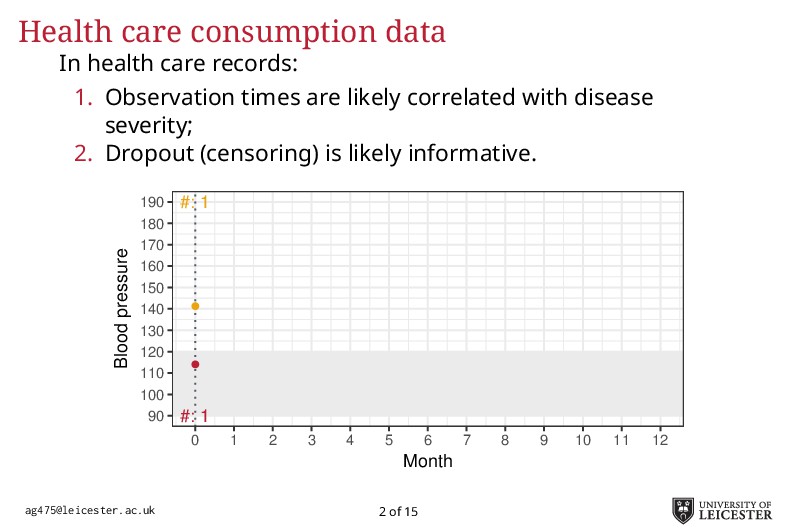
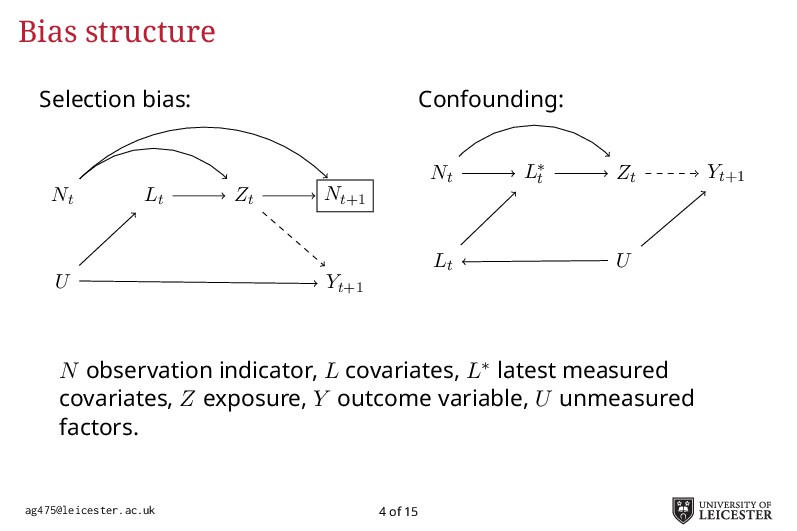
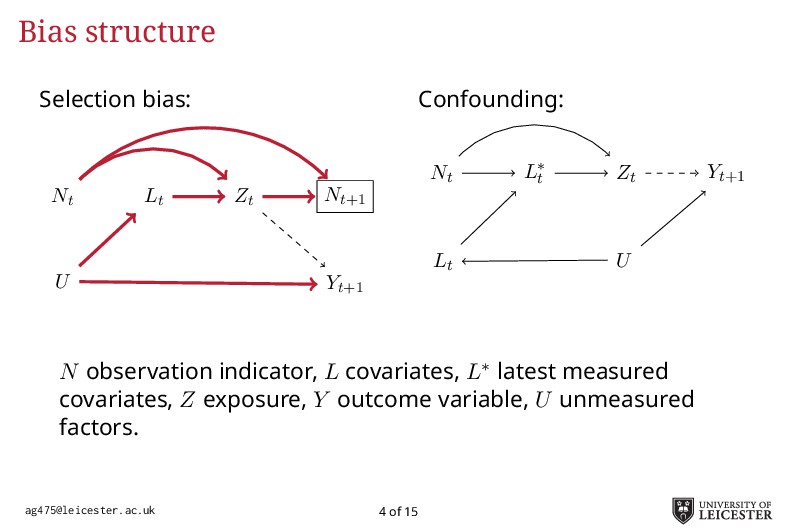
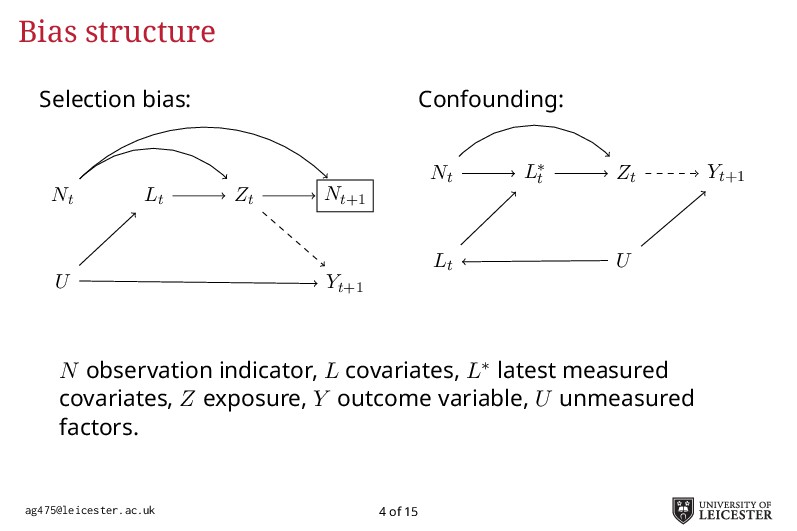
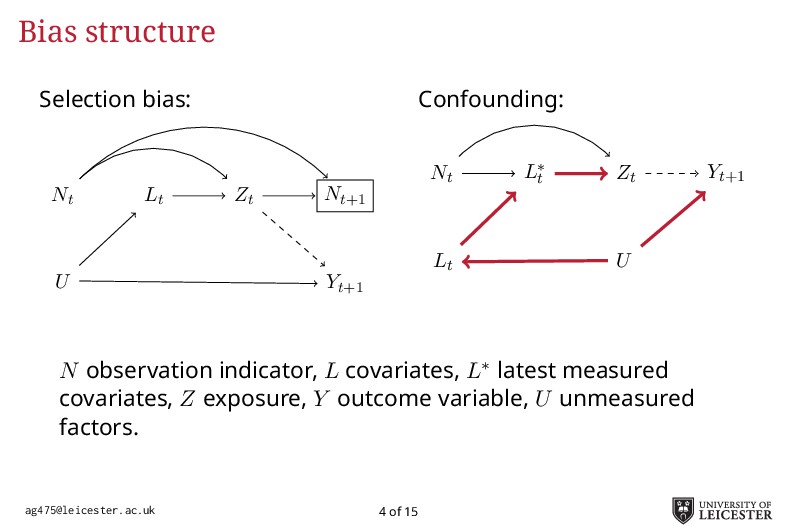
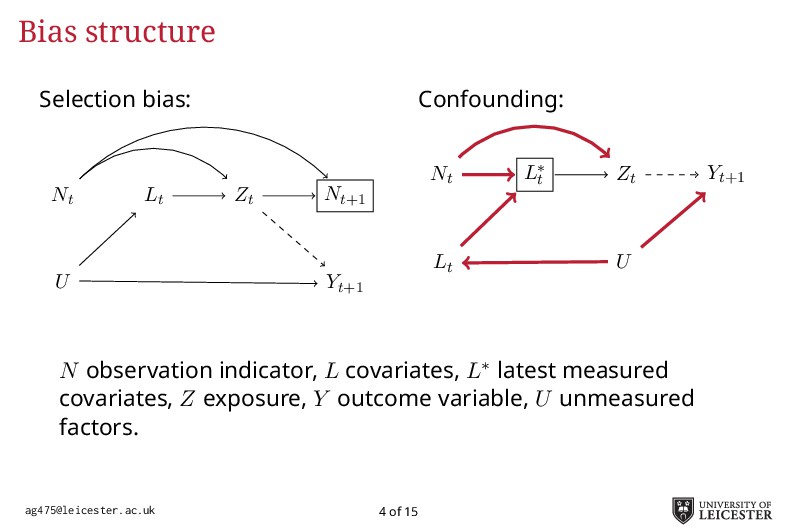
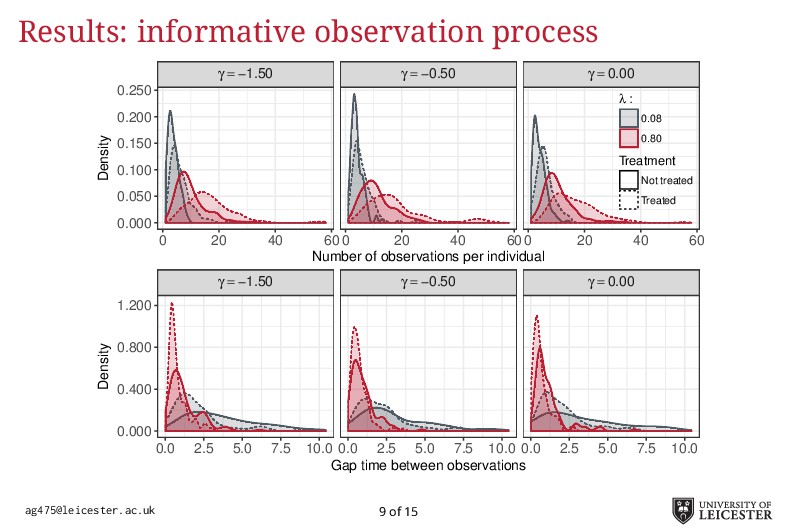
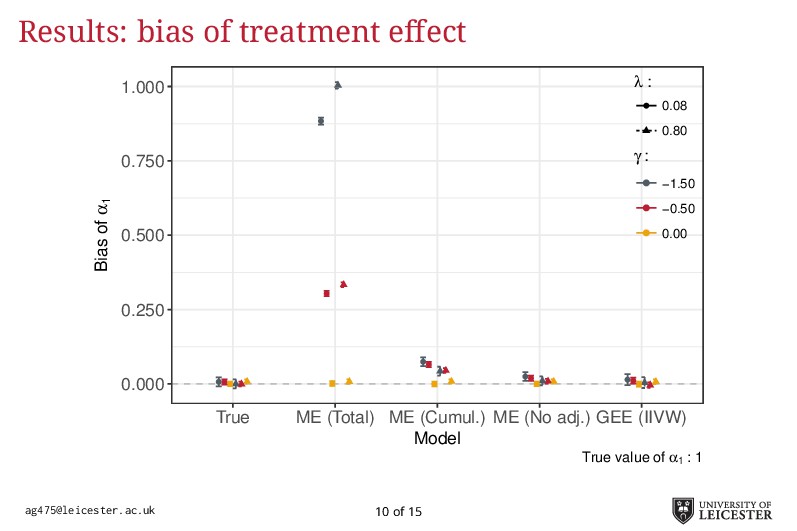
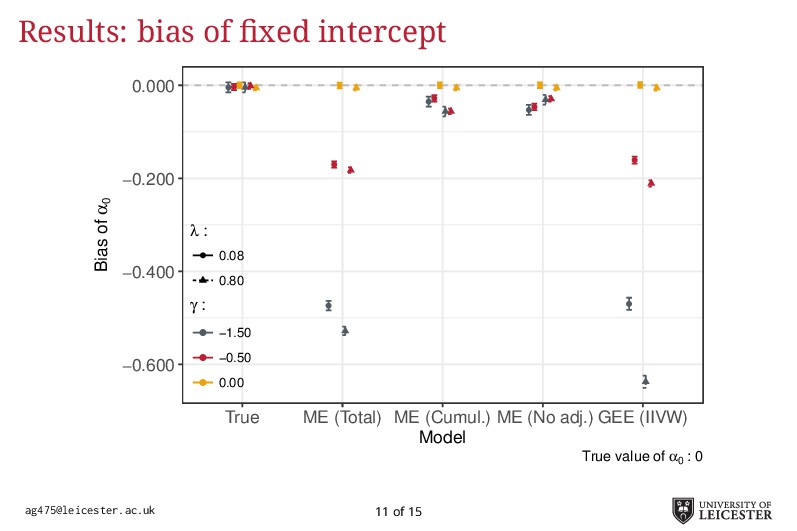
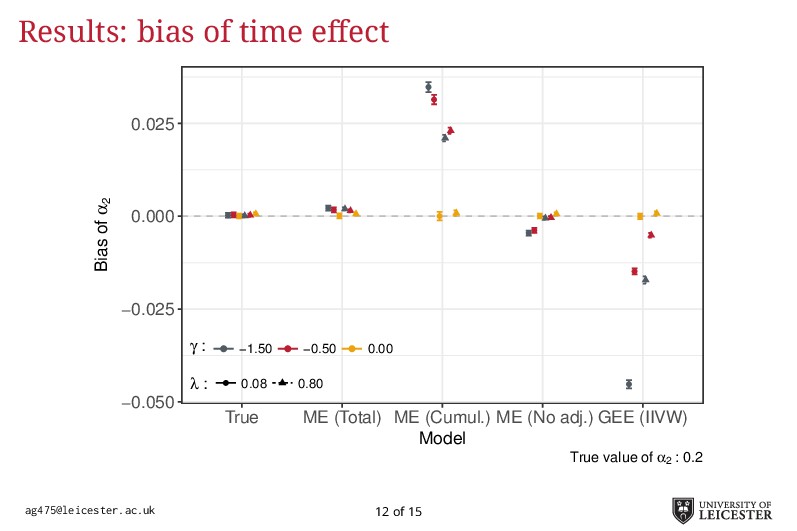
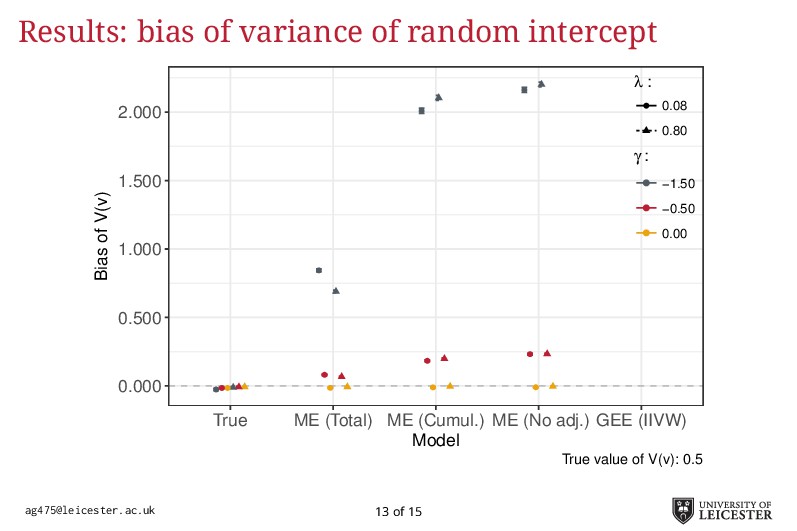
Electronic health records are being increasingly used in medical research to answer more relevant and detailed clinical questions; however, they pose new and significant methodological challenges. For instance, observation times are likely correlated with the underlying disease severity: patients with worse conditions utilise healthcare more and have worse biomarkers recorded. Additionally, a terminal event truncating observation of the longitudinal process is deemed informative when it correlates with disease severity. Traditional methods for analysing longitudinal data assume independence between observation times and disease severity; yet, with healthcare data such assumption unlikely holds leading to biased model estimates. Joint models for longitudinal and survival data can account for informative dropout processes, but research is scarce on whether inference is valid when the observation process is informative. Through extensive simulation studies, we compare different analytical approaches proposed to account for an informative visiting process. We cover both simple (including the number of measurements as a covariate) and complex methods (e.g. trivariate joint models for the longitudinal, survival, and visiting processes; Liu, 2008). We conclude by summarising which methods lead to valid inference, and under which settings, and describe how to fit the more complex models within an extended joint modelling framework (Crowther, 2017).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}