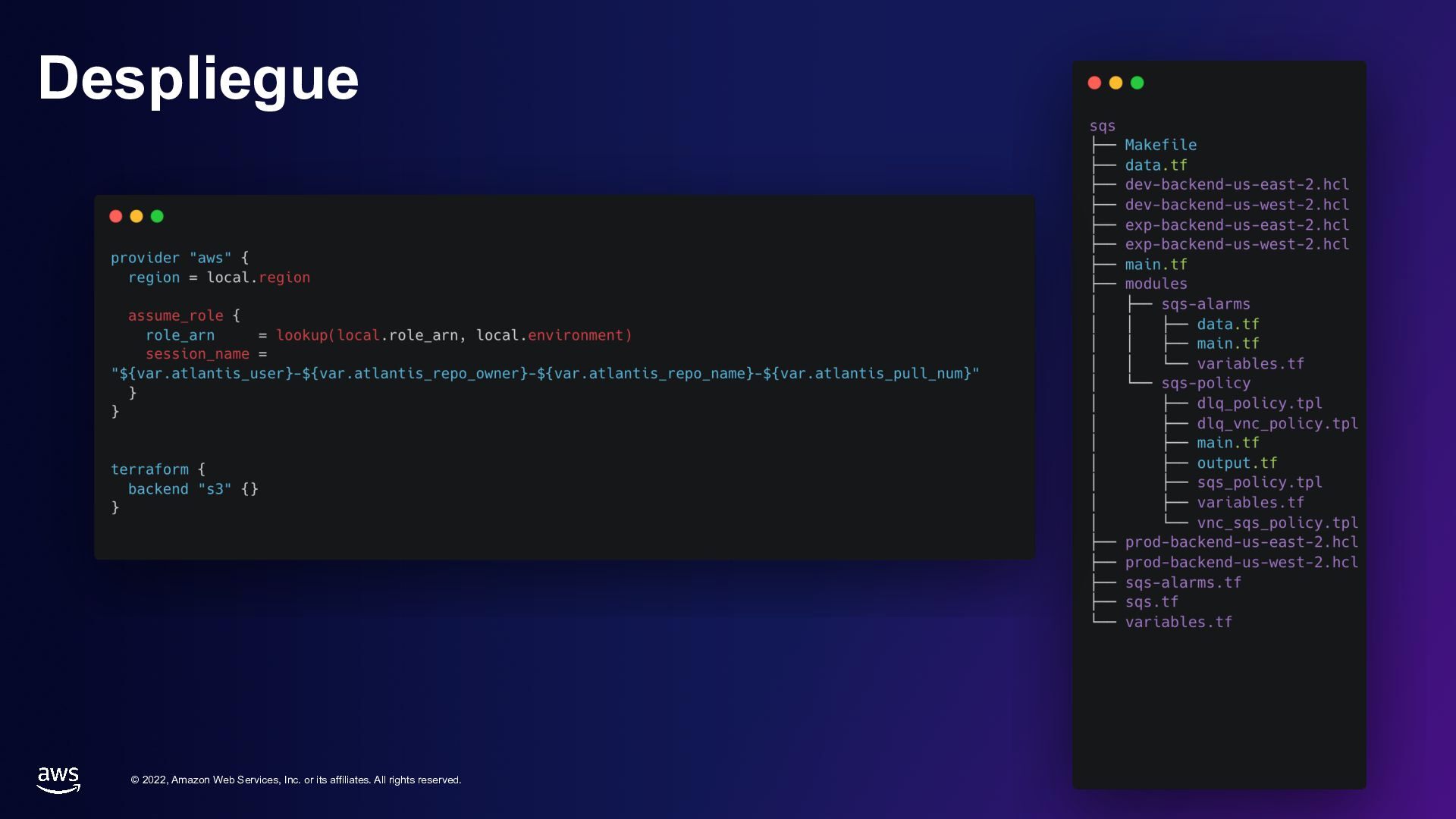
rights reserved. Despliegue • Infraestructura como código • Control de cambios granular ▪ Cuenta, ambiente y región ▪ Predictibilidad – Tiempo, dependencias • IAM - sólo los permisos necesarios • Fallos controlados
rights reserved. A considerar • Verificar la oferta y disponibilidad en el catálogo de servicios • Inversión asociada con respecto al consumo y utilización de recursos en varias regiones
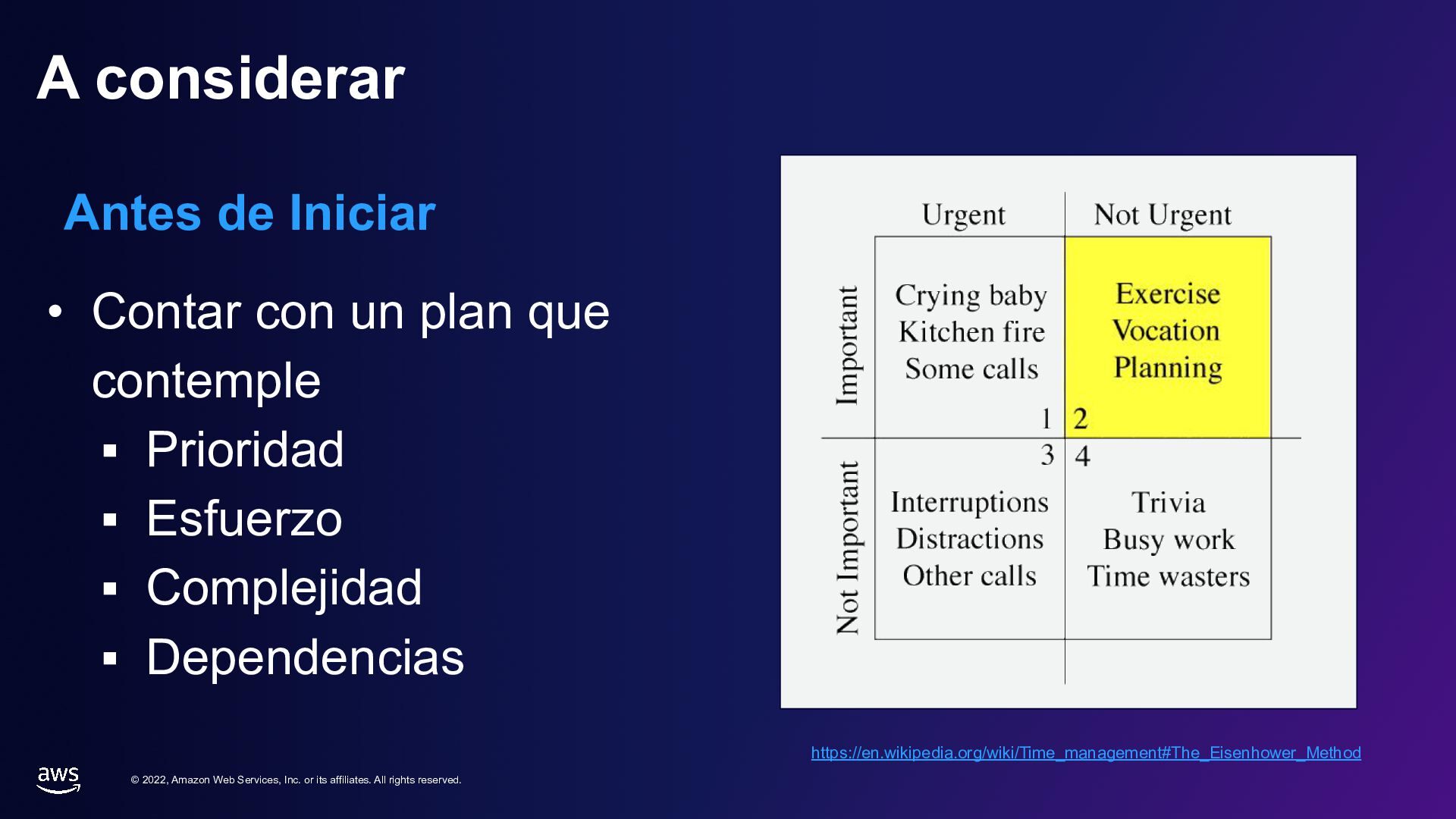
rights reserved. A considerar Antes de Iniciar • Contar con un plan que contemple ▪ Prioridad ▪ Esfuerzo ▪ Complejidad ▪ Dependencias https://en.wikipedia.org/wiki/Time_management#The_Eisenhower_Method
rights reserved. Resumen • Se necesita una infraestructura global para lograr resiliencia y tolerancia a fallos ◦ Infraestructura cercana al usuario ◦ Podemos crecer y adaptar cargas de trabajo de acuerdo a su geografía • El acceso a datos entre regiones debe ser fiable y rápido
rights reserved. Resumen • El manejo de los recursos requiere de un nivel de complejidad en orquestamiento y automatización • Priorizar la inversión constante en automatización ◦ Ejemplo: recrear fácilmente entornos en otra región con IaC.
rights reserved. Próximos pasos • Planeacion e inventario de infraestructura Well Architected Review • Siempre hay pequeñas excepciones donde podemos regionalizar • Una buena estrategia de manejo de DNS hace una gran diferencia
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}