This talk goes over the infrastructure needed to run Microservices in production by answers the following questions:
* Why do I want to run my software in Containers?
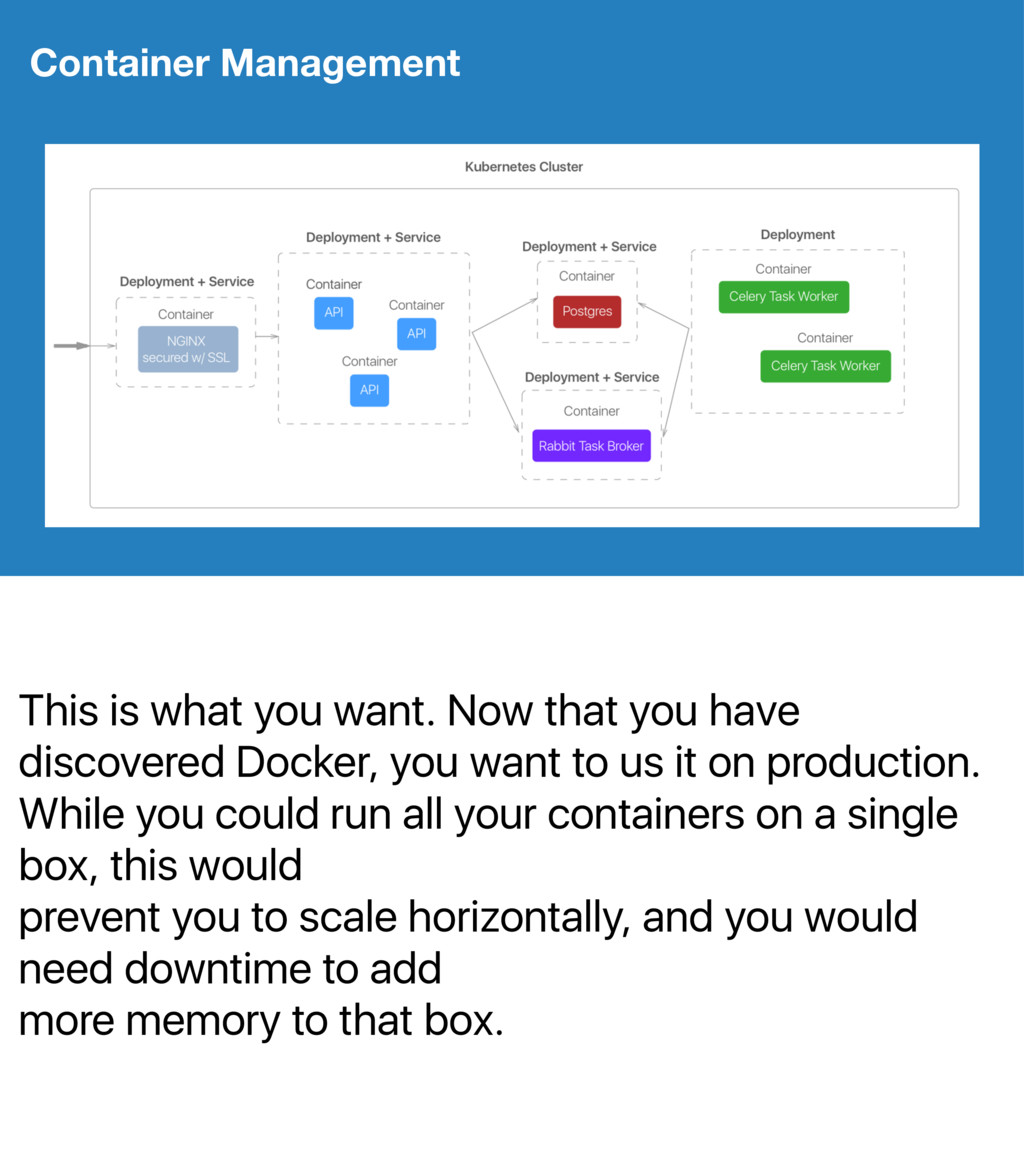
* What is a Kubernetes or Mesos?
* Am I going to need a DevOps or SRE team? What will they do?
* How will my Continuous Integration/Delivery will look like?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Container Management: Scheduler Options[^2] More info here: https://medium.com/@mustwin/a-handy-guide-to- the-mesos-kubernetes-swarm-jungle- ad6bc086c736#.6ji95fm7e](https://files.speakerdeck.com/presentations/066434ac9f444b888e1dff4582c8e331/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}