running properly and meets the expectations. Integration Tests • My system is running properly and meets the expectations. UI/UX Tests • It is like a charm!
running properly and meets the expectations. Integration Tests • My system is running properly and meets the expectations. UI/UX Tests • It is like a charm!
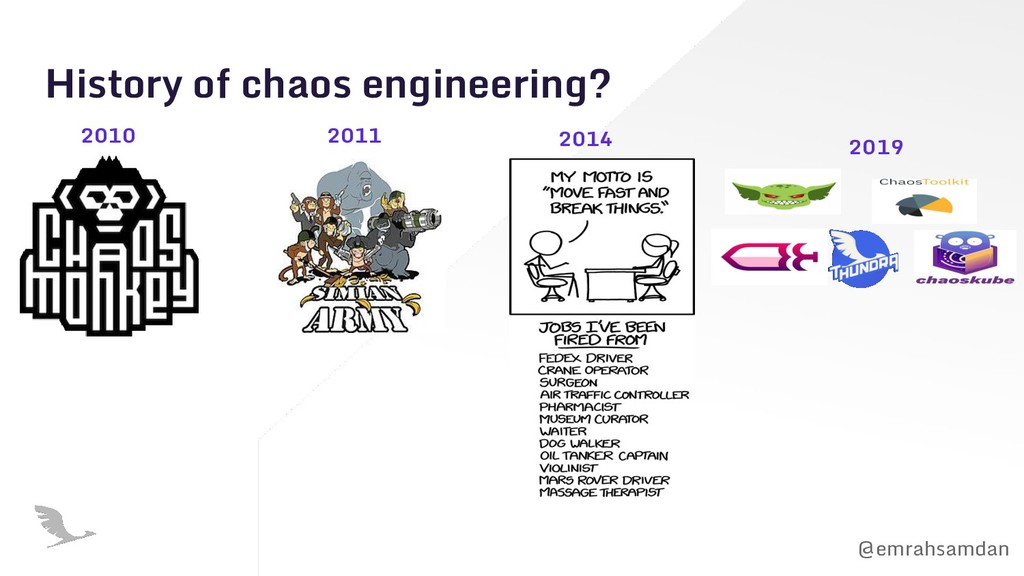
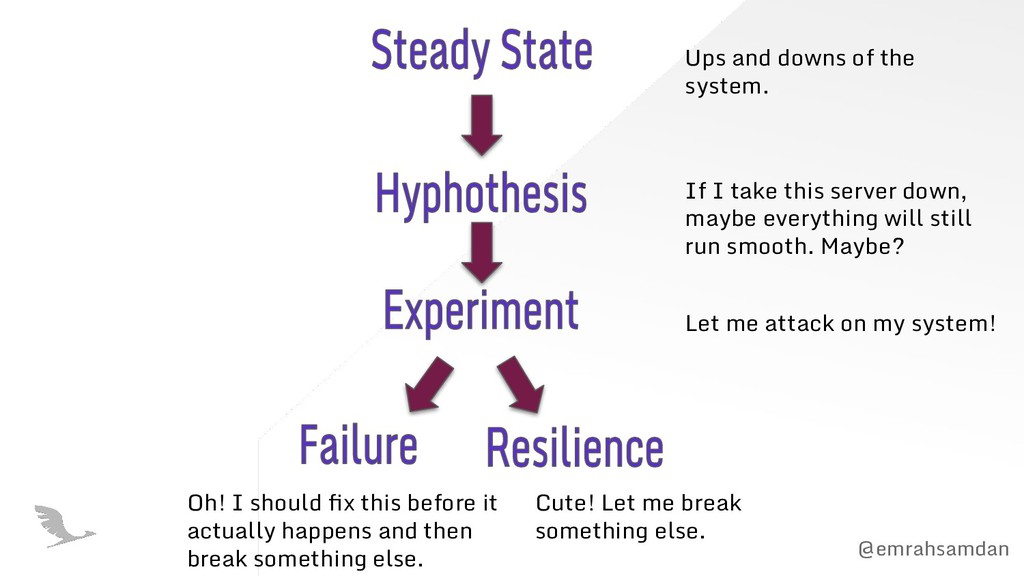
this server down, maybe everything will still run smooth. Maybe? Let me attack on my system! Cute! Let me break something else. Oh! I should fix this before it actually happens and then break something else.
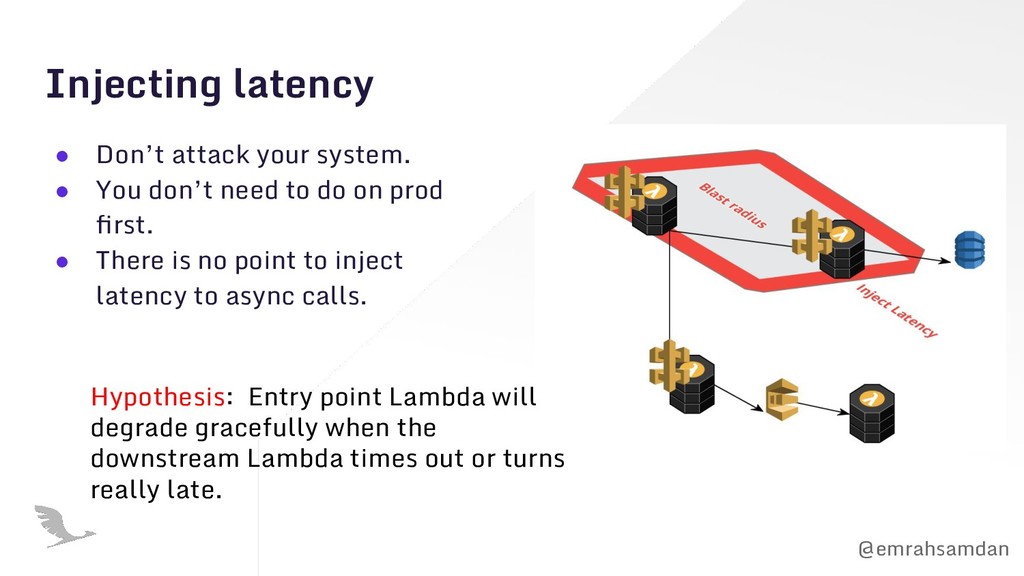
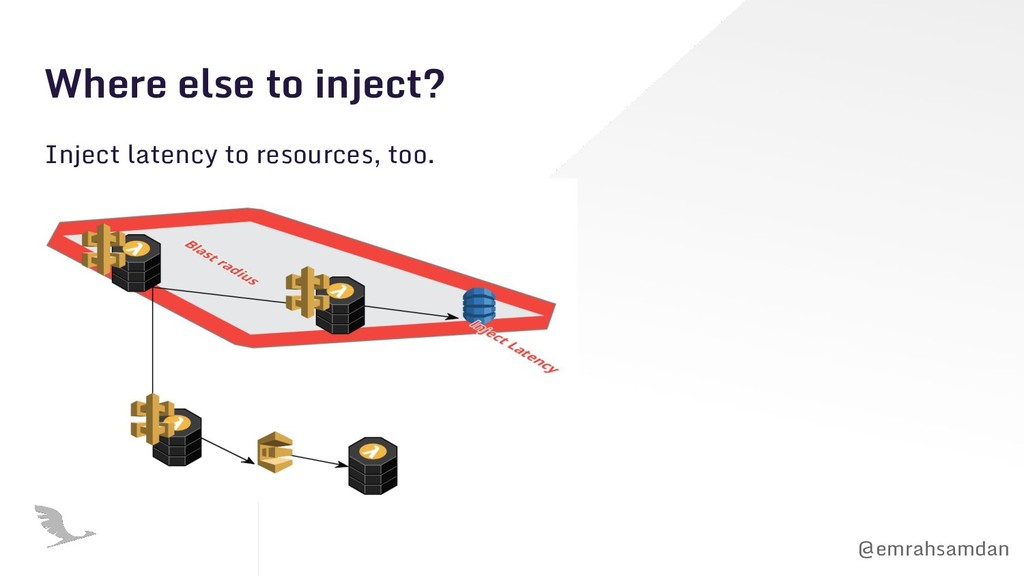
first row, the leftmost cell: Known-knowns. • Blast radius: The effect will make the smallest effect. • Put a stop button somewhere! • Plan how you learn. • You don’t need to do it on production for the first time. • The most important Let the other people know! Surprising chaos is not funny. No, at all!
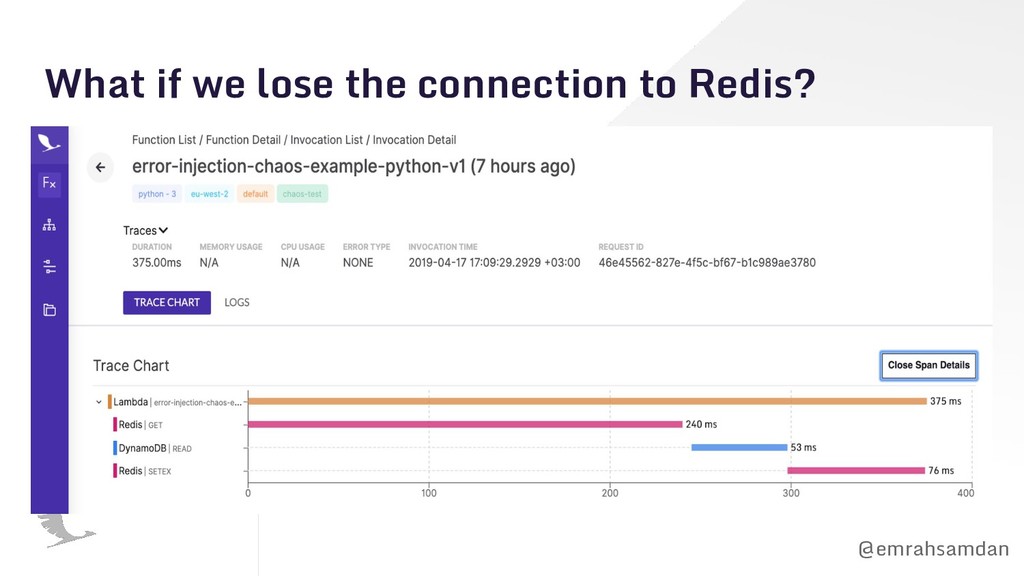
DB. • DB is returning too slow for 1% of your customers. Hypothesis: The system won’t experience an outage when DB is hardly accessible. Result: People experiences timeouts while waiting for results.
don’t need to do on prod first. • There is no point to inject latency to async calls. Hypothesis: Entry point Lambda will degrade gracefully when the downstream Lambda times out or turns really late.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}